获取数据列的第 x 行,通过 Offsets 获取该行的起始索引 start=offsets (x) 和下一行的起始索引 end=offsets (x+1),然后使用这两个索引通过 Bytes 获取具体数据对应的字节流 bytes.slice (start,end),最后按照字段类型做相应的转换即可。
注:为方便表述,上面例子做了一定的简化,对于 Nullable 数据列,实际上还有 FixedLengthColumn<uint8_t> 的数据结构,对应一段连续的 Bool 数据,用来表示对应行号的列数据取值是否为 Null,用来加速 Nullable 列的计算效率,减少数据列的存储空间。
内存分配和管理设计
由于 BE 端是通过 Memory Tracker 进行内存管理的,我们在实现 JNI Reader 时,由 Memory Tracker 统一进行内存的分配和销毁,避免直接使用 JVM Unsafe 分配 Native Memory,来保证内存统计的准确性,并防止出现错误的内存使用导致的各类问题。
编程框架设计
在编程框架上,我们完整定义了 JNI Connector 的 Java 接口,让开发者不需要进行复杂的 JNI 编程以及相关的内存管理,只需要继承 ConnectorScanner 抽象类,实现 open (), getNext (), close () 这三个抽象方法,然后在 BE 侧给出具体实现类的名称,便可以完整使用我们的 JNI Connector, 读取各类 Java 数据源的数据。
混合使用 Native Reader 和 JNI Reader 设计
在 Hudi Reader 的实现里,我们有一个优化方案。上文提到,我们在 Scan range 里添加了 useJNIReader 的字段。这个字段具体取值在 FE 端通过下面逻辑控制:
判断当前表的数据类型:如果是 MOR 表,查询类型为 Snapshot,且该 File Slice 包含一个或一个以上的 Delta log,useJNIReader 便置为 True,其他情况都为 False。
这样带来的效果是,对于同一个 MOR 表的 Snapshot 读取,BE 端实际上会同时混合使用两种不同的 Reader 去拿数据,使用 Native reader 读取不包含 Delta Logs 的 File Slice,使用 JNI Reader 读取包含 Delta Logs 的 File Slice,不同的 Reader 混合使用可以进一步提升读取效率,且这些加速对于用户都是透明无感知的。
6、使用案例
1. 创建 hudi catalog
CREATE EXTERNAL CATALOG "hudi_catalog"
PROPERTIES (
"type" = "hudi",
"hive.metastore.uris"= "thrift://xxx:9083" -- hive metastore地址
);2. 执行查询
select * from hudi_catalog.<db_name>.<table_name>;+------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+
| id | age | _hoodie_commit_time | _hoodie_partition_path | _hoodie_record_key | _hoodie_commit_seqno | _hoodie_file_name |
+------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+
| 3 | 33 | 20220422111823231 | age=33 | id:3 | 20220422111823231_0_3 | 29d8d367-93f9-4bd3-aae4-47852e443e36-0_0-128-114_20220422111823231.orc |
+------+------+---------------------+------------------------+--------------------+-----------------------+------------------------------------------------------------------------+
7、性能测试
测试环境:
阿里云 EMR Presto 集群,阿里云 EMR StarRocks 集群
硬件配置:
Master: ecs.g7.4xlarge 16 vCPU 64 GiB
Worker: ecs.g7.4xlarge 16 vCPU 64 GiB * 5
软件配置:
StarRocks 版本:master 分支(Hudi MOR 读取特性会在 2.5.0 正式发布)
StarRocks 软件配置:默认配置
Presto 版本:0.277
Presto 软件配置:
query.max-memory-per-node=40GB
query.max-memory=200GBCOW 表 Snapshot 查询 TPCH-100 测试结果
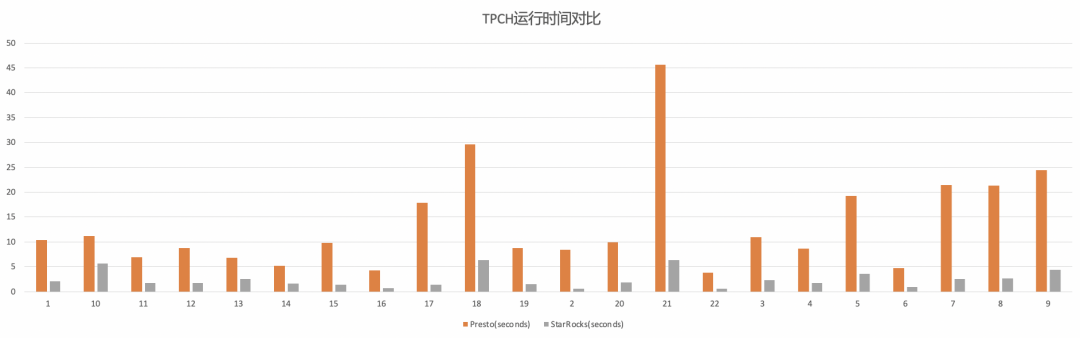
对于 COW 表 Snapshot 查询,使用 StarRocks 相对 Presto 大约会带来 5 倍的性能提升。
MOR 表 Snapshot 查询 TPCH-100 测试结果
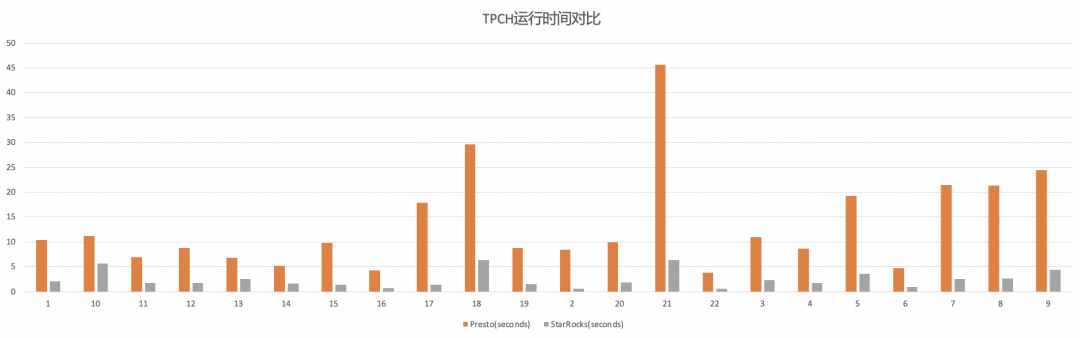
对于 MOR 表 Snapshot 查询,如上文描述,混合使用了 Native Reader 和 JNI Reader,因此,我们在 StarRocks 上测试读取不同比例更新数据(带有 Delta Logs 的 File Slice)的执行时间,来得到不同更新比例场景下的查询效率数据。从测试结果可以看出,更新数据比例越小,StarRocks 实际执行时使用 Native Reader 的比例也就越高,执行效率也越好。
根据社区的经验,最常见的库表更新场景里,在 Hudi 表做 Compaction 操作前,带有 Delta Logs 的 File Slice 占整个表的比例大约在 20% 左右,在这种条件下,使用 StarRocks 相对 Presto 大约会带来 2-3 倍的性能提升。
对于 MOR 表 Read Optimized 查询,StarRocks 内部执行原理和流程与 COW 表相同,性能提升数据也一致。