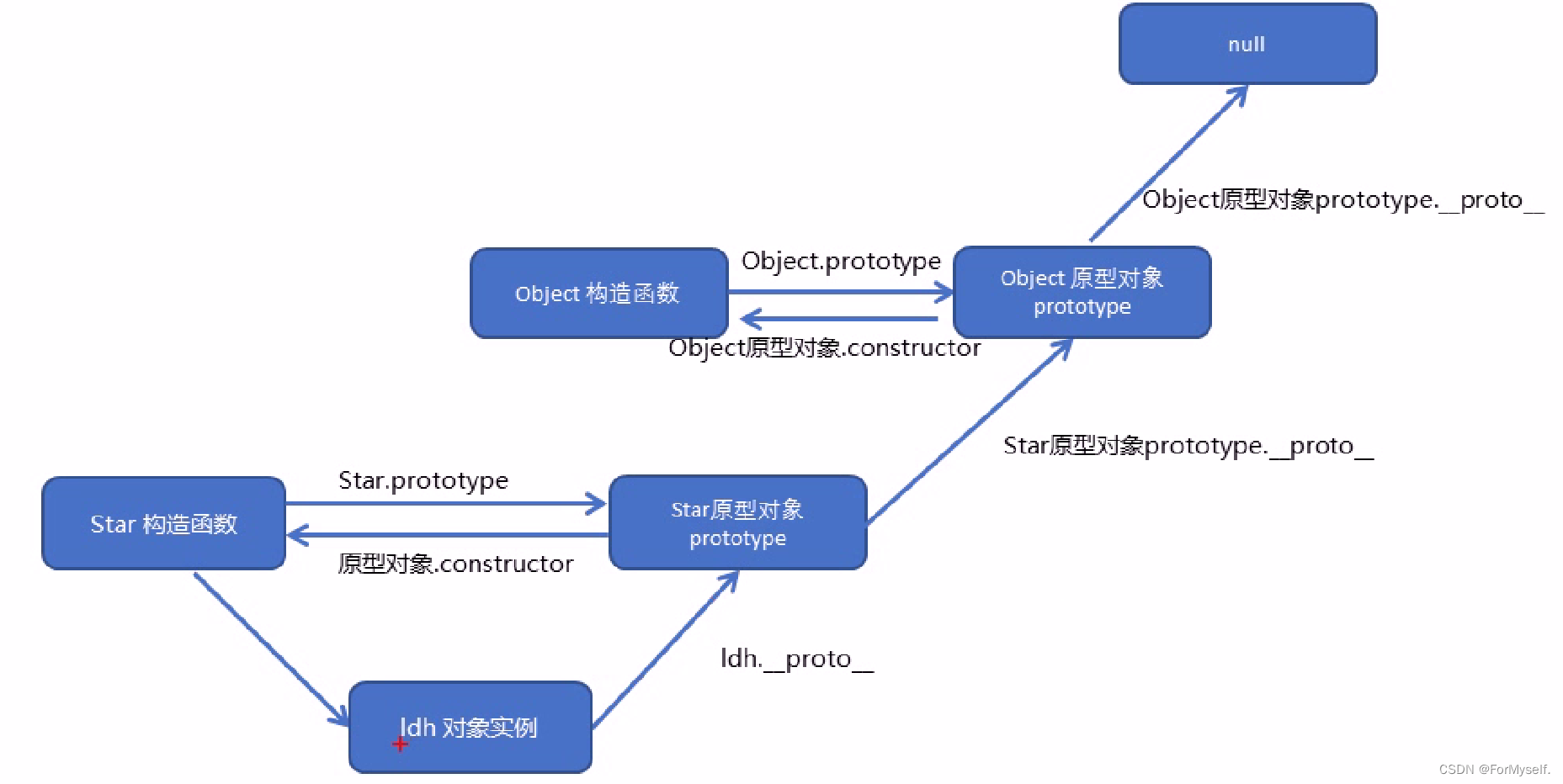
QRegExp
头文件:#include<QRegExp>
构造函数:

常用函数:
| indexIn() | 判断是否符合规则 |
| matchedLength() | 返回最后一个匹配字符串的长度,没有的话返回-1 |
| setPattern() | 将模式字符串设置为模式。区分大小写、通配符和最小匹配选项不会更改 |
| swap() | 交换正则表达式 |
| replace() | 替换字符 |
| setMinimal(bool) | 设置是否为贪婪 true为懒惰,flase为贪婪(默认) |
| setPatternSyntax(QRegExp::RegExp) | 设置正则语法模式 |
| pattern() | 返回该正则表达式 |
| exactMatch() | 返回字符串是否匹配,匹配返回true,不匹配返回false |
| cap() | 捕获(返回由第 n 个子表达式捕获的文本)第一个元素 cap(0) 是整个匹配字符串。每个后续元素对应于下一个捕获左括号。因此,cap(1) 是第一个捕获括号的文本,cap(2) 是第二个捕获括号的文本 |
| captureCount() | 返回正则表达式中包含的捕获数。 |
| captrueTexts() | 返回捕获的文本字符串的列表 |
| setCaseSensitivity(Qt::CaseInsensitive) | 设置不区分大小写 |
| pos() | 返回搜索字符串中捕获的第 n 个文本的位置 |
| escape() | 返回转义后的字符字符串 |
setPatternSyntax(QRegExp::RegExp)
| QRegExp::RegExp | 默认 |
| QRegExp::RegExp2 | 和第一个一样但有贪婪的量词 |
| QRegExp::Wildcard | 这提供了一个简单的模式匹配语法,类似于 shell |
| QRegExp::WildcardUnix | 这类似于通配符,但具有Unix shell的行为。通配符可以使用字符“\”进行转义。 |
| QRegExp::FixedString | 模式是一个固定字符串。这相当于在字符串上使用 RegExp 模式,其中所有元字符都使用escape() 进行转义 |
| QRegExp::W3CXmlSchema11 | 该模式是由 W3C XML 架构 1.1 规范定义的正则表达式。 |
c++使用 \d \w \s 这些需要使用转义字符 变为 \\d \\w \\s
QRegExp rx("^\\d\\d?$") //以两个数字为数字,第二个可以不用函数的使用:
indexIn()函数的使用
indexIn(constQString&str,intoffset= 0,QRegExp::CaretModecaretMode= CaretAtZero)
- str 需要匹配的字符串
- offset 偏移量默认为0, 0的话为第一个开始,-1从最后一个开始,-2倒数第二个开始
- 返回的结果 -1 不匹配 匹配的话返回匹配的位置
QRegExp exp("^\\d$|^[1-9][0-9]$|^100$");//匹配[0-100]
qDebug()<<exp.indexIn("-1");//不匹配
qDebug()<<exp.indexIn("0");
qDebug()<<exp.indexIn("50");
qDebug()<<exp.indexIn("100");
qDebug()<<exp.indexIn("200");//不匹配
setPattern()函数的使用
用来设置一个regexp
QRegExp exp("^\\d$|^[1-9][0-9]$|^100$");//匹配[0-100]
exp.setPattern("\\b12\\b");//输入一个regexp,匹配12
qDebug()<<exp.indexIn("mmm mmm 12");//位置为8
qDebug()<<exp.indexIn("mm 12");//位置为3
qDebug()<<exp.indexIn("12");//位置为0
qDebug()<<exp.indexIn(" 12");//位置为1
replace()函数的使用:
用来替换所匹配的字符
QRegExp exp("^\\d$|^[1-9][0-9]$|^100$");//匹配[0-100]
exp.setPattern("M(?!ail)"); //匹配字符,M后面不能跟有ail
QString str="abcdM";
str.replace(exp,"Mail");//把匹配到的字符替换为Mail
qDebug()<<str; ![]()
统计匹配的个数
exp.setPattern("\\bab\\b|\\bcd\\b");//匹配ab或cd
QString str1="ab cd ef g ab cd";
int pos=0;
int count=0;
while(pos>=0)
{
pos=exp.indexIn(str1,pos);获取匹配的索引
if(pos>=0)
{
++pos;//从匹配字符的下一个开始匹配
++count;//匹配成功,个数+1
}
}
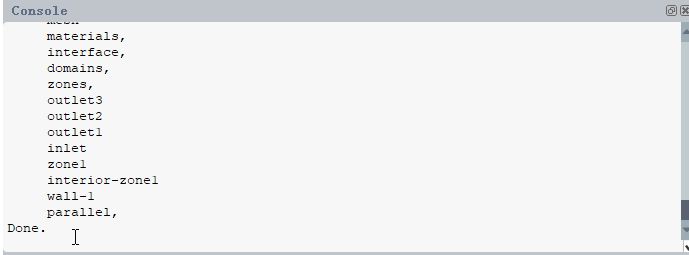
qDebug()<<count;//输出数量![]()
setPatternSyntax(QRegExp::RegExp)的使用
设置使用通配符
exp.setPattern("*.txt");//匹配.txt结尾的
exp.setPatternSyntax(QRegExp::Wildcard);//使用通配符
qDebug()<<exp.exactMatch("p.txt");//true
qDebug()<<exp.exactMatch("p.txt.p");//false
cap()捕获的使用
cap(0)表示完全匹配,会返回整个匹配结果,cap(1) 是第一个捕获括号的文本,cap(2) 是第二个捕获括号的文本
cap(0)cap(1)cap(2) 的区别
- 使用捕获的格式为:(E)
- 使用非捕获格式为:(?:E) 非捕获效率比捕获高
QRegExp exp2("(\\d+)(?:\\s*)(cm|inch)");
int p2=exp2.indexIn("Length:198cm");
if(p2>-1)
{
qDebug()<<exp2.cap(0);//输出全部匹配的内容
qDebug()<<exp2.cap(1);//输出第一个匹配的内容
qDebug()<<exp2.cap(2);//输出第二个匹配的内容
}
遍历:
QRegExp exp1("(\\d+)");
QString s1="1 2 3 45 678 999";
QString list;
int p1=0;
while((p1=exp1.indexIn(s1,p1))!=-1)//遍历整个字符串
{
list.append(exp1.cap(1));//第一个捕获到的文本
p1+=exp1.matchedLength();//获取上一个匹配的字符串长度
}
qDebug()<<list;
pos函数的使用:
QRegExp exp3("(\\d)\\s(\\d{2})");
qDebug()<<exp3.indexIn("as 1 2 34 56 er");//符合条件的位置
qDebug()<<exp3.pos(0);//符合条件的位置
qDebug()<<exp3.pos(1);//捕获1的位置
qDebug()<<exp3.pos(2);//捕获2的位置
escape()函数的使用
使用这函数方便了转义
qDebug()<<QRegExp::escape("123");//无需转义
qDebug()<<QRegExp::escape("()");//需转义
qDebug()<<QRegExp::escape("[]");//需转义
qDebug()<<QRegExp::escape("{}");//需转义
qDebug()<<QRegExp::escape("f(x)");//需转义
qDebug()<<QRegExp::escape("$");//需转义
setMinimal(bool)贪婪的使用
系统默认是贪婪的
- setMinimal(true)设置为懒惰
QRegExp exp4("(0+)");
int ppp=exp4.indexIn("00000");
if(ppp!=-1)
{
qDebug()<<exp4.cap(1);//输出结果为00000
}
exp4.setMinimal(true);//设为懒惰
int ppp1=exp4.indexIn("00000");
if(ppp1!=-1)
{
qDebug()<<exp4.cap(1);//输出结果为0
}