# 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周3 | 谈谈我在腾讯的架构设计经验
# 第4期 | 黄延岩:微信实验平台 - 全面拥抱湖仓时代


微信实验平台简介
微信实验平台主要提供微信内部各个业务场景(视频号、直播、搜一搜、公众号等)下的各类实验场景的支持,有 AB 实验、MAB 实验、BO 实验、Interleaving 实验、客户端实验、社交网络实验、双边实验等。
资源量级
微信实验平台承载的是全微信所有业务的实验场景下的指标计算及统计推断,业务有效指标个数达到了6w+,妥妥的资源使用大户,当前规模:
|
基于成本及稳定性、中心内业务建设等角度考虑,我们计算资源大多收敛在 Gemini(微信云原生大数据平台),天穹 Gaia(TEG 公司级大数据平台)计算资源做 Backup,当平台依赖计算集群有异常,可以进行任务层面的计算集群切换,使我们支持的业务用户影响范围最小化,存储资源则完全依赖于天穹。
选型分析
Iceberg、Hudi 以及 DeltaLake 是基本同时期出现的开源表存储格式项目,整体的功能和定位也是基本相同,也一定会前期百花齐放相互借鉴最终走向同质化,网上已经有很多相关对比介绍的文章,这里就不详细比较了。
我们选择 iceberg 作为 Lakehouse Table Format 的方案的主要原因是:
|
其他例如组件抽象更友好、更通用、pluggable 设计,向下支持的文件格式(Parquet/Orc/Avro)、存储类型(Object Storage/File Storage)更多,向上支持的计算引擎(Spark/Flink/Hive/Trino/Impala/SR…)更广泛,这些并不是我们业务方的主要考虑点。只要其与我们平台业务依赖的引擎框架都能足够兼容,生产环境稳定性可控、性能优异、解决方案优雅,即:在兼容我们已有技术架构下,优化现有流程,达到更快(计算时效性)及更省(节省更多资源)的目标。

基于 Iceberg Table Schema 建设优化
实验平台业务不是层级复杂、主题域多样的业务数仓建设场景,而是仅具备超大规模指标计算的单一场景。所以我们的工作重点也不在高效复杂的数仓建设上,而是在于大规模指标计算优化上。
实验平台指标计算一般分为两种类型的表,命中表:包含某个实验 ID 及命中 uin 信息的物理表, 业务表:业务配置的用于指标计算及后续假设检验的物理表, 一般命中表及业务表及相关的配置逻辑口径会组成具体的某个指标。
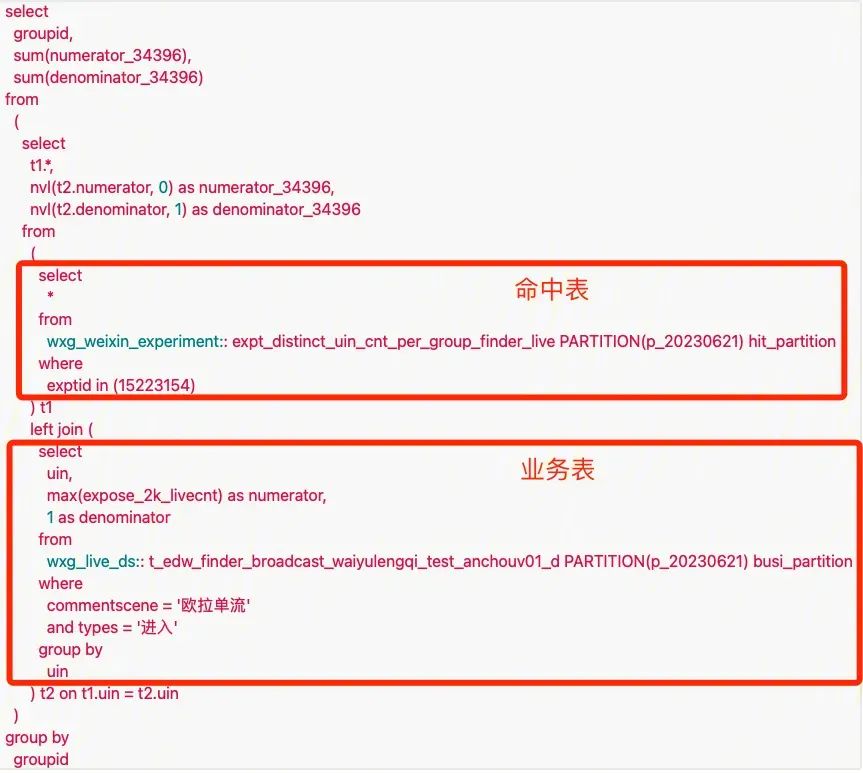
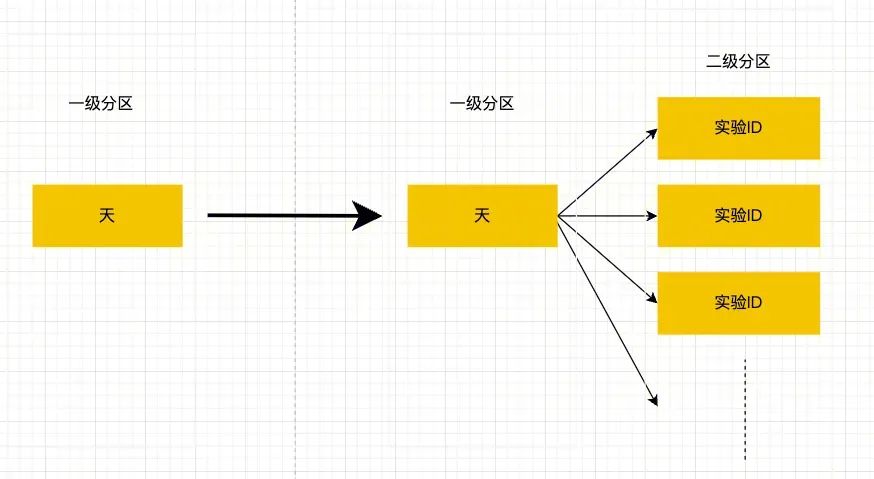
有经验的数仓同学基本都清楚,表 Schema 的建设优化,基本都在于分区、分桶、排序、索引等方面。
业务表在表 Schema 的优化上会依赖于业务数仓的建设,依托于业务方的能力,实验平台可控性并不强。命中表的 Schema 恰恰是平台建设优化的重点,一般某天的某个指标计算会绑定具体的实验 ID,很自然的会想到按天作为一级分区,实验 ID 作为二级分区,可以将可用数据最小化,降低后续指标计算的读表 IO/shuffle IO。可是难点在于之前依赖于THive的建设,命中表一般至少保留3个月,实验 ID 更是达到 2w 个,做笛卡尔积后分区个数可达180w,Thive的元数据体系会受限于单点数据库瓶颈,存在 OMS(厂版Hive metastore) RDBS 单点问题,经常会因为某个表元数据太多导致整个元数据库 OMS 负载高,导致 Thive 不可用,影响 THive 服务上所有业务方保证的 SLA,所以 Thive 一般无法做到此种分区结构。刚好 Iceberg 的出现,由于其基于 HDFS 的独立三层元数据体系,可以将元数据信息的压力从 OMS 分摊到 HDFS 上,规避 OMS 的单点瓶颈问题。
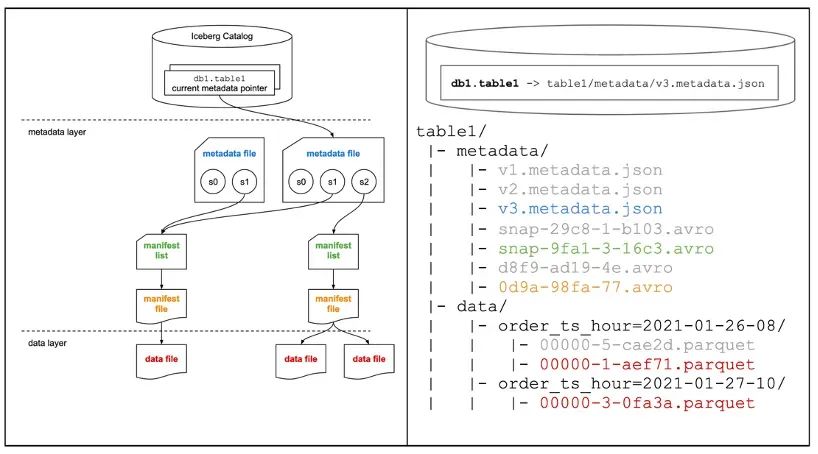
总结起来,其实就是利用 Iceberg 的三层元数据体系带来的灵活性,细化业务表多级分区,规避 OMS 受限于单点数据库 RDBS 瓶颈的问题,提升后续计算效率。但要注意的是,要考虑到 NameNode 的元数据膨胀的问题,单 HDFS 存储集群一般超过8亿 metadata file(目录+文件)则处于高负载,会对 HDFS 存储集群后续稳定性带来压力。
Merge into+Time travel 代替传统数仓拉链表
微信实验平台会有命中信息增量变更的场景,即数仓同学所熟悉的缓慢变化维问题。
Slowly Changing Dimensions:维度建模的数据仓库中的概念,在现实世界中,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。这种随着时间发生变化的维度我们一般称之为缓慢变化维,并且把处理维度表的历史变化信息的问题称为处理缓慢变化维的问题。 拉链表:记录历史数据,记录一个事物从开始一直到当前状态的所有变化的信息。处理缓慢变化维问题的典型方案,拉链表的 table schema 实现通常加入属性列 start_time,end_time 来标识对应维度记录的生效时间/生命周期,能够支持方便地分析出历史数据变化情况。 |
一般此类问题的传统解决方案都是基于 Hive 拉链表来实现的,来减少重复的冗余数据,Hive 拉链表虽然可以解决业务问题,但是效率和灵活性都较低。我们引入了高效的数据湖表格式 Iceberg 来解决相应问题,相比于朴素的 Hive 增加了很多变化和灵活性。
Hive 拉链表的方式来减少重复的冗余数据,记录加上 start_time,end_time 作为生效起止时间, 但是此种方式带来的新问题就是每日计算时都需要拉取全部数据读入进 MapReduce/Spark 等计算框架内,将新增数据处理后再写入,需要消耗的计算资源很大,如果数据量特别大也很容易导致集群负载压力过大使任务失败。并且在读取拉链表的时候也需要加过滤条件(where >=start_time and <end_time)会扫描过滤很多无关的数据,导致查询效率低下。
基于新的数据湖表格式 Iceberg 来更优雅地处理缓慢变化维问题,对比传统解决该问题基于 Hive 的拉链表方案的优势。归纳起来主要是通过如下方式实现:
使用 Merge Into 替代 Insert Overwrite
采用 Merge Into 进行增量数据批量变更(update/insert/delete)。
是通过重写相关文件,即包含在提交中需要更新的行的数据文件来支持 Merge Into,相对比于 Insert Overwrite 的方式,Iceberg 只替换受影响的数据文件来提升运行效率写入效率。
MERGE INTO iceberg_catalog.mmexpt_lakehouse.mmexpt_cumu_finder t
USING (select
first_hit_ds,uin,exptid,groupid,bucketsrc_hit
from
iceberg_catalog.mmexpt_lakehouse.mmexpt_daily_finder
) s
ON t.uin = s.uin and t.groupid = s.groupid
WHEN MATCHED AND s.ds < t.first_hit_ds THEN UPDATE SET t.first_hit_ds = s.ds
WHEN NOT MATCHED
THEN INSERT (first_hit_ds, uin, exptid, groupid, bucketsrc_hit, ext_int, ext_string)
VALUES (s.first_hit_ds, s.uin, s.exptid, s.groupid, s.bucketsrc_hit, null, null);使用 Time Travel Snapshot 代替拉链表冗余的记录有效起止时间 start_time,end_time 属性字段
可以使用 time travel in sql queries,比如查询2022-12-07 01:21:00 的历史状态,可以直接用。
-- time travel to 2022-12-07 01:21:00
SELECT * FROM mmexpt_lakehouse.table TIMESTAMP AS OF '2022-12-07 01:21:00';该种方式查询也会比拉链表减少很多处理数据量,不需要做有效时间字段的 filter(where >=start_time and <end_time),而是通过上层的元数据管理直接将相应天的数据文件拉出做计算。
另外由于厂内 iceberg 老版本还不支持 timestamp as of 等语法,iceberg/issues/270 我们给厂内数平同学单独提了issue,在 iceberg metadata 中加入了 custom-timestamp 结合 sql hint 来代替 timestamp as of 方式。后续我们计划应用 Iceberg 1.2.2 带来的 Branching and Tagging 来去做更优雅的 Snapshot Time Travel。
特殊情况处理
例如历史数据出错,则可以直接回滚到具体出错前的 snapshot。
让用户在每次提交的 snapshot 列表中切换,比如 version rollback,set snapshot id。
Roll back table db.sample to snapshot ID 1:
CALL catalog_name.system.rollback_to_snapshot('db.sample', 1)
Sets the current snapshot ID for a table.
CALL catalog_name.system.set_current_snapshot('db.sample', 1)然后数据修正后 commit 到其后的 snapshot 中。
总结起来,其实就是利用 Iceberg 的三层元数据体系带来的灵活性,可以解决 Hive 实现传统拉链表方式下的写入效率低,查询效率低,灵活性低,易用性低等问题。在特定业务超大拉链表的场景中,任务写入及查询效率都带来了指数级的提升。
针对此方案我们也申请了专利《一种基于数据湖表格式处理缓慢变化维问题的新方法》专利立项编号:2023010065CN
流批一体
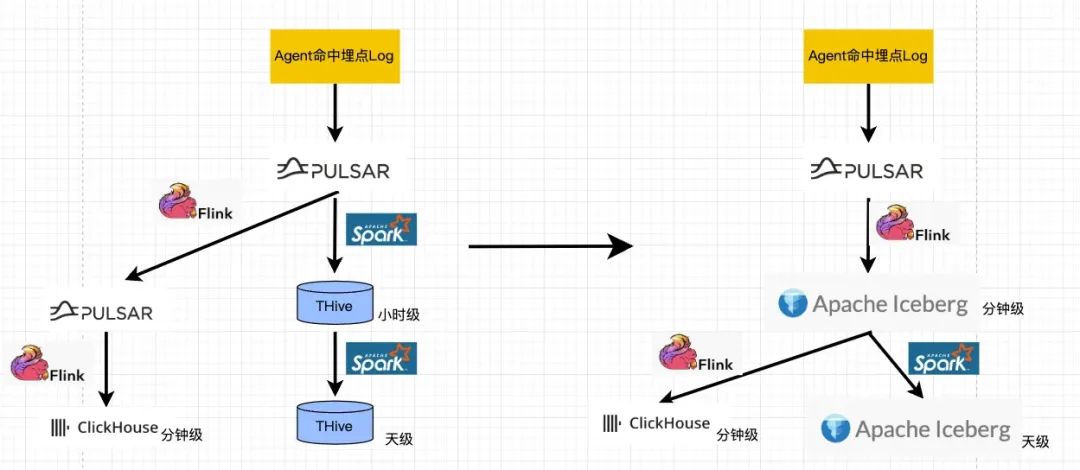
Iceberg 使 CDC 场景做分钟级写入成为可能,可以将 Iceberg 统一流批 Pipeline,作为公共上游,使代码复用,减少数据冗余,并从根源上规避数据不一致等问题。同时我们也希望精简全链路,过多的 step 会增加数据开发的成本,也会降低全链路的稳定性和可靠性。如上图所示,架构也会更加优雅。

在我们的使用实践过程中,发现 THive 兼容性不足,其中默认的 ORC 为厂内魔改版本,带来一定的对接使用隐患,比如 ClickHouse ORC 外表无法识别。ORC 魔改版本在 Spark 上的优化,也距离原生组件有些差距。
总结起来 Iceberg 方案的优势,对比太过朴素的 Hive,兼容性不足的 THive,Iceberg 带来的高级 Feature: 包括 ACID 粗粒度事务语义,可以避免脏读及下游失败等问题,借助于三层 Metadata 实现的 snapshot、time travel、schema evolution/partition evolution, row-level upsert/delete 等 feature 都带来了极致的灵活性。在业务升级、问题回滚相较于朴素的 Hive 带来了新的优雅的解决思路。配合异步 Auto-optimizing 服务优化数据存储组织方式(定期 compact 或进行合理排序和分组),提高查询效率,给我们带来很大收益。
我们已经将 20PB 的历史数据迁移到 Iceberg 库上,并且后续增量数据默认采用 Iceberg 作为数据基座。
结合社区开源版本优化红利,Spark 3.3全面接入(Gemini on Spark Oteam),带来的增强了 AQE(adaptive query execution) 能力,增加 row-level runtime filter 来补充 Dynamic Partition pruning 等 Feature,及 Iceberg 1.2.2的全面接入,我们从计算性能、存储占用两方面进行了优化的实践,最终效果为,计算上总核时优化69.4%,节省约20w 核时/天,存储空间上优化约100PB,总计折合降本预计约3kw/年。在降本的同时提升了离线计算的效率。计算任务 p99耗时减少70%, 平均任务耗时减少60%。

针对数据开发过程中的业务常见问题- 数据倾斜问题,小文件问题,随机性问题,我们都有遇到,并有一套解决方式供大家参考。
数据倾斜问题
分区数据倾斜
如上方案一描述的,我们采用实验 ID 作为二级分区,每个实验的命中流量都是不均匀的,尤其针对一些全流量的 holdout 实验,就针对写入 Iceberg 的 Stage 做了单独的大实验倾斜处理,在写入前的重分布过程中,加入了打散化处理。
val bucketIdHashUdf = udf((exptid: Long, uin: Long) => {
val maxExptIds: ListBuffer[Long] = maxExptIdsBroadCast.value
if (maxExptIds.contains(exptid)) {
exptid.toString + "_" + ((uin.hashCode() & Integer.MAX_VALUE) % 50)
} else {
exptid.toString
}
})
val icerbergDf = df
.withColumn("bucket_id", bucketIdHashUdf(col("exptid"), col("uin")))
.repartition(partitionNum, col("ds"), col("bucket_id"))
.sortWithinPartitions("ds", "exptid")Merge Into 写入倾斜
在 Iceberg TBLPROPERTIES 中加入了 Write Properties。
'write.distribution-mode' = 'range' -- Defines distribution of write data: none: don’t shuffle rows; hash: hash distribute by partition key ; range: range distribute by partition key or sort key if table has an SortOrder批写小文件问题
相对于实时场景下分钟级 commit 造成 snapshot 及 datafile 膨胀的问题,我们面对的场景是 batch 场景,基本为日度例行任务,需要合理配置 targetSizeInBytes,及合理控制 spark stage 的 partition number,来规避 batch 场景写入 iceberg 的小文件太多问题,即每个 spark 的 partition 都会写入 iceberg datafile 如果写入的 iceberg datafile < write.target-file-size-bytes 则直接写对应的文件,如果写入的 iceberg datafile > write.target-file-size-bytes 则会拆分多个文件 split 写入。
同时,因为我们的存储资源量级太大, 也跟数平运维同学,申请了专属独占的 HDFS 存储集群,来保证业务稳定性,避免 NameNode 过载导致文件读写延迟变大或者 Connect Fail Exception 等问题,并开通了存储集群 grafana 监控等权限,提前预知集群健康度对任务的影响。
随机性问题
预期中的 Spark 任务应该具有幂等性,即任务多次运行的结果应该完全相同,当出现结果不同的随机性问题时,就很难去回放数据。
Accumulator 带来的随机性问题
因为我们的超大任务规模比较大(单任务读写>20T),运行过程中因为机器的负载等问题,导致 task fail 甚至 stage fail 很正常,恰恰 fail 造成了 Accumulator 的数据运行不一致,spark document 上有注明。
For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will only be applied once, i.e. restarted tasks will not update the value. In transformations, users should be aware of that each task’s update may be applied more than once if tasks or job stages are re-executed.Accumulator 的更新应该在 action 算子中,而不应该在 transformation 算子中,来保证 Accumulator 的更新只会应用一次。
Random 处理数据倾斜带来的随机性问题
处理数据倾斜时,常用的方案为在倾斜 key 上加入随机数来进行打散,但是这种处理方式在 Shuffle Fail 进行 retry 时,数据会被不同的 task 重复 fetch,导致引入随机性问题。小任务不太容易出现 Shuffle Fail 的问题,超大任务或者集群负载水位较高时,则更容易触发此类问题,应该用取模或者哈希之类的幂等函数来打散倾斜的 Key,规避此类随机性问题。
其他思考
另外关于其他 Iceberg Data Skipping 层面的排序、索引等数据组织上优化的考虑,我们也做了一些思考。
如前面提及的,实验平台业务不是层级复杂、主题域多样的业务数仓建设场景,而是仅具备超大规模指标计算的单一场景。所以我们的工作重点也不在高效复杂的数仓建设上,而是在于大规模指标计算优化上。业务上决定了我们没有字段点查的场景,所以并没有使用 bloom filter、bitmap filter 等字段索引 feature,仅使用 Iceberg 默认存储文件级别每列的 Min、Max 信息,并用于 TableScan 阶段的文件过滤。Z-Order 对我们业务场景收益不大,没有太多的基于某个表的多个常用字段进行 filter 的 data-skipping 需求。

StarRocks+Iceberg 更好的湖仓融合
我们的实时指标计算场景,我们没有复杂的 ETL pipeline,主要利用 OLAP(StarRocks/ClickHouse)等 SQL 表达能力强的引擎,作为实时指标计算的依赖引擎,而非 Flink/Structured Streaming 等可编程能力强的计算框架。
ClickHouse 是性能优秀的 OLAP 引擎,但是 Clickhouse sql 表达及优化能力,普适性不足。为了解决 clickhouse shuffle 问题及冷数据复用避免转移到 cos 等对象存储, 实现极速的 SQL on Iceberg,更好的 Ad Hoc Analysis 体验,我们后续的实时湖仓方案会采用 StarRocks 3.x + Iceberg,便于湖仓融合。
StarRocks 既能兼容 TPC-DS Benchmark 的语法,在 ClickBench Benchmark(https://benchmark.clickhouse.com/) 打榜上和 Top 1的 Clickhouse 性能极其接近,更注定了 StarRocks 发展上限很高。

硬件层面计算框架加速
我们的业务更多 focus 在计算框架层的参数优化,和实现逻辑优化,希望可以优化到极致。从另一个视角思考,硬件层面加速计算过程,对我们的 Gemini 微信云原生大数据平台依赖的 CVM,相同成本下 1T SSD 云盘替换为8块 500G 高性能云硬盘做 RAID-0,因为高性能云硬盘本身就是采用3副本来保证数据高可用,做 RAID-0后可用性也是完全可以接受,同时 IO 吞吐可以翻4倍(SSD 275MB/s, 8块云硬盘做 RAID-0 吞吐量能达到 1GB/s),由于离线计算框架更多使用顺序读写,该方案在实施中,预期收益明显。
Steaming Lakehouse
伴随着社区 Apache Paimon 的孵化,我们也希望流批一体架构变得更简洁,在保证性能的前提下,忽略掉流存储 MQ 和湖存储 Table Format 的差异,可以对外作为一个统一组件供业务使用,追求批流一致性语义,提供实时离线一体化的开发体验。
以上就是微信实验平台改造的过程与结果,如果文章对你有帮助,欢迎转发分享。
-End-
原创作者|杨波
📢湖仓一体有哪些优势,你对这个技术有什么看法?欢迎留言。我们将挑选一则最有意义的评论,为其留言者送出腾讯定制-便捷通勤袋1个(见下图)。8月30日中午12点开奖。






关注并星标腾讯云开发者
第一时间看鹅厂架构设计经验