FCAF3D数据和源码配置调试过程请参考上一篇博文:【三维目标检测】FCAF3D(一)_Coding的叶子的博客-CSDN博客。本文主要详细介绍FCAF3D网络结构及其运行中间状态。
1 模型总体过程
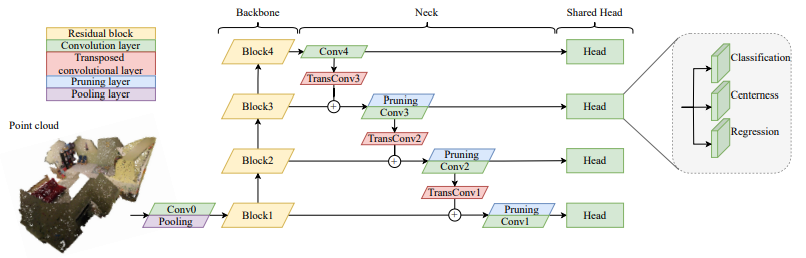
FCAF3D模型的整体结构如下图所示。该模型属于anchor-free目标检测算法。FCAF3D主干网络采用的是典型的ResNet34 FPN结构。该结构采用了三维稀疏卷积进行计算,计算过程中得到的非稀疏点作为Head预测的种子点。FPN层实现了四种不同特征尺度下的预测,各种尺度下的特征维度分别为64、128、256和512。各种尺度特征采用相同形式的Head结构分别完成目标类别、中心度和目标框位置的预测。

2 主要模块解析
2.1 输入数据
输入数据维度为Nx6,这6个维度分别为坐标x、y、z和色彩r、g、b,且N=100000。输入数据经MinkowskiEngine引擎转为稀疏表达,体素尺寸为0.01m。经过稀疏表达之后,体素坐标coordinates构成维度为batch_id、x、y、z,体素特征features构成维度为r、g、b。由于涉及到体素化操作,点的数量会发生变化,假设由N变到M。
#points Nx6 N=100000 xyzrgb
x = self.extract_feat(points)
coordinates, features = ME.utils.batch_sparse_collate([(p[:, :3] / self.voxel_size, p[:, 3:]) for p in points], device=points[0].device)
#coordinates为体素坐标,体素大小为0.01m ,Mx4,[batch_id x y z]
#features为rgb取值
x = ME.SparseTensor(coordinates=coordinates, features=features) #稀疏表达2.2 主干网络backbone
主干网络采用的是典型的残差网络ResNet34,共34层卷积或池化操作。和普通二维ResNet相比,所用结构最大区别在于使用了三维稀疏卷积,并通过MinkowskiEngine引擎实现,因而模型中定义其名称分别为MinkResNet、MinkowskiConvolution和MinkowskiMaxPooling。
主干网络输出4种不同尺度特征,分别为M3x64、M4x128、M5x256和M6x512模型主要过程如下:
self.backbone(x)、Mx3、Resnet34、MinkResNet
MinkowskiConvolution(in=3, out=64, kernel_size=[3, 3, 3], stride=[2, 2, 2], dilation=[1, 1, 1]) M1X64
MinkowskiMaxPooling(kernel_size=[2, 2, 2], stride=[2, 2, 2], dilation=[1, 1, 1]) M2X64
Layer1 [(64, 3), (64, 3)] *3 stride 2 -> M3 x 64,x1
Layer2 [(128 , 3), (128, 3)] *4 stride 2 -> M4 x128,x2
Layer3 [(256 , 3), (256, 3)] *6 stride 2 -> M5 x256,x3
Layer4 [(256 , 3), (256, 3)] *3 stride 2 -> M6 x512,x42.3 特征金字塔FPN
特征金字塔FPN一方面为Head提供不同尺度的特征图,另一方面实现了浅层和深层之间的特征融合。特征融合主要包括上采样和融合两个步骤。上采样是为了使深层特征和浅层特征具备相同的特征维度以便后续进行融合,其可通过插值或反卷积实现。
以深层特征x4为例,其特征维度为M6 x 512,经过反卷积MinkowskiGenerativeConvolutionTranspose(512, 256)和卷积MinkowskiConvolution(256, 256)得到上采样后特征(M7x256)。上采样后特征与前一层特征x3直接叠加得到新的融合特征(M7x256)。FCAF3D对融合后的特征还做了一次prune裁剪操作。假设经过裁剪后的点云特征维度仍为M7x256,该特征作为第3层的输出特征。
通过特征金字塔操作,FCAF3D得到了四种不同尺度特征,即M6x512、M7x256、N8x128、M9x64,这里统一用MxF来表示。融合后特征经过卷积MinkowskiConvolution(F, 128)再次进行一次特征提取并得到FPN最终输出M6x128、M7x128、M8x128、M9x128。
关键程序如下。
x4 MinkowskiConvolution(in=512, out=128, kernel_size=[3, 3, 3], stride=[1, 1, 1], dilation=[1, 1, 1]) x5 M6x128
scores = self.conv_cls(x) M6x5 分类分数,共5个类别
prune_scores = ME.SparseTensor(scores.features.max(dim=1, keepdim=True).values)
MinkowskiGenerativeConvolutionTranspose(in=512, out=256, kernel_size=[2, 2, 2], stride=[2, 2, 2], dilation=[1, 1, 1]) 上采样
MinkowskiConvolution(in=256, out=256, kernel_size=[3, 3, 3], stride=[1, 1, 1], dilation=[1, 1, 1])
M7 x 256
x = inputs[i] + x#特征融合
x = self._prune(x, prune_score)#点云裁剪
MinkowskiGenerativeConvolutionTranspose(in=256, out=128, kernel_size=[2, 2, 2], stride=[2, 2, 2], dilation=[1, 1, 1]) M7x128 特征提取2.4 FCAF3D Head
FCAF3D Head分别对FPN层输出的4种不同尺度特征经过卷积操作得到目标中心度、分类得分和位置预测。Head结果输出如下,每个都对应了4种不同尺度,其中points是稀疏卷积操作后得到的非稀疏点坐标,也作为预测的种子点。
center_preds [M9x1、M8x1、M7x1、M6x1]
bbox_preds [M9x6、M8x6、M7x6、M6x6]
cls_preds [M9x5、M8x5、M7x5、M6x5]
points [M9x3、M8x3、M7x3、M6x3]关键程序如下
中心度Head:
center_pred = self.conv_center(x).features Mx1
MinkowskiConvolution(in=128, out=1, kernel_size=[1, 1, 1], stride=[1, 1, 1], dilation=[1, 1, 1])
分类Head:
scores = self.conv_cls(x)
MinkowskiConvolution(in=128, out=5, kernel_size=[1, 1, 1], stride=[1, 1, 1], dilation=[1, 1, 1]) M6x5
位置Head:
reg_final = self.conv_reg(x).features Mx6
MinkowskiConvolution(in=128, out=6, kernel_size=[1, 1, 1], stride=[1, 1, 1], dilation=[1, 1, 1])2.5 损失函数
2.5.1 标签计算
标签计算过程中需要为上述不同尺度下的各个点points赋予真实标签。有效的预测点(种子点),即存在真实标签与之对应,必须满足如下条件:
- 点所在特征尺度下,某一真实标注框在该尺度下必须有pts_assign_threshold(27)个点在框内。
- 每个真实框可能存在多个尺度满足(1)中要求,采用特征尺度最大的作为best_level。
- 点需要要在某一真实目标框内。
- 计算满足上述条件中各个点的中心度,每个真实框最多选择18个中心度较大的种子点。
- 针对中心度满足要求的种子点,如果种子点同时满足多个真实框要求,那么仅预测体积最小的真实框。
计算步骤如下:
- 计算点是否在目标框内。
- 计算在各个尺度下属于某一真实目标框中的点个数,选择点数满足阈值要求的点。
- 保留最佳尺度best_level下对应的点。
- 针对每个真实目标框最多选择18个中心度较大的种子点。
- 针对上述满足要求的种子点,选择最小真实目标框体积的目标标签。
- 根据(5)中的标签得到中心度标签center_targets(不满足要求的点设置为-1), 候选框标签bbox_targets(6个维度,不含方向),类别标签cls_targets(不满足要求的点设置为-1)。
2.5.2 损失计算
模型预测结果主要包含三部分:目标类别、中心度、位置。输入数据包含5个类别,且目标类别的损失函数为FocalLoss。目标中心度和bbox位置的损失函数分别为CrossEntropyLoss和AxisAlignedIoULoss。
关键程序如下:
正样本:类别标签cls_targets≥0的种子点,数量n_pos
cls_loss = self.cls_loss(cls_preds, cls_targets, avg_factor=n_pos) FocalLoss()
仅对正样本进行中心度和位置回归损失计算
pos_center_preds = center_preds[pos_inds]
pos_bbox_preds = bbox_preds[pos_inds]
pos_center_targets = center_targets[pos_inds].unsqueeze(1)
pos_bbox_targets = bbox_targets[pos_inds]
center_denorm = max(reduce_mean(pos_center_targets.sum().detach()), 1e-6)
center_loss = self.center_loss(pos_center_preds, pos_center_targets, avg_factor=n_pos) CrossEntropyLoss
bbox_loss = self.bbox_loss(self._bbox_to_loss(self._bbox_pred_to_bbox(pos_points, pos_bbox_preds)), self._bbox_to_loss(pos_bbox_targets), weight=pos_center_targets.squeeze(1), avg_factor=center_denorm) AxisAlignedIoULoss()2.6 顶层结构
顶层结构主要包含以下三部分:
- 特征提取:采用ResNet34 FPN模型结构提取4种不同尺度的特征尺寸,输出结果见2.3节。
- FCAF3D Head:结果预测,见2.4节。
- 损失函数:见2.5节。
def forward_train(self, points, gt_bboxes_3d, gt_labels_3d, img_metas):
x = self.extract_feat(points)
losses = self.head.forward_train(x, gt_bboxes_3d, gt_labels_3d, img_metas)
return losses3 训练命令
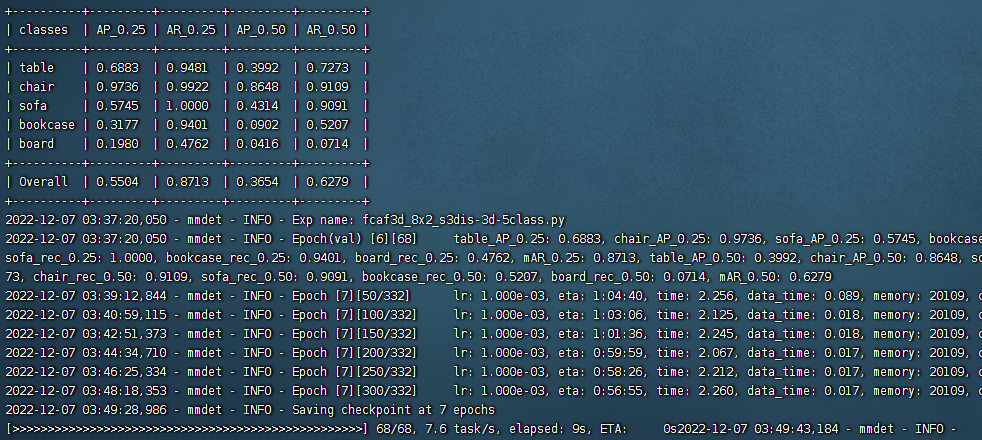
python tools/train.py configs/fcaf3d/fcaf3d_8x2_s3dis-3d-5class.py4 运行结果