文章目录
- List\<T\>/LinkedList \<T\>为什么是神?(泛型为什么是神)
- 一些常见,通用的委托和接口
- `Comparison`
- `Enumerator`
List<T>/LinkedList <T>为什么是神?(泛型为什么是神)
List<T>为什么是神?在谈论这个问题之前,我想先说说其他数据表结构相较于List<T>究竟差在了哪里……
首先是HashTable
本身呢就被Dictionary<TKey,TValue>完爆,HashTable既不是线程安全的,也不是类型安全的,虽然提供了Synchronized()方法可以获取线程安全的类型,以为自己是个哈希表就可以为所欲为了,但这种挑战神的行为导致最终降下了神罚,最后几乎被HasSet<T>所取代。HashSet<T>的Contains方法复杂度是O(1),List<T>的Contains方法复杂度是O(n)。HashSet还是线程安全和类型安全的。而且HashSet<T>是专门设计用来做集合运算(取交集,并集等),所以提供了UnionWith、IntersectWith等方法。无论从方方面面来看HashTable都比不上HashSet<T>。
然后是Array数组类型
竟然还胆敢在神的面前跳脚,仗着自己老前辈的身份倚老卖老,连插入删除都如此困难,除了因为随机存取查找复杂度低以外一无是处。完全不适合作为存储表的对象,没有动态变长的东西!
接着是ArrayList
Array自以为换个马甲就好使了。ArrayList是类型不安全的,虽有线性表的优点,但是类型不安全,内部默认装的是object类型的,导致它存取时存在装箱拆箱的操作。没有泛型,狗都不用。
List<T>的优点
List<T>是谦卑的,虽然HashSet<T>拥有更高的效率,但是它是一个使用哈希表的集结构,不允许出现重复元素,因此和表在定位上还是有区别的,所以神不会和他计较。作为表结构,无论是线性表的List<T>还是链表的LinkedList<T>,神已经赢了太多太多了。而对于Dictionary<K,V>,神慈悲地包容了它,可以使用ToDictionary ()方法转换为Dictionary(using System.Linq)。而Dictionary中的键或者值也可以通过ToList()方法转换为List<T>。
因此,线性表请认准List<T>,链表则使用LinkedList<T>,字典请使用Dictionary<K,V>。哈希表/数据集请使用HashSet<T>
只查找,首选List;
插入为主,查找和删除为辅,首选LinkedList;
删除为主,查找和插入为辅,首选Dictionary;
想要效率高,泛型不可少。不使用泛型的数据类还是往后稍稍吧。
一些常见,通用的委托和接口

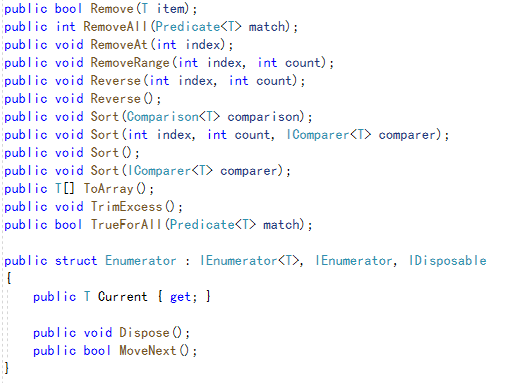
List中提供了许多方法,通过方法名我们一眼就知道这些方法是干什么的了,你可能注意到了其中重载的一些用于接受接口和泛型委托的方法,例如public void Sort(Comparison<T> comparison);,public void Sort(IComparer<T> comparer);这些。此处需要介绍两个比较常用的委托(接口):Comparison,Enumerator。
Comparison
Comparison——比较器,对应的接口是IComparer,IComparer接受两个同类型变量的比较,这两个变量一个叫左值x,一个叫右值y。
比较器的返回值是int,默认地,如果左值大于右值,那么比较器的返回值是>0的,而如果右值大于左值则返回值<0。左右值相等则等于0。
在C#中list提供了这个方法:
public void Sort(Comparison<T> comparison);
public void Sort(int index, int count, IComparer<T> comparer);
public void Sort();
public void Sort(IComparer<T> comparer);
这是个用于list的默认排序方法,当我们直接调用排序的时候,将会自动地对内部数据进行升序排序:
List<int> list = new List<int>();
list.Add(1);
list.Add(3);
list.Add(2);
list.Add(6);
list.Add(4);
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i]);
}
// 输出:1 3 2 6 4
list.Sort();
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i]);
}
// 输出:1 2 3 4 6
那么如果我们想要实现降序排序怎么办呢?我们就可以使用这个委托来解决,刚才我们说,在委托中左值大于右值,那么比较器的返回值是>0的,而如果右值大于左值则返回值<0。左右值相等则等于0。那么如果我们改变了默认委托的返回值,使得左值大于右值时返回值为<0不就可以实现降序排序了吗:
void Start()
{
List<int> list = new List<int>();
list.Add(1);
list.Add(3);
list.Add(2);
list.Add(6);
list.Add(4);
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i]);
}
// 输出:1 3 2 6 4
list.Sort(Desc);
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i]);
}
// 输出:6 4 3 2 1
}
public int Desc(int x, int y)
{
if (x > y)//修改委托的返回值逻辑
{
return -1;
}
else
{
return 1;
}
}
甚至我们还可以根据自己的需求来修改排序,例如我希望右值为3的时候返回0:
public int Desc(int x, int y)
{
if (y == 3)
{
return 0; //虽然可以自定义,但并无卵用,Sort方法使用的据说是快速排序加堆排序
// 除非你真的很了解源码,不然最后结果是怎么样就不晓得了
}
if (x > y)
{
return -1;
}
else
{
return 1;
}
}
// 排序后输出: 3 6 4 2 1
同样我们也支持匿名函数,使用lambda表达式和三目运算符来实现匿名函数的最简化:
list.Sort((x, y) => { return x > y ? -1 : 1; });
那么既然List可以接受泛型,当然也能接受类,我们可否直接对类进行排序呢?答案是不行的:
public class Item
{
int Money;
public Item(int i)
{
Money = i;
}
}
void Start()
{
List<Item> list = new List<Item>();
Item item1 = new Item(1);
Item item2 = new Item(3);
Item item3 = new Item(2);
Item item4 = new Item(6);
Item item5 = new Item(4);
list.Add(item1);
list.Add(item2);
list.Add(item3);
list.Add(item4);
list.Add(item5);
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i].Money);
}
list.Sort();// 报错,不是可比较类型
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i].Money);
}
}
之所以无法进行比较,是因为我们所定义的这个Item类并没有继承IComparable接口,如果我们想要类可比较,有两种方法:第一种就是像我们刚才讲的,为委托重写写一个接受两个Item类型参数的返回值为int类型的函数,以比较它们的money属性:
void Start()
{
/*省略部分重复代码 */
list.Sort(Desc);
}
public int Desc(Item x, Item y)
{
if (x.Money > y.Money)
{
return -1;
}
else
{
return 1;
}
}
但是这样的话有几个问题,首先因为函数是定义在类外的,如果需要我们比较的是一个私有变量那这个方法就不可行了;其次,把比较的方法暴露在外面也不符合我们封装的初衷。
另一个更好的做法是让类继承IComparable<T>接口(特别注意要继承带泛型的接口而不是接受object的IComparable,避免装箱拆箱),那么list就能自动传入比较的方法:
public class Item : IComparable<Item>
{
int Money;
public Item(int i)
{
Money = i;
}
public int CompareTo(Item other)
{
if (this.Money > other.Money)
{
return 1;
}
else
{
return -1;
}
}
public int GetMoney()
{
return this.Money;
}
}
void Start()
{
List<Item> list = new List<Item>();
Item item1 = new Item(1);
Item item2 = new Item(3);
Item item3 = new Item(2);
Item item4 = new Item(6);
Item item5 = new Item(4);
list.Add(item1);
list.Add(item2);
list.Add(item3);
list.Add(item4);
list.Add(item5);
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i].GetMoney());
}
// 输出: 1 3 2 6 4
list.Sort();
for (int i = 0; i < list.Count; i++)
{
Debug.Log(list[i].GetMoney());
}
// 输出: 1 2 3 4 6
}
使用上述的代码,我们就实现了很好的封装,既能保证money是一个私有的变量,又可以实现list中对item类的排序。
Enumerator
Enumerator——枚举器,当我们需要遍历某个数据结构的时候,往往需要用到枚举器。通常一些数据类继承了IEnumerator接口,我们可以用其中的GetEnumerator()方法来实例化这个枚举器:
IEnumerator enumerator = list.GetEnumerator();
使用枚举器可以遍历整个数据结构,其中枚举器提供了三个成员:MoveNext,Current,Reset:
public interface IEnumerator
{
object Current { get; }
bool MoveNext();
void Reset();
}
当使用枚举器的时候,这样遍历:
public class Item : IComparable<Item>
{
int Money;
public Item(int i)
{
Money = i;
}
public int CompareTo(Item other)
{
if (this.Money > other.Money)
{
return 1;
}
else
{
return -1;
}
}
public int GetMoney()
{
return this.Money;
}
}
void Start()
{
Initiate();
IEnumerator enumerator = list.GetEnumerator();
while (enumerator.MoveNext())
{
Item newitem = (Item)enumerator.Current;
Debug.Log(newitem.GetMoney());
}
enumerator.Reset();
// 输出: 1 3 2 6 4
}
通过枚举器也可以实现遍历,问题在于枚举器的返回类型是object,这又避免不了装箱拆箱操作了。
我们也可以直接使用List内部提供的枚举器,这个枚举器是可以立即释放的,因为它继承了IDisposable接口:
public struct Enumerator : IEnumerator<T>, IEnumerator, IDisposable
{
public T Current { get; }
public void Dispose();
public bool MoveNext();
}
只需使用using即可在使用完毕之后将其立即释放,实际上直接使用内部提供的枚举器反而更好,因为list内部的枚举值Current返回类型是对应的泛型而非object:
using (var enumerator = list.GetEnumerator())
{
while (enumerator.MoveNext())
{
// 由于返回值是泛型类型,所以可以直接调用方法而无需拆箱
Debug.Log(enumerator.Current.GetMoney());
}
}
enumerator.Reset(); // 编译错误,在using语句块外对象已经被销毁
你可能也注意到了,在编译器中提供了两个很相似的接口:IEnumerable和IEnumerator。根据词性我们知道,前者是可枚举的意思,后者是枚举器。当一个类继承了IEnumerable<T>的接口时,实现的接口方法会提供GetEnumerator(),需要实现IEnumerable以及IEnumerable<T>的接口,并返回对应枚举器。当一个类继承了IEnumerable的时候,我们才可以使用foreach来进行遍历。
以下摘自「Unity3D」(6)协程使用IEnumerator的几种方式
除此之外,你可能也发现了,IEnumerator正是协程定义时的关键字,有意思的是协程的执行正是通过枚举器实现的,每个定义的单个协程其实正式的名称是Routine例程,不同Routine之间协同执行,就是Coroutine协程。这个Routine需要能够分步计算,才能够互相协作,不然一路执行到底,就是一般函数了。而IEnumerator接口恰恰承担了这个分步计算的任务。每次执行就是一次MoveNext(),并且可以通过Current返回执行中的结果。
所以,带有yield指令的IEnumerator的函数,最终会被编译成一个实现了IEnumerator接口的类,这是C#自带的功能。
经过多日对C#的学习,我已经被其深深地折服,java的特性,python的灵活,c++的花里胡哨,所有语言之主,唯一真神。厦门!🙏