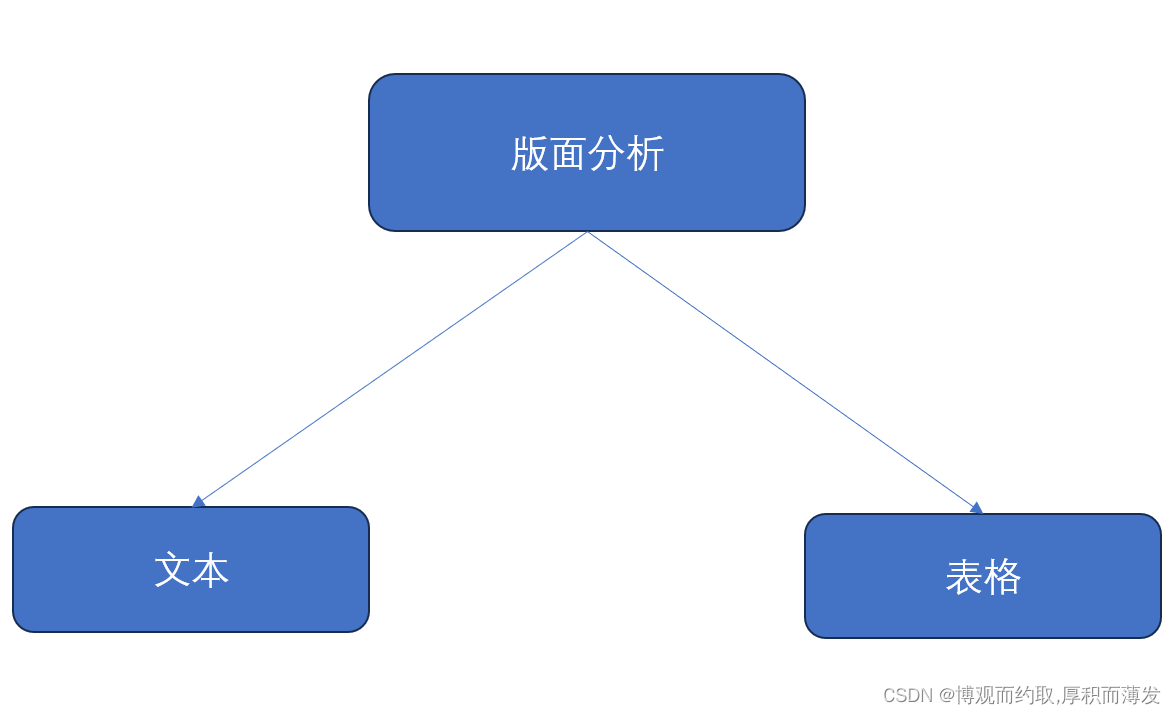
1、版面分析
使用轻量模型PP-PicoDet检测模型实现版面各种类别的检测。
数据集:
英文:publaynet数据集的训练集合中包含35万张图像,验证集合中包含1.1万张图像。总共包含5个类别。
中文:CDLA据集的训练集合中包含5000张图像,验证集合中包含1000张图像
2、文本分析
文本检测:改进了基于分割的DBNet (Differentiable Binarization)
数据集:ICDAR 2015 数据集包含1000张训练图像和500张测试图像。
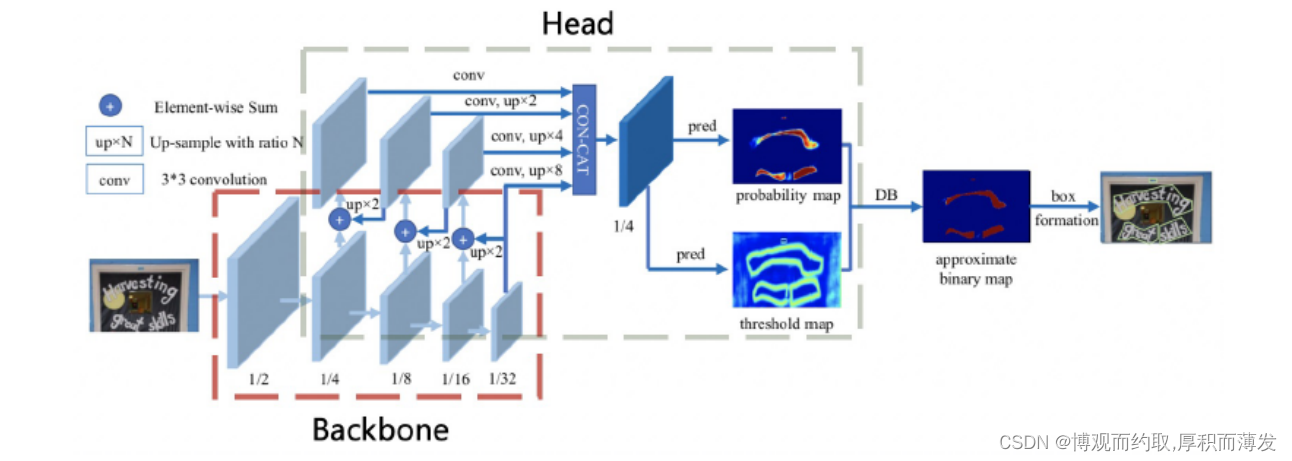
文本识别:SVTR_LCNet(将基于Transformer的SVTR网络和轻量级CNN网络PP-LCNet 融合的一种轻量级文本识别网络)
数据集:
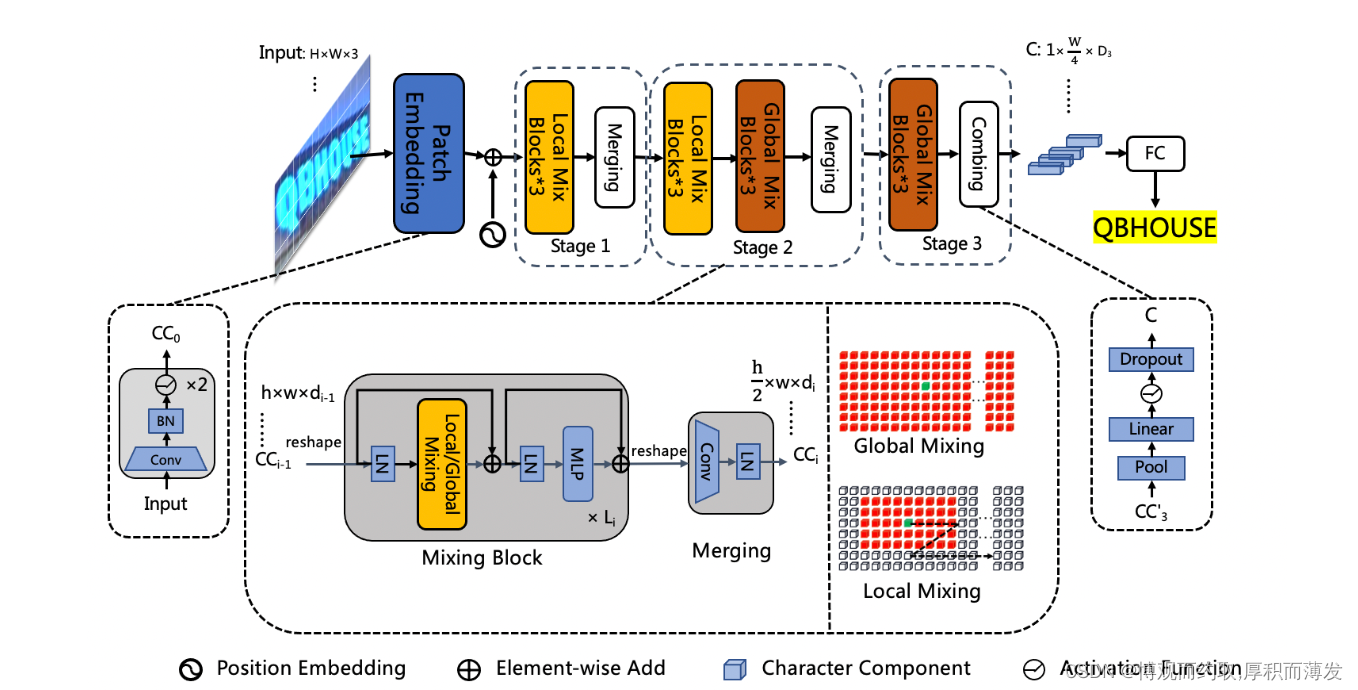
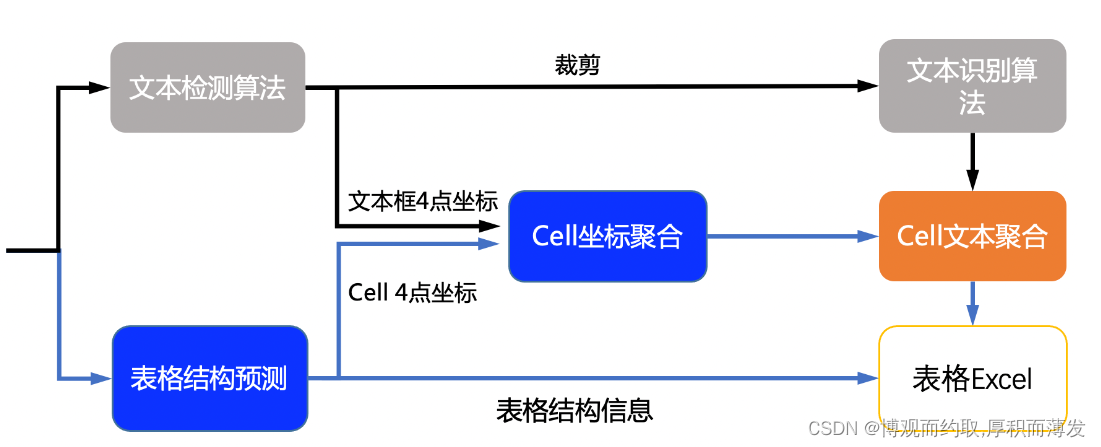
3、表格
1. 文字检测模型:用于检测表格里的文本
2. 文字识别模型:用于对检测到的文本进行识别
3. SLANet模型用于预测表格结构的HTML信息和表格单元格坐标
数据集:
PubTabNet数据集的训练集合中包含50万张图像,验证集合中包含0.9万张图像
好未来表格识别竞赛数据集的训练集合中包含1.6万张图像。验证集未给出可训练的标注。



![牛客复盘] 2023河南萌新联赛第(七)场:信息工程大学 B\I 20230823](https://img-blog.csdnimg.cn/fb038d556d6c481893474a67b28ef153.png)