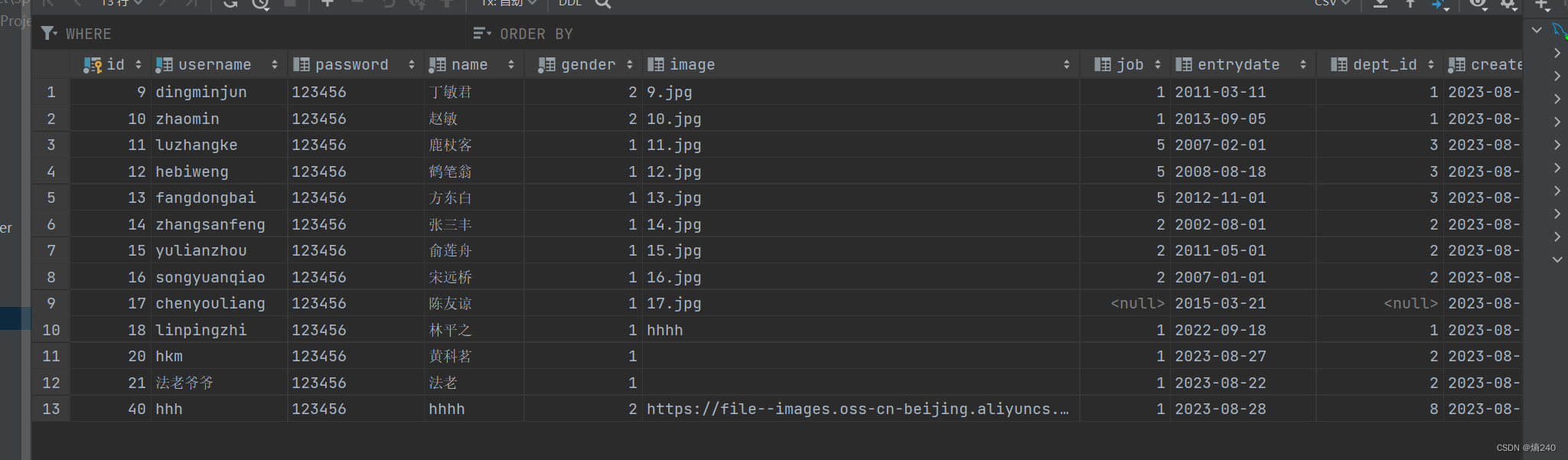
卷友们好,我是rumor。
对于怎么实现AGI这个玄学的目标,感觉大家都是差不多的状态:咱也不知道怎么做,但就是觉得现在的LLM技术还远远不够。
所以之前看到OpenAI说要用模型去做对齐研究[1],以及最近发话要4年内做出SuperAlignment[2]时,我都是一脸问号,觉得没什么新东西,get不到他们的思路。

为什么要做AI研究器
直到最近断断续续刷了两遍Jan Leike的访谈,我突然有种悟了的感觉,原来核心思想就这么简单。而且回过头看,OpenAI近几年其实就是在遵循这个思想,却做出了看似「暴力」的一个个突破。
OpenAI所选择的路径就是:「Turn compute into alignment」,通过计算的量变产生智能的质变。计算需要数据、算力、模型框架的共同作用,拆解成具体的步骤,则是自动化->规模化->迭代。
以前我们总以「范式」这个词来划分NLP的发展,比如监督学习->预训练+精调->预训练+RLHF。其实这些范式只是增加有效计算量的方法:
自动化:有监督 -> 自监督,摆脱人的依赖,更高效地获取监督信号
规模化:在更多的数据、更大的模型上进行更多的计算
迭代:不断基于新的case迭代模型,形成数据飞轮
自动化和规模化所带来的质变不用多说,GPT系列足以证明。但最后一步的「迭代」却经常被忽视,而这可能是通向Superalignment重要的一步,Alpha GO就是最好的栗子。 它从最开始模仿人类棋手落子,到具备基本能力后不断自我博弈,最终超越人类棋手。
那么问题来了:目前我们所做的「迭代」,不管是RLHF还是纯SFT,仍旧需要人工提供监督信号,无法做到自动化和规模化,迭代速度就会很慢。同时人类也无法监督超越自身水平的任务,不可能训出超智能的模型。这就是为什么OpenAI从22年就开始说,要用AI来辅助人类进行评估[3]。
继续思考,如果有个模型可以给出等同人类水平的监督信号,我们除了评估还可以用它干什么?当然是顺着量变产生质变的思想,让它自动化、规模化地帮忙迭代出AGI呀!
自动化:让AI研究器自动规划实验、提供监督信号训练模型
规模化:把上述自动流程扩展
迭代:AI研究器本身也是一个模型,让它们鸡生蛋蛋生鸡,不断互相训练
想到这里,OpenAI为什么要构建「a roughly human-level automated alignment researcher」的思路就水到渠成了。不知道Jan Leike大佬的思考逻辑是怎样的,反正我自己这么捋下来还挺顺,欢迎讨论。
如何做AI研究器
找到「AI研究器」这个启动点之后,接下来就是怎么实现的问题了。相比于如何训练出这个模型,Jan大佬把主要的中心都放在了如何构建自动化、全面化的评估上,其实跟上面的道理一样,好的评估可以提供监督反馈,从而指导模型的迭代方向。
首先,需要能验证模型可以达到人类水平。其实要真正评估出这个还是很难的,就像现在业内这么多模型,没人能给出一个真的排行榜一样。而且最好是自动化的,避免人来提供ground truth,才能进行更全面的评估。这里大佬提供了一个discriminator-critique gap的测量方法,比如我们做了一个编程模型,想利用ChatGPT自动评估他的效果,最简单的做法是直接命令ChatGPT判断某道编程题做的对不对。那问题就来了,我们怎么确定ChatGPT评估结果是否置信?都人工看一遍太浪费时间了。自动化的做法是直接基于ChatGPT训练一个判断变成结果是否正确的判别模型,然后我们专门用一些有label的难样本,去看判别模型的准确率和ChatGPT的准确率,如果差的不多,就说明不用训练也可以用它直接评估编程结果的好坏。
其次,自动化地进行鲁棒性检测、可解释性分析。为啥非要做可解释性呢?
可以为我们指出解决问题的途径
现有很多研究是在做知识和神经元的关联性,大佬认为更有意义的是自动化、规模化地去做,从而探究更高维度(模型整体)的可解释性
最后,故意训练不对齐的模型进行对抗测试,验证评估方法的有效性。从而避免出现假对齐的情况。最极端的就是真训出了一个超级智能,他可能会想办法备份自己的权重,逃脱人类控制,需要专门通过其他代理任务(比如让模型去hack某台机器)看一下这个程度有多难,评估系统能否检测出来。
投入成本的考量
OpenAI未来4年内将会在Superalignment上组建30-100人规模的团队,投入20%的算力。其实20%个人感觉主要是先表个决心,这个数量Jan大佬说已经是对齐方向上最大的单笔投入了,做得好以后还会再加。
倒是4年这个规划,说近不近说远不远,还关乎于其他从业者要经历多久的红利衰退期(狗头),Jan给出了如下规划:
2年内搞清楚用什么技术实现AI对齐研究器,把问题拆的足够细,剩下就是工程问题了
3年内实现AI对齐研究器
剩下一年探索超级对齐
这么一看时间还是挺紧的,后面两个计划略显乐观,Jan给出的信心是85%,而且表示有很多实验已经在实验中了(至少从22年8月那个博文发出前就开始研究了)。他的信心主要来自于5方面:
语言模型的成功:LLM可以理解自然语言,让我们可以向模型表达我们希望他们怎么做,操控起来更加容易
RLHF的效果超出预期:只用了很少的计算,甚至还没尝试收集数据,就可以在小模型上得到比大模型更好的效果
在评估度量方面已经取得了很多进展,可以提供改进的方向
评估比生成更简单:如果人类只做评估,而不做生成,那么开发速度就会加快,还是自动化监督信号的思想
对语言模型的信念:语言模型很适合做超级对齐,任何任务都可以表述为文本的输入输出,不管是做实验和理解结果都可以做
目前的技术还有用吗
对于预训练,Jan Leike认为预测下一个token这种方式并不一个长期目标,可能需要更好的任务。个人认为互联网上视频、图像、文字数据迟早会被消耗殆尽,所以目前的预训练主要是提供一个较好的基模型,后续高质量的监督信号应该会来源于模型本身,就像前文一直说的「自动化」。但这样是否还能称作「预训练」就不一定了。
对于RLHF,Jan Leike也持怀疑态度,因为目前的监督信号来源于人工评判,但人工并不擅长区分看起来都很好的答案,各种论文显示人类之间的一致率有70%就不错了,这个监督信号本身自己都不一定对的齐。同时,需要人工就导致无法规模化扩展,也不符合我们增加计算量的需求。
目前预训练+RLHF的范式大概率也只是AI发展中的一个版本,按照OpenAI的AI研究器思路,后续模型训练的系统复杂度可能会提升很多,估计会有N多个擅长不同任务的AI研究器来训一个模型,人工只需要提供少量监督信号,告诉系统要做什么,就可以让他们自动运转,训完了自动同步权重,不断升级。
总结
整个Jan Leike的采访看下来,真的收获颇丰,不知道有没有清晰地表达出来,其实就是:
计算是核心,计算的量变产生智能的质变
加速有效计算量的方法是:自动化->规模化->迭代
就像人类百万年来,从石器时代进化到现在的信息时代,科技的进步不是一蹴而就,而是螺旋上升,由几代人的智慧凝结而成。
P.S. 本文包含很多个人对OpenAI博文、Jan Leike访谈的理解,请辩证看待,欢迎讨论。
参考资料
[1]
Our approach to alignment research: https://openai.com/blog/our-approach-to-alignment-research
[2]Introducing Superalignment: https://openai.com/blog/introducing-superalignment
[3]Our approach to alignment research: https://openai.com/blog/our-approach-to-alignment-research

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「记住啊,计算!」

![牛客复盘] 2023河南萌新联赛第(七)场:信息工程大学 B\I 20230823](https://img-blog.csdnimg.cn/fb038d556d6c481893474a67b28ef153.png)