思路:之前有反转链表前n个值、以及反转指定区间的链表,所以这个我只想在这两个基础上实现。用左右指针来确定当前反转的区间,每次反转之前都检查一下当前区间是否足够k,即区间之后的节点cur,足够就可以反转,反转之后找到当前的cur,循环反转。
class Solution:
p = None
def reverse(self,head,l):
if l == 1:
self.p = head.next
return head
last = self.reverse(head.next,l-1)
head.next.next = head
head.next = self.p
return last
def reverselr(self,head,l,r):
if l == 1:
return self.reverse(head,r)
head.next = self.reverselr(head.next,l-1,r-1)
return head
def reverseKGroup(self , head: ListNode, k: int) -> ListNode:
cur = head
left = 1
right = 1
while cur:
while right - left < k - 1 and cur: #如果当前左右差足够k并且cur存在,找下一个cur
cur = cur.next
right += 1
if cur:
head = self.reverselr(head,left,right) #反转部分
p = head #重新找当前的cur位置
for i in range(right):
p = p.next
cur = p
left = right + 1 #更新左右
right = left
return head

思路:二分,两两合并,然后再次两两合并,直到只剩一个链表。
class Solution:
def mergetwo(self,list1,list2):
dump = ListNode(-1)
p = dump
p1 = list1
p2 = list2
while p1 and p2:
if p1.val < p2.val:
p.next = p1
p1 = p1.next
else:
p.next = p2
p2 = p2.next
p = p.next
if p1:
p.next = p1
if p2:
p.next = p2
return dump.next
def mergeKLists(self , lists: List[ListNode]) -> ListNode:
k = len(lists)
if k == 1:
return lists[0]
if k == 0:
return None
left = 0 if k % 2 == 0 else 1 #如果k是奇数,就先两两合并剩下的
first = lists[0] if left == 1 else None
right = k - 1
res = []
while left < right:
a = self.mergetwo(lists[left],lists[right])
left += 1
right -= 1
res.append(a) #新链表数组
if right == left: #如果左右相等
res.append(lists[left]) #数组加入当前链表,重新合并下一轮
lists = res
right = len(res) - 1
left = 0
res = []
elif right < left and len(res) > 1:#如果左右不等并且res没有合并到最后
left = 0
right = len(res) - 1 #合并下一轮
lists = res
res = []
ans = self.mergetwo(res[0],first) #考虑到第一个链表
return ans

思路:反转两个链表,然后开始加和对应的值,用和%10当做此次的value来新增节点,和//10作为进位。当两个链表都走到最后了,查看进位值是否为1,如果是就再新增一个节点,如果不是,就把全部新增节点反转输出。
class Solution:
def reverse(self,head):
if head is None or head.next is None:
return head
last = self.reverse(head.next)
head.next.next = head
head.next = None
return last
def addInList(self , head1: ListNode, head2: ListNode) -> ListNode:
head1 = self.reverse(head1)
head2 = self.reverse(head2)
add = 0 #进位
ans = ListNode(-1) #设置头结点
p = ans
while head1 and head2: #依次加和
value = (head1.val + head2.val + add) % 10
add = (head1.val + head2.val + add) // 10
p.next = ListNode(value)
p = p.next
head1 = head1.next
head2 = head2.next
while head1: #加和剩下的链表
value = (head1.val+add) % 10
add = (head1.val+add) // 10
p.next = ListNode(value)
p = p.next
head1 = head1.next
while head2: #加和剩下的链表
value = (head2.val+add) % 10
add = (head2.val+add) // 10
p.next = ListNode(value)
p = p.next
head2 = head2.next
if add: #最后查看是否还有进位
p.next = ListNode(add)
p = p.next
return self.reverse(ans.next) #返回新增链表的反转

思路:先遍历一次链表,用数组存储,然后快排数组,最后将数组转化成链表
import random
class Solution:
def paixu(self,num):
if len(num) <= 1:
return num
p = random.choice(num)
left = self.paixu([i for i in num if i < p])
right = self.paixu([i for i in num if i > p])
same = [i for i in num if i == p]
return left+same+right
def sortInList(self , head: ListNode) -> ListNode:
if head is None or head.next is None:
return head
num = []
while head: #遍历链表
num.append(head.val)
head = head.next
nums = self.paixu(num) #快排数组
dump = ListNode(-1)
p = dump
for i in nums: #重组链表
p.next = ListNode(i)
p = p.next
return dump.next

思路:将链表转化成数组,然后比较num==num[::-1]
class Solution:
def isPail(self , head: ListNode) -> bool:
if head is None or head.next is None:
return True
num = []
while head:
num.append(head.val)
head = head.next
return num == num[::-1]

思路:设置奇偶位,然后先移动奇位,将数据加入新建链表中,然后再移动偶位,将数据加入新建链表中。最后输出新建链表。
class Solution:
def oddEvenList(self , head: ListNode) -> ListNode:
if head is None or head.next is None or head.next.next is None: #特殊判断
return head
odd = head
even = head.next
dump = ListNode(-1)
p = dump
while odd or even:
if odd:
p.next = ListNode(odd.val)
if odd.next:
odd = odd.next.next
else:
odd = odd.next
else:
p.next = ListNode(even.val)
if even.next:
even = even.next.next
else:
even = even.next
p = p.next
return dump.next

思路:遍历链表,如果当前值等于下一个值,就删除下一个节点,如果不等于就移动指针到下一位。
class Solution:
def deleteDuplicates(self , head: ListNode) -> ListNode:
if head is None or head.next is None:
return head
p = head
while p and p.next:
if p.val == p.next.val: #如果等,就删下一个节点
p.next = p.next.next
else: #不等就移动指针
p = p.next
return head
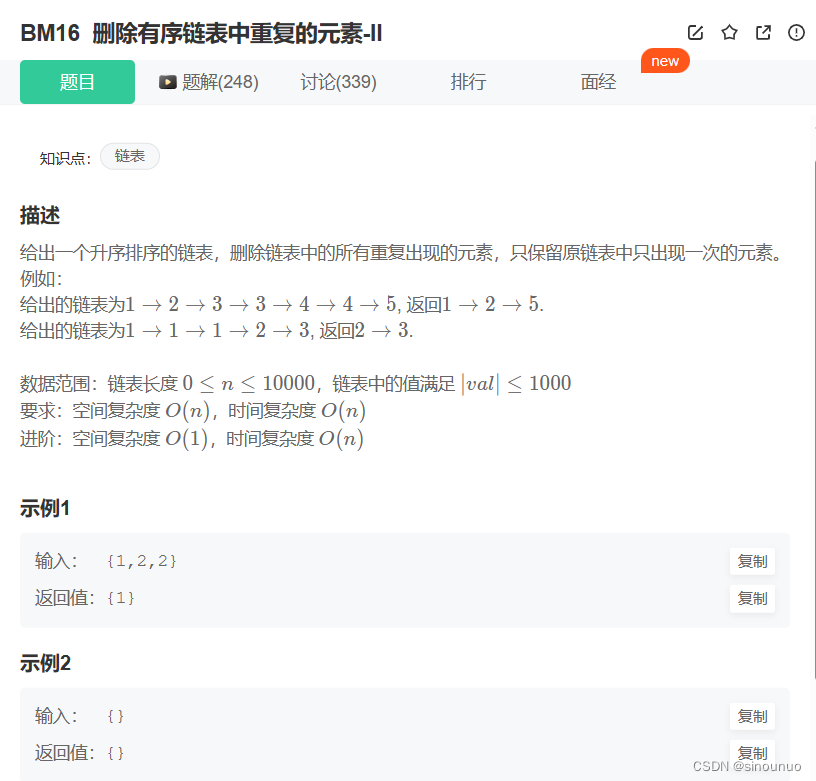
思路:因为是升序链表,设置头结点(为了删除head),如果dump.next.val==dump.next.next.val ,记录当前的value值,删除所有值是value的节点。如果不等,就移动指针。
class Solution:
def deleteDuplicates(self , head: ListNode) -> ListNode:
if head is None or head.next is None:
return head
dump = ListNode(-1)
dump.next = head
p = dump
while p.next and p.next.next:
if p.next.val == p.next.next.val: #如果值相等
value = p.next.val
while p.next and p.next.val == value:
p.next = p.next.next
else: #如果值不等
p = p.next
return dump.next






![EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks [2022 CVPR]](https://img-blog.csdnimg.cn/7ca043ac83ca42c5a6301dc33a63ae22.png)