本文所用资料下载
一. Representing text
Let’s load Jane Austen’s Pride and Prejudice.
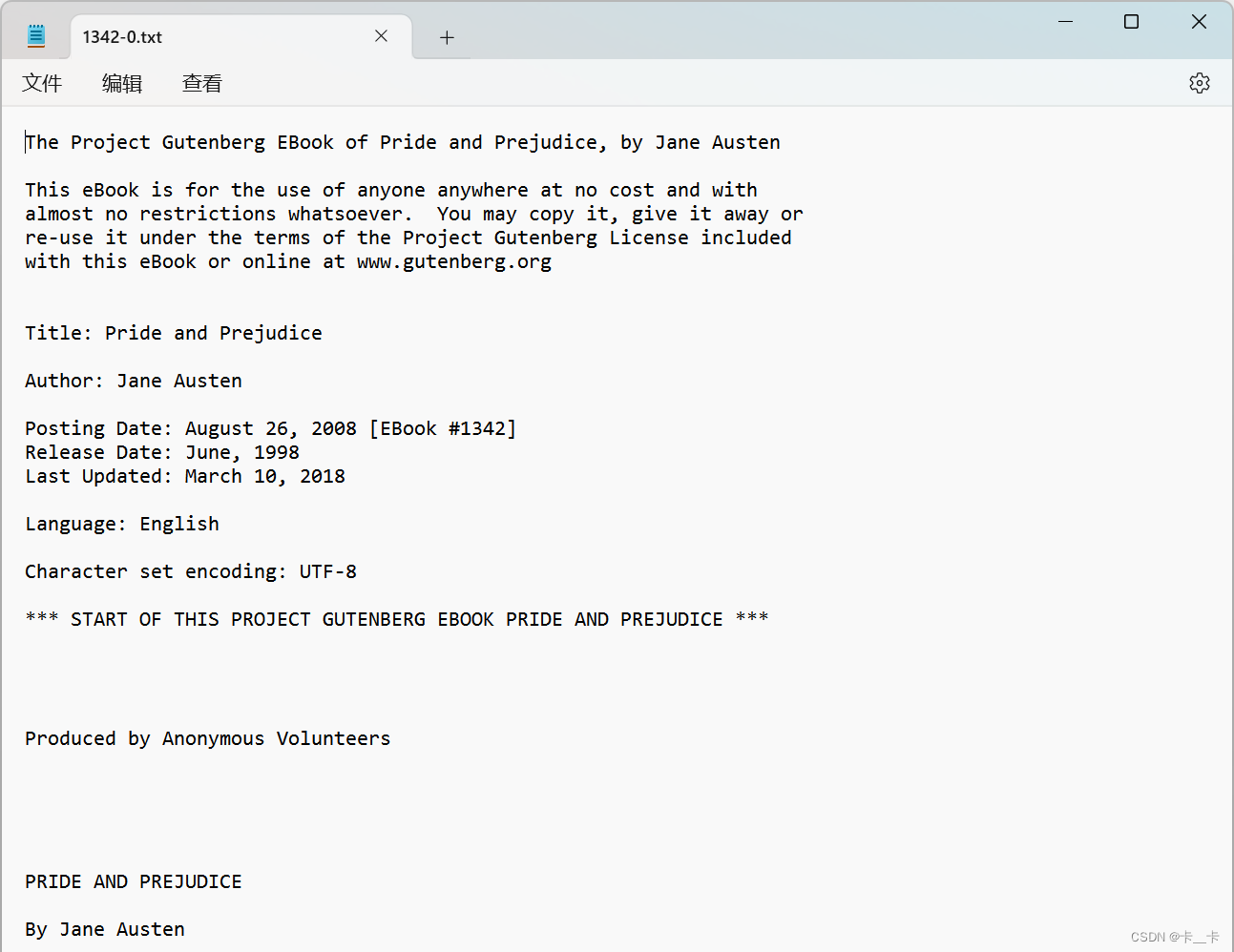
We first split our text into a list of lines and pick an arbitrary line to focus on:
with open('D:jane-austen/1342-0.txt', encoding='utf8') as f:
text = f.read()
lines = text.split('\n')
line = lines[200]
line

Let’s create a tensor that can hold the total number of one-hot-encoded characters for the whole line:
import torch
letter_t = torch.zeros(len(line), 128) # 128 hardcoded due to the limits of ASCII
letter_t.shape

# 遍历经过转换为小写并剥去首尾空白的字符串line中的每个字符
# enumerate函数用于在每次迭代中获取索引i和字符letter
for i, letter in enumerate(line.lower().strip()):
# 检查小写字母的ASCII值是否小于128。如果是,ASCII值就赋给letter_index,否则设置为0。
# 这是为了处理ASCII值在0-127范围之外的字符
letter_index = ord(letter) if ord(letter) < 128 else 0
# 与字符的ASCII值对应的元素设置为1,其他元素设置为0
letter_t[i][letter_index] = 1
循环结束时,letter_t将包含一个矩阵,其中每一行对应输入字符串中的一个字符,列表示ASCII值(最大到127),在与字符的ASCII值对应的列中为1,在其他地方为0。
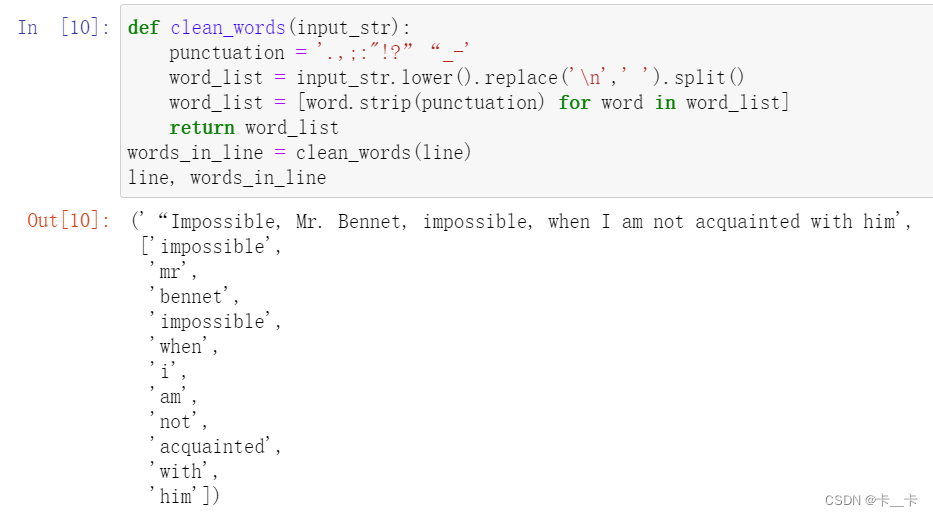
We’ll define clean_words, which takes text and returns it in lowercase and stripped of punctuation. When we call it on our “Impossible, Mr. Bennet” line, we get the following:
def clean_words(input_str):
punctuation = '.,;:"!?”“_-'
# replace将换行符替换为空格,split()将字符串拆分成单词列表
word_list = input_str.lower().replace('\n',' ').split()
# 去除单词开头和结尾的标点字符
word_list = [word.strip(punctuation) for word in word_list]
return word_list
words_in_line = clean_words(line)
line, words_in_line
Next, let’s build a mapping of words to indexes in our encoding:
# set将清理后的单词列表转换为集合来去除重复单词,sort进行排序
word_list = sorted(set(clean_words(text)))
# 使用enumerate函数遍历word_list中的每个单词word和对应的索引i(将单词映射到它在排序后的单词列表中的索引位置),然后创建一个名为word2index_dict的字典,其中键是单词word,值是索引i
word2index_dict = {word: i for (i, word) in enumerate(word_list)}
len(word2index_dict), word2index_dict['impossible']

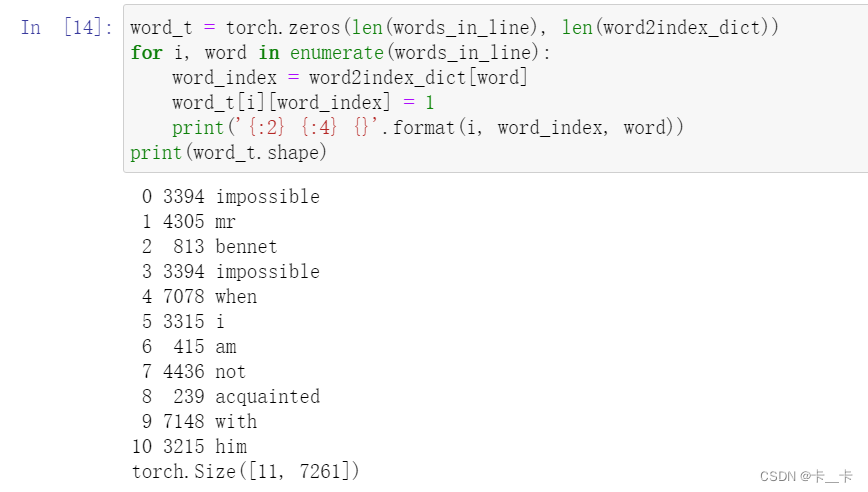
Let’s now focus on our sentence: we break it up into words and one-hot encode it—that is, we populate a tensor with one one-hot-encoded vector per word.
# 行数是 words_in_line 中的单词数量,列数是整个文本中出现的不同单词数量
word_t = torch.zeros(len(words_in_line), len(word2index_dict))
for i, word in enumerate(words_in_line):
word_index = word2index_dict[word]
word_t[i][word_index] = 1
# {:2}表示若不足2个字符,左侧填充空格补齐
print('{:2} {:4} {}'.format(i, word_index, word))
print(word_t.shape)
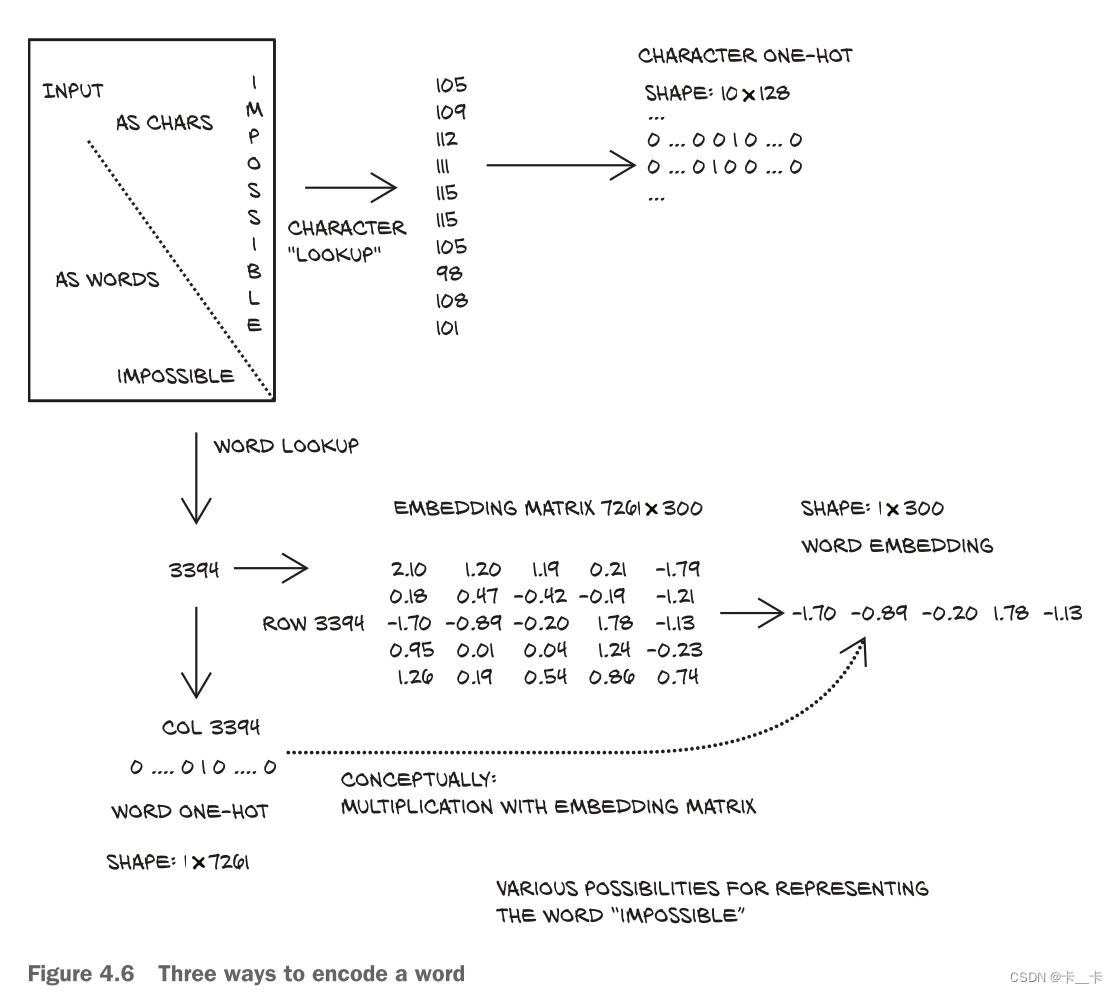
字符级别编码和单词级别编码各有利弊。字符级别编码涉及表示更少的类别(单个字符),而单词级别编码需要表示更多的类别(单词),并且需要处理词汇表之外的词汇。字符级别编码具有更少的类别集,但可能无法捕捉单词的全部含义。另一方面,单词级别编码传达更多的语义信息,但涉及管理更大的词汇量。
因此提出了一种中间方法 byte pair encoding method。它从字典中的个别字母开始,逐步将频繁出现的字节对添加到字典中,直到达到一定的大小。这种方法结合了字符和单词级别编码的一些优点。
One-hot encoding在有限数量的类别数据上有效,但在像自然语言中这样的大词汇量情况下,变得不实用,因为词语几乎是无限的,因此我们提出了vectors of floating-point numbers。一个包含100个浮点数的向量确实可以表示大量的词,将单个单词映射到这个100维空间中,从而促进后续学习,这叫做embedding。我们可以简单地迭代词汇表,并为每个单词生成一组100个随机浮点数。
We can generate a 2D space where axes map to nouns—fruit (0.0-0.33), flower (0.33-0.66), and dog (0.66-1.0 —and adjectives—red (0.0-0.2), orange (0.2-0.4), yellow (0.4-0.6), white (0.6-0.8), and brown (0.8-1.0). Our goal is to take actual fruit, flowers, and dogs and lay them out in the embedding.
当我们开始嵌入单词时,我们可以将苹果映射到水果和红色象限中的一个数字。向日葵可以得到花,黄色和棕色,然后雏菊可以得到花,白色和黄色。
Now our embeddings look like figure 4.7.

结果嵌入的一个有趣的方面是,相似的单词不仅聚集在一起,而且与其他单词有一致的空间关系。例如,如果我 取苹果的嵌入向量,然后开始加减其他单词的向量,我们可以开始进行类似于苹果-红-甜+黄+酸的类比,最后得 一个非常类似于柠檬的向量。
词汇表中的一个词到一个向量的映射不是固定的,而是取决于周围的句子。然而,它们经常被使用,就像我们在 里提到的简单的经典嵌入一样。
一旦生成了词嵌入,它们可以作为各种下游NLP(自然语言处理)任务的输入,如情感分析、机器翻译、文本生成等。现代的嵌入模型如BERT和GPT-2比基本词嵌入更复杂,融合了复杂的神经架构,更有效地捕捉上下文和含义。词嵌入是NLP中的一个关键概念,使机器能够理解和处理词语之间的语义关系,从而在各种语言相关的任务中实现更好的性能。
二. exercise
答案仅供参考
- Take several pictures of red, blue, and green items with your phone or other digital camera (or download some from the internet, if a camera isn’t available).
(1)Load each image, and convert it to a tensor.
(2)For each image tensor, use the .mean() method to get a sense of how bright
the image is.
(3)Take the mean of each channel of your images. Can you identify the red,
green, and blue items from only the channel averages?
解:以一张图片为例

(1)
import imageio.v2 as imageio
img_arr=imageio.imread('D:/3e/1.jpg') # 使用imageio模块加载图像
import torch
img = torch.from_numpy(img_arr) # 转化为tensor
out = img.permute(2, 0, 1) # H × W × C 转为 C × H × W
(2)
out=out.float() # mean只能处理浮点型
out_mean=out.mean()
# out_mean输出tensor(100.8920)
图像张量的平均值可以获得亮度的估计值,out_mean越大说明图片亮度越大
(3)
i1=out[0,:,:].mean()
i2=out[1,:,:].mean()
i3=out[2,:,:].mean()
i1,i2,i3

三个通道分别对应红绿蓝的均值,可以看到i1的均值最大,即图片偏红色
- Select a relatively large file containing Python source code.
(1)Build an index of all the words in the source file (feel free to make your tokenization as simple or as complex as you like; we suggest starting with replacing r"[^a-zA-Z0-9_]+" with spaces).
(2)Compare your index with the one we made for Pride and Prejudice. Which is larger?
(3)Create the one-hot encoding for the source code file.
(4)What information is lost with this encoding? How does that information compare to what’s lost in the Pride and Prejudice encoding?
解:
(1)
r"[^a-zA-Z0-9_]+"
r 在字符串前面表示"原始字符串",它不会对反斜杠进行转义处理,如
> out:
^表示非
+表示前面的表达式可以连续出现一次或多次,它指示前面的模式可以匹配一个或多个相同的字符或子字符串。

with open('D:/model.py',encoding='utf8') as f:
text=f.read()
以换行符切分,每块一行
lines=text.split('\n')
一共89行

将非字母数字下划线替换为空格,并按空格进行切分
def clean_words(input_str):
word_list=input_str.replace(r'[^a-zA-Z0-9_]+',' ').split()
return word_list
words_in_line = clean_words(text)
words_in_line
完成映射
# set将清理后的单词列表转换为集合来去除重复单词,sort进行排序
word_list = sorted(set(words_in_line))
# 使用enumerate函数遍历word_list中的每个单词word和对应的索引i
word_list_dict = {word: i for (i, word) in enumerate(word_list)}

(2)比Pride and Prejudice小
(3)
import torch
letter_t = torch.zeros(len(words_in_line), len(word_list)) # 行是单词数,列是去重后的单词数
for i, letter in enumerate(words_in_line):
wordindex=word_list_dict[letter]
letter_t[i][wordindex] = 1

(4)我们去除的非数字字母下划线的数据丢失了,python代码中有更多的非标点符号(例如“.”),因此会丢失更多的数据。