2023年ISCA国际语音通讯学会年会(2023 Annual Conference of the International Speech Communication Association, INTERSPEECH 2023)将于2023年8月20日-24日在爱尔兰都柏林召开,清华大学人机语音交互实验室(THUHCSI)将在本次会议上发表9篇论文。这些论文涉及语音合成、语音识别、语音增强、语音分离、视频配音等多个研究领域。
01 Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model
作者:Xiang Li, Songxiang Liu, Max M.Y. Lam, Zhiyong Wu, Chao Weng, Helen Meng
合作单位:腾讯 AI Lab、香港中文大学
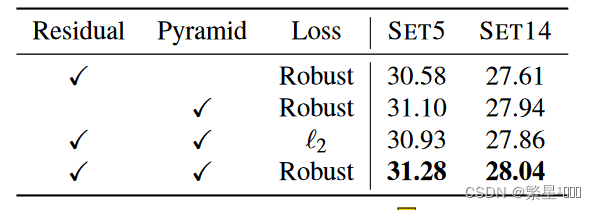
论文主要创新点:本文针对表现力语音合成中的自动韵律控制,首次提出了一种基于去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM)的语音韵律预测器(prosody predictor)。该预测器使用文本内容特征作为生成条件,基于 DDPM 的生成式建模框架完成从文本内容特征到韵律表征的建模。相较于现有的最小化韵律表征预测误差训练的方法,该方法不再受到对目标韵律特征分布的简化假设的限制,而是直接利用 DDPM 对韵律表征的概率分布进行建模;同时,由于 DDPM 的采样结果多样性,该方法可以实现在同一句输入文本上生成不同的韵律预测结果,避免了生成语音风格的同质化。在高表现力有声读物数据上的实验结果表明,将该预测器替换到 FastSpeech 2 语音合成框架中用于预测音素的韵律特征(即时长 duration、基频 pitch、能量 energy),可以有效改善对真实韵律特征分布的拟合效果,并改善现有方法中的过平滑问题。主观评测结果也显示,使用所预测的韵律表征控制合成的语音表现力得到了显著提升。
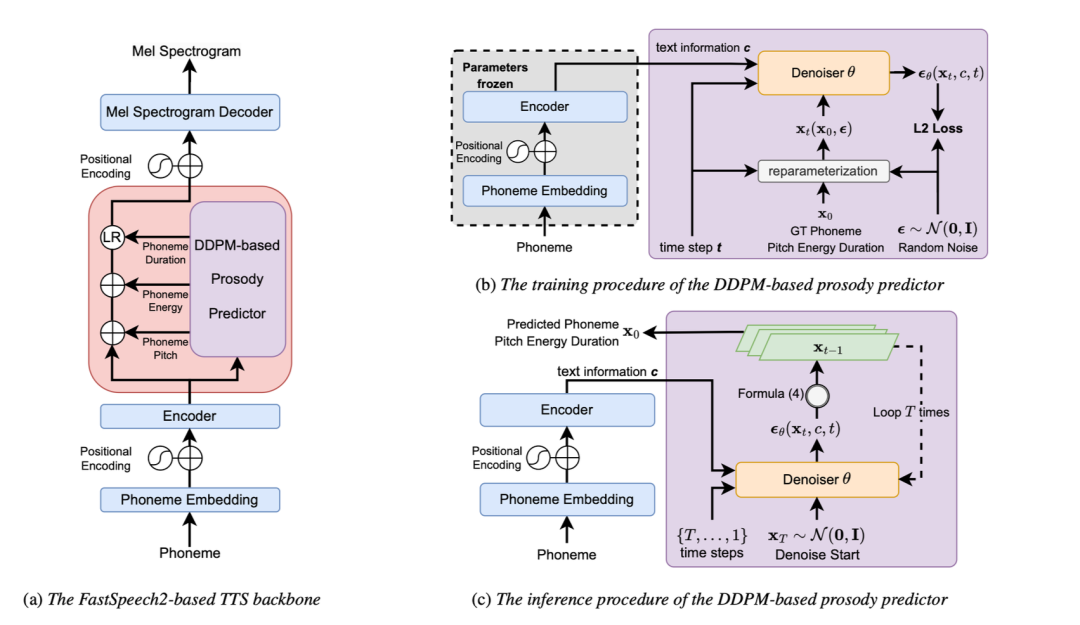
包含基于 DDPM 的韵律预测器的 TTS 系统框架及训练、推理图示

基于 DDPM 的韵律预测器的主客观评测结果
02 Towards Spontaneous Style Modeling with Semi-supervised Pre-training for Conversational Text-to-Speech Synthesis
作者:Weiqin Li, Shun Lei, Qiaochu Huang, Yixuan Zhou, Zhiyong Wu, Shiyin Kang, Helen Meng
合作单位:元象科技有限公司
论文主要创新点:本文针对自发风格的对话语音合成(Spontaneous-style Conversational TTS)提出了一种基于半监督预训练的自发现象建模方法,并加入一个语言学感知网络加强对话中的上下文信息建模。自发风格中包含很多不流畅的现象(例如:嗯、啊、尾音的延长等),这些副语言学特征称为自发现象,是自发风格TTS和阅读风格TTS的主要区别。但是高质量、带标签的自发风格数据集获取的成本太高,因此本文针对填充停顿(filled pause)和延长(prolongation)这两种自发现象提出了一种半监督预训练方法来增加自发现象标签的数量,利用高质量数据集训练一个标签检测器,从大量低质量数据集中提取伪标签,再用大量的低质量数据集对TTS模型进行预训练,最后用高质量数据集进行微调,加强TTS模型对自发现象的预测能力。对话中的语言学信息指的是对话中各个句子的联系,本文提出一个基于多头注意力机制的语言学感知网络来建模对话中的语言学信息,使得合成的音频更加自然。主观测评实验结果表明所提出的方法能提升模型建模和预测对话中自发现象的能力。
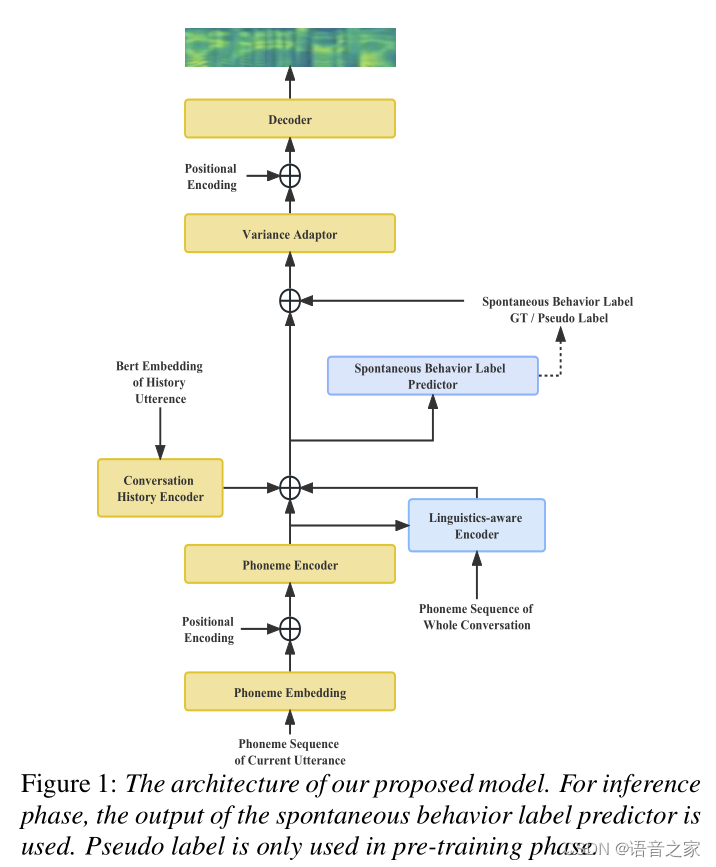
所提方法的基本结构
03 Prosody Modeling with 3D Visual Information for Expressive Video Dubbing
作者:Zhihan Yang, Shangsong Liu, Xu Li,
Haozhe Wu, Zhiyong Wu, Ying Shan, Jia Jia
合作单位:腾讯科技有限公司
论文主要创新点:自动视频配音任务是为了满足个人和行业对配音的需求而提出的。目前的方法大多关注时长匹配,忽略了韵律的同步性,缺乏表现力。在本文中,我们引入了3D视觉韵律建模来提高视频配音的表现力,3D视觉韵律被定义为3D空间中的表情和头部姿势,其优点是:1)与话语的语气和重音高度相关;2) 比2D图像更准确;3) 从诸如说话者身份之类的无关因素中解脱出来。我们提出了一种3D-VD(3D视频配音器)系统来结合3D视觉韵律,利用视觉文本逐步对齐器来控制生成的韵律。实验表明,该方法在自然度、唇语对齐以及视觉和听觉韵律的同步性方面优于以前只考虑2D人脸图像的方法。案例研究验证了表达和音高之间的相关性。
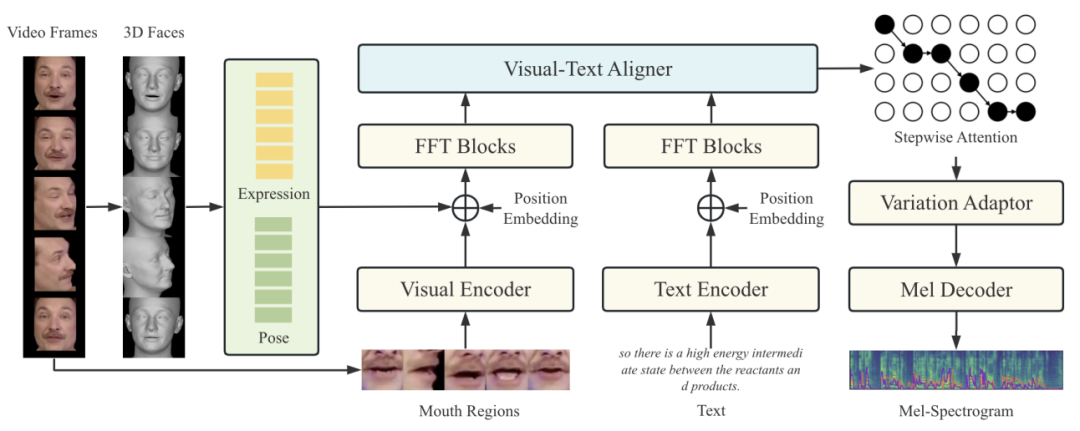
所提方法的基本结构
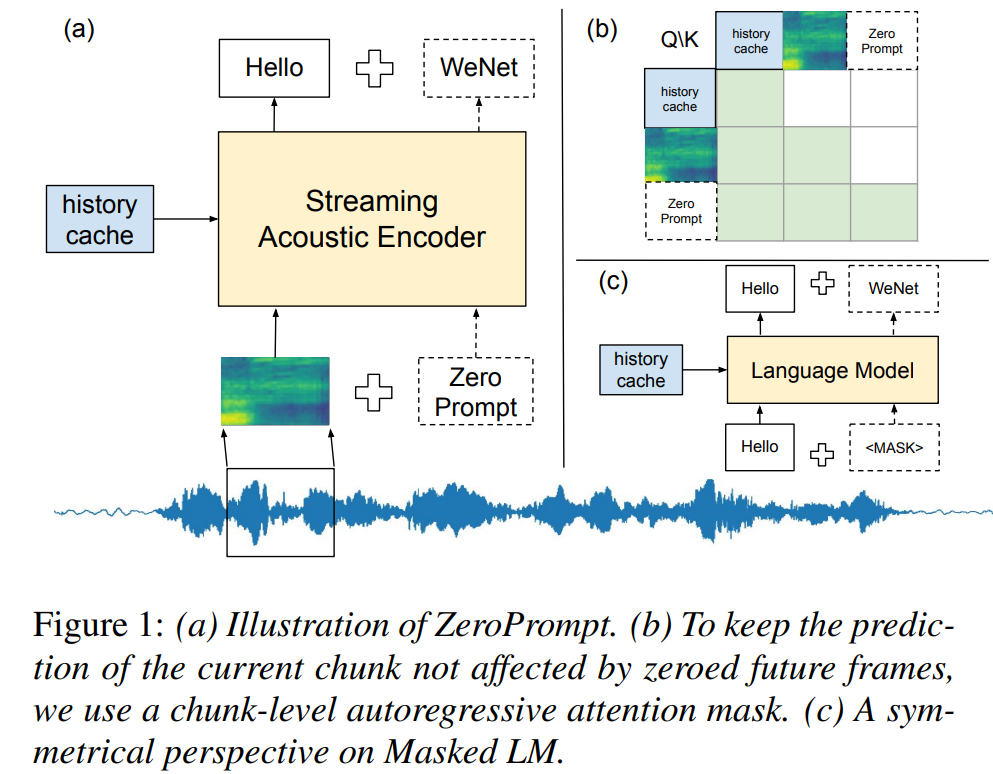
04 ZeroPrompt: Streaming Acoustic Encoders are Zero-Shot Masked LMs
作者: Xingchen Song, Di Wu, Binbin Zhang, Zhendong Peng, Bo Dang, Fuping Pan, Zhiyong Wu
合作单位:地平线信息技术有限公司、
WeNet开源社区
论文主要创新点:在本论文中,我们介绍了ZeroPrompt(下图1(a))和相应的Prompt-and-Refine策略(下图3),这是两种简单但有效的无需训练的方法,用于降低流式自动语音识别(ASR)模型的令牌显示时间(TDT),而无需牺牲准确性。ZeroPrompt的核心思想是在推理过程中向每个chunk附加空白帧,空白帧充当了一种提示,以鼓励模型预测未来的单词。我们认为流式声学编码器自然具备Masked Language Models的建模能力,我们的实验表明ZeroPrompt在工程上是廉价的,并且可以应用于任何数据集上而不会造成准确性的损失。具体来说,与基准模型相比,我们在首个令牌显示时间(TDT-F)上实现了350至700毫秒的减少,在最后一个令牌显示时间(TDT-L)上实现了100至400毫秒的减少,并且在Aishell-1和Librispeech数据集上,在理论和实验上实现了相等的识别错误率(WER)。

05 SememeASR: Boosting Performance of End-to-End Speech Recognition Against Domain and Long-Tailed Data Shift with Sememe Semantic Knowledge
作者:Jiaxu Zhu,Changhe Song,Zhiyong Wu,Helen Meng
合作单位:鹏城实验室、香港中文大学
论文主要创新点:本文提出了一个基于义原(Sememe)知识的语义增强的端到端语音识别模型,以提高模型对长尾数据的识别效果,并增强模型的领域泛化能力。根据语言学定义,义原是语言中的最小语义单元,能够非常显式地表示每个单词背后的隐式语义信息。考虑到基于知识驱动的方法能够有效缓解基于数据驱动方法带来的如长尾数据识别差等问题,我们在首次在语音识别任务中引入基于义原的知识。因此,本文使用了一系列方法把义原信息引入到端到端语音识别模型中。其中主要的是引入义原表征和文本表征进行结合,以提高文本的表征能力。其次是使用多任务训练方法,引入义原预测任务进一步加强模型对于义原知识的建模能力。我们的实验表明,引入语义信息可以提高语音识别的有效性。此外,我们的进一步实验表明,义原知识可以提高模型对长尾数据的识别。并增强模型的域泛化能力。
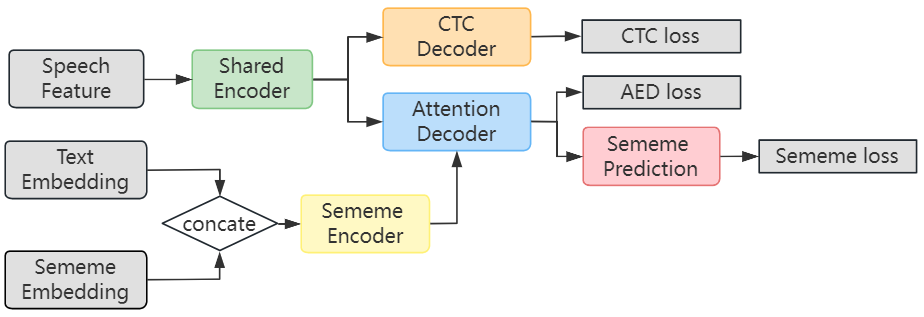
所提方法的基本结构
06 Text-Only Domain Adaptation for End-to-End Speech Recognition Through Down-Sampling Acoustic Representation
作者:Jiaxu Zhu,Weinan Tong,Yaoxun Xu,Changhe Song,Zhiyong Wu,Zhao You,
Dan Su,Dong Yu,Helen Meng
合作单位:腾讯科技有限公司、鹏城实验室、
香港中文大学
论文主要创新点:本文面向使用新领域纯文本对端到端语音识别进行领域适应(Text-only Domain Adaptation)的工作,提出了一种新的语音模态和文本模态共享表征空间的方法。不同于之前的相关工作通过上采样文本表征和语音表征对齐的方法,我们通过引入Continuous integrate-and-fire(CIF)机制对声学表征进行下采样并与相应文本单调对齐,使得声学表征和文本表征长度一致。此外,我们引入拼音作为语音模态和文本模态的中间桥梁,让语音和文本两种模态映射到共同的表征空间。在使用新领域的纯文本进行领域适应时,我们利用文本转成拼音,并通过拼音编码器把拼音映射到和声学模态共享的表征空间,获得对应的表征以代替缺失的声学表征,从而在新领域对端到端语音识别模型的Decoder部分进行微调,达到提高语音识别模型在新领域上识别效果的目的。
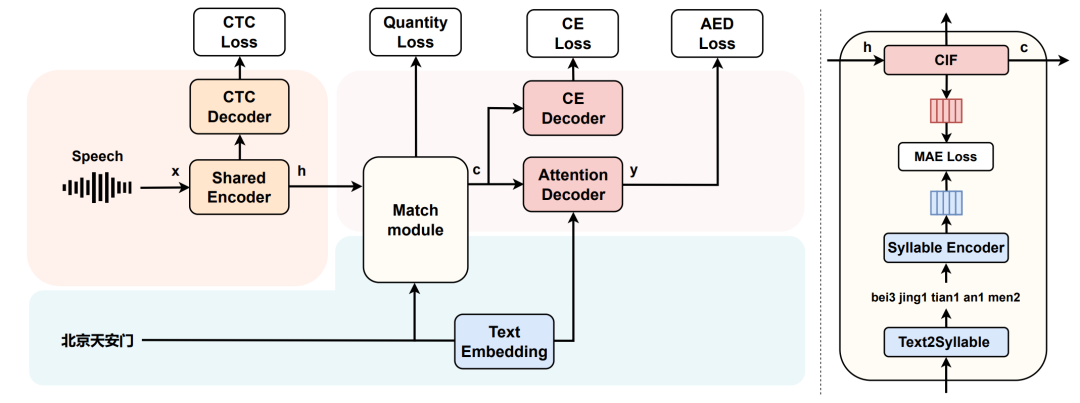
所提方法的基本结构
07 Focus on the Sound around You: Monaural Target Speaker Extraction via Distance and Speaker Information
作者:Jiuxin Lin, Peng Wang, Heinrich Dinkel, Jun Chen, Zhiyong Wu, Zhiyong Yan, Yongqing Wang, Junbo Zhang, Yujun Wang
合作单位:小米科技有限公司
论文主要创新点:目标语音提取(Target Speaker Extraction,TSE)在语音增强和语音分离的某些应用场景中表现出优异的性能。然而,在存在显著混响的嘈杂环境中获取辅助说话人相关信息以及提取目标说话人语音仍然具有挑战性。受最近提出的基于距离的声音分离的启发,我们提出了NS-Extractor,它能够利用距离信息在不需要说话人信息注册的前提下,提取指定距离范围内的目标说话人语音。同时,我们引入全带与子带建模以增强我们的NS-Extractor在存在显著混响环境情况下的鲁棒性。在多个数据集上的实验结果表明了我们的改进的有效性以及我们所提出的NS-Extractor在不同应用场景中的出色性能。
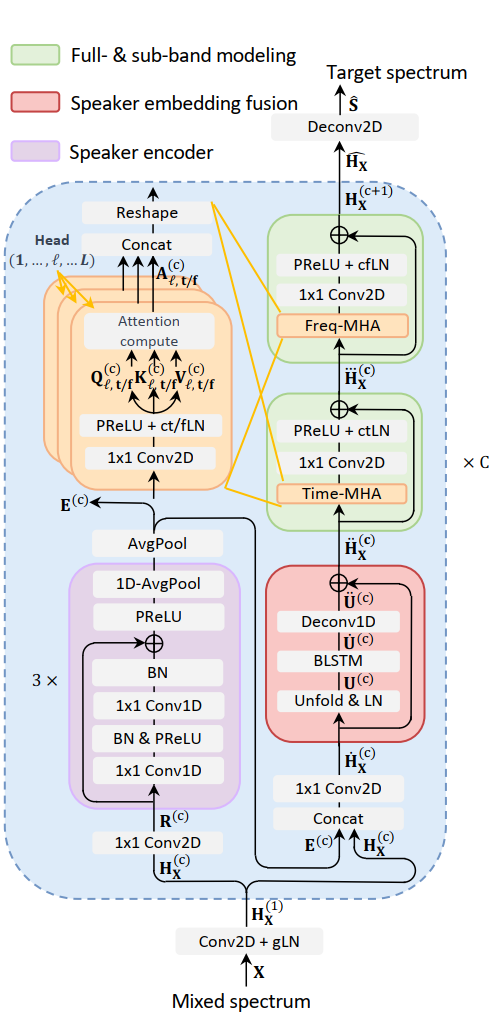
所提方法的基本结构
08 MC-SpEx: Towards Effective Speaker Extraction with Multi-Scale Interfusion and Conditional Speaker Modulation
作者:Jun Chen,Wei Rao,Zilin Wang,
Jiuxin Lin, Yukai Ju, Shulin He, Yannan Wang, Zhiyong Wu
合作单位:腾讯天籁实验室、香港中文大学
论文主要创新点:先前的SpEx+在说话人提取方面取得了出色的表现,引起了人们的广泛关注。然而,它仍然存在对多尺度信息和说话人嵌入的利用不足的问题。为此,本文提出了一种新的高效的说话人提取系统,该系统中包括多尺度融合机制和有条件的说话人调制(ConSM)机制,被称为MC-SpEx。首先,我们设计了权重共享的多尺度融合器(ScaleFusers),以有效地利用多尺度信息,并保证模型特征空间的一致性。然后,为了在生成掩模时考虑不同的尺度信息,我们提出了多尺度交互式掩模生成器(ScaleInterMG)。此外,我们还引入了ConSM模块,以充分利用语音提取器中的说话人嵌入。Libri2Mix数据集上的实验结果表明了我们的改进的有效性,并且,我们提出的MC-SpEx达到了最先进的性能。
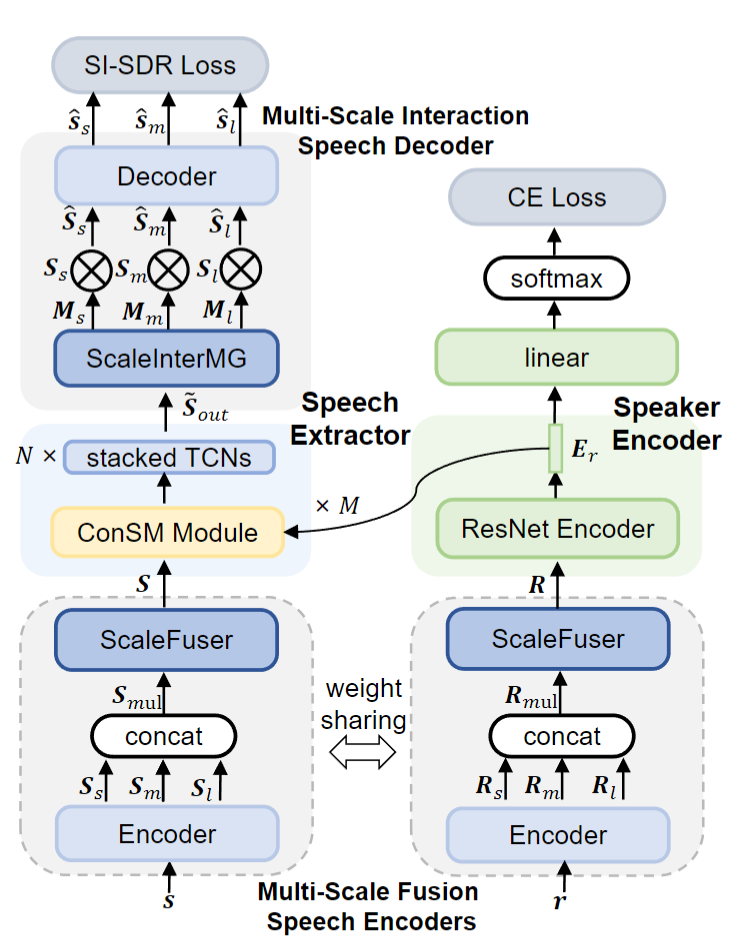
所提方法的基本结构
09 Gesper: A Restoration-Enhancement Framework for General Speech Reconstruction
作者:Wenzhe Liu, Yupeng Shi, Jun Chen, Wei Rao, Shulin He, Andong Li, Yannan Wang, Zhiyong Wu
合作单位:腾讯天籁实验室、中科院声学所
论文主要创新点:本文文描述了一个提交在2023年ICASSP的语音信号改进(SSI)挑战赛的实时通用语音重建(Gesper)系统。这一新提出的系统是一个两阶段的架构,在这一架构中,我们首先执行语音修复操作,随后紧接着进行语音增强。我们首次提出一个基于复数谱映射的生成对抗网络(CSM-GAN)作为第一阶段的语音修复模块。对于噪声抑制和去混响,增强模块采用全带-宽带并行处理。在ICASSP 2023 SSI挑战赛的盲测集上,本文所提出的的Gesper系统满足实时条件,获得了3.27 P.804的总体平均意见分数(MOS)和3.35 P.835的总体MOS,在track 1和track 2中均排名第一。
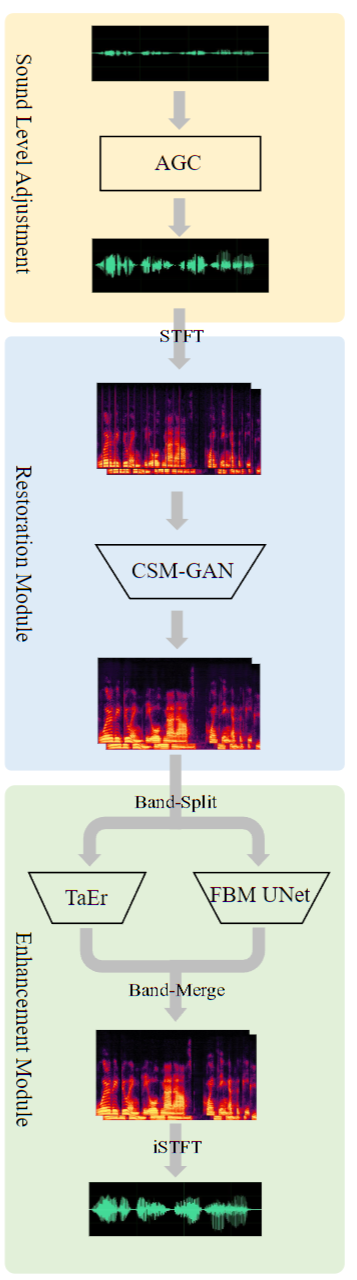
所提方法的基本结构