统计文本文件中高频词是常见操作(参考文章:Linux centos7 高频词统计)。而查找并统计文本文件中共有多少单词(独立字符串,包括中文或数字串)也是一项很好地实践项目。
本文主要应用命令替换、循环结构、sort、grep及awk命令等达到目标。最后剖析不同方法的差异且且提出使用建议。
bash中如何从文本文件中提取所有单词?主要有四维思路:用grep方法搜索所有单词存入一个变量;for循环遍历所有单词;while循环查找所有单词存入一个数组或打印输出;awk打印所有行之所有字段。
讨论项目主要目标:获取文件中的所有单词(是批独立数字串或英文字符串的简称)。仅存储每个单词一次,且不区分大小写。
本文训练素材:
cat test4.txt
123 222 345
my name is shantong
12345 789
my qq number is 36142959
my email is 36142959@qq.com
my ip is 192.168.1.141
my name is zhange
My telephone num is 13523072436
My qq number is 845537614
Server_name is Softeem
Company Site is http://www.pili-zz.net
MMMM1234
192.168.89.115
一、grep
grep命令可以搜索单词:加参数 –w;或在搜索字符前后加\b;或在搜索字符前加\< 后加\>;
而用对于未知的单词,可以使用posix字符[[:alpha:]],或\w
WORDS=`grep -o -E '\w+' filename | sort -u -f`
grep –o 仅显示匹配内容
grep –E 搜索表达式可用扩展正则
由grep搜索到的单词是所有文本文件的单词,有大量重复的,通过排序、去重,忽略大小写,可以用sort -u –f,达到单词唯一。
sort –u 排序时去掉重复
sort –f 排序时忽略大小写
命令替换格式``与$()效果相同,可以自由选择一种。
WORDS=$(grep -o -E "[[:alpha:]]+" filename|sort -u -f) 仅英语词组
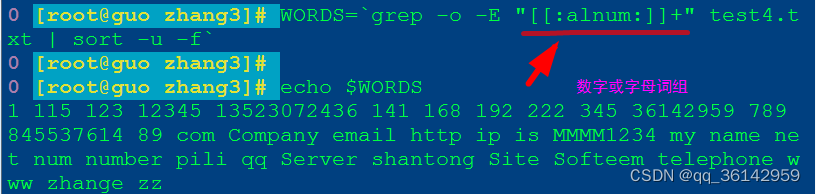
WORDS=`grep -o -E "[[:alnum:]]+" test4.txt | sort -u -f` 包括数字或英文词组


二、for循环
一个文本文件中,有大量单词,如果需要查找统计这些内容,首先想到的应该是用for循环,从文件中一个一个读取,或打印输出,或重定向到文件中。
for循环是按行循环读取的,不是按单词读取。我们可以把文本作为一个大的变量容器,我们一个一个单词读取,如下所示:
for word in $(<inputfile)
do
echo "$word" >>outfile
done
echo `cat outfile |sort –u –f`
rm –fr outfile
写成一行代码:
for word in $(<test4.txt); do echo "$word" >>outfile; done;echo `cat outfile |sort -u -f`;rm-fr outfile

先用$(<inputfile)把文件作为一个变量,再进行循环。获取单词太多,需要重定向到一个文件,再排序、去重。中间临时文件可以执行完程序后删除(这是一个好习惯!)
如果不排序、去重,for循环查找到的单词是这样的:

三、while循环
默认情况下,while循环中的read命令是读取整行。因此,解决方案可能是读取整行,然后使用例如for再获得单词:
while read line; do
for word in $line; do
echo"word = '$word'"
done
done <filename

与for循环一样,前面截图是未排序、去重的。
两个循环获取的单词也是一样多,功能相同。
四、awk
awk功能强大之处在于,利用此命令可以获取一行内容,也可以进一步列出行内的单词。可以格式化输出,有条件的输出部分或全部。
不排序去重查询输出文本文件的单词:
awk '{for(i=1; i<=NF; i++){print $i}}' text_file

排序且去重查询输出文本文件的单词:
awk '{
for(i=1;i<=NF;i++){
count[$i]++
}
} END {
for(k in count){
print k
}
}' test4.txt

写作一行代码:
awk '{for(i=1;i<=NF;i++){words[$i]++}}END{for(j in words){print j}}' test4.txt

加入内置变量RS的不同值,可以获取更详细的单词,不再包括单词与标点符号的组合。

小结
在利用bash命令行获取文本文件的所有单词方面,应用grep法最简单最快速,有重要参考价值。而获取比较理想的效果最好采取awk方法,其可以加入多种不同的分隔符,用于详细分解由不同标点符号或连接符构成的长串字符。
运用循环方法,思路明确,但由于分隔符不易设置,不能有效得到满意结果。即使利用排序、去重等手段,也不能分解如http://www.pili zz.net这样的长字符串。