文章目录
- 论文详解
- Overall pipeline
- Multi-Dconv Head Transposed Attention
- Gated-Dconv Feed-Forward Network
- 代码详解
论文:《Restormer: Efficient Transformer for High-Resolution Image Restoration》
代码:https://github.com/swz30/Restormer
论文详解
本文的目标是开发一个高效的Transformer模型,该模型可以处理高分辨率的图像,用于恢复任务。为了缓解计算瓶颈,我们引入了multi-head SA layer的关键设计和一个比单尺度网络Swin-IR的计算需求更小的multi-scale hierarchical module。
我们首先展示了我们的Restormer architecture的整体结构(见图2)。
然后我们描述了提出的Transformer Block的核心组件:
(a) multi-Dconv head transposed attention (MDTA)
(b)gated-Dconv feed-forward network (GDFN)
最后,我们提供详细的渐进训练方案,以有效地学习图像统计。
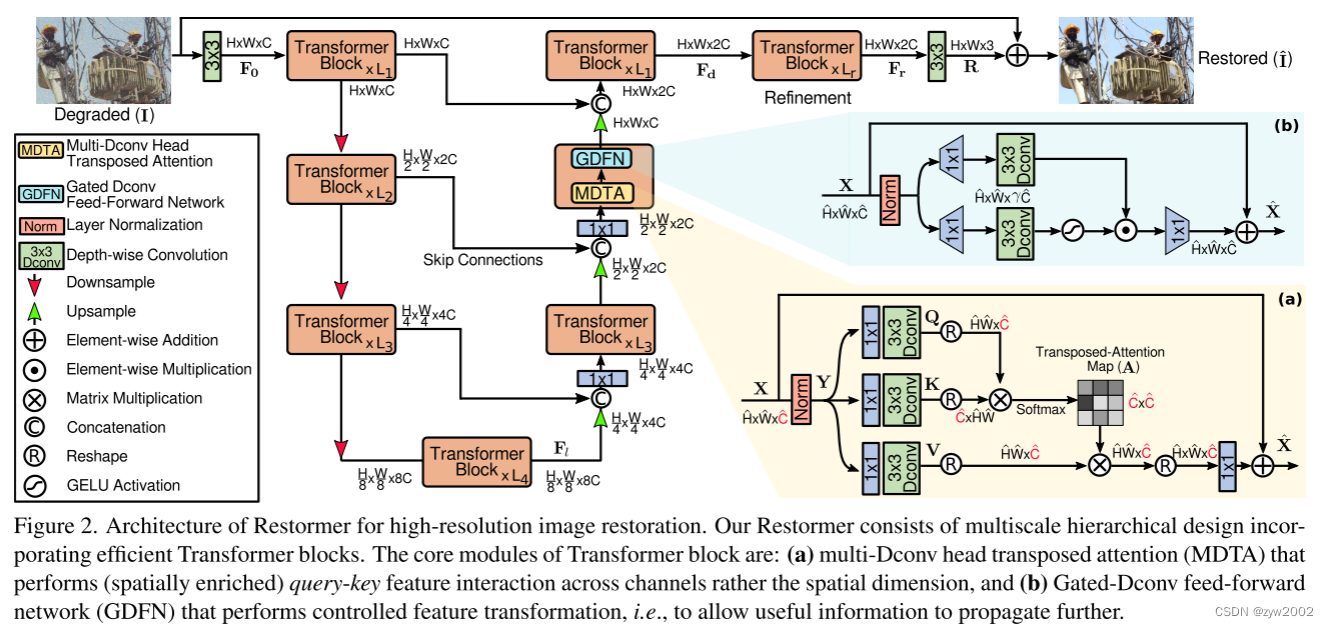
Overall pipeline
给定低质量图像 I ∈ R H × W × 3 I∈R^{H×W×3} I∈RH×W×3, Restoremer首先进行卷积,得到底层特征嵌入 F 0 ∈ R H × W × C F_0∈R^{H×W×C} F0∈RH×W×C; 其中 H×W为空间维数,C为通道数。接下来,这些浅层特征 F 0 F_0 F0经过一个4级对称encoder-decoder,转化为深层特征 F d ∈ R H × W × 2 C F_d∈R^{H×W×2C} Fd∈RH×W×2C。
encoder-decoder 的每个层都包含多个Transformer Block,其中块的数量从顶部到底部逐渐增加,以保持效率。从高分辨率输入开始,Encoder 分层地减少空间大小,同时扩大信道容量。该Decoder以低分辨率潜在特征 F l ∈ R H 8 × W 8 × 8 C F_l∈R^ {\frac{H}{8} ×\frac{W}{8} ×8C} Fl∈R8H×8W×8C为输入,并逐步恢复高分辨率表示。
对于特征下采样和上采样,我们分别采用了pixel-unshuffle和pixel-shuffle操作。
为了帮助恢复过程,encoder feature通过skip connections(Unet中提出的操作)连接到decoder freature。连接操作之后是1×1卷积,以在所有levels上减少通道(减半),除了最上面的levels。
在level-1,我们让Transformer Block将编码器的低级图像特征与解码器的高级特征聚合在一起。这种方法有利于在恢复后的图像中保持精细的结构和纹理细节。然后,在高空间分辨率的细化阶段进一步丰富深度特征 F d F_d Fd。
这些设计选择产生了质量上的改善,我们将在实验部分(第4节)中看到。最后,对精化的特征进行卷积层处理,生成残差图像 R ∈ R H × W × 3 R∈R^{H×W×3} R∈RH×W×3,在残差图像上加上退化图像,得到恢复后的图像: I ^ = I + R \hat I= I +R I^=I+R。接下来,我们将介绍Transformer模块的模块。
Multi-Dconv Head Transposed Attention
Transformer的主要计算开销来自于self-attention 层。在传统的SA中,key-query dot - product交互的时间和存储复杂度随输入的空间分辨率(即W×H) 像素图像的 O ( W 2 H 2 ) O(W^2H^2) O(W2H2)呈二次增长。
因此,将SA应用于大多数涉及高分辨率图像的图像恢复任务是不可行的。为了缓解这个问题,我们提出了MDTA,如图2(a)所示,它具有线性复杂度。关键因素是跨通道应用SA,而不是空间维度,即计算跨通道的cross-covariance,以生成隐式编码全局上下文的注意映射 作为MDTA的另一个重要组成部分,在计算feature covariance生成global attention map之前,我们引入depth-wise convolutions来强调local context。

从层归一化后的张量
Y
∈
R
H
^
×
W
^
×
C
^
Y∈R^{\hat H×\hat W×\hat C}
Y∈RH^×W^×C^中,我们的MDTA首先生成查询(Q)、键(K)和值(V) projection,丰富了local context。
它是通过应用1×1卷积来聚合pixel-wise cross-channel context,然后使用3×3 depth-wise convolution 来编码channel-wise spatial context,生成了 Q = W d Q W p Q Y , K = W d K W p K Y and V = W d V W p V Y \mathbf{Q}=W_d^Q W_p^Q \mathbf{Y}, \mathbf{K}=W_d^K W_p^K \mathbf{Y} \text { and } \mathbf{V}=W_d^V W_p^V \mathbf{Y} Q=WdQWpQY,K=WdKWpKY and V=WdVWpVY。 其中 W p ( . ) W_p(.) Wp(.) 是 1×1 point-wise convolution, W d ( . ) W_d(.) Wd(.)是3×3 depth-wise convolution。我们在网络中使用bias-free convolutional。
接下来,我们对query和key的projections进行reshape,使它们的dot-product interaction生成一个大小为 R C ^ × C ^ R^{\hat C×\hat C} RC^×C^的Transposed-Attention map (A),而不是大小为 R H ^ W ^ × H ^ W ^ R^{\hat H\hat W×\hat H \hat W} RH^W^×H^W^的大型regular attention map。
总体而言,MDTA流程定义为:
X ^ = W p A t t e n t i o n ( Q ^ , K ^ , V ^ ) + X A t t e n t i o n ( Q ^ , K ^ , V ^ ) = V ^ ⋅ Softmax ( K ^ ⋅ Q ^ / α ) \hat{\mathbf{X}}=W_p Attention (\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})+\mathbf{X}\\Attention (\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})=\hat{\mathbf{V}} \cdot \operatorname{Softmax}(\hat{\mathbf{K}} \cdot \hat{\mathbf{Q}} / \alpha) X^=WpAttention(Q^,K^,V^)+XAttention(Q^,K^,V^)=V^⋅Softmax(K^⋅Q^/α)
其中 X ^ \hat X X^ 和 X X X 是输出和输入的feature map, Q ^ ∈ R H ^ W ^ × C ^ ; K ^ ∈ R C ^ × H ^ W ^ ; and V ^ ∈ R H ^ W ^ × C ^ \hat{\mathbf{Q}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} ; \hat{\mathbf{K}} \in \mathbb{R}^{\hat{C} \times \hat{H} \hat{W}} ; \text { and } \hat{\mathbf{V}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} Q^∈RH^W^×C^;K^∈RC^×H^W^; and V^∈RH^W^×C^ 由原尺寸 R H ^ × W ^ × C ^ R^{\hat H×\hat W×\hat C} RH^×W^×C^对张量进行reshape 得到矩阵。在这里, α \alpha α 是一个可学习的标度参数,用于在应用Softmax函数之前控制 K ^ \hat K K^和 Q ^ \hat Q Q^的点积的大小。
与传统的多头SA相似,我们将通道的数量划分为“heads”,并同时学习不同的attention map。
Gated-Dconv Feed-Forward Network
为了变换特征,regular feed-forward network (FN) 分别相同地作用于每个像素位置。它使用两个1×1卷积,一个扩展feature channels (通常 扩展率 γ=4),另一个减少通道回到原始的输入维数。在隐藏层中应用了non-linearity。
在这项工作中,我们在FN中提出了两项基本修改,以改进representations learning: (1) gating mechanism (2) depthwise convolutions.
我们的GDFN体系结构如图2(b)所示。该gating mechanism 是parallel paths of linear transformation layers的element-wise product,其中一个被GELU non-linearity激活。

与MDTA一样,我们也在GDFN中包含depth-wise 来编码来自空间相邻像素位置的信息,这对于学习局部图像结构以便有效恢复非常有用。 上训练的模型在测试时显示出增强的性能,而图像可以具有不同的分辨率(图像恢复的常见情况)。渐进学习策略的行为与课程学习过程类似,即网络从一个较简单的任务开始,逐渐转向学习一个较复杂的任务(需要保持良好的图像结构/纹理)。由于对大补丁的训练需要花费更长的时间,所以随着补丁大小的增加,我们减少了批处理的大小,以便在每个优化步骤中保持与固定补丁训练相同的时间。
代码详解
to_3d
把4维的张量转换成3维的张量,输入形状(b,c,h,w), 输出形状(b,h*w,c)。
# (b,c,h,w)->(b,h*w,c)
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
to_4d
把3维的张量转换成4维的张量,输入形状(b,h*w,c), 输出形状(b,c,h,w)。
# (b,h*w,c)->(b,c,h,w)
def to_4d(x,h,w):
return rearrange(x, 'b (h w) c -> b c h w',h=h,w=w)
BiasFree_LayerNorm
实现了不带偏置的层归一化
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
# (b,h*w,c)
sigma = x.var(-1, keepdim=True, unbiased=False) # 计算矩阵x沿着最后一个维度的方差
'''
var: 计算方差的函数
-1: 表示最后一个维度
keepdim=True 表示保留维度
unbiased = False 表示使用有偏方差的计算方式
'''
return x / torch.sqrt(sigma+1e-5) * self.weight
WithBias_LayerNorm
实现了带偏置的层归一化
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True) # 计算均值
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.bias # 添加偏置
LayerNorm
最终的LayerNorm实现。先把输入的形状从(b,c,h,w)转为(b,h*w,c);然后再通过上述实现的带偏置的层归一化(WithBias_LayerNorm)或者不带偏置的层归一化(BiasFree_LayerNorm);最后再把形状变回原来输入的形状(b,c,h,w) 。
class LayerNorm(nn.Module): # 层归一化
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type =='BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x): # (b,c,h,w)
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
# to_3d后:(b,h*w,c)
# body后:(b,h*w,c)
# to_4d后:(b,c,h,w)
FeedForward
下面代码主要实现了Gated-Dconv Feed-Forward Network (GDFN)中红框的部分。
但是在代码实现部分,两条支路中的1x1的卷积(point-wise)和3x3的Dconv(depth-wise) 是在原始输入上一起做的,完成后再在通道维度分成两块。

class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
# point-wise convolution 1x1的卷积
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
# depth-wise convolution groups=in_channels
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
# 1x1 卷积
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x): # (b,c,h,w)
# point-wise convolution
x = self.project_in(x) # (b,hidden_features*2,h,w)
# depth-wise convolution
x1, x2 = self.dwconv(x).chunk(2, dim=1)
# dwconv后:(b,hidden_features*2,h,w)
# chunk后: x1和x2的大小均为(b,hidden_features,h,w)
# gelu激活函数 element-wise multiplication
x = F.gelu(x1) * x2# (b,hidden_features,h,w)
x = self.project_out(x) # (b,c,h,w)
return x
Attention
下面代码主要实现了Multi-DConv Head Transposed Self-Attention (MDTA)中的红框部分。

在代码实现上,用于生成k,q,v的三条支路中的1x1的卷积(point-wise)和3x3的Dconv(depth-wise) 是在原始输入上一起做的,完成后再在通道维度分成三块。
class Attention(nn.Module):
def __init__(self, dim, num_heads, bias):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) # 初始化是(num_heads,1,1)
# point-wise 1x1的卷积
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
# depth-wise groups=in_channels
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
def forward(self, x): # x: (b,dim,h,w)
b,c,h,w = x.shape
qkv = self.qkv_dwconv(self.qkv(x))
# qkv后:(b,3*dim,h,w)
# qkv_dwconv后: (b,3*dim,h,w)
q,k,v = qkv.chunk(3, dim=1)
# chunk后:q、k、v的大学均为(b,dim,h,w)
# (b,dim,h,w)->(b,num_head,c,h*w)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
# 在最后一维进行归一化
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
# (b,num_head,c,h*w) @ (b,num_head,h*w,c) -> (b,num_head,c,c)
# 然后乘以temperature这个可学习的参数(指的是注意力机制中的sqrt(d),d表示特征的维度)
attn = (q @ k.transpose(-2, -1)) * self.temperature # @ 表示数学中的矩阵乘法
# softmax 函数归一化,得到注意力得分
attn = attn.softmax(dim=-1) # (b,num_head,c,c)
# attn和v做矩阵乘法:(b,num_head,c,c) @ (b,num_head,c,h*w)->(b,num_head,c,h*w)
out = (attn @ v)
# reshape: (b,num_head,c,h*w)->(b,num_head*c,h,w)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
# 1x1conv: (b,dim,h,w)
out = self.project_out(out) # dim=c*num_head
return out # (b,c,h,w)
TransformerBlock
TransformerBlock就是把刚才实现的GDFN和MDTA分别添加上LN和残差连接后串联起来。
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):
super(TransformerBlock, self).__init__()
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.attn = Attention(dim, num_heads, bias)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
def forward(self, x): # (b,c,h,w)
x = x + self.attn(self.norm1(x))
# LN->GDTA->残差连接
x = x + self.ffn(self.norm2(x))
# LN->GDFN->残差连接
return x # (b,c,h,w)
OverlapPatchEmbed
通过一个3x3的卷积,把输入特征的通道数变成embed_dim
class OverlapPatchEmbed(nn.Module):
def __init__(self, in_c=3, embed_dim=48, bias=False):
super(OverlapPatchEmbed, self).__init__()
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, x): # (b,in_c,h,w)
x = self.proj(x) # (b,embed_dim,h,w)
return x
Downsample
下采样操作,输入形状(b,n_feat,h,w),输出形状(b,n_feat*2,h/2,w/2)
class Downsample(nn.Module):
def __init__(self, n_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2))
def forward(self, x):
#x: (b,n_feat,h,w)
# Conv2d后:(b,n_feat/2,h,w)
# PixelUnshuffle: (b,n_feat*2,h/2,w/2)
return self.body(x)
Upsample
上采样操作,输入形状(b,n_feat,h,w), 输出形状(b,n_feat/2,h*2,w*2)。
class Upsample(nn.Module):
def __init__(self, n_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2))
def forward(self, x):
# x: (b,n_feat,h,w)
#Conv2d后:(b,n_feat*2,h,w)
#PixelShuffle后:(b,n_feat/2,h*2,w*2)
return self.body(x)
Restormer
实现最终网络结构的部分。
class Restormer(nn.Module):
def __init__(self,
inp_channels=3,
out_channels=3,
dim = 48,
num_blocks = [4,6,6,8],
num_refinement_blocks = 4,
heads = [1,2,4,8],
ffn_expansion_factor = 2.66,
bias = False,
LayerNorm_type = 'WithBias', ## Other option 'BiasFree'
dual_pixel_task = False ## True for dual-pixel defocus deblurring only. Also set inp_channels=6
):
super(Restormer, self).__init__()
self.patch_embed = OverlapPatchEmbed(inp_channels, dim)
self.encoder_level1 = nn.Sequential(*[TransformerBlock(dim=dim, num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.down1_2 = Downsample(dim) ## From Level 1 to Level 2
self.encoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.down2_3 = Downsample(int(dim*2**1)) ## From Level 2 to Level 3
self.encoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.down3_4 = Downsample(int(dim*2**2)) ## From Level 3 to Level 4
self.latent = nn.Sequential(*[TransformerBlock(dim=int(dim*2**3), num_heads=heads[3], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[3])])
self.up4_3 = Upsample(int(dim*2**3)) ## From Level 4 to Level 3
self.reduce_chan_level3 = nn.Conv2d(int(dim*2**3), int(dim*2**2), kernel_size=1, bias=bias)
self.decoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.up3_2 = Upsample(int(dim*2**2)) ## From Level 3 to Level 2
self.reduce_chan_level2 = nn.Conv2d(int(dim*2**2), int(dim*2**1), kernel_size=1, bias=bias)
self.decoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.up2_1 = Upsample(int(dim*2**1)) ## From Level 2 to Level 1 (NO 1x1 conv to reduce channels)
self.decoder_level1 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.refinement = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_refinement_blocks)])
#### For Dual-Pixel Defocus Deblurring Task ####
self.dual_pixel_task = dual_pixel_task
if self.dual_pixel_task:
self.skip_conv = nn.Conv2d(dim, int(dim*2**1), kernel_size=1, bias=bias)
###########################
self.output = nn.Conv2d(int(dim*2**1), out_channels, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, inp_img): #(b,c,h,w)
inp_enc_level1 = self.patch_embed(inp_img) # (b,c,h,w)
# 4个 1-head TransformerBolock
out_enc_level1 = self.encoder_level1(inp_enc_level1) # (b,c,h,w)
inp_enc_level2 = self.down1_2(out_enc_level1) # (b,c*2,h/2,w/2)
# 6个 2-head TransformerBlock
out_enc_level2 = self.encoder_level2(inp_enc_level2) # (b,c*2,h/2,w/2)
inp_enc_level3 = self.down2_3(out_enc_level2) # (b,c*4,h/4,w/4)
# 6个 4-head TransformerBlock
out_enc_level3 = self.encoder_level3(inp_enc_level3) # (b,c*4,h/4,w/4)
inp_enc_level4 = self.down3_4(out_enc_level3) # (b,c*8,h/8,w/8)
# 8个 8-head TransformerBlock
latent = self.latent(inp_enc_level4)
inp_dec_level3 = self.up4_3(latent) # (b,c*4,h/4,w/4)
inp_dec_level3 = torch.cat([inp_dec_level3, out_enc_level3], 1) # (b,c*8,h/4,w/4)
inp_dec_level3 = self.reduce_chan_level3(inp_dec_level3) # (b,c*4,h/4,w/4)
# 6个 4-head TransformerBlock
out_dec_level3 = self.decoder_level3(inp_dec_level3) # (b,c*4,h/4,w/4)
inp_dec_level2 = self.up3_2(out_dec_level3) # (b,c*2,h/2,w/2)
inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1) # (b,c*4,h/2,w/2)
inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2) # (b,c*2,h/2,w/2)
# 6个 2-head TransformerBlock
out_dec_level2 = self.decoder_level2(inp_dec_level2) # (b,c*2,h/2,w/2)
inp_dec_level1 = self.up2_1(out_dec_level2) # (b,c,h,w)
inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1) # (b,2*c,h,w)
#4个 1-head TransformerBlock
out_dec_level1 = self.decoder_level1(inp_dec_level1) # (b,2*c,h,w)
#4个 1-head Transformer
out_dec_level1 = self.refinement(out_dec_level1) # (b,2*c,h,w)
#### For Dual-Pixel Defocus Deblurring Task ####
if self.dual_pixel_task:
out_dec_level1 = out_dec_level1 + self.skip_conv(inp_enc_level1)
out_dec_level1 = self.output(out_dec_level1)
###########################
else:
# 残差连接
out_dec_level1 = self.output(out_dec_level1) + inp_img #(b,c,h,w)
return out_dec_level1