文章目录
- 需求
- 思路:
- 步骤
- 伪代码
需求
从不同的csv文件中提取相同的列,然后合并成一个csv
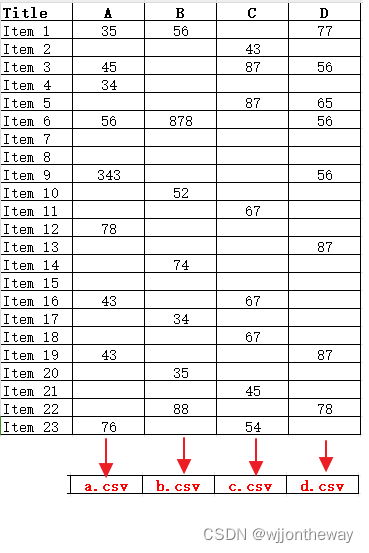
假设有这样一张csv, column A, B, C, D 的数据分别来自a.csv, b.csv, c.csv, d.csv指定的某一列数据。
Title 列的Items是之前的csv共有的
思路:
按列合成一个dict, 再转成Data Frame, 然后保存成csv文件
dict = {'Title':['Item 1', 'Item 2', ...],
'A': [xxx, yyy, zzz, ....],
'B': [xx, '', yy, '', zz, ....],
'C': [cc, aa, '', bb, ......]}
步骤
- Step 1. 定义一个dict: merge_dict = { }
- Step 1, 将标题组成一个key: value, {Title: [‘Item 1’, ‘Item 2’, ‘Item 3’…]}, 并更新merge_dict
- Step 2,先提取某个csv中指定的列, 按key = ‘A’, value = [xx, yy, zz, …] 继续更新merge_dict
- Step 3, 循环提取其他csv中指定的列, 更新merge_dict
- Step 4, 整个结束后,merge_ditc就是上述的样式
伪代码
merge_dict = {}
# open an csv
df = read_csv('a.csv')
# get the Title items list
title_items = df['Title'].to_list()
# update merge_dict
merge_dict['Title'] = title_items
# get related values in x.csv
for csv in csv_list:
df = pd.read_csv(csv)
common_column_data = df['common_column'].to_list()
column_name = csv.split('.')[0]
merge_dict[column_name ] = common_column_data
# convert dict to data Frame
df = pd.DataFrame(merge_dict )
# save to merged csv files
df.to_csv("merged.csv", index= False)