引言
💡本文为🔗[从零实现深度学习框架]系列文章内部限免文章,更多限免文章见 🔗专栏目录。
本着“凡我不能创造的,我就不能理解”的思想,系列文章会基于纯Python和NumPy从零创建自己的类PyTorch深度学习框架。
上篇文章中我们介绍了多头注意力,本文我们来了解Transformer Encoder模块剩下的组件,即残差连接、层归一化和前馈网络层。
Transformer架构
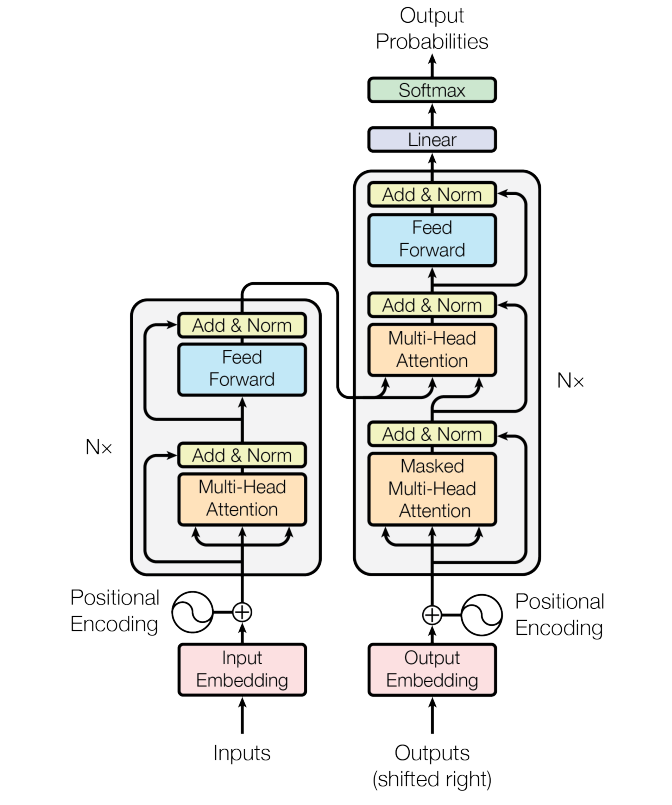
它也是一个encoder-decoder架构,左边是encoder,右边是decoder。我们先来看下它们内部的构件(从下到上)。
- Encoder
- Input Embedding:输入嵌入层
- Positional Encoding:位置编码
- Encoder Transformer Block:由于Encoder和Decoder的Block不同,这里区分来展开。
- Multi-Head Attention:多头注意力
- Add: 残差连接
- (Layer) Norm:层归一化
- (Position-wise) Feed Forward:位置级前馈网络
- 上面是一个Block包含的内容,由于设计成了输入和输出的维度一致,因此可以堆叠N个。
- Decoder
- Output Embedding:输出嵌入层
- Positional Encoding:位置编码
- Decoder Transformer Block
- Masked Multi-Head Attention:掩码多头注意力
- Add: 残差连接
- (Layer) Norm:层归一化
- Multi-Head Attention:多头注意力
- (Position-wise) Feed Forward:位置级前馈网络
- 上面是一个Block包含的内容,由于设计成了输入和输出的维度一致,因此可以堆叠N个。
- Linear:线性映射层
- Softmax:输出概率
再回顾一下Transformer架构,已经实现的用红色标出。
残差连接
残差连接(residual connection,skip residual,也称为残差块)其实很简单,如下图所示:
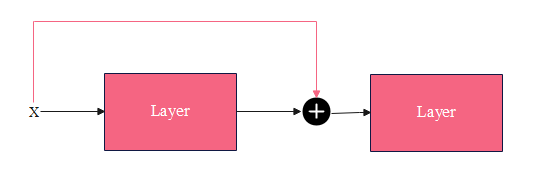
x
\pmb x
x为网络层的输入,该网络层包含非线性激活函数,记为
F
(
x
)
F(\pmb x)
F(x),用公式描述的话就是:
y
=
x
+
F
(
x
)
(1)
\pmb y = \pmb x + F(\pmb x) \tag 1
y=x+F(x)(1)
y
\pmb y
y是该网络层的输出,它作为第二个网络层的输入。有点像LSTM中的门控思想,输入
x
\pmb x
x没有被遗忘。
一般网络层数越深,模型的表达能力越强,性能也就越好。但随着网络的加深,也带来了很多问题,比如梯度消失、梯度爆炸。
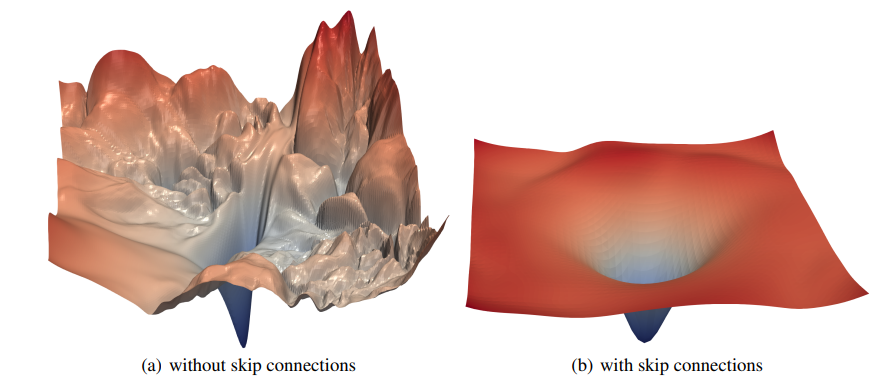
可以看出来,增加了残差连接后,损失平面更加平滑,没有那么多局部极小值。直观地看,有了残差连接了, x \pmb x x的信息可以直接传递到下一层,哪怕中间 F ( x ) F(\pmb x) F(x)是一个非常深的网络,只要它能学到将自己的梯度设成很小,不影响 x \pmb x x梯度的传递即可。
还有一些研究(Residual networks behave like ensembles of relatively shallow networks)表明,深层的残差网络可以看成是不同浅层网络的集成。
残差连接实现起来非常简单,就是公式 ( 1 ) (1) (1)的代码化:
x = x + layer(x)
层归一化
层归一化想要解决一个问题,这个问题在Batch Normalization的论文中有详细的描述(参考小节中有论文笔记,建议阅读原论文),即深层网络中内部结点在训练过程中分布的变化(Internal Covariate Shift,ICS,内部协变量偏移)问题。
如果神经网络的输入都保持同一分布,比如高斯分布,那么网络的收敛速度会快得多。但如果不做处理的话,这很难实现。由于低层参数的变化(梯度更新),会导致每层输入的分布也会在训练期间变化。
考虑有sigmoid激活函数 z = g ( W u + b ) z=g(Wu+b) z=g(Wu+b)的网络层,其中 u u u是该层的输入; W W W和 b b b是可学习的参数,且 g ( x ) = 1 1 + exp ( − x ) g(x) = \frac{1}{1 +\exp(-x)} g(x)=1+exp(−x)1。随着 ∣ x ∣ |x| ∣x∣增加, g ′ ( x ) g^\prime (x) g′(x)趋向于 0 0 0。这意味着对于 x = W u + b x = Wu+b x=Wu+b 中除了绝对值较小的维度之外的所有维度,流向 u u u的梯度将消失,导致模型训练缓慢。然而,因为 x x x也被 W , b W,b W,b和所有后续层的参数影响,在训练期间改变这些参数值也可能将 x x x的很多维度移动到非线性上的饱和区域(见下图红线位置),减缓收敛速度。这种影响还会随着网络层数的加深而增强。实际中,该饱和和梯度消失问题通常通过使用ReLU激活单元来解决,并且需要小心地初始化,以及小的学习率,这也会导致训练过慢。
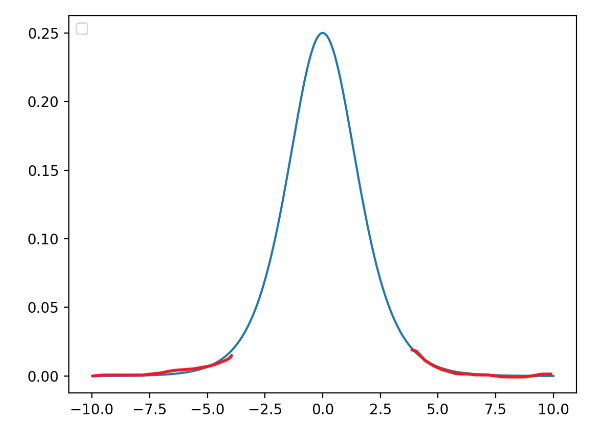
批归一化首先被提出来通过在深度神经网络中包含额外的归一化阶段来减少训练时间。批归一化通过使用训练数据中每个批次输入的均值和标准差来归一化每个输入。它需要计算累加输入统计量的移动平均值。在具有固定深度的网络中,可以简单地为每个隐藏层单独存储这些统计数据。针对的是同一个批次内所有数据的同一个特征。
然而批归一化并不适用于处理NLP任务的RNN(Transformer)中,循环神经元的累加输入通常会随着序列的长度而变化,而且循环神经元的需要计算的次数是不固定的(与序列长度有关)。
通常在NLP中一个批次内的序列长度各有不同,所以需要进行填充,存在很多填充token。如果使用批归一化,则容易受到长短不一中填充token的影响,造成训练不稳定。而且需要为序列中每个时间步计算和存储单独的统计量,如果测试序列不任何训练序列都要长,那么这也会是一个问题。
而层归一化针对的是批次内的单个序列样本,通过计算单个训练样本中一层的所有神经元(特征)的输入的均值和方差来归一化。没有对批量大小的限制,因此也可以应用到批大小为 1 1 1的在线学习。
批归一化是不同训练数据之间对单个隐藏单元(神经元,特征)的归一化,层归一化是单个训练数据对同一层所有隐藏单元(特征)之间的归一化。对比见下图:
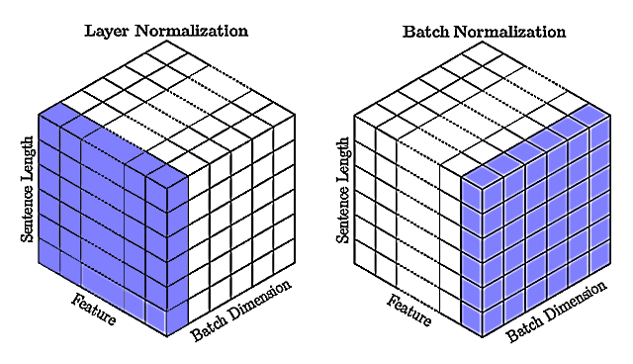
如上图右所示,批归一化针对批次内的所有数据的单个特征(Feature);层归一化针对批次内的单个样本的所有特征,它们都包含所有时间步。
说了这么多,那么具体是如何计算层归一化的呢?
y
=
x
−
E
[
x
]
Var
[
x
]
+
ϵ
⋅
γ
+
β
(2)
\pmb y = \frac{\pmb x -E[\pmb x]}{\sqrt{\text{Var}[\pmb x] + \epsilon}} \cdot \pmb\gamma + \pmb\beta \tag 2
y=Var[x]+ϵx−E[x]⋅γ+β(2)
x
\pmb x
x是归一化层的输入;
y
\pmb y
y是归一化层的输出(归一化的结果);
γ \pmb \gamma γ和 β \pmb \beta β是为归一化层每个神经元(特征)分配的一个自适应的缩放和平移参数。这些参数和原始模型一起学习,可以恢复网络的表示。通过设置 γ ( k ) = Var [ x ( k ) ] \gamma^{(k)} = \sqrt{\text{Var}[\pmb x^{(k)}]} γ(k)=Var[x(k)]和 β ( k ) = E [ x ( k ) ] \beta^{(k)}=E[\pmb x^{(k)}] β(k)=E[x(k)],可以会输入恢复成原来的激活值,如果模型认为有必要的话;
ϵ \epsilon ϵ是一个很小的值,防止除零。
class LayerNorm(Module):
def __init__(self, features: int, eps: float = 1e-6):
"""
Args:
features: 特征个数
eps:
"""
super().__init__()
self.gamma = Parameter(Tensor.ones(features))
self.beta = Parameter(Tensor.zeros(features))
self.eps = eps
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x: (batch_size, input_len, emb_size)
Returns:
"""
mean = x.mean(-1, keepdims=True)
std = x.std(-1, keepdims=True)
return self.gamma * (x - mean) / (std + self.eps) + self.beta
FFN
Position-wise Feed Forward(FFN),逐位置的前馈网络,其实就是一个全连接前馈网络。
它一个简单的两层全连接神经网络,不是将整个嵌入序列处理成单个向量,而是独立地处理每个位置的嵌入。所以称为position-wise前馈网络层。也可以看为核大小为1的一维卷积。
目的是把输入投影到特定的空间,再投影回输入维度。
class PositionWiseFeedForward(nn.Module):
'''
实现FFN网路
'''
def __init__(self, d_model, d_ff, dropout=0.1):
"""
Args:
d_model: 模型大小
d_ff: FF层的大小,2
dropout:
"""
super().__init__()
# 将输入转换为d_ff维度
self.linear1 = nn.Linear(d_model, d_ff)
# 将d_ff转换回d_model
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# 经过三次变换: 线性->非线性->线性
return self.dropout(self.linear2(F.relu(self.linear1(x))))
我们继续之前的例子:
import numpy as np
embed_dim = 512
vocab_size = 5000
num_heads = 8
# 第二个样本包含两个填充
input_data = Tensor(
np.array([[1, 2, 3, 4, 5], [6, 7, 8, 0, 0]])
)
# batch_size = 2
# seq_len = 5
batch_size, seq_len = input_data.shape
embedding = nn.Embedding(vocab_size, embed_dim)
# 模拟嵌入层
input_embeds = embedding(input_data)
mask = generate_mask(input_data)
attn = MultiHeadAttention(embed_dim=embed_dim, num_heads=num_heads)
ffn = PositionWiseFeedForward(embed_dim, d_ff=2048)
# 编码器中,query、key、value来自同一个嵌入
values = attn(input_embeds, input_embeds, input_embeds, mask)
print(values.shape)
output = ffn(values)
print(values.shape)
(2, 5, 512)
(2, 5, 512)
可以看到FFN并没有改变输入的维度,下面通过全1输入证明它对每个位置的作用是一样的:
input_data = Tensor.ones(2, 5)
ffn = PositionWiseFeedForward(5, d_ff=2048)
ffn.eval() # 抑制dropout
print(ffn(input_data))
Tensor(
[[-2.9619 1.7855 2.1681 -1.176 -0.2168]
[-2.9619 1.7855 2.1681 -1.176 -0.2168]], requires_grad=True)
可以看到,由于这两个输入是完全一样的,它们经过这个FFN得到的结果也是一样的,这里要取消dropout,否则可能(被dropout后)不一样了。可以理解为这种线性变换同等地应用到输入的每个位置上。
Post-LN v.s. Pre-LN
在Transformer中应用层归一化时,通常有两种选择。即Post-Layer Normalization(Post-LN)和Pre-Layer Normalization(Pre-LN)。
所谓Post-LN,即原始的Transformer将层归一化放置在残差连接之间,这被称为是Post-Layer Normalization(Post-LN)的做法。
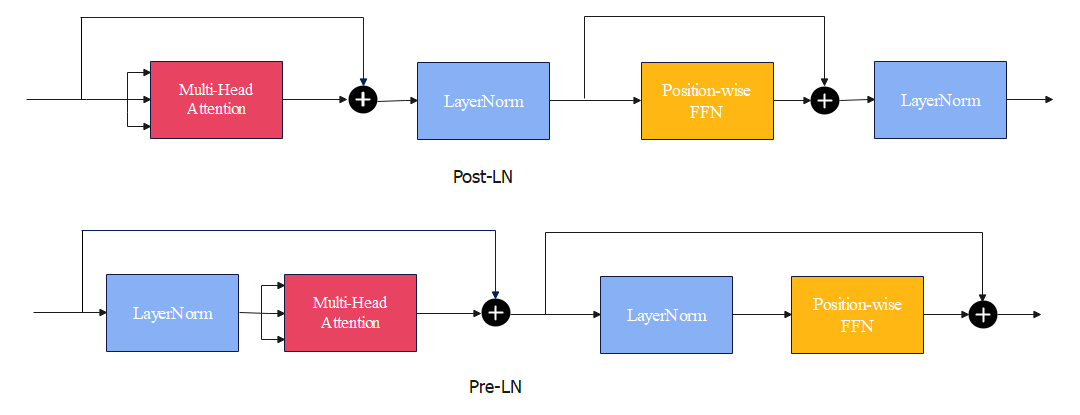
见上图中的Post-LN,可以看到层归一化在两个残差连接(块)中间;而Pre-LN的设计下层归一化在残差连接内部。
Post-LN也是Transformer的默认做法。但这种方式很从零开始训练,把层归一化放到残差块之间,接近输出层的参数的梯度往往较大。然后在那些梯度上使用较大的学习率会使得训练不稳定。通常需要用到学习率预热(warm-up)技巧,在训练开始时学习率需要设成一个极小的值,然后在一些迭代后逐步增加,最后再持续衰减。同时还需要小心地初始化模型的参数。
将层归一化放到残差连接的范围内,即Pre-LN。这在训练期间往往更加稳定,收敛更快,并且通常不需要任何学习率预热。在论文ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE中有详细的介绍,也可以看后面的参考文章,论文作者说使用Pre-LN的方式可以安全地移除学习预热阶段。其实如果仔细看的话,输入流有可能直接流向最后的输出,残差连接内的网络层相当于不存在了,对于梯度也是一样。
但Pre-LN真的是又快又好吗?最近人们认为,Pre-LN虽然更容易训练,但最终效果往往不如Post-LN好。
我们来看Pre-LN对应的公式:
x
t
+
1
=
x
t
+
F
(
Norm
(
x
t
)
)
(3)
\pmb x_{t+1} = \pmb x_t +F(\text{Norm}(\pmb x_t)) \tag 3
xt+1=xt+F(Norm(xt))(3)
这里
Norm
\text{Norm}
Norm代表层归一化;
F
F
F表示另一个网络层,比如多头注意力或FFN,括号内的参数表示作为输入。
对它从
t
+
2
t+2
t+2处展开有:
x
t
+
2
=
x
t
+
1
+
F
(
Norm
(
x
t
+
1
)
)
=
x
t
+
F
(
Norm
(
x
t
)
)
+
F
(
Norm
(
x
t
+
1
)
)
\begin{aligned} \pmb x_{t+2} &= \pmb x_{t+1} +F(\text{Norm}(\pmb x_{t+1})) \\ &= \pmb x_t + F(\text{Norm}(\pmb x_{t})) +F(\text{Norm}(\pmb x_{t+1})) \end{aligned}
xt+2=xt+1+F(Norm(xt+1))=xt+F(Norm(xt))+F(Norm(xt+1))
实际上是增加了网络的"宽度",网络的深度并没有增加。因为当
t
t
t较大时,
x
t
+
1
\pmb x_{t+1}
xt+1与
x
t
\pmb x_t
xt的差别是很小的。
怎么理解网络的宽度呢?下图就可以很好地理解:
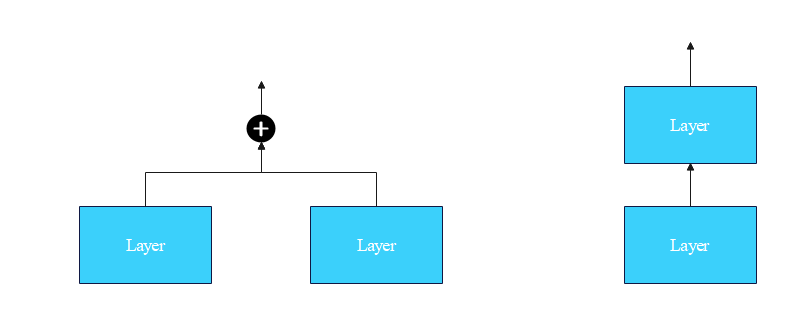
这样我们了解了实现Encoder Transformer Block的所有细节。实现起来就不难了,我们这里支持Post-LN和Pre-LN二选一。
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model: int, num_heads: int, dim_feedforward: int = 2048, dropout: float = 0.1,
norm_first: bool = False):
"""
Args:
d_model: 输入的特征个数
num_heads: 多头个数
dim_feedforward: FFN中的扩张的维度大小,通常会比d_model要大
dropout:
norm_first: 为True记为Pre-LN;默认为False对应的Post-LN。
"""
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionWiseFeedForward(d_model, dim_feedforward, dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.norm_first = norm_first
def forward(self, src: Tensor, src_mask: Tensor = None) -> Tensor:
x = src
if self.norm_first:
# 层归一化
x = self.norm1(x)
# 多头注意力 -> 残差连接
x = x + self.dropout1(self.attn(x, x, x, src_mask))
# 层归一化 -> FFN -> 残差连接
x = x + self.dropout2(self.feed_forward(self.norm2(x)))
else:
# 多头注意力 -> 残差连接 -> 层归一化
x = self.norm1(x + self.dropout1(self.attn(x, x, x, src_mask)))
x = self.norm2(x + self.dropout2(self.feed_forward(x)))
return x
我们测试一下前向传播:
import numpy as np
embed_dim = 512
vocab_size = 5000
num_heads = 8
# 第二个样本包含两个填充
input_data = Tensor(
np.array([[1, 2, 3, 4, 5], [6, 7, 8, 0, 0]])
)
# batch_size = 2
# seq_len = 5
batch_size, seq_len = input_data.shape
embedding = nn.Embedding(vocab_size, embed_dim)
# 模拟嵌入层
input_embeds = embedding(input_data)
mask = generate_mask(input_data)
encoder_layer = TransformerEncoderLayer(embed_dim, num_heads,dim_feedforward=2048)
output = encoder_layer(input_embeds, mask)
print(output.shape)
(2, 5, 512)
参考
- [论文翻译]Attention Is All You Need
- The Annotated Transformer
- Speech and Language Processing
- The Illustrated Transformer
- [论文笔记]Batch Normalization
- [论文笔记]Layer Normalization
- [论文笔记]ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE
- How does Layer Normalization work?