很有可能在某个时候,您需要将模型训练工作扩展到超过一个GPU。在上一个视频中,我强调了当您的模型变得太大而无法适应单个GPU时,您需要使用多GPU计算策略。但即使您的模型确实适合单个GPU,使用多个GPU加速训练也有好处。即使您正在使用小型模型,了解如何跨GPU分配计算也会很有用。让我们讨论如何有效地跨多个GPU进行这种扩展。
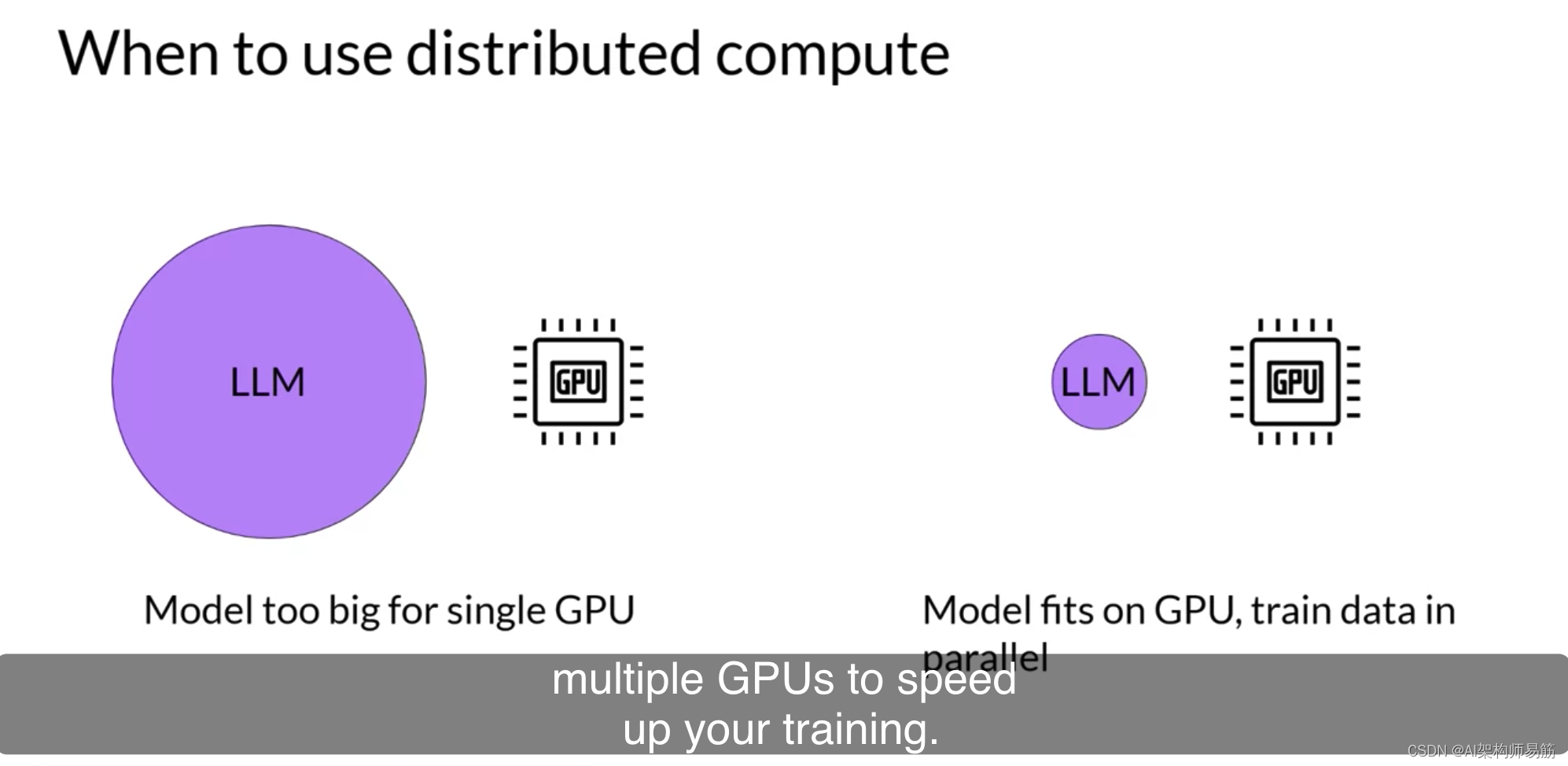
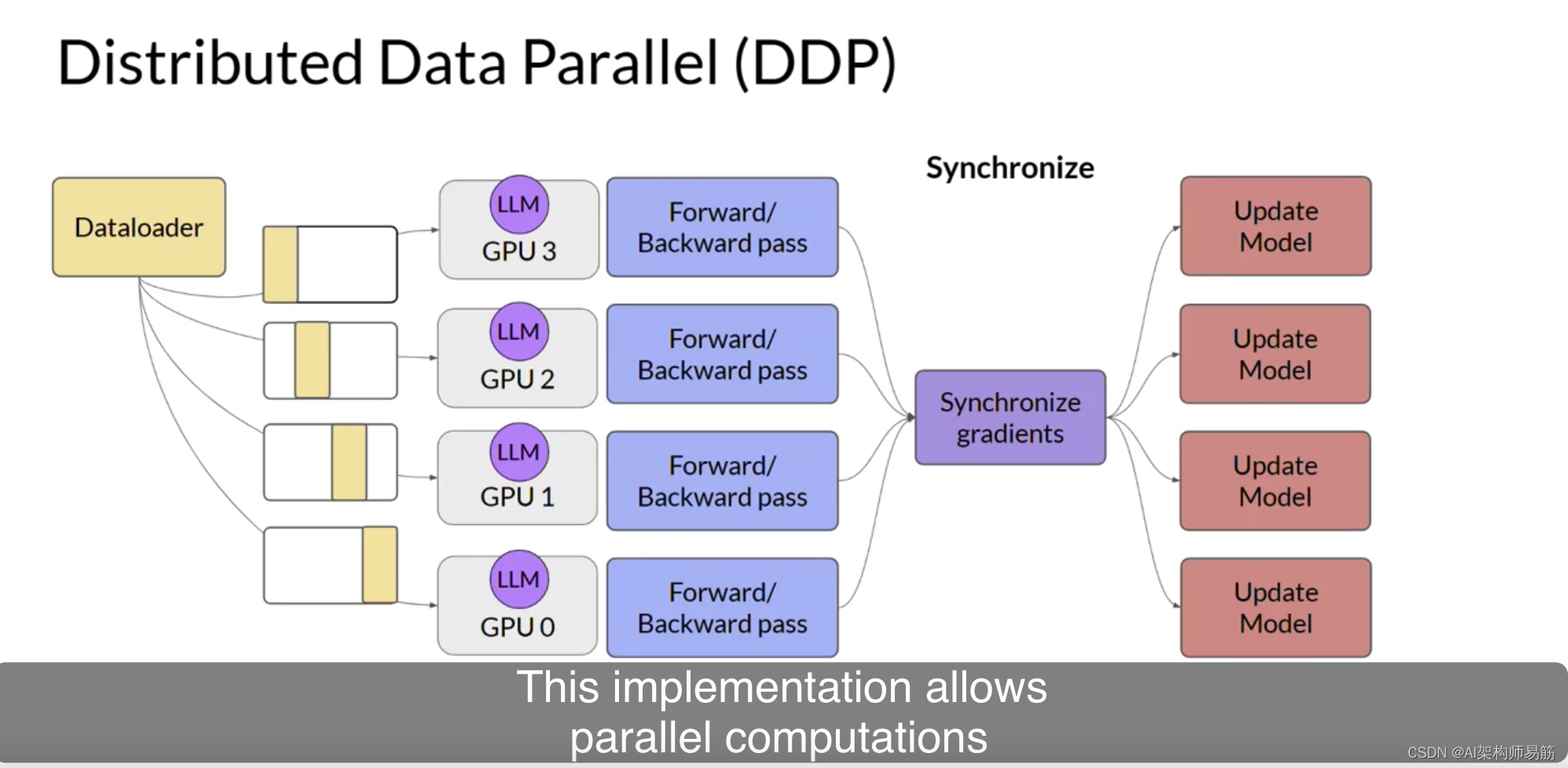
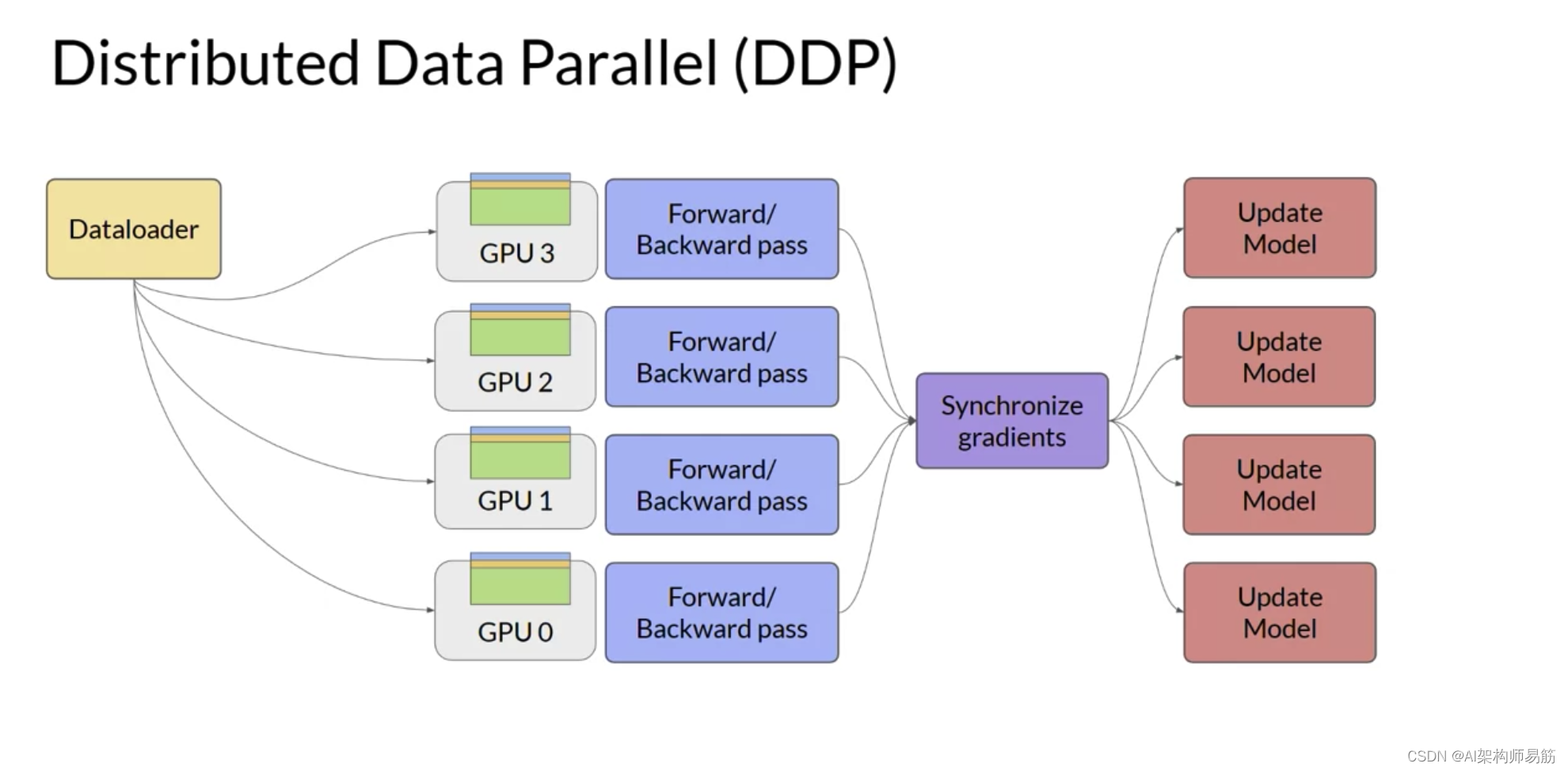
您将从考虑模型仍然适合单个GPU的情况开始。扩展模型训练的第一步是将大型数据集分布到多个GPU,并并行处理这些数据批次。这种模型复制技术的一个流行实现是PyTorch的Distributed Data Paraller分布式数据并行,或简称DDP。DDP将您的模型复制到每个GPU,并将数据批次并行发送到每个GPU。每个数据集并行处理,然后一个同步步骤组合每个GPU的结果,从而更新每个GPU上的模型,这在芯片之间始终是相同的。这种实现允许跨所有GPU进行并行计算,从而加快训练速度。请注意,DDP要求您的模型权重和所有其他训练所需的参数、梯度和优化器状态都适合单个GPU。
如果您的模型对此过大,您应该考虑另一种称为模型分片Model Sharded的技术。模型分片的一个流行实现是PyTorch的Fully Sharded Data Parallel完全分片数据并行,或简称FSDP。FSDP的动机是2019年由Microsoft研究人员发表的一篇论文,该论文提出了一种称为ZeRO的技术。ZeRO代表零冗余优化器,ZeRO的目标是通过分布或分片模型状态跨GPU与ZeRO数据重叠来优化内存。这允许您在模型不适合单个芯片的内存时,跨GPU缩放模型训练。

在回到FSDP之前,让我们快速看看ZeRO是如何工作的。
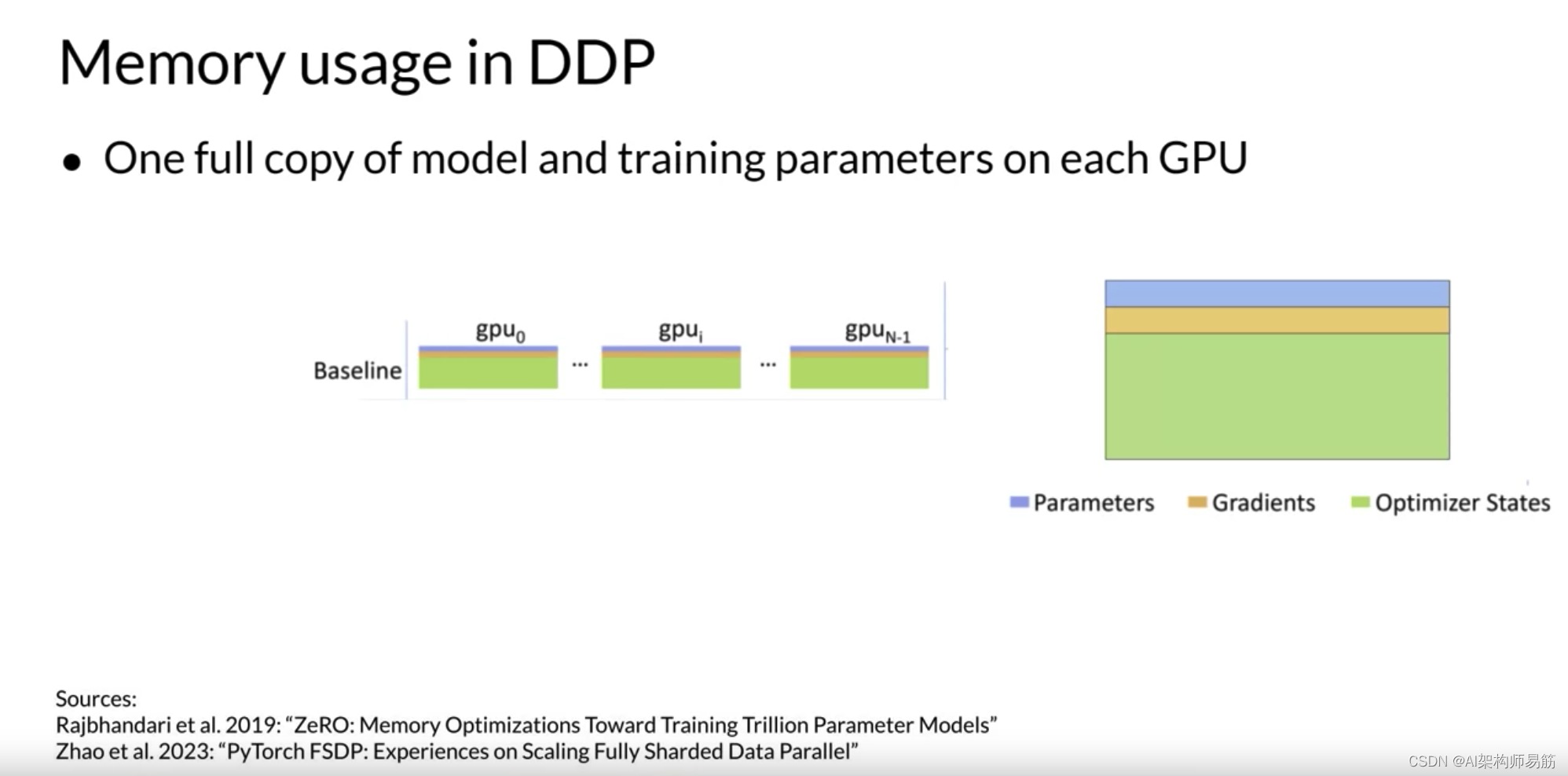
本周早些时候,您查看了训练LLM所需的所有内存组件,最大的内存需求是优化器状态,它占用的空间是权重的两倍,然后是权重本身和梯度。

让我们将参数表示为这个蓝色框,梯度为黄色,优化器状态为绿色。

我之前展示的模型复制策略的一个限制是您需要在每个GPU上保留一个完整的模型副本,这导致了冗余的内存消耗。您在每个GPU上存储相同的数字。
另一方面,ZeRO通过分布也称为分片模型参数、梯度和优化器状态跨GPU,而不是复制它们,从而消除了这种冗余。与此同时,沉没模型状态的通信开销接近之前讨论的Distributed Data Paraller (DDP)。
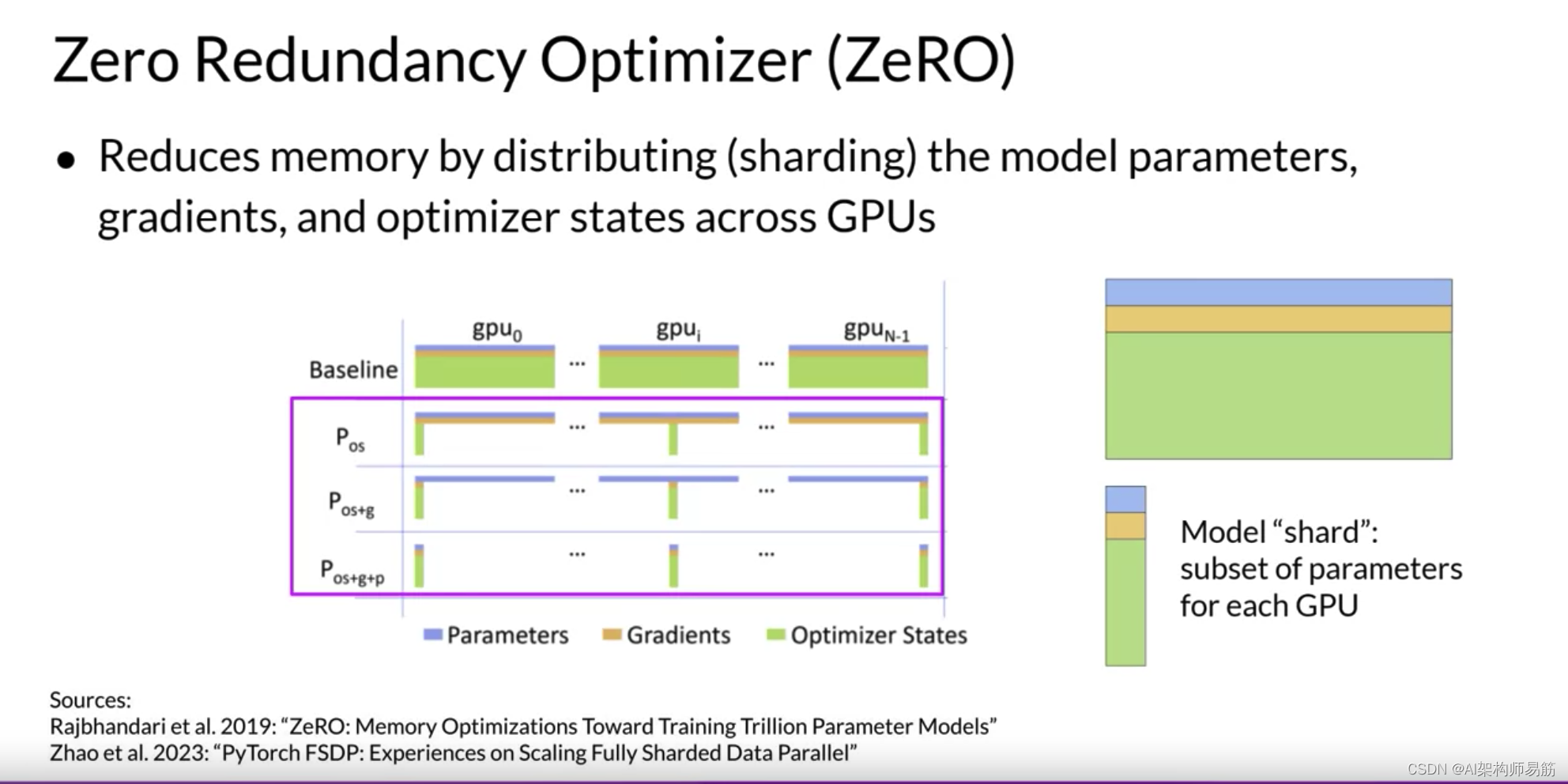
ZeRO提供了三个优化阶段。ZeRO阶段1仅跨GPU分片Optimizer States优化器状态,这可以将您的内存占用减少到四分之一。
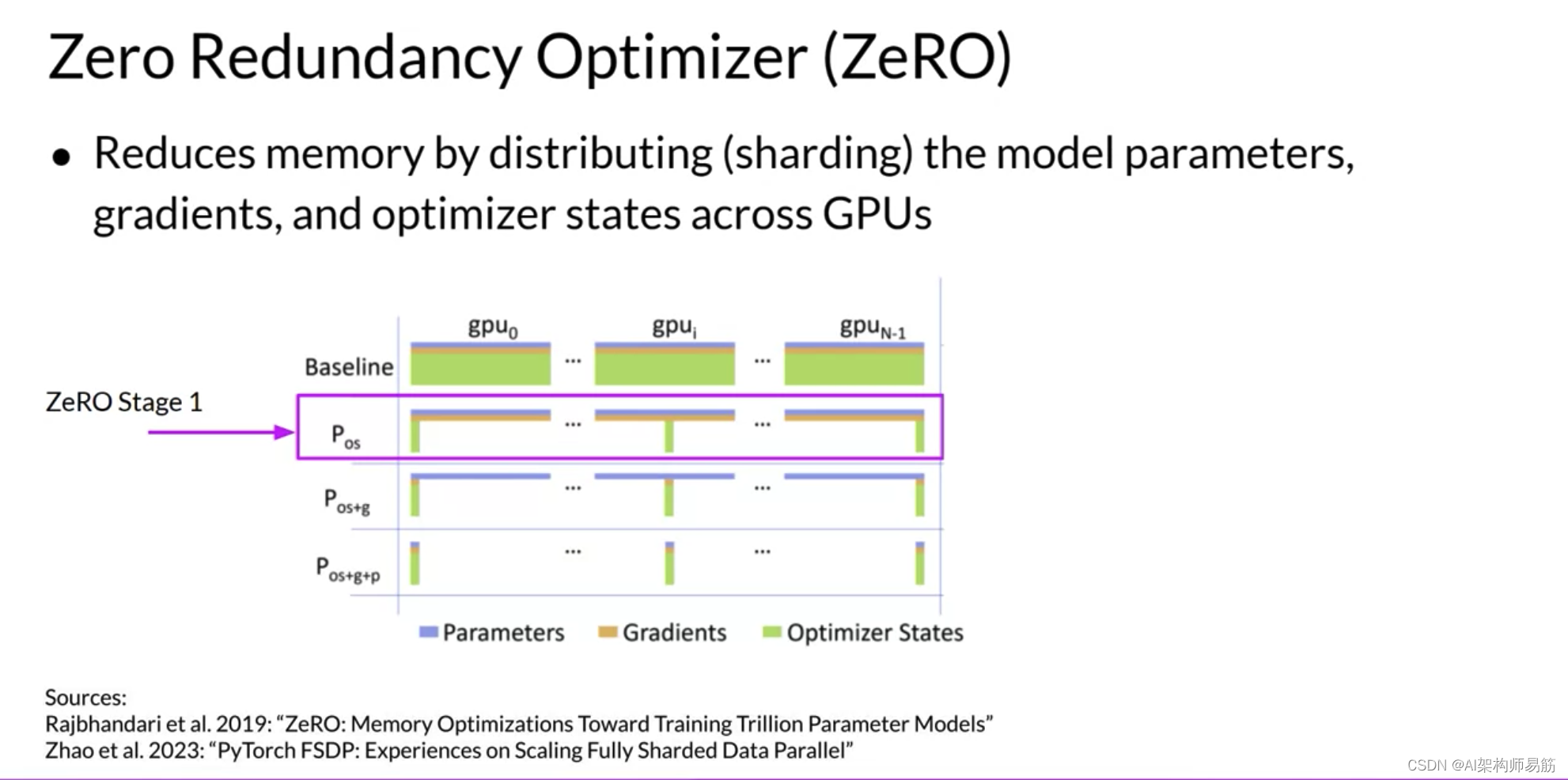
ZeRO阶段2还将Gradient梯度分片到芯片上。与阶段1一起应用时,这可以将您的内存占用减少到八倍。
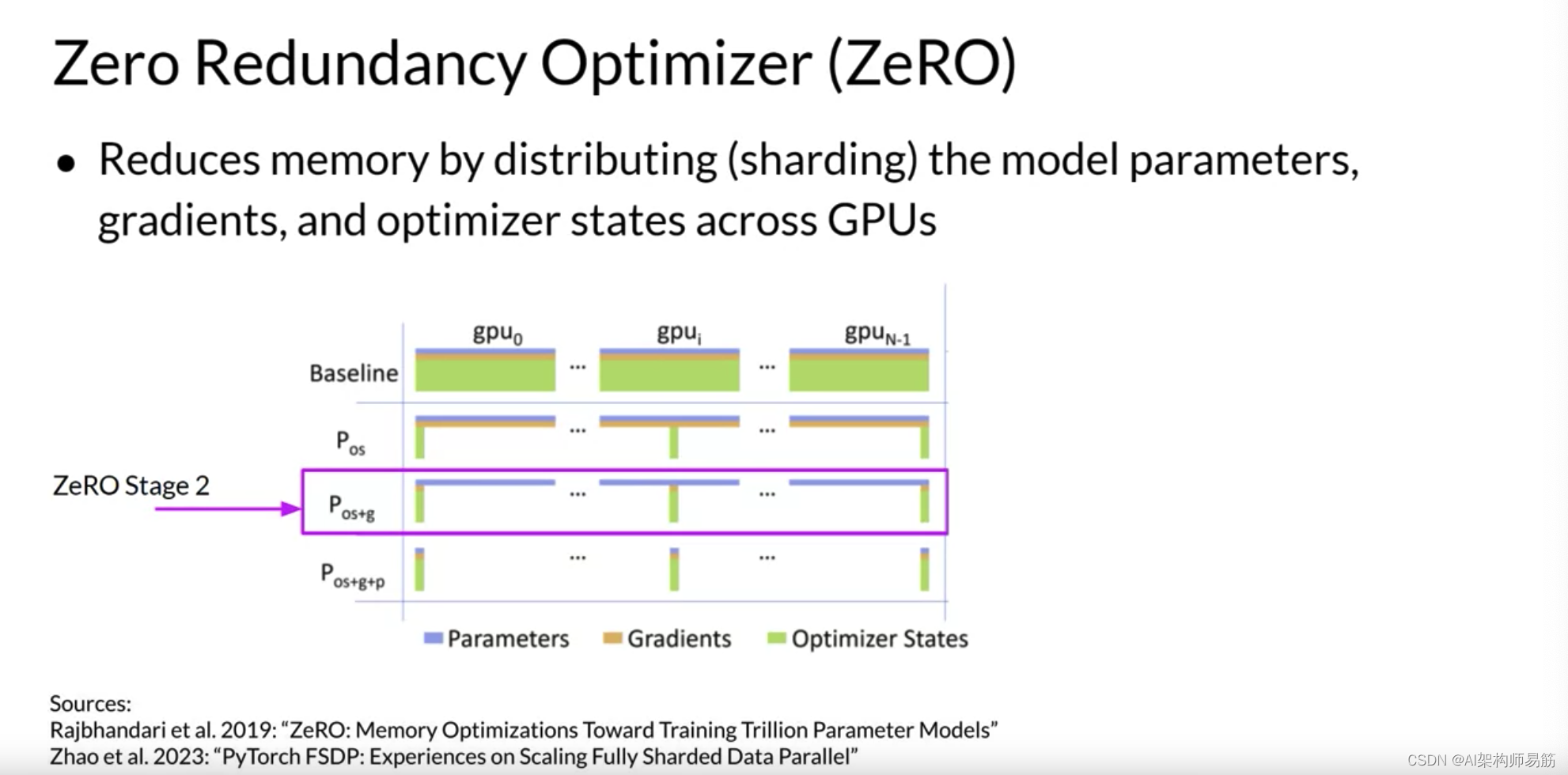
最后,ZeRO阶段3将所有组件(包括模型参数Parameters)分片到GPU上。与阶段1和2一起应用时,内存减少与GPU数量成线性关系。例如,跨64个GPU的分片可以将您的内存减少64倍。

让我们将这个概念应用到GDP的可视化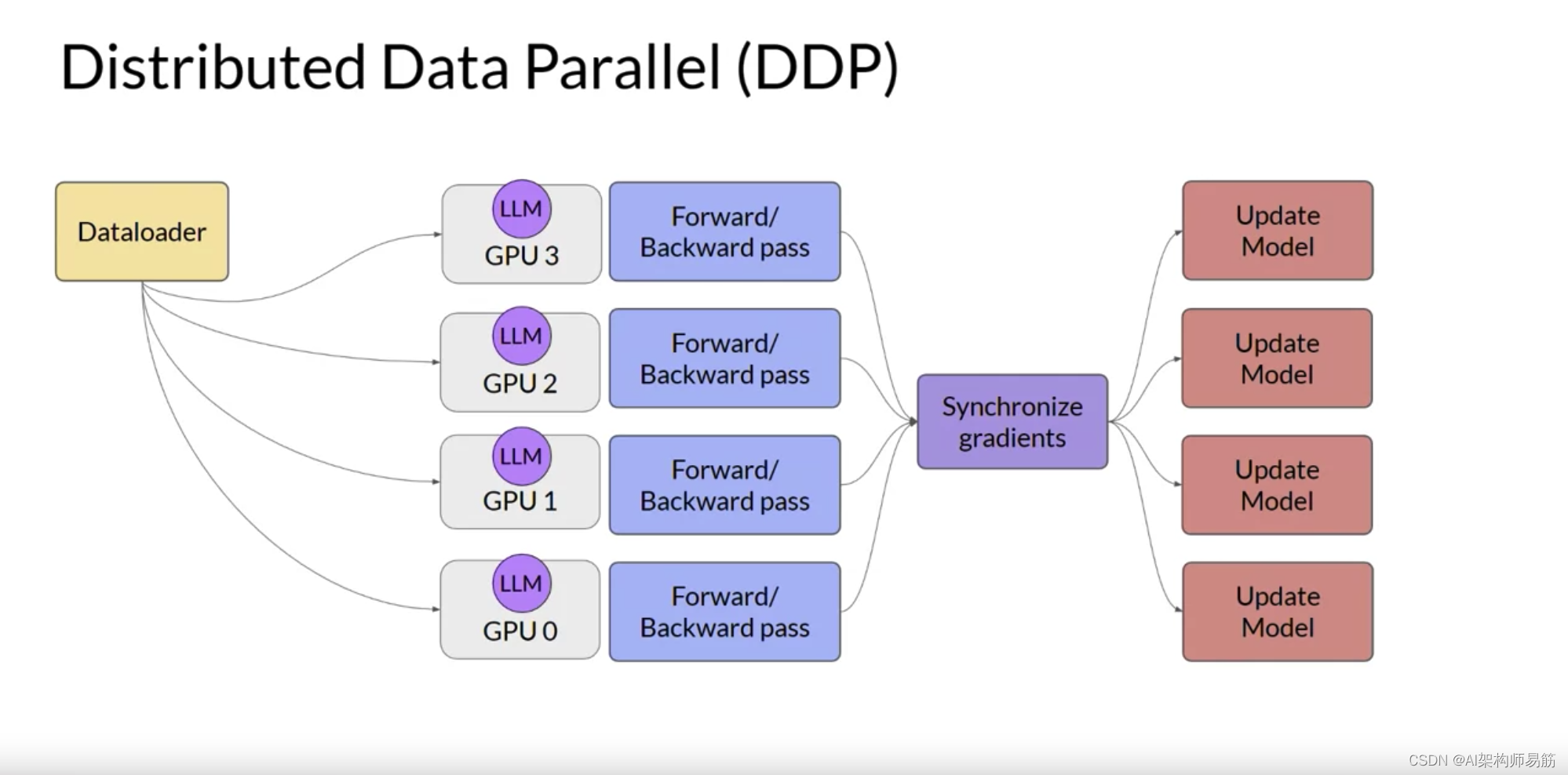
,
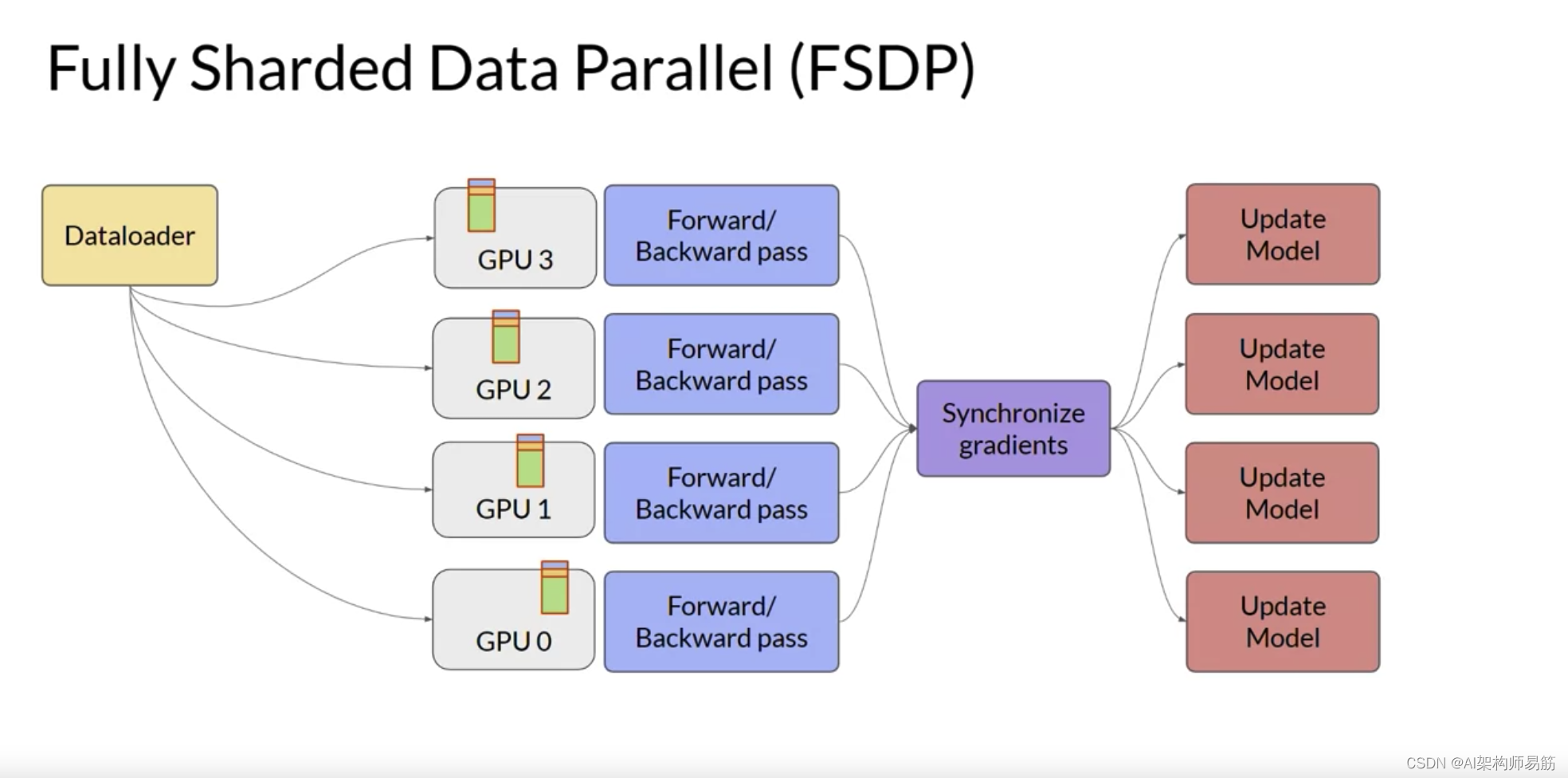
并用模型参数、梯度和优化器状态的内存表示替换LLM。当您使用FSDP时,您将数据分布到多个GPU,如您在DDP中看到的那样。
但是,使用FSDP,您还可以使用ZeRO论文中指定的策略之一,将模型参数、梯度和优化状态分布或分片到GPU节点上。使用这种策略,您现在可以使用太大而无法适应单个芯片的模型。
与DDP相反,其中每个GPU都有本地化处理每批数据所需的所有模型状态,FSDP要求您在前向和后向传递之前从所有GPU收集此数据。
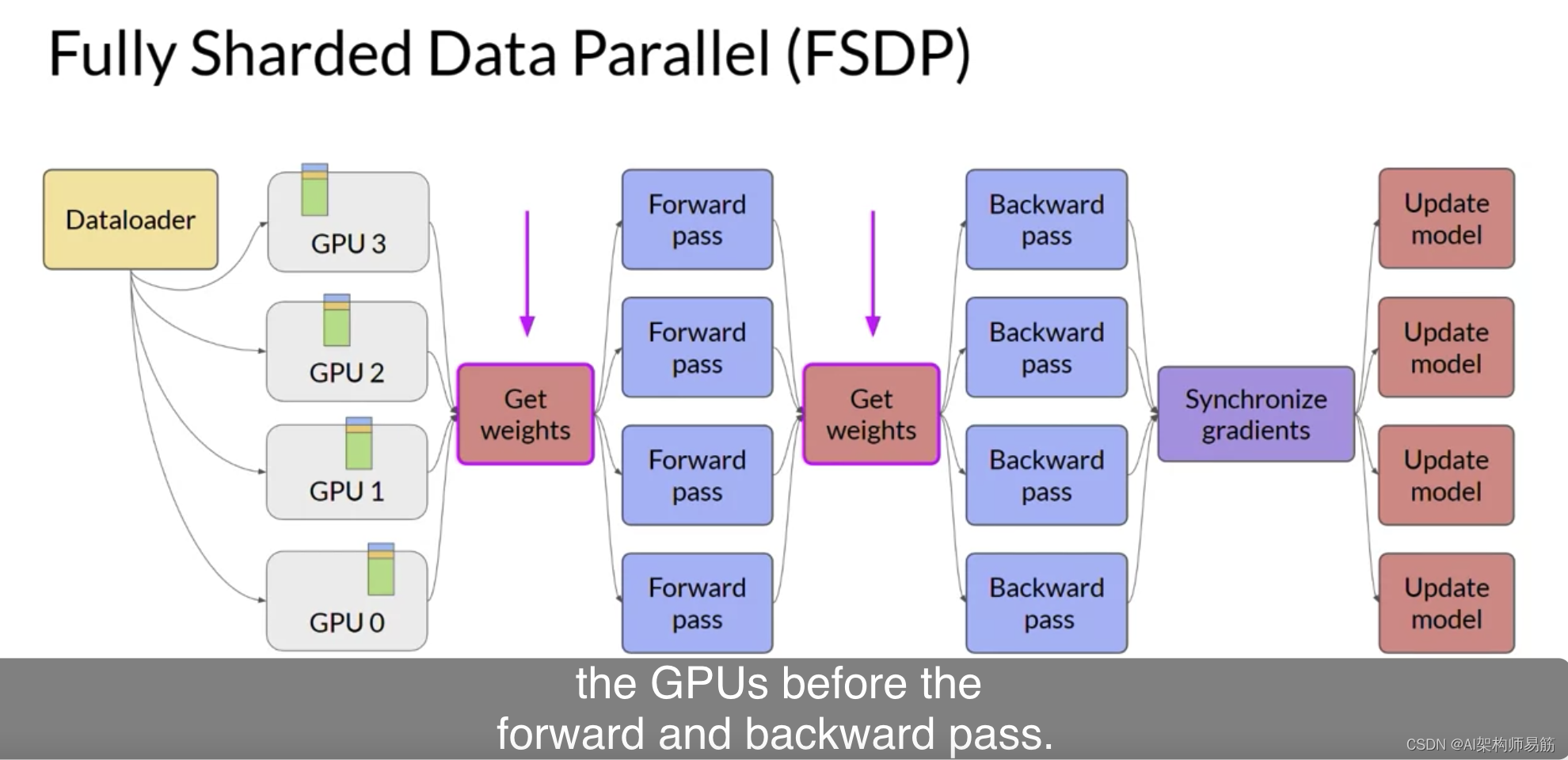
每个CPU按需从其他GPU请求数据,将分片数据转化为非分片数据以供操作使用。操作后,您将非分片的非本地数据释放回其他GPU作为原始分片数据。您还可以选择在后向传递期间为未来的操作保留它。注意,这需要更多的GPU RAM,这是一个典型的性能与内存权衡决策。
在后向传递后的最后一步,FSDP与DDP相同地跨GPU同步梯度。

如FSDP所描述的模型分片
- 允许您减少整体GPU内存使用。
- 您还可以选择让FSDP将部分训练计算卸载到GPU,以进一步减少GPU内存使用。
- 为了管理性能与内存使用之间的权衡,您可以使用FSDP的sharding factor分片因子配置分片级别。
分片因子为1基本上删除了分片并复制了与DDP类似的完整模型。

如果您将分片因子设置为可用GPU的最大数量,您将打开完整的分片。这节省了最多的内存,但增加了GPU之间的通信量。

中间的任何分片因子都启用了超分片。

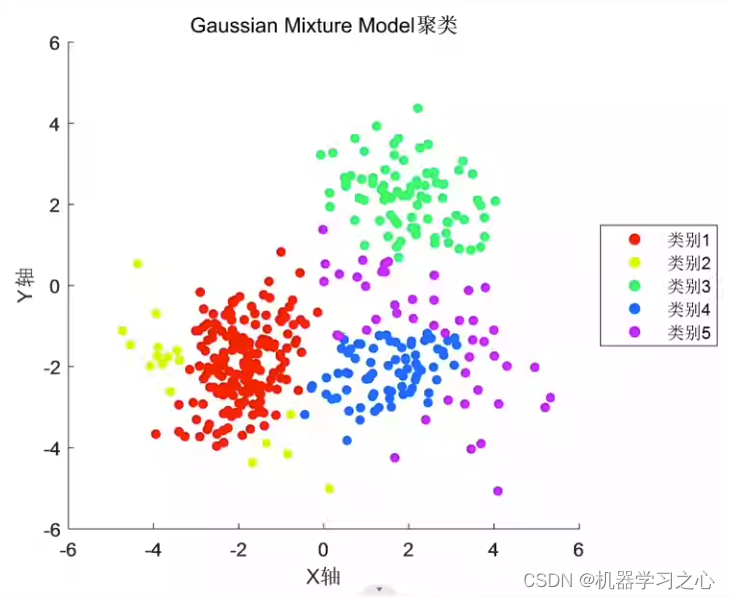
让我们看看FSDP与DDP在每个GPU的teraflops上的性能如何。这些测试使用最多512个NVIDIA V100 GPU执行,每个GPU有80GB的内存。注意,一个teraflop对应于每秒一万亿次
1
0
12
10^{12}
1012浮点运算。第一个数字显示了不同大小T5模型的FSDP性能。您可以看到FSDP的不同性能数字,完整分片为蓝色,超分片为橙色,完整复制为绿色。作为参考,DDP性能以红色显示。
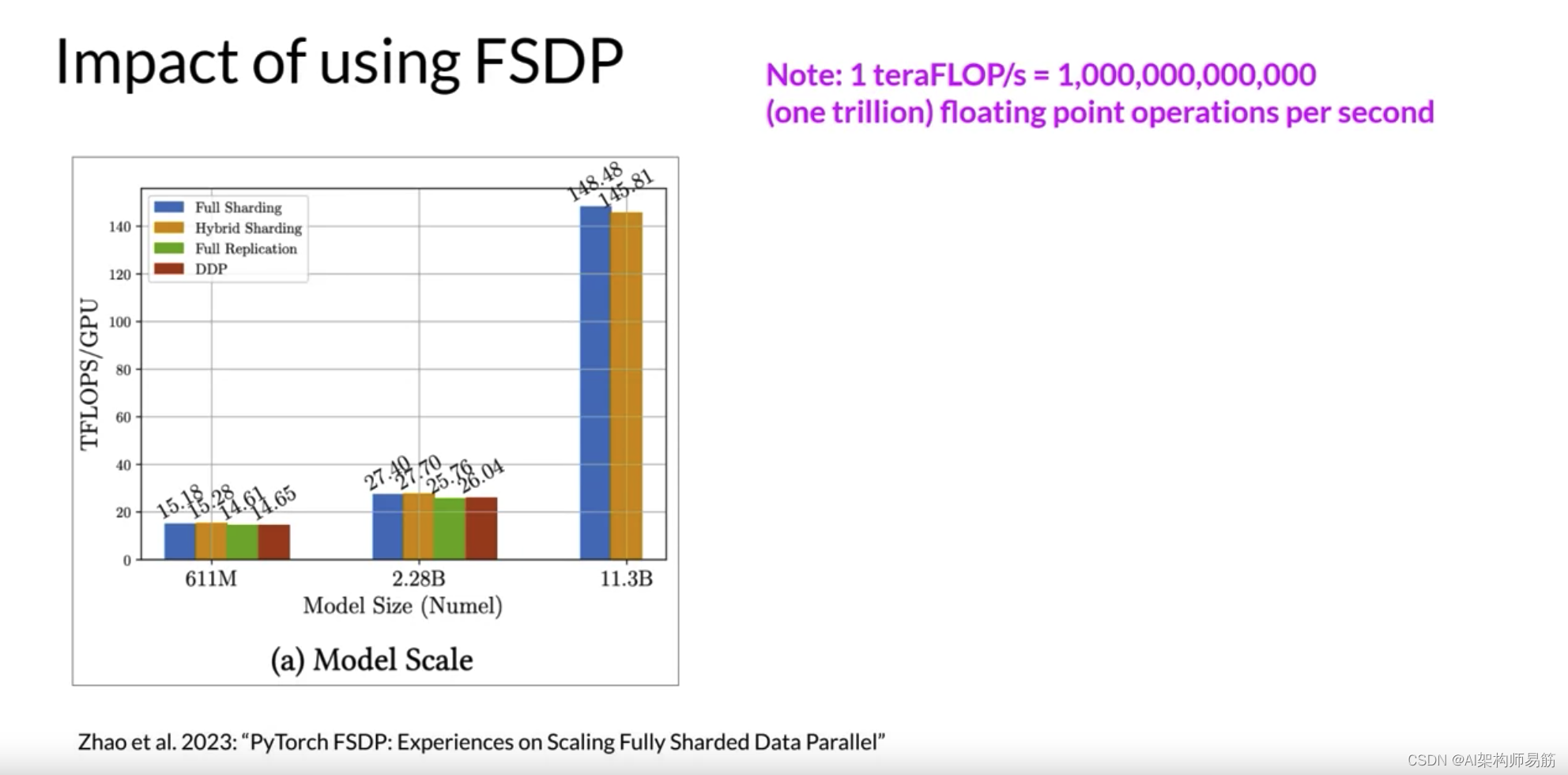
对于首先有611百万参数和22.8亿参数的25个模型,FSDP和DDP的性能相似。现在,如果您选择超过22.8亿的模型大小,例如25个模型有113亿参数,DDP会遇到内存不足的错误。另一方面,FSDP可以轻松处理这种大小的模型,并在将模型的精度降低到16位时获得更高的teraflops。
第二个数字显示了当增加GPU数量从8-512为11亿T5模型时,每个GPU teraflops减少了7%,
这里使用了批量大小为16的橙色和批量大小为8的蓝色。随着模型在大小上增长并分布到越来越多的GPU上,芯片之间的通信量增加开始影响性能,减慢计算。
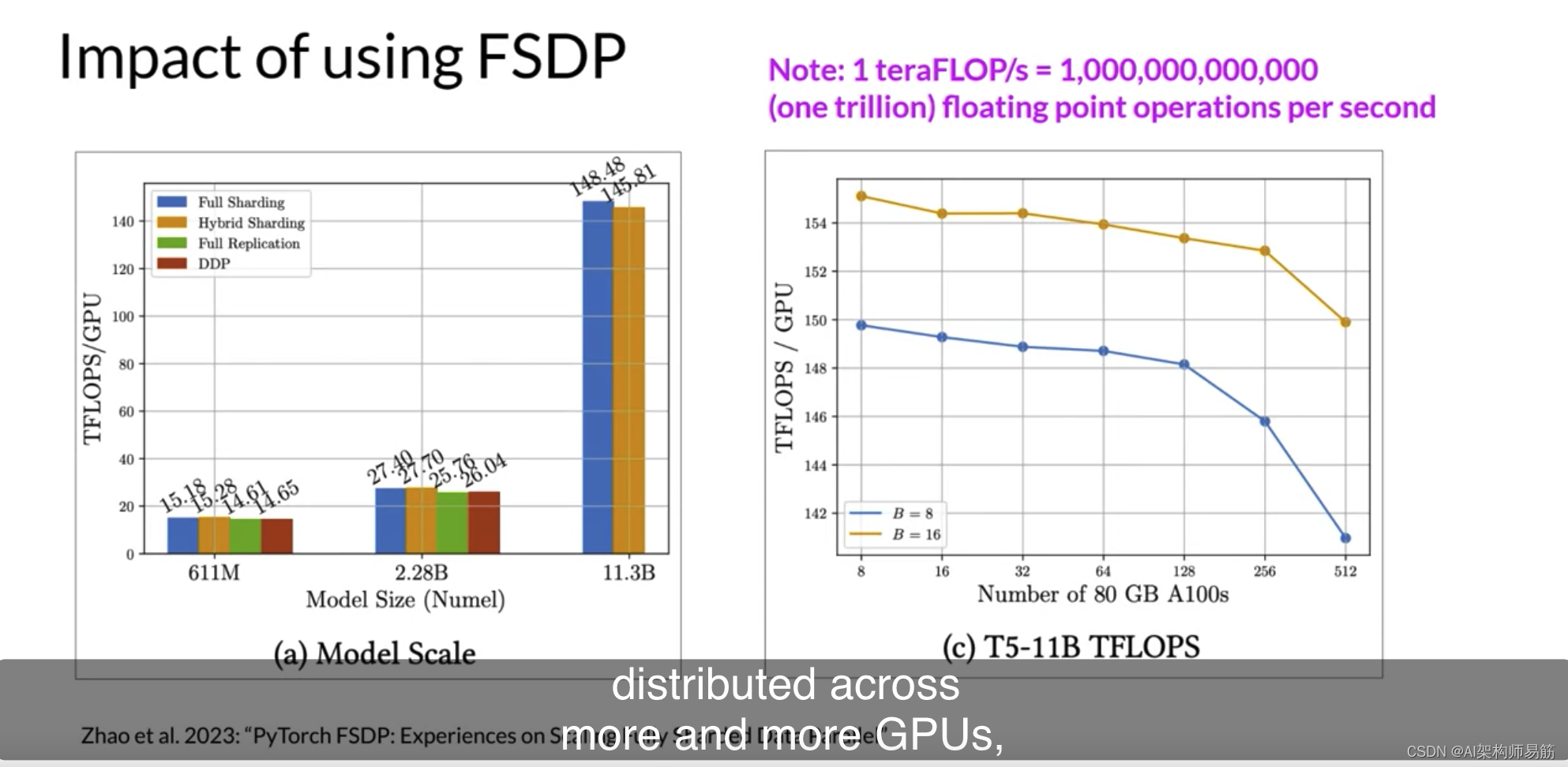
总之,这表明您可以使用FSDP进行小型和大型模型,并无缝地跨多个GPU扩展模型训练。
我知道这次讨论非常技术性,我想强调的是,您不需要记住所有的细节。最重要的是,当训练LLM时,了解数据、模型参数和训练计算如何跨进程共享。鉴于跨GPU训练模型的费用和技术复杂性,一些研究人员一直在探索如何使用较小的模型实现更好的性能。在下一个视频中,您将了解有关计算最佳模型的研究。让我们继续看下去。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/e8hbI/optional-video-efficient-multi-gpu-compute-strategies