1. 排序算法
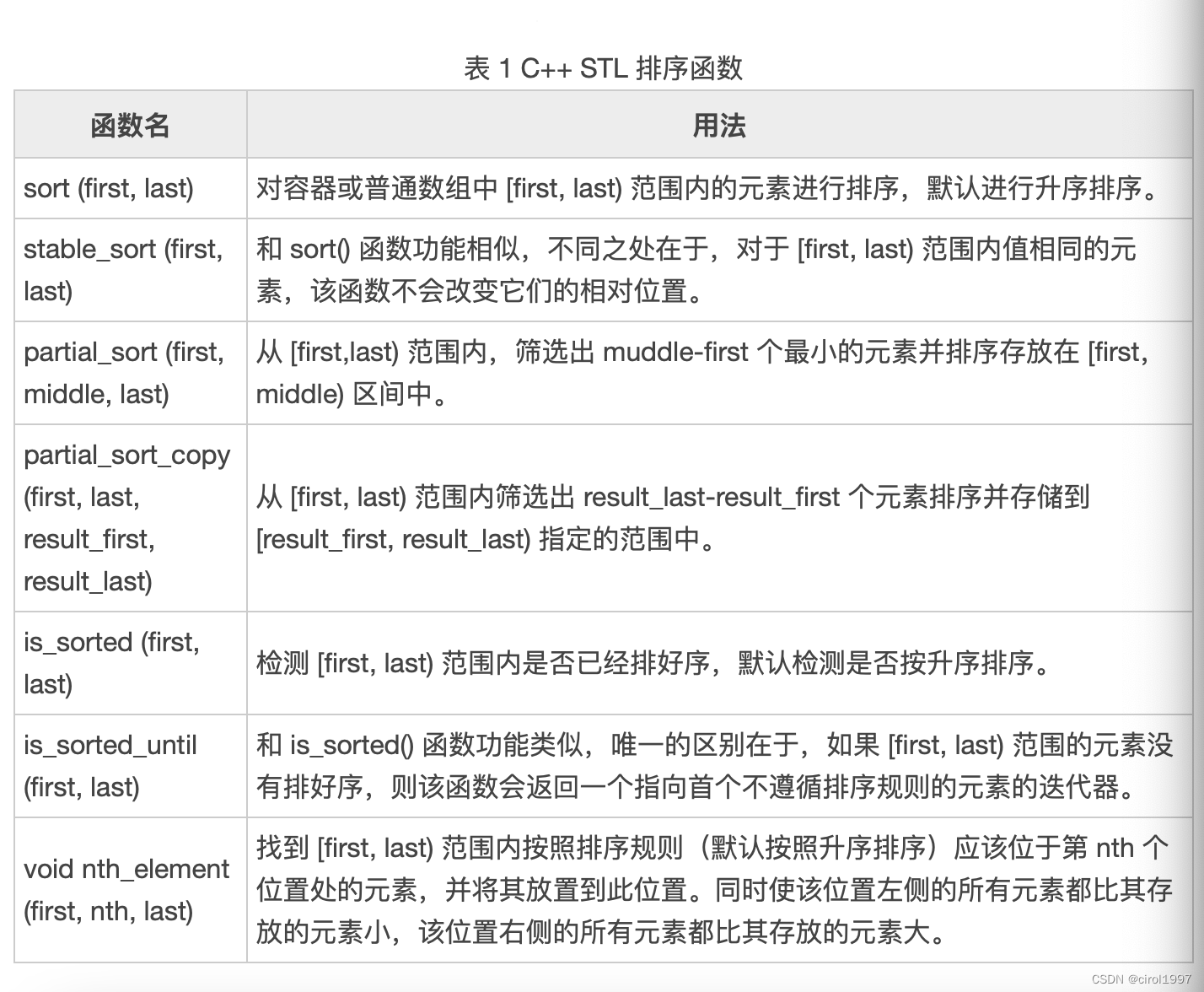
- sort() 函数是基于快速排序实现的,故不保证相对位置,但是stable_sort (first, last)保证,它基于归并排序。
- sort()只适用于支持随机迭代器的容器(array, vector, deque),好理解,毕竟用的快排
- 如果用默认的comp func排序,那么要支持 < (>) 重载
- 时间复杂度N*log2N
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
std::vector<int> myvector{ 32, 71, 12, 45, 26, 80, 53, 33 };
//调用第一种语法格式,对 32、71、12、45 进行排序
std::sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序
std::sort(myvector.begin(), myvector.begin() + 4, std::greater<int>()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序
std::sort(myvector.begin(), myvector.end(), mycomp2());//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
std::cout << *it << ' ';
}
return 0;
}
2. 找第N小的数nth_element()
//排序规则采用默认的升序排序
void nth_element (RandomAccessIterator first,
RandomAccessIterator nth,
RandomAccessIterator last);
//排序规则为自定义的 comp 排序规则
void nth_element (RandomAccessIterator first,
RandomAccessIterator nth,
RandomAccessIterator last,
Compare comp);
- 运行完之后会出现一个现象是:该函数会找到第 n 大的元素 K 并将其移动到第 n 的位置处,同时所有位于 K 之前的元素都比 K 大,所有位于 K 之后的元素都比 K 小。
- 同样和大小有关,基本上需要随机访问迭代器啦,那么也需要重载运算符咯。
- 原理:其实就是快排一样的方法,只是找到第n个数就停止了
3. 选出前n个大的元素
有一个存有 100 万个元素的容器,但我们只想从中提取出值最小的 10 个元素,该如何实现呢?
//按照默认的升序排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
//按照 comp 排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
Compare comp);
1 . partial_sort() 函数会以交换元素存储位置的方式实现部分排序的。具体来说,partial_sort() 会将 [first, last) 范围内最小(或最大)的 middle-first 个元素移动到 [first, middle) 区域中,并对这部分元素做升序(或降序)排序。
2. partial_sort采用的堆排序(heapsort),它在任何情况下的复杂度都是n*log(n). 如果你希望用partial_sort来实现全排序,你只要让middle=last就可以了。
4. 合适的排序算法

5. std::list排序,采用归并
参考下面的方法:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* merge(ListNode *head1,ListNode *head2) {
ListNode *n_head=new ListNode(0);
ListNode *h_head=n_head;
while(head1!=nullptr && head2!=nullptr) {
if(head1->val<head2->val) {
ListNode *temp=head1->next;
h_head->next=head1;
head1=temp;
} else if(head1->val>head2->val) {
ListNode *temp=head2->next;
h_head->next=head2;
head2=temp;
} else {
ListNode *temp=head1->next;
ListNode *temp1=head2->next;
h_head->next=head1;
h_head=h_head->next;
h_head->next=head2;
head1=temp;
head2=temp1;
}
h_head=h_head->next;
}
if(head1!=nullptr) {
h_head->next=head1;
} else if(head2!=nullptr) {
h_head->next=head2;
} else h_head->next=nullptr;
return n_head->next;
}
ListNode *helper(ListNode* head,ListNode *tail) {
if(head==nullptr) return head;
if(head->next==tail) {
head->next=nullptr;
return head;
}
ListNode *slow=head,*fast=head;
while(fast!=tail) {
slow=slow->next;
fast=fast->next;
if(fast!=tail) {
fast=fast->next;
}
}
ListNode *mid=slow;
return merge(helper(head,mid),helper(mid,tail));
}
ListNode* sortList(ListNode* head) {
return helper(head,nullptr);
}
};
说明:
1.归并,找到中间值用的快慢指针
2. 但实际STL里面的排序用的是非递归的归并,代码可参考:
https://blog.csdn.net/qq_31720329/article/details/85535787
3. 如果对std::list做排序用std::sort,那么实际上随机访问数值时需要逐个获取,时间复杂度也相当于n^2了
6. 排序算法优先使用函数对象
性能优势
对于排序算法,使用函数对象编译器可以直接进行内联,减少函数调用次数。而使用普通函数时,传入算法内部的实际是函数指针,编译器无法对其进行优化。
7.合并两个有序的容器
借助 merge() 或者 inplace_merge() 函数实现。
//以默认的升序排序作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
//以自定义的 comp 规则作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result, Compare comp);
- 当 2 个有序序列存储在同一个数组或容器中时,如果想将它们合并为 1 个有序序列,除了使用 merge() 函数,更推荐使用 inplace_merge() 函数。
8. 查找
- find()函数就不说了
- 和 find() 函数相同,find_if() 函数也用于在指定区域内执行查找操作。不同的是,前者需要明确指定要查找的元素的值,而后者则允许自定义查找规则。
std::vector<int> find_if_vec{4,2,3,1,5};
auto find_if_it = std::find_if(find_if_vec.begin(), find_if_vec.end(), [](int a){return a%2 == 0;});
std::cout << "find_if_it : " << *find_if_it << std::endl;
/* find_if_it : 4 */
- find_if_not()相反
- find_end()和 search() :find_end() 函数用于在序列 A 中查找序列 B 最后一次出现的位置, 序列 B 在序列 A 中第一次出现的位置,该如何实现呢?可以借助 search() 函数。
- search() 和 search_n() :用于在指定区域内查找第一个符合要求的子序列。不同之处在于,前者查找的子序列中可包含多个不同的元素,而后者查找的只能是包含多个相同元素的子序列。
关于 search() 函数和 search_n() 函数的区别,给大家举个例子,下面有 3 个序列:
序列 A:1,2,3,4,4,4,1,2,3,4,4,4
序列 B:1,2,3
序列 C:4,4,4
如果想查找序列 B 在序列 A 中第一次出现的位置,就只能使用 search() 函数;而如果想查找序列 C 在序列 A 中第一次出现的位置,既可以使用 search() 函数,也可以使用 search_n() 函数。
9. 数据分类partition()和stable_partition()
- 我理解类似快排只是比较的不是大小,是一种条件
- partition 可直译为“分组”,partition() 函数可根据用户自定义的筛选规则,重新排列指定区域内存储的数据,使其分为 2 组,第一组为符合筛选条件的数据,另一组为不符合筛选条件的数据。
ForwardIterator partition (ForwardIterator first,
ForwardIterator last,
UnaryPredicate pred);
- partition() 函数还会返回一个正向迭代器,其指向的是两部分数据的分界位置,更确切地说,指向的是第二组数据中的第 1 个元素。
#include <iostream> // std::cout
#include <algorithm> // std::partition
#include <vector> // std::vector
using namespace std;
//以普通函数的方式定义partition()函数的筛选规则
bool mycomp(int i) { return (i % 2) == 0; }
//以函数对象的形式定义筛选规则
class mycomp2 {
public:
bool operator()(const int& i) {
return (i%2 == 0);
}
};
int main() {
std::vector<int> myvector{1,2,3,4,5,6,7,8,9};
std::vector<int>::iterator bound;
//以 mycomp2 规则,对 myvector 容器中的数据进行分组
bound = std::partition(myvector.begin(), myvector.end(), mycomp2());
for (std::vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << " ";
}
cout << "\nbound = " << *bound;
return 0;
}
10. 二分查找lower_bound()函数
- 如 find()、find_if()、search() 等。值得一提的是,这些函数的底层实现都采用的是顺序查找(逐个遍历)的方式,在某些场景中的执行效率并不高.
- C++ STL标准库中还提供有 lower_bound()、upper_bound()、equal_range() 以及 binary_search() 这 4 个查找函数,它们的底层实现采用的都是二分查找的方式。
- lower_bound() 函数用于在指定区域内查找不小于目标值的第一个元素。也就是说,使用该函数在指定范围内查找某个目标值时,最终查找到的不一定是和目标值相等的元素,还可能是比目标值大的元素。
- 注意这个不小于可以自己定义。
- 再次强调,该函数仅适用于已排好序的序列。所谓“已排好序”,指的是 [first, last) 区域内所有令 element<val(或者 comp(element,val),其中 element 为指定范围内的元素)成立的元素都位于不成立元素的前面。
std::vector<int> lower_bound_vec{4,5,3,1,2};
auto lower_bound_vec_it = std::lower_bound(lower_bound_vec.begin(), lower_bound_vec.end(), 3, [](int i, int j) {return i >j; });
std::cout<< "lower_bound_vec_it = " << *lower_bound_vec_it<<std::endl;
/* 3 */
- 注意,myvector 容器中存储的元素看似是乱序的,但对于元素 3 来说,大于 3 的所有元素都位于其左侧,小于 3 的所有元素都位于其右侧,且查找规则选用的是 mycomp2(),其查找的就是第一个不大于 3 的元素,因此 lower_bound() 函数是可以成功运行的。
11. 二分查找upper_bound()函数
用于在指定范围内查找大于目标值的第一个元素。
举个例子,假设 有一个数组num:
1 2 2 2 3 4 5
value = 2
lower_bound 得到的是num[1]
uppper_bound得到的是nun[4]
12. 查找所有相等的元素
//找到 [first, last) 范围中所有等于 val 的元素
pair<ForwardIterator,ForwardIterator> equal_range (ForwardIterator first, ForwardIterator last, const T& val);
- 也要排好序
- 该函数会返回一个 pair 类型值,其包含 2 个正向迭代器。当查找成功时:
第 1 个迭代器指向的是 [first, last) 区域中第一个等于 val 的元素;
第 2 个迭代器指向的是 [first, last) 区域中第一个大于 val 的元素。
反之如果查找失败,则这 2 个迭代器要么都指向大于 val 的第一个元素(如果有),要么都和 last 迭代器指向相同。 - 我可以理解为第一个返回的是lower_bound获取的值,第二个是upper_bound获取的值
13. 检查算法
- 用来检查在算法应用到序列中的元素上时,什么时候使谓词返回 true
- all_of() 算法会返回 true,前提是序列中的所有元素都可以使谓词返回 true。
- any_of() 算法会返回 true,前提是序列中的任意一个元素都可以使谓词返回 true。
- none_of() 算法会返回 true,前提是序列中没有元素可以使谓词返回 true。
std::vector<int> none_of_vec{22, 19, 46, 75, 54, 19, 27, 66, 61, 33, 22, 19};
std::cout << "There are "
<< (std::none_of(none_of_vec.begin(), none_of_vec.end(), [](const int &i){return i == 18;}) ? "no" : "some")
<< " student age = 18 ."
<< std::endl;
/* There are no student age = 18 .*/
- 注意返回的是true or false
- count_if() 会返回可以使作为第三个参数的谓词返回 true 的元素个数。
14. copy_n(STL copy_n)算法详解
- copy_n() 算法可以从源容器复制指定个数的元素到目的容器中。第一个参数是指向第一个源元素的输入迭代器,第二个参数是需要复制的元素的个数,第三个参数是指向目的容器的第一个位置的迭代器
- 这个算法会返回一个指向最后一个被复制元素的后一个位置的迭代器
std::vector<int> none_of_vec{22, 19, 46, 75, 54, 19, 27, 66, 61, 33, 22, 19};
std::cout << "There are "
<< (std::none_of(none_of_vec.begin(), none_of_vec.end(), [](const int &i){return i == 18;}) ? "no" : "some")
<< " student age = 18 ."
<< std::endl;
/* There are no student age = 18 .*/
std::vector<std::string> names {"A1","George" ,"Harry", "Iain", "Beth","Carol", "Eve","Dan", "Joe","Fred"};
std::unordered_set<std::string> more_names {"Janet", "John"};
std::copy_n(std::rbegin(names)+1, 3, std::inserter(more_names, std::begin(more_names)));
/*
[0] = "Eve"
[1] = "Dan"
[2] = "Joe"
[3] = "John"
[4] = "Janet"
*/
- 还有copy_if
后面还有很多算法不想看了,其实都是基本的算法
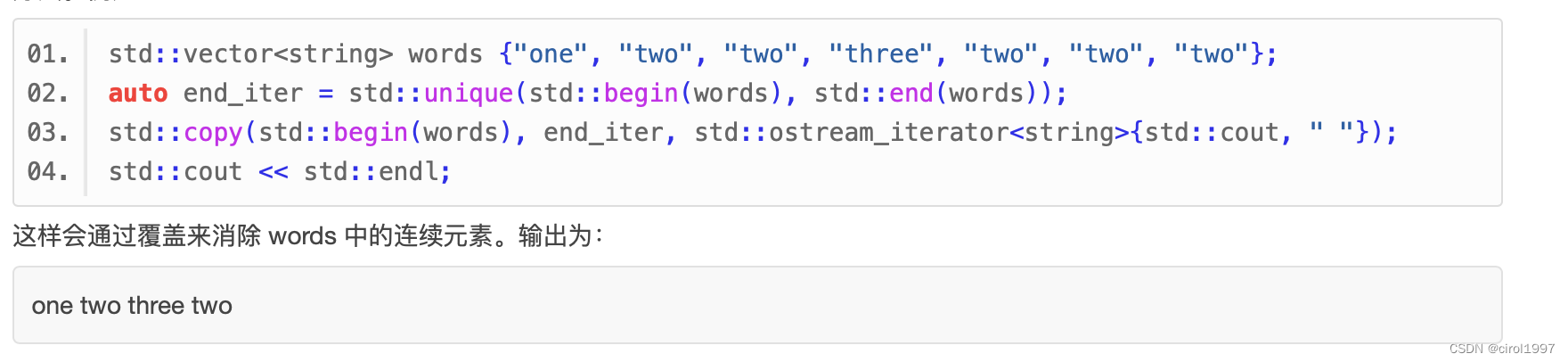
- unique() 算法可以在序列中原地移除重复的元素,这就要求被处理的序列必须是正向迭代器所指定的。在移除重复元素后,它会返回一个正向迭代器作为新序列的结束迭代器。可以提供一个函数对象作为可选的第三个参数,这个参数会定义一个用来代替 == 比较元素的方法。例如:



remove是覆盖的方法和uinque一样
条件相等 replace


![IAR编译报错 ErrorLi005]: no definition for](https://img-blog.csdnimg.cn/086232a918fe4f76b8648b95c4a201e7.png)