目录
一 什么是大数据?
二 大数据特征
三 分布式计算
四 Hadoop是什么?
五 Hadoop发展及版本
六 为什么要使用Hadoop
七 Hadoop vs. RDBMS
八 Hadoop生态圈
九 Hadoop架构
一 什么是大数据?
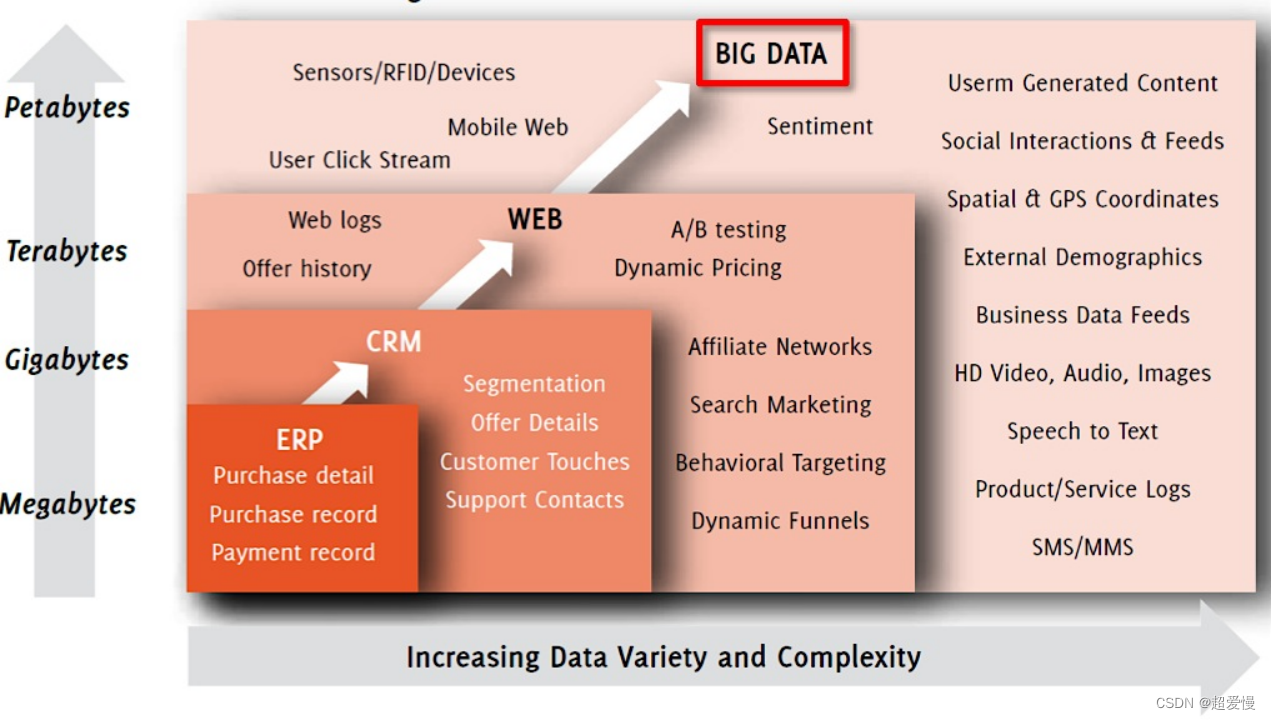
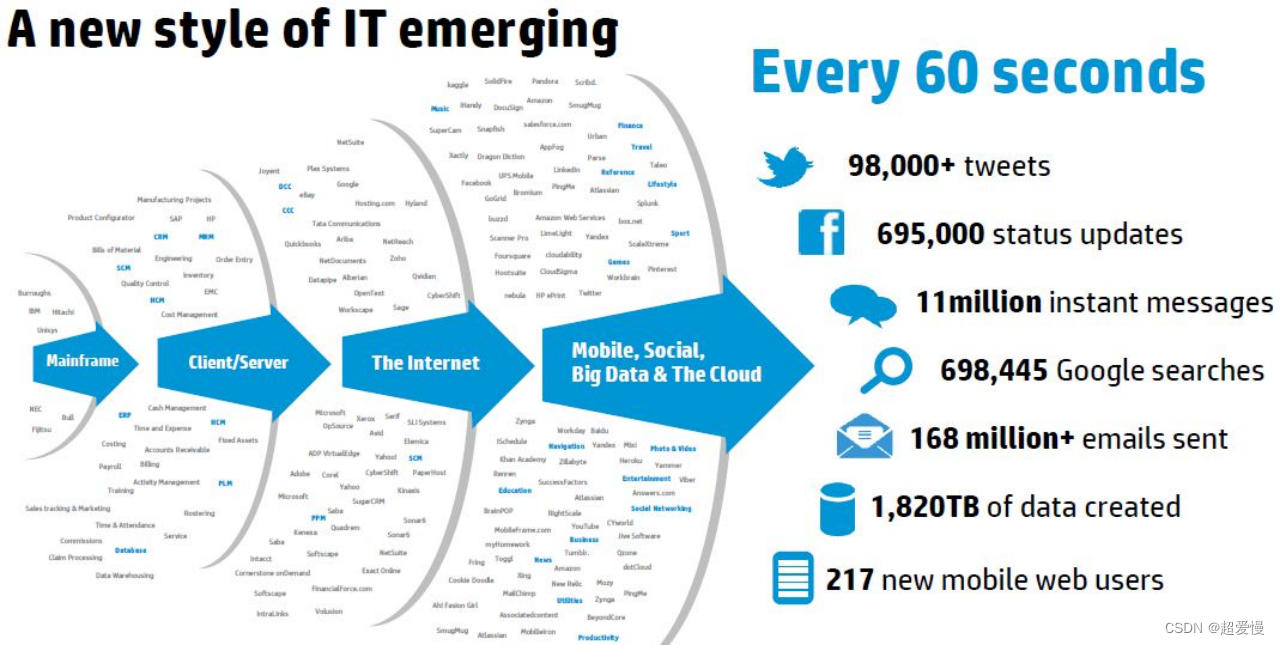
大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
大数据技术要解决的问题:海量数据存储和海量数据计算
二 大数据特征
- 4V特征
- Volume(大数据量):90% 的数据是过去两年产生
- Velocity(速度快):数据增长速度快,
- 时效性高 Variety(多样化):数据种类和来源多样化 结构化数据(如表形式的数据)、半结构化数据(如 json)、非结构化数据(如日志信息)
- Value(价值密度低):需挖掘获取数据价值
- 固有特征
- 时效性
- 不可变性
三 分布式计算
分布式计算将较大的数据分成小的部分进行处理。
| 传统分布式计算 | 新的分布式计算 - Hadoop | |
| 计算方式 | 将数据复制到计算节点 | 在不同数据节点并行计算 |
| 可处理数据量 | 小数据量 | 大数据量 |
| CPU性能限制 | 受CPU限制较大 | 受单台设备限制小 |
| 提升计算能力 | 提升单台机器计算能力 | 扩展低成本服务器集群 |
四 Hadoop是什么?
- Hadoop是一个开源分布式系统架构,解决海量数据存储和海量数据计算的问题
- 处理海量数据的架构首选
- 非常快得完成大数据计算任务
- 已发展成为一个Hadoop生态圈

五 Hadoop发展及版本
- Hadoop起源于搜索引擎Apache Nutch
- 创始人:Doug Cutting
- 2004年 - 最初版本实施
- 2008年 - 成为Apache顶级项目
- Hadoop发行版本
- 社区版:Apache Hadoop
- Cloudera发行版:CDH
- Hortonworks发行版:HDP
六 为什么要使用Hadoop
- 高扩展性
- 在集群间分配任务数据,可方便的扩展数以千计的节点
- 高可靠性
- Hadoop底层维护多个数据副本
- 高容错性
- Hadoop框架能够自动将失败的任务重新分配
- 低成本
- Hadoop架构允许部署在廉价的机器上
- 灵活,可存储任意类型数据
- 开源,社区活跃
七 Hadoop vs. RDBMS
Hadoop与关系型数据库对比
| RDBMS | Hadoop | |
| 格式 | 写数据时要求 | 读数据时要求 |
| 速度 | 读数据速度快 | 写数据速度快 |
| 数据监管 | 标准结构化 | 任意结构数据 |
| 数据处理 | 有限的处理能力 | 强大的处理能力 |
| 数据类型 | 结构化数据 | 结构化、半结构化、非结构化 |
| 应用场景 | 交互式OLAP分析 ACID事务处理 企业业务系统 | 处理非结构化数据 海量数据存储计算 |
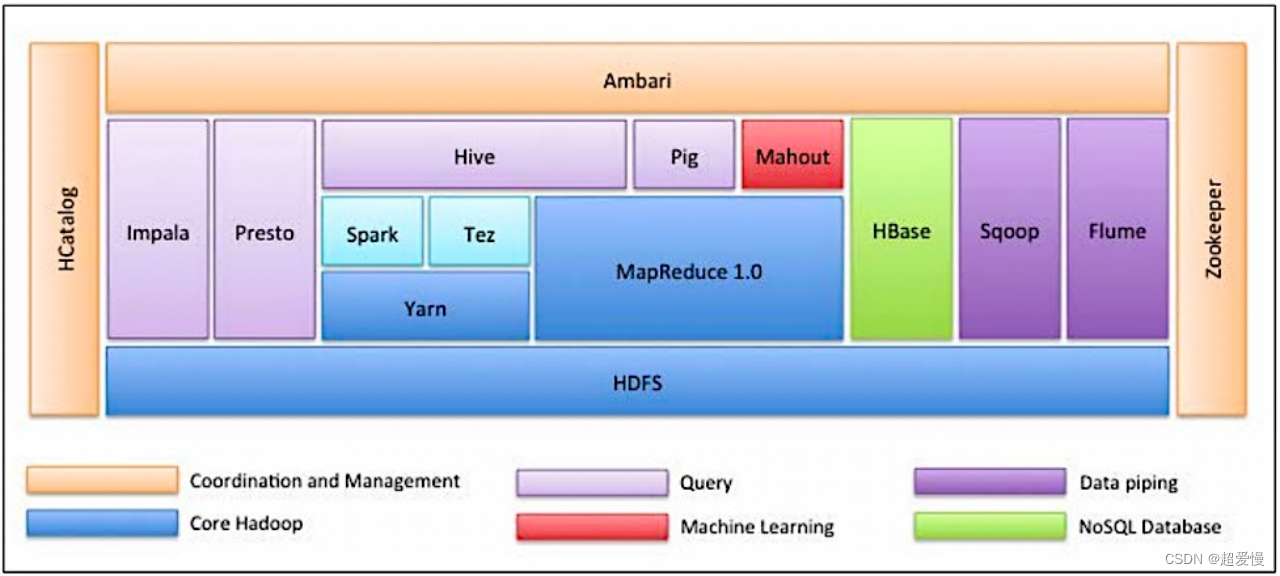
八 Hadoop生态圈
九 Hadoop架构
- HDFS(Hadoop Distributed File System)
- 分布式文件系统,解决分布式存储
- MapReduce
- 分布式计算框架
- YARN
- 分布式资源管理系统 在Hadoop 2.x中引入
- Common
- 支持所有其他模块的公共工具程序

- 支持所有其他模块的公共工具程序