👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——NLP实战(自然语言推断——数据集)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
NLP实战(自然语言推断——注意力机制实现)
- 引入
- 模型
- 注意(Attending)
- 比较
- 聚合
- 整合代码
- 训练和评估模型
- 读取数据集
- 创建模型
- 训练和评估模型
- 使用模型
- 小结
引入
在之前已经介绍了什么是自然语言推断,并且下载并处理了SNLI数据集。由于许多模型都是基于复杂而深度的架构,因此提出用注意力机制解决自然语言推断问题,并且称之为“可分解注意力模型”。这使得模型没有循环层或卷积层,在SNLI数据集上以更少的参数实现了当时的最佳结果。下面就实现这种基于注意力的自然语言推断方法(使用MLP),如下图所述:
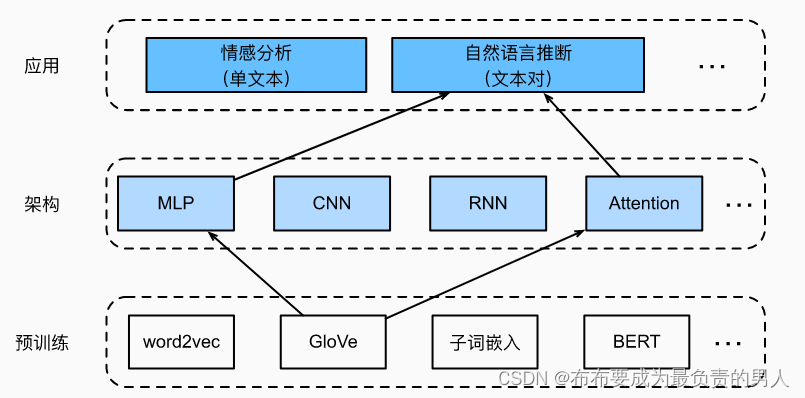
这里的任务就是要将预训练GloVe送到注意力和MLP的自然语言推断架构。
模型
与保留前提和假设中词元的顺序,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,然后比较和聚合这些信息,以预测前提和假设之间的逻辑关系。这和机器翻译中源句和目标句之间的词元对齐类似,前提和假设之间的词元对齐可以通过注意力机制来灵活完成。如下所示就是使用注意力机制来实现自然语言推断的模型图:
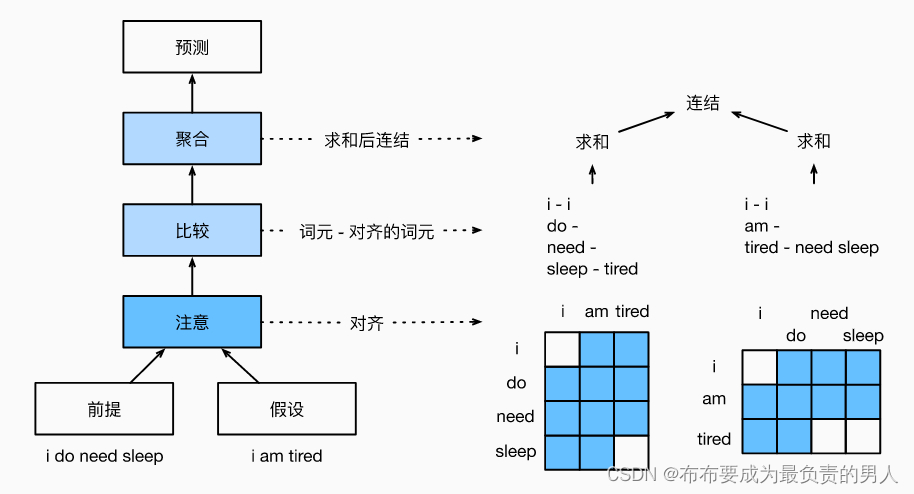
上面的i和i相对,前提中的sleep会对应tired,假设中的tired对应的是need sleep。
从高层次讲,它由三个联合训练的步骤组成:对齐、比较和汇总,下面会通过代码来解释和实现。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
注意(Attending)
第一步是将一个文本序列中的词元与另一个序列中的每个词元对齐。假设前提是“我需要睡眠”,假设是“我累了”。由于语义上的相似性,我们不妨将假设中的“我”与前提中的“我”对齐,将假设中的“累”与前提中的“睡眠”对齐。同样,我们可能希望将前提中的“我”与假设中的“我”对齐,将前提中“需要睡眠”与假设中的“累”对齐。
注意,这种对齐是使用的加权平均的“软”对齐,其中理想情况下较大的权重与要对齐的词元相关联。为了便于演示,上图是用了“硬”对齐的方式来展示。
现在,我们要详细描述使用注意力机制的软对齐。
用
A
=
(
a
1
,
.
.
.
,
a
m
)
和
B
=
(
b
1
,
.
.
.
,
b
n
)
A=(a_1,...,a_m)和B=(b_1,...,b_n)
A=(a1,...,am)和B=(b1,...,bn)
分别表示前提和假设,其词元数量分别为m和n,其中:
a
1
,
b
j
∈
R
d
是
d
维的词向量
a_1,b_j∈R^d是d维的词向量
a1,bj∈Rd是d维的词向量
关于软对齐,我们将注意力权重计算为:
e
i
j
=
f
(
a
i
)
T
f
(
b
j
)
e_{ij}=f(a_i)^Tf(b_j)
eij=f(ai)Tf(bj)
其中函数f是在下面的mlp函数中定义的多层感知机。输出维度f由mlp的num_hiddens参数指定。
def mlp(num_inputs, num_hiddens, flatten):
net = []
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_inputs, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
net.append(nn.Dropout(0.2))
net.append(nn.Linear(num_hiddens, num_hiddens))
net.append(nn.ReLU())
if flatten:
net.append(nn.Flatten(start_dim=1))
return nn.Sequential(*net)
值得注意的是,上式中,f分别输入ai和bi,而不是把它们一对放在一起作为输入。这种分解技巧导致f只有m+n次计算(线性复杂度),而不是mn次计算(二次复杂度)。
对上式中的注意力权重进行规范化,我们计算假设中所有词元向量的加权平均值,以获得假设的表示,该假设与前提中索引i的词元进行软对齐:
β
i
=
∑
j
=
1
n
e
x
p
(
e
i
j
)
∑
k
=
1
n
e
x
p
(
e
i
k
)
b
j
β_i=\sum_{j=1}^n\frac{exp(e_{ij})}{\sum_{k=1}^nexp(e_{ik})}b_j
βi=j=1∑n∑k=1nexp(eik)exp(eij)bj
同理,我们计算假设中索引为j的每个词元与前提词元的软对齐:
α
j
=
∑
i
=
1
m
e
x
p
(
e
i
j
)
∑
k
=
1
m
e
x
p
(
e
k
j
)
a
i
α_j=\sum_{i=1}^m\frac{exp(e_{ij})}{\sum_{k=1}^mexp(e_{kj})}a_i
αj=i=1∑m∑k=1mexp(ekj)exp(eij)ai
下面,我们定义Attend类来计算假设(beta)与输入前提A的软对齐以及前提(alpha)与输入假设B的软对齐。
class Attend(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Attend, self).__init__(**kwargs)
self.f = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B):
# A/B的形状:(批量大小,序列A/B的词元数,embed_size)
# f_A/f_B的形状:(批量大小,序列A/B的词元数,num_hiddens)
f_A = self.f(A)
f_B = self.f(B)
# e的形状:(批量大小,序列A的词元数,序列B的词元数)
e = torch.bmm(f_A, f_B.permute(0, 2, 1))
# beta的形状:(批量大小,序列A的词元数,embed_size),
# 意味着序列B被软对齐到序列A的每个词元(beta的第1个维度)
beta = torch.bmm(F.softmax(e, dim=-1), B)
# beta的形状:(批量大小,序列B的词元数,embed_size),
# 意味着序列A被软对齐到序列B的每个词元(alpha的第1个维度)
alpha = torch.bmm(F.softmax(e.permute(0, 2, 1), dim=-1), A)
return beta, alpha
比较
在下一步中,我们将一个序列中的词元与和该词元软对齐的另一个序列进行比较。注意,软对齐中,一个序列中的所有词元(尽管可能具有不同的注意力权重)将与另一个序列中的词元进行比较。
在比较步骤中,我们将来自一个序列的词元的连结(运算符[·,·])和来自另一个序列的对其的词元送入函数g(一个多层感知机):
v
A
,
i
=
g
(
[
a
i
,
β
i
]
)
,
i
=
1
,
.
.
.
,
m
v
B
,
j
=
g
(
[
b
j
,
α
j
]
)
,
j
=
1
,
.
.
.
,
n
其中,
v
A
,
i
指:所有假设中的词元与前提中词元
i
软对齐,再与词元
i
的比较;
v
B
,
j
指:所有前提中的词元与假设中词元
j
软对齐,再与词元
j
的比较。
v_{A,i}=g([a_i,β_i]),i=1,...,m\\ v_{B,j}=g([b_j,α_j]),j=1,...,n\\ 其中,v_{A,i}指:所有假设中的词元与前提中词元i软对齐,再与词元i的比较;\\ v_{B,j}指:所有前提中的词元与假设中词元j软对齐,再与词元j的比较。
vA,i=g([ai,βi]),i=1,...,mvB,j=g([bj,αj]),j=1,...,n其中,vA,i指:所有假设中的词元与前提中词元i软对齐,再与词元i的比较;vB,j指:所有前提中的词元与假设中词元j软对齐,再与词元j的比较。
下面的Compare类定义了比较的步骤:
class Compare(nn.Module):
def __init__(self, num_inputs, num_hiddens, **kwargs):
super(Compare, self).__init__(**kwargs)
self.g = mlp(num_inputs, num_hiddens, flatten=False)
def forward(self, A, B, beta, alpha):
V_A = self.g(torch.cat([A, beta], dim=2))
V_B = self.g(torch.cat([B, alpha], dim=2))
return V_A, V_B
聚合
现在我们有两组比较向量:
v
A
,
i
和
v
B
,
j
v_{A,i}和v_{B,j}
vA,i和vB,j
在最后一步中,我们将聚合这些信息以推断逻辑关系。我们首先求和这两组比较向量:
v
A
=
∑
i
=
1
m
v
A
,
i
,
v
B
=
∑
j
=
1
n
v
B
,
j
v_A=\sum_{i=1}^mv_{A,i},v_B=\sum_{j=1}^nv_{B,j}
vA=i=1∑mvA,i,vB=j=1∑nvB,j
接下来,我们将两个求和结果的连结提供给函数h(一个多层感知机),以获得逻辑关系的分类结果:
y
^
=
h
(
[
v
A
,
v
B
]
)
\hat{y}=h([v_A,v_B])
y^=h([vA,vB])
聚合步骤在以下Aggregate类中定义。
class Aggregate(nn.Module):
def __init__(self, num_inputs, num_hiddens, num_outputs, **kwargs):
super(Aggregate, self).__init__(**kwargs)
self.h = mlp(num_inputs, num_hiddens, flatten=True)
self.linear = nn.Linear(num_hiddens, num_outputs)
def forward(self, V_A, V_B):
# 对两组比较向量分别求和
V_A = V_A.sum(dim=1)
V_B = V_B.sum(dim=1)
# 将两个求和结果的连结送到多层感知机中
Y_hat = self.linear(self.h(torch.cat([V_A, V_B], dim=1)))
return Y_hat
整合代码
通过将注意步骤、比较步骤和聚合步骤组合在一起,我们定义了可分解注意力模型来联合训练这三个步骤:
class DecomposableAttention(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_inputs_attend=100,
num_inputs_compare=200, num_inputs_agg=400, **kwargs):
super(DecomposableAttention, self).__init__(**kwargs)
self.embedding = nn.Embedding(len(vocab), embed_size)
self.attend = Attend(num_inputs_attend, num_hiddens)
self.compare = Compare(num_inputs_compare, num_hiddens)
# 有3种可能的输出:蕴涵、矛盾和中性
self.aggregate = Aggregate(num_inputs_agg, num_hiddens, num_outputs=3)
def forward(self, X):
premises, hypotheses = X
A = self.embedding(premises)
B = self.embedding(hypotheses)
beta, alpha = self.attend(A, B)
V_A, V_B = self.compare(A, B, beta, alpha)
Y_hat = self.aggregate(V_A, V_B)
return Y_hat
训练和评估模型
现在,我们将在SNLI数据集上对定义好的可分解注意力模型进行训练和评估。我们从读取数据集开始。
读取数据集
我们使用上节定义的函数下载并读取SNLI数据集,批量大小和序列长度分别设为256和50:
batch_size, num_steps = 256, 50
train_iter, test_iter, vocab = d2l.load_data_snli(batch_size, num_steps)
创建模型
我们将预训练好的100维GloVe嵌入来表示输入词元。我们将向量ai和bj的维数定义为100。f和g的输出维度被设置为200。然后我们创建一个模型实例,初始化参数,并加载GloVe嵌入来初始化输入词元的向量。
embed_size, num_hiddens, devices = 100, 200, d2l.try_all_gpus()
net = DecomposableAttention(vocab, embed_size, num_hiddens)
glove_embedding = d2l.TokenEmbedding('glove.6b.100d')
embeds = glove_embedding[vocab.idx_to_token]
net.embedding.weight.data.copy_(embeds)
训练和评估模型
现在我们可以在SNLI数据集上训练和评估模型。
lr, num_epochs = 0.001, 4
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction="none")
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
d2l.plt.show()
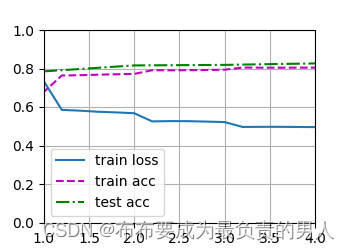
运行结果:
loss 0.495, train acc 0.805, test acc 0.826
443.5 examples/sec on [device(type=‘cpu’)]
运行图片:
使用模型
定义预测函数,输出一对前提和假设之间的逻辑关系。
#@save
def predict_snli(net, vocab, premise, hypothesis):
"""预测前提和假设之间的逻辑关系"""
net.eval()
premise = torch.tensor(vocab[premise], device=d2l.try_gpu())
hypothesis = torch.tensor(vocab[hypothesis], device=d2l.try_gpu())
label = torch.argmax(net([premise.reshape((1, -1)),
hypothesis.reshape((1, -1))]), dim=1)
return 'entailment' if label == 0 else 'contradiction' if label == 1 \
else 'neutral'
我们可以使用训练好的模型来获得对实例句子的自然语言推断结果:
print(predict_snli(net, vocab, ['he', 'is', 'good', '.'], ['he', 'is', 'bad', '.']))
预测结果:
‘contradiction’
小结
1、可分解注意模型包括三个步骤来预测前提和假设之间的逻辑关系:注意、比较和聚合。
2、通过注意力机制,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,反之亦然。这种对齐是使用加权平均的软对齐,其中理想情况下,较大的权重与要对齐的词元相关联。
3、在计算注意力权重时,分解技巧会带来比二次复杂度更理想的线性复杂度。
4、我们可以使用预训练好的词向量作为下游自然语言处理任务的输入表示。