前言
在「RTE2022 实时互联网大会」中,熹乐科技创始人 & CEO @范维肖CC 以《基于开源 YoMo 框架构建“全球同服”的 Realtime Metaverse Application》为题进行了主题演讲。
本文内容基于演讲内容进行整理,为方便阅读略有删改。

大家好,我是熹乐科技的 C.C. 范维肖,我们公司的产品是开源的实时边缘框架 YoMo。在过去的两年中,很多 Metaverse 行业的开发者使用了我们的产品。这次就和大家分享一下过去的两年中,我们在 Metaverse 领域的一些经验和体会。
在过去的二十年,开发者已经非常习惯 RESTful 开发方式,API 非常的简单,我们用类似于 JSON、PutBuffer 等方式作为数据结构来做传输,通过一个 GET 一个 POST 就能够解决绝大多数的业务逻辑问题。这也形成了今天主流的「API 经济」模型,它主要的逻辑就是用户跟服务器在发生交互。
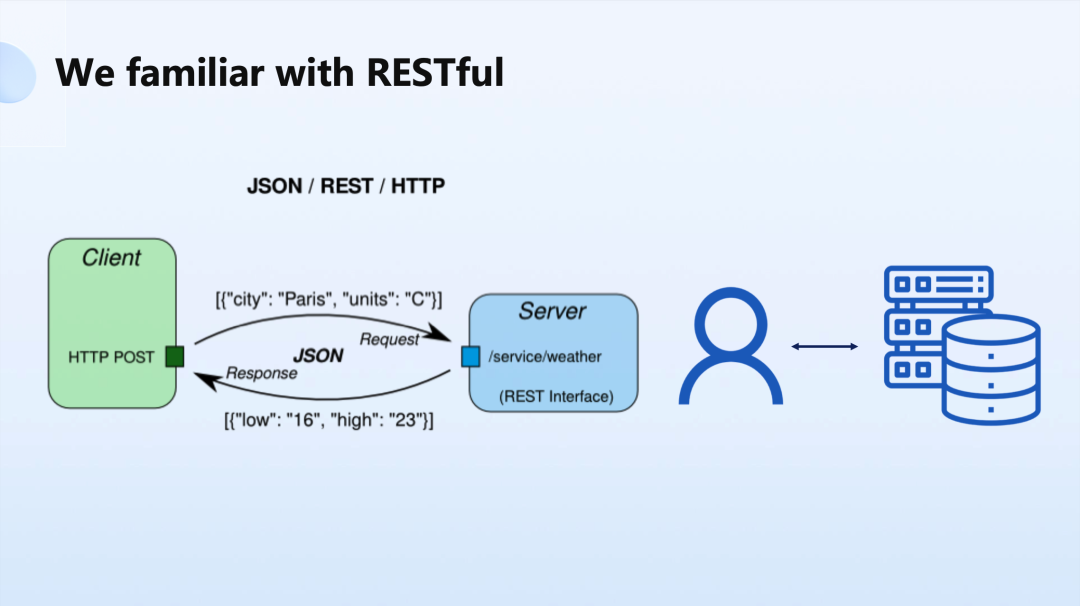
但是在 Metaverse 领域当中,RESTful 方式受到了很大的挑战。比如下图中的场景:
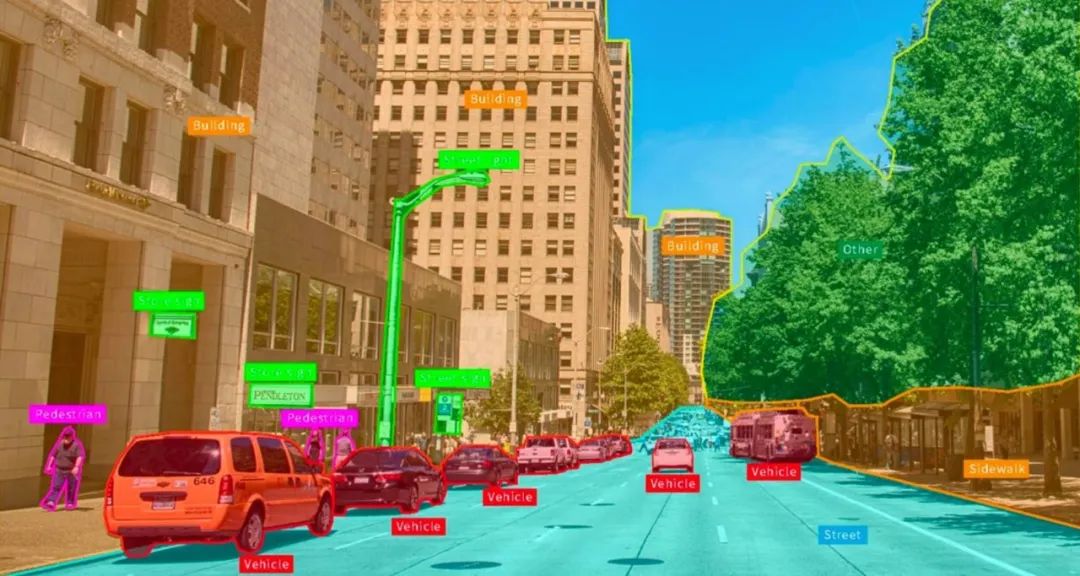
无论是在一辆自动驾驶汽车上,还是戴着 VR、AR 跟我们的现实世界形成与虚拟世界的实时投影,过程中都有大量的数据需要进行计算,而这些数据往往不是结构化的数据。
01 传统产品和 metaverse 的三个关键差异因素
在这一类 metaverse 场景中,和传统的产品相比有三个重要的不同因素。第一个关键差异,是越来越多的数据从 JSON 变成了流式的数据 Streaming Data。

这当中一个明显特点,是各种传感器在采集数据、传输数据。对于用户而言,上行数据的量比下行数据的量要大,也就意味着越来越多的数据需要通过网络来进行共享,需要去寻找它的计算单元完成计算。这个情况和此前“下行数据远远高于上行数据”、计算离用户很远的情况是完全不一样的。
第二个差异在于低时延成为了一个非常非常重要的因素。
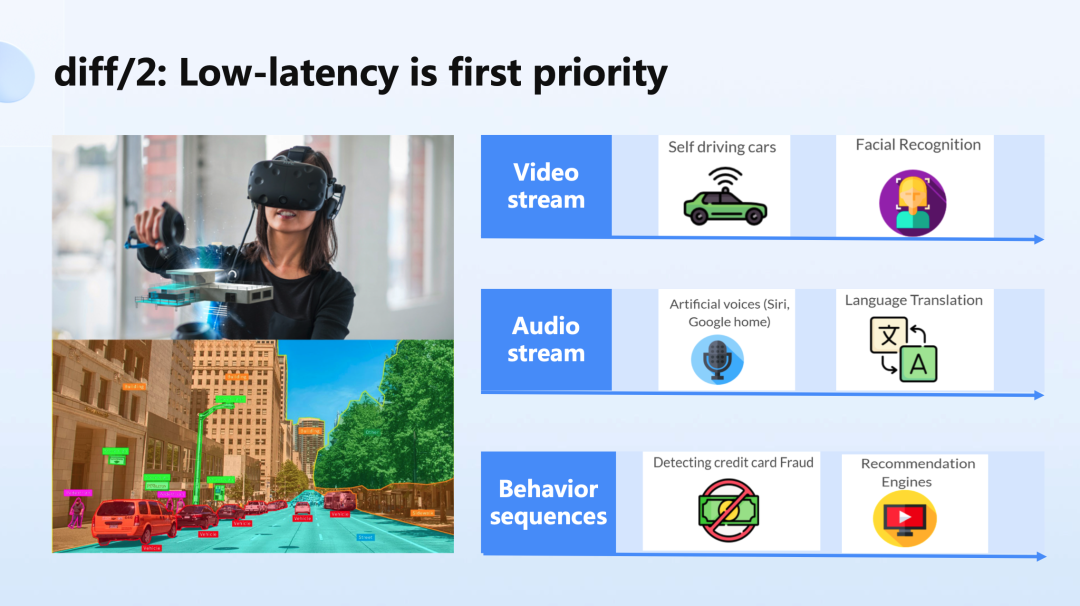
像在刚才我们讲的场景当中,可以大致分为三部分:
- Video Stream
- Audio Stream
- Behavior Sequences
其中 Video Stream 主要应用在自动驾驶汽车、人脸识别当中;Audio Stream 是通过一条流来传输音频,可用于各类实时翻译、语音控制等场景;Behavior Sequences 是动作序列,连续的动作序列数据可以用于做规则判断、模式识别、推荐引擎,以及欺诈检测等等。这些都需要实时的完成计算。
第三个不同的点是整个 Metaverse 是一个全球化的模型,每一个人都在跟全球所有的人组成一个自己主导的虚拟世界,那么每一个“我”与另一个人之间的 Metaverse 是相互融合在一起的,每个人都是自己世界的中心,这是 Metaverse 相关产品架构的底层逻辑。
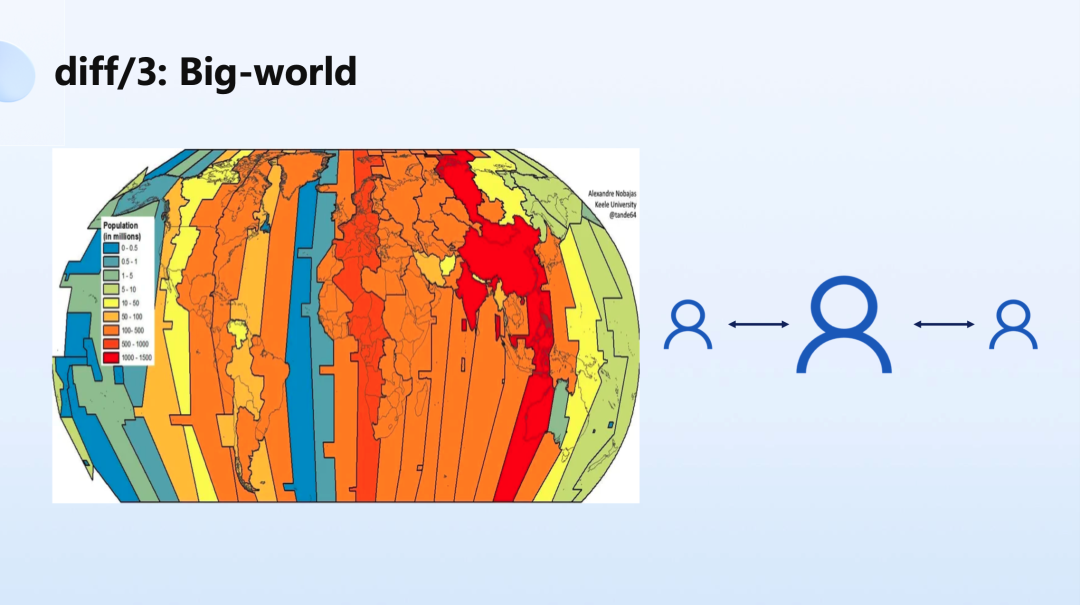
那么这也形成了一个与之前传统来讲最大的不同:以前是人与计算单元发生交互,但今天人与人之间在发生着剧烈的交互。这是我们过去两年服务 Metaverse 行业开发者的过程中,一个最明显的感受。
02 如何解决这些难题?
开源框架 YoMo 有一个最简单的定位是 Streaming Serverless,让开发者使用 Serverless 的模式作为编程范式,构建整个的微服务的逻辑,解决流式的实时开发。
这个概念其实不新,在最早计算机出现的时候,进程间的通讯靠的就是 Unix Pipeline。
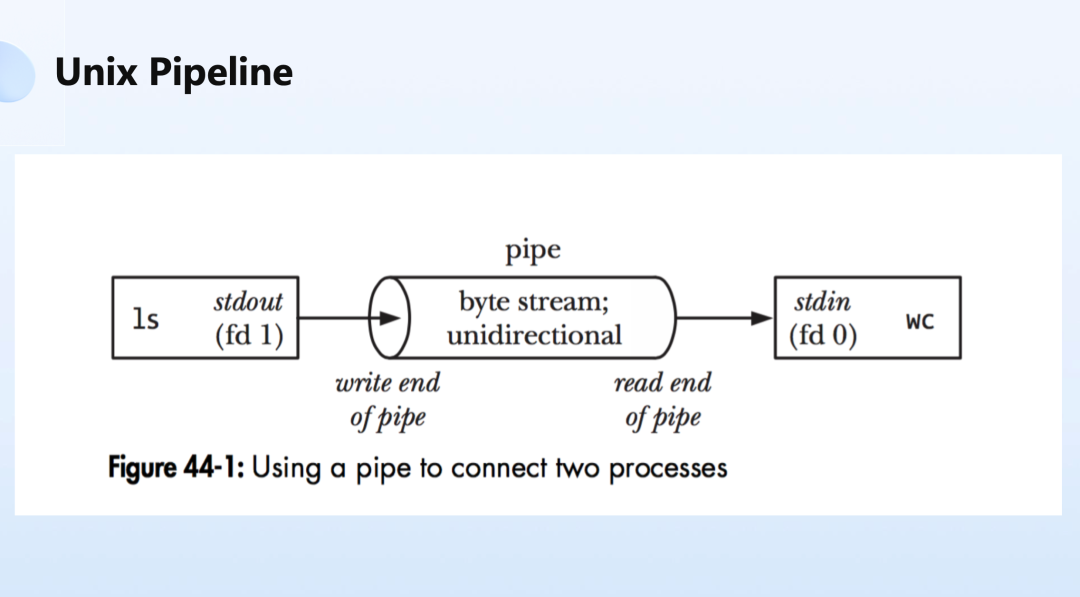
如上图所示的进程中,把输出放到左侧 ls 命令的标准输出中,通过 Unix Pipeline 以字节流的方式,进行单向的向后传递,传递给右侧的 wc 程序。通过这样的方式,解耦了左侧的 ls 和右侧的 wc。
那么 Unix Pipeline 就可以按照这样的流程连续起来,用文件描述服务去做整个的解耦和连接,这也是经典的 Unix 哲学中一个很重要的部分。
而像我们经常在命令行中通过用 cat 命令去打印内容,用 sort 去排序,用 uniq 去排除重复的数据,用 grep 去做过滤,这些应用是用一个竖线来表示整体的 Pipeline 的这个过程。
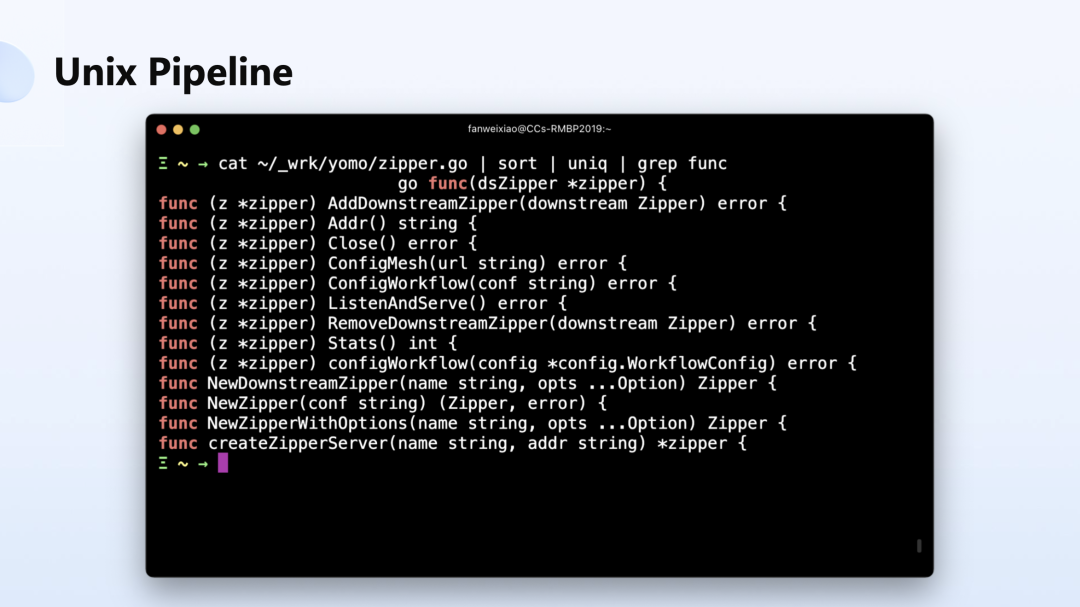
YoMo 就是基于这个思想,但是放大到了整个互联网的级别来做。
现在我们来看下图,如果我们的应用程序从左侧的 sort 到 uniq,然后 sort 到最后的 head,这几个命令我们需要去平衡它的计算成本和计算时延的需求。
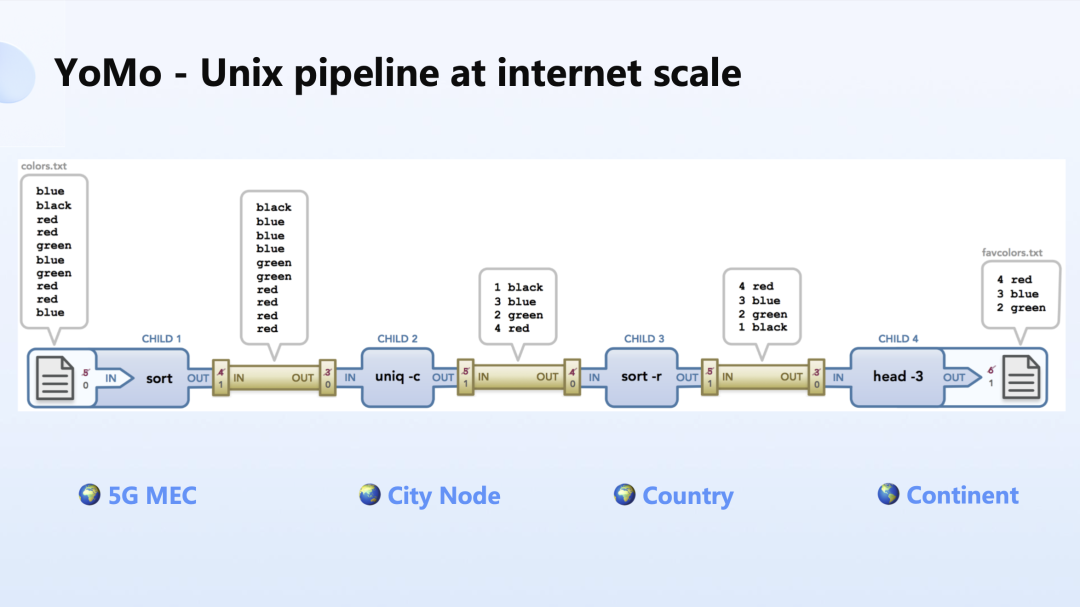
那么我们就可以把它分别部署在不同的位置,比如说最左侧,我们可以把它部署在 5G MEC 上,这样的 sort 就能够达到很快的结果。然后我们可以依次来调整剩下的级别,放到城市级、国家级甚至整个大洲,就我们今天常规的云计算的节点上面。
这样我们就能获得更低的计算成本来构建应用,这使得不同的服务可以按照它的响应级别和成本控制的要求,去做平衡和取舍。这在传统的分布式计算当中,要花很大的精力去构建如此的基础设施。
这也引出来 YoMo 的三个核心概念 —— 数据源、处理函数和 Zipper。
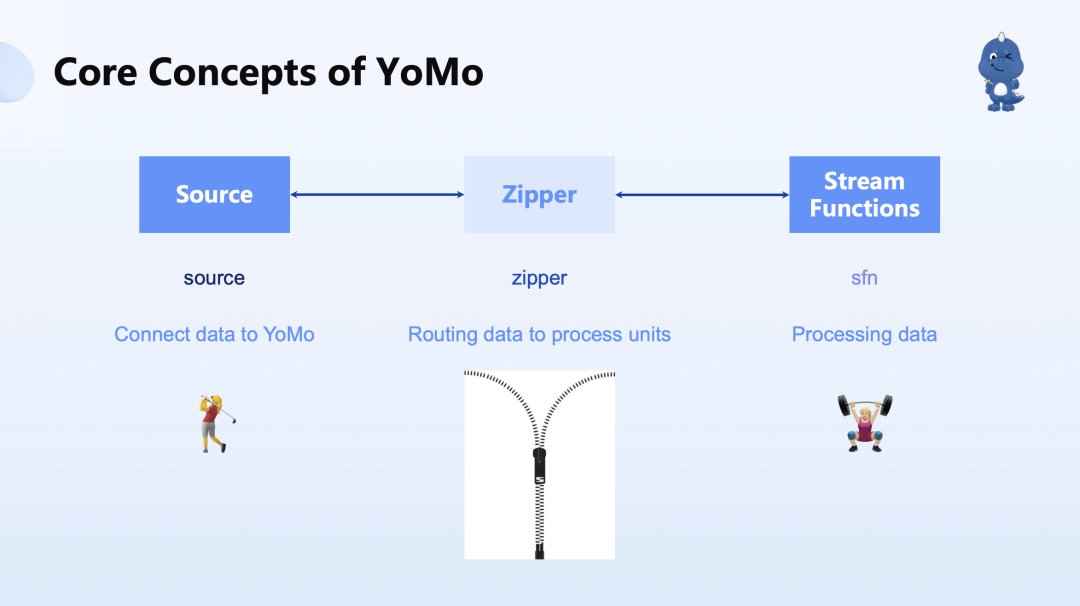
Zipper 就像 linux 的 Pipeline 功能一样把两侧连接起来,去把数据调配到不同的计算资源。数据源是用于把数据结构转换成能在 YoMo 里面去流动的信息,这样才能够实现低时延、高效的全球传输。
计算的算子可以把它理解为数据流动的方式,从左向右在做流动,那么中间靠一个 Zipper,像衣服的拉链一样,把所有的算子和数据重合,每次重合就是一次计算。这样最终能形成的架构是地理位置分布式的架构方式。
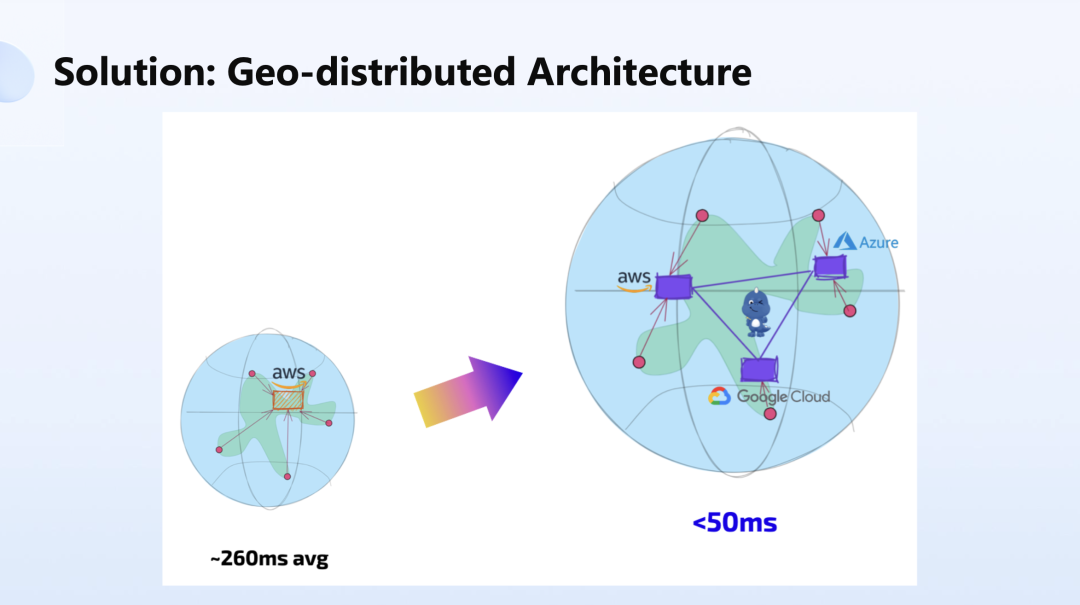
目前传统在用的分布式都是在一个单一数据中心里的分布式,但需要满足全球用户使用的时候,需要变为架构在今天的 IaaS 之上的全球分布式技术。
写这样的应用大家肯定会感到非常的痛苦,我们在离开 7 毫秒时延的约束,全球范围都一两百毫秒的时候,如何能保证我们的分布式的 CAP 理论一致性等等,都是相对棘手的难题。
所以 YoMo 的框架旨在于解决面向于全球分布式场景下,如何更简单的构建自己的应用程序。那我们应用程序一旦构建完就可以部署在离用户更近的地方,来为他附近的用户提供低时延,并且成本更低廉的服务,这样全球应用的平均时延可以从今天的 260 毫秒优化到全球小于 50 毫秒。
地理位置分布式是逃不开的话题,因为网络的时延和光速是成正比的。今天我们的网络在极限场景下,数据的传输速率跟距离成正比。
下面的几张图展示了当数据中心放到北京,在 10 毫秒、20 毫秒、50 毫秒的时延情况下,理论上能覆盖的面积。
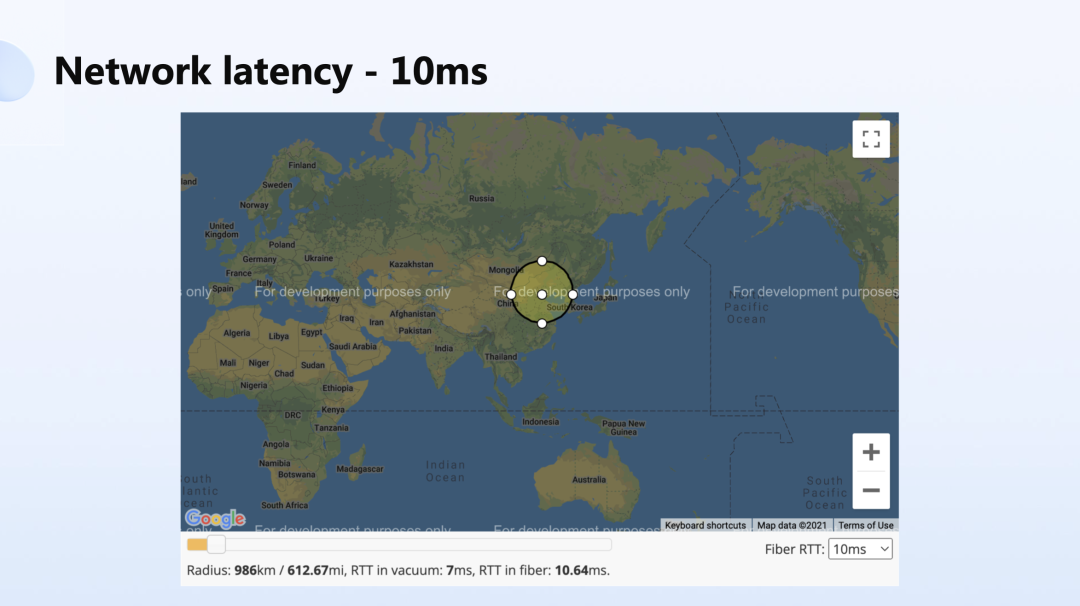
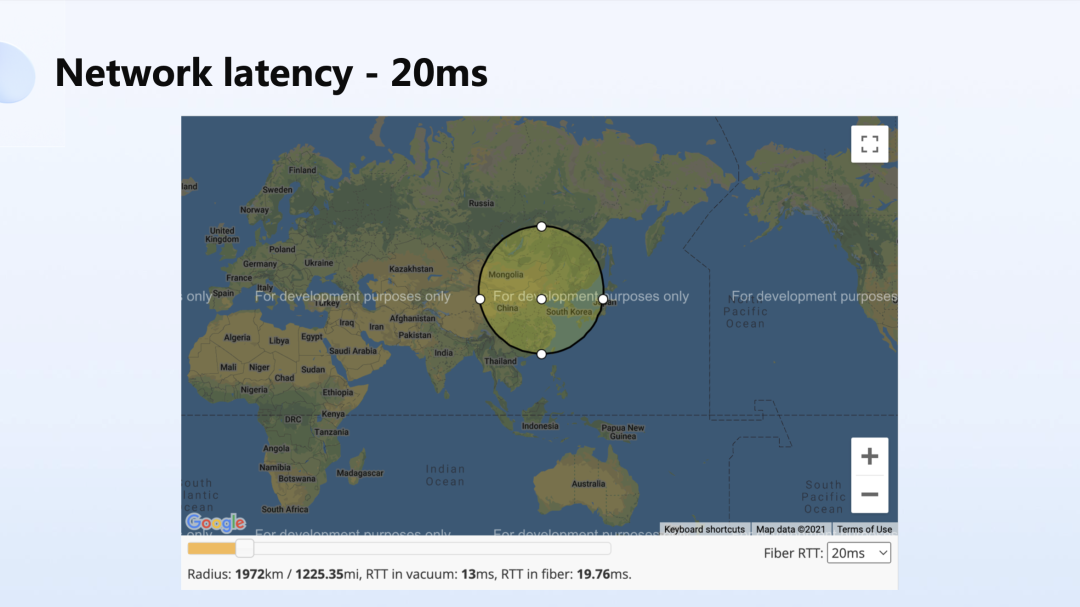
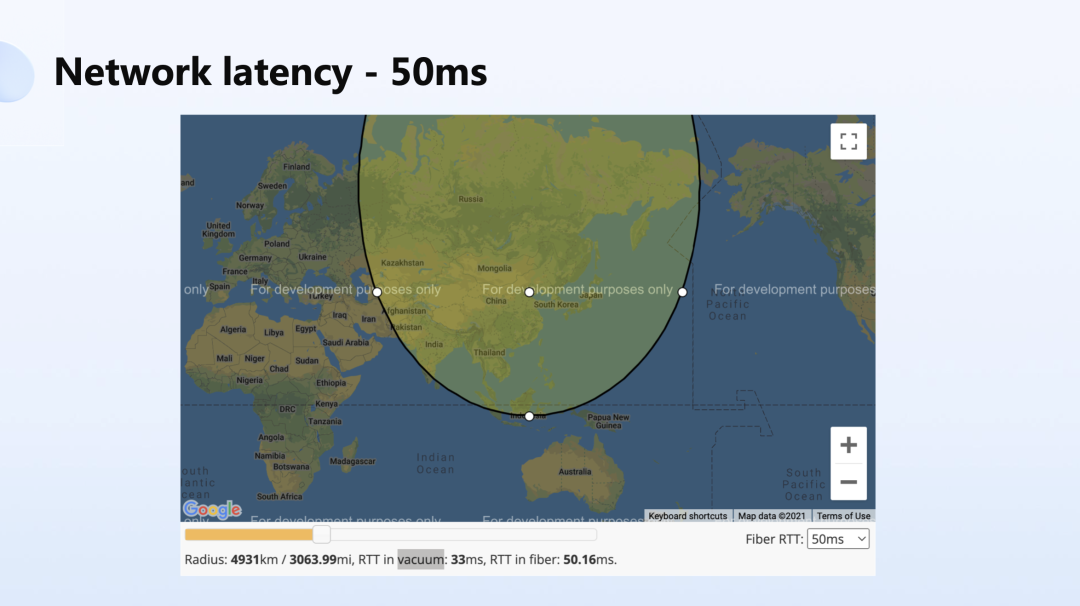
如图所示,50 毫秒的时延理论上可以实现覆盖亚洲和东欧的部分;100 毫秒的时延,如果将数据中心部署在美国的东部,理论上是可以覆盖半个地球的,但实际环境中其实根本做不到这一点。
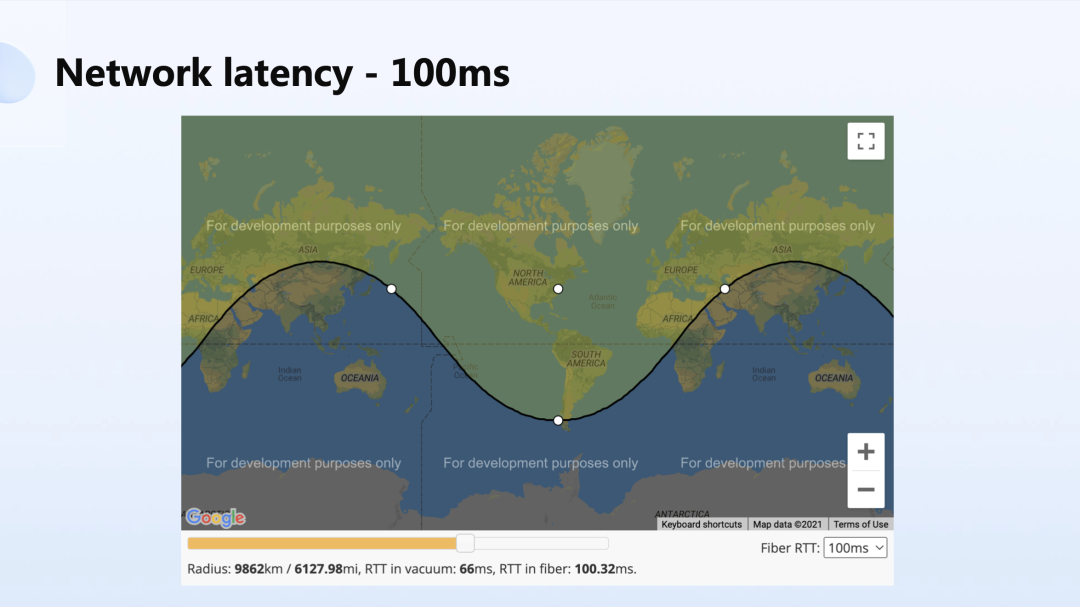
因为实际场景下,用户从自己的端上到接入服务的链路非常长,而且业务提供方对此又不可控。这种情况下的问题就要糟糕很多,在很多基础设施环节都需要做大量的优化。
很多公有云在不同的大洲都有多个数据中心,但跨区域的时候,这些数据中心之间的交互其实也是不够理想的。这个时候要考虑的,是如何解决同一个云上多数据中心、不同云不同数据中心之间如何能高速的交互,并且能使得我们的应用能够自我治理。
自我治理可以使得它不断的繁殖。当一个区域的用户越来越多的时候,我可以繁殖一个新的节点出来,这个节点是自适应、自组织的,并且能向上与之前的计算农场结合在一起。
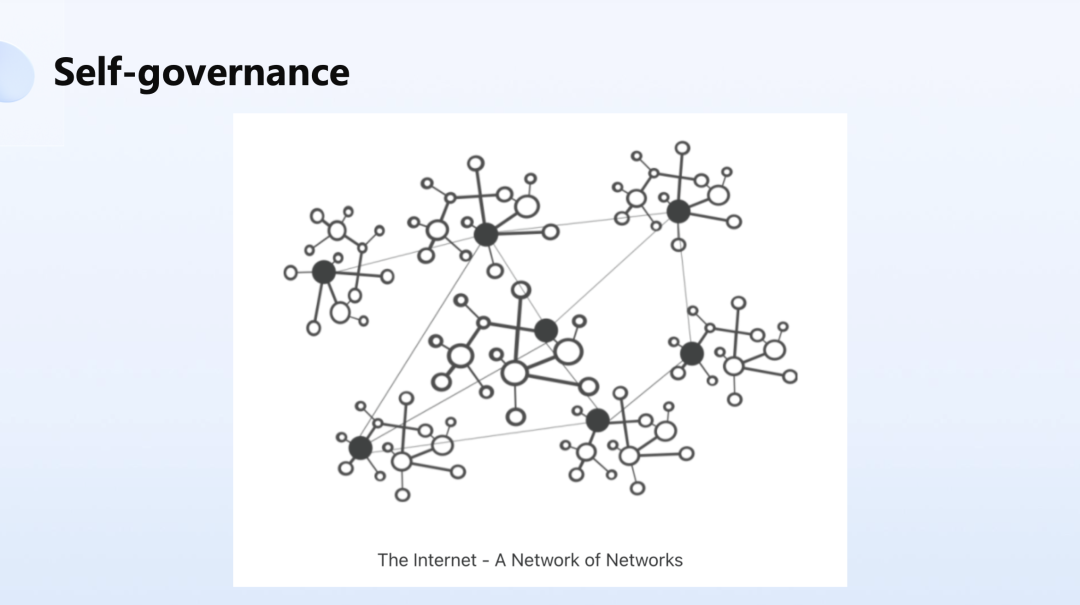
这种自我治理的思路不是创新,也是来自于互联网架构中非常传统的基础模型。Internet 其实就是 a network of networks,它就是由一个一个的网络组成,中间由 BGP 连起来,这也是 YoMo 架构的理念。
03 开发者友好性
YoMo 要花大量的精力去解决的第三个事情,是开发者友好性的问题。为什么呢?想想我们今天的端,我们有很多做端游的用户,他们用 YoMo 来解决的第一个问题是 WIFI 网络的问题。
这背后的原因在于,目前我们大多数场景还在用 WIFI-5,其数据传递链路是波,而波是非常容易受到干扰的,比如说建筑物的遮挡和多设备之间的干扰,从而导致丢包。

在有丢包、时延产生的时候,TCP 吞吐量就会快速的下降,因此我们不得不去调整拥塞控制算法。但拥塞控制算法需要按照具体的应用来设置,做视频和做游戏是完全不一样的。加上链路中网络设备僵化因素的存在,也使得使得我们对 TCP 的优化不一定能成立。比如说中间设备很老不支持新的算法,那么 TCP 就会降级,降级到最原始、最落后的状态。所以中间设备的僵化其实是现阶段全链路调优 TCP 过程中很难的一点。
但是去年,IETF 发布了 RFC9000,就是 QUIC 协议。QUIC 基于 UDP,具备更好的安全性,今年发布的 HTTP/3 底层的传输层就是 QUIC 协议。
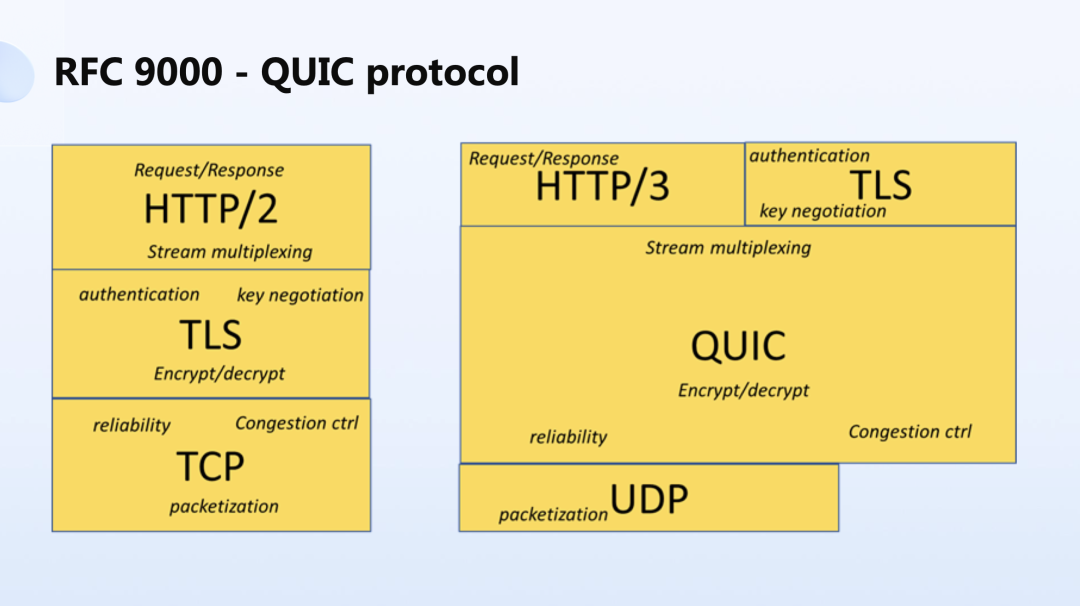
QUIC 有各种优点,比如说它的多流非常的好,非常适合去开发复杂业务逻辑的应用,但是很难用。
如果大家去翻 QUIC 的 IETF 的文档会发现它是一个协议族,有一大堆的文档要读,都读透了才能充分的驾驭它,进而改造上层应用的代码去发挥 QUIC 的优势。你会发现一会儿我要翻 QUIC 的东西,一会儿我要翻 QUIC 扩展的东西,非常麻烦。那么如何能让我们将 QUIC 应用到我们的应用里边变得非常容易?能否跟以前开发应用程序一样还那么简单?那么如何降低用户的学习成本,这其实是 YoMo 在做的一个非常重要部分的工作。
下面这张图程序员们也非常熟悉了,是著名的 Emacs 的蜗牛曲线。
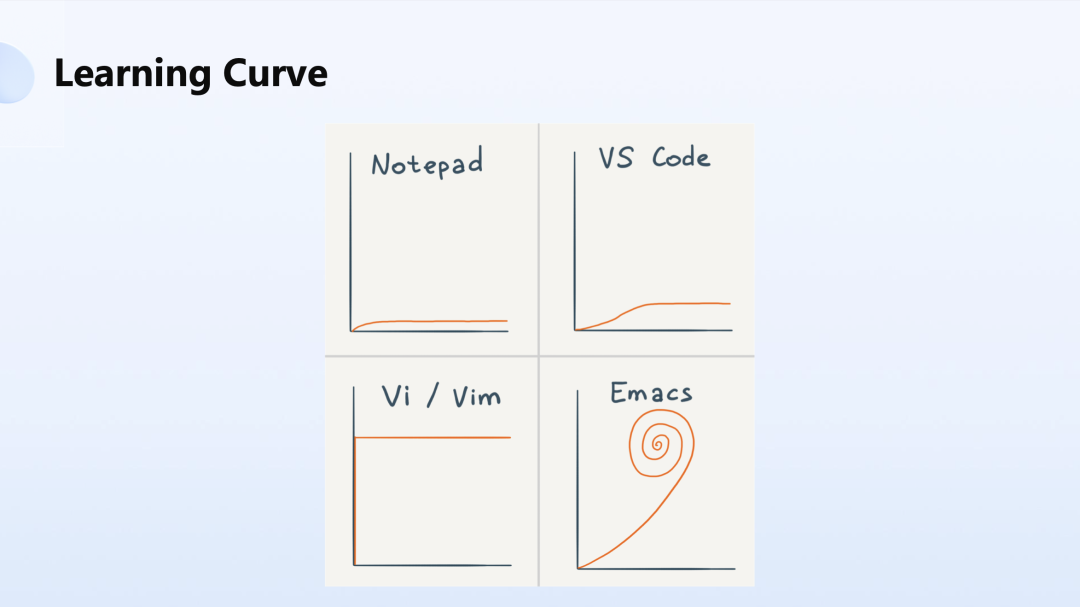
我们降低学习成本的一个方式,就是借助于 Serverless。Serverless 的开发范式大家都已经非常的熟悉了,但 Serverless 到今天仍有一个致命的缺点,就是绝大多数的 Serverless 是无状态的执行,按照执行时长计费,这使得 Serverless 涉及到一系列的问题,比如说没有状态的时候还是要把临时状态打到 DB 上。但在全球分布式系统里,我们的 DB 又非常难去做全球读写,中心化的 DB 使得时延无法得到保障。
所以我们把 Serverless 升级了一下,把它先变成了 stateful。

如上图中的函数所示。当拿到一个数据的时候,我们支持把它抽象成一个 Rx 的流,从而可以借助很多 Rx 的方法去解决问题。比如说像这个例子当中,我要从类似于 VR 眼镜这样的传感器中传数据,那么我可以让它每收到 50 个数据包做成一个 buffer,收到 50 个数据包后我再让 echo 去计算。这在以前我们需要花费精力去做这种框架支持应用的快速开发,今天借助 YoMo 会简单很多。
同时,它要保持着以前 Serverless 的简单易用特性。

目前, YoMo 的 Streaming Serverless 也支持了 Rust 语言,现在有越来越多的开发者在使用 Rust 语言去写自己的后端,Rust 的生态也变得越来越好,这种语言有很多出彩的地方。

但 Rust 也相对难以管理。尤其我们还要考虑一个问题,就是目前的算子都是在云上进行,不管是在边缘的云上还是在传统的公有云上。那有没有可能把算子拉到端上来执行?
比如说要考虑更好的数据安全,那么如何来调配它?基于这一点,我们选择了使用 WebAssembly 来做支持。
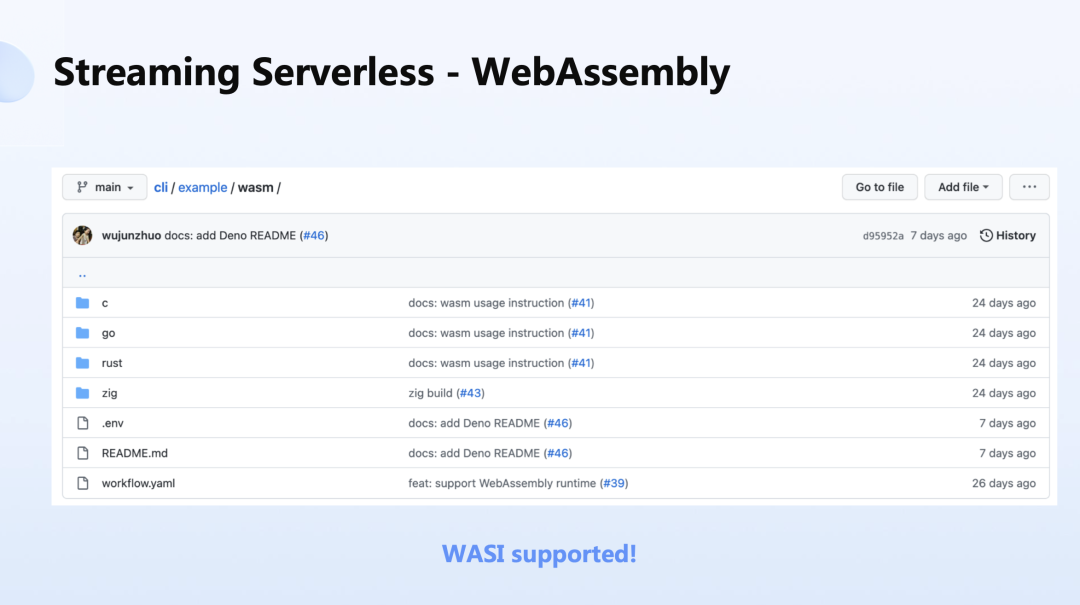
我们完全可以把 Serverless 函数变成 WebAssembly,那么它就可以在 YoMo 里面去被执行。
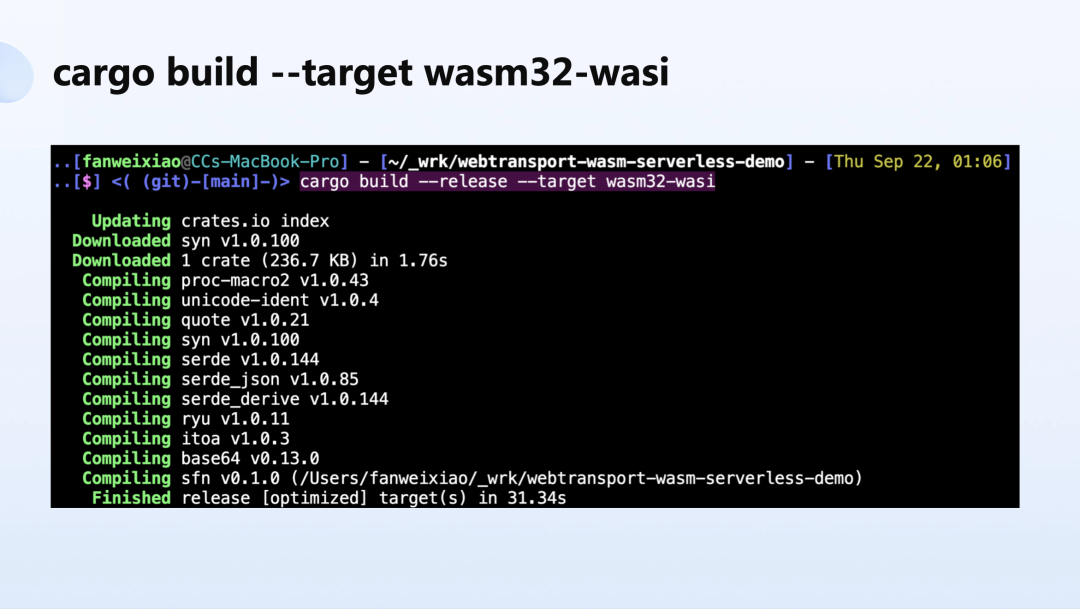
像上图所示的 demo 中,可以把 rust 代码编译成 wasm32-wasi 这样的 target,然后用 YoMo run 然后把它运行起来。
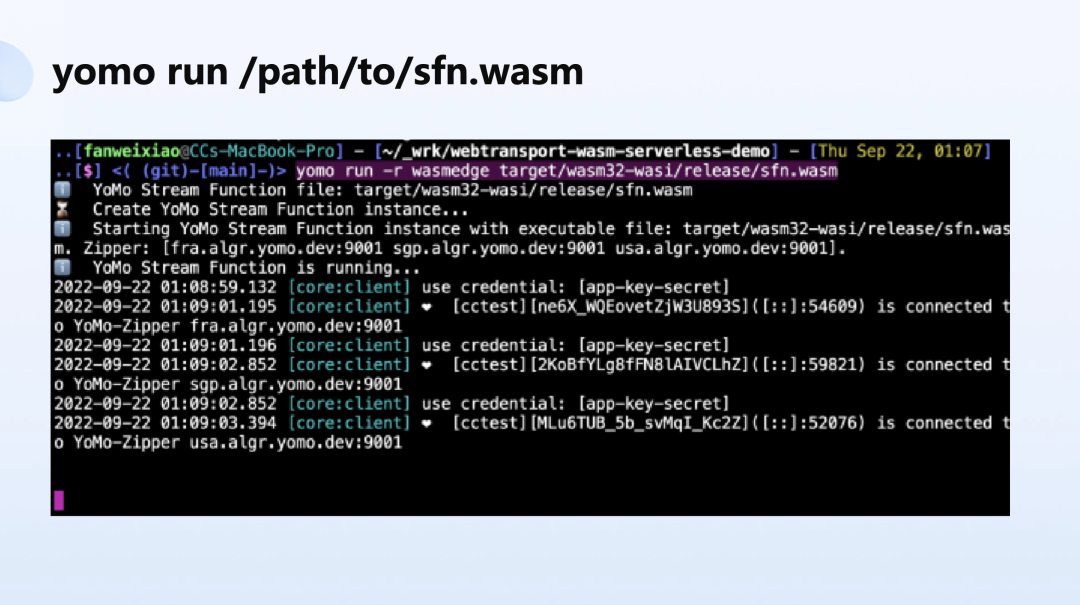
我们也在跟 CNCF 的项目在合作,比如上面这个例子里,就是 YoMo 与开源的 WasmEdge 打通,基于标准的接口,都是社区型的开源项目,使得开发者不用担心被单一供应来源绑定的问题。
04 为前端开发者的特别准备
这两年前端发生了很大的变化,但是开发工具并没有发展得很快。举个例子,过去的十几年里面吧,我们要想写一些 Web 的实时应用,我们可选的工具并不多。WebSocket 可能是绝大多数人都在用的一个工具。但是 WebSocket 太老了,而且呢,WebSocket 有诸多的劣势,尤其是针对于今天复杂的应用程序而言。
在今年的年初,谷歌发布了 WebTransport,现在 Chrome、Microsoft Edge 都已经做了支持,然后 Firefox 也正在去支持它,今天全球 70+% 的 Web 请求都已经支持它了,可是它的落地占比却还不足 0.1%。
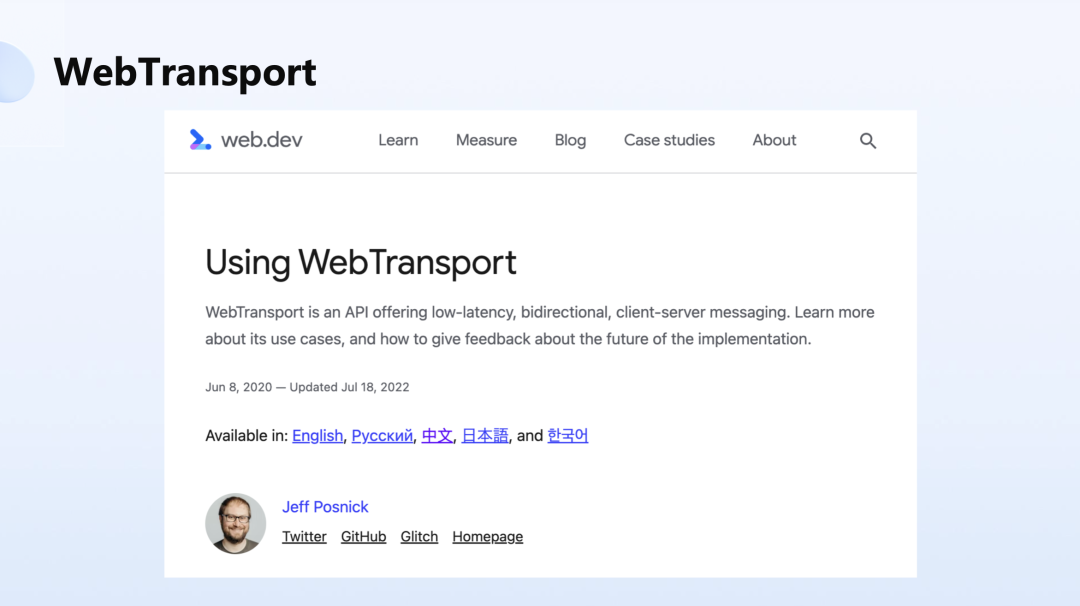
我们能看到关于 WebTransport 的介绍,它其实就是一个使用 HTTP/3 协议的一个双向的传输通道,它被设计就是为了要解决双向通讯的问题。
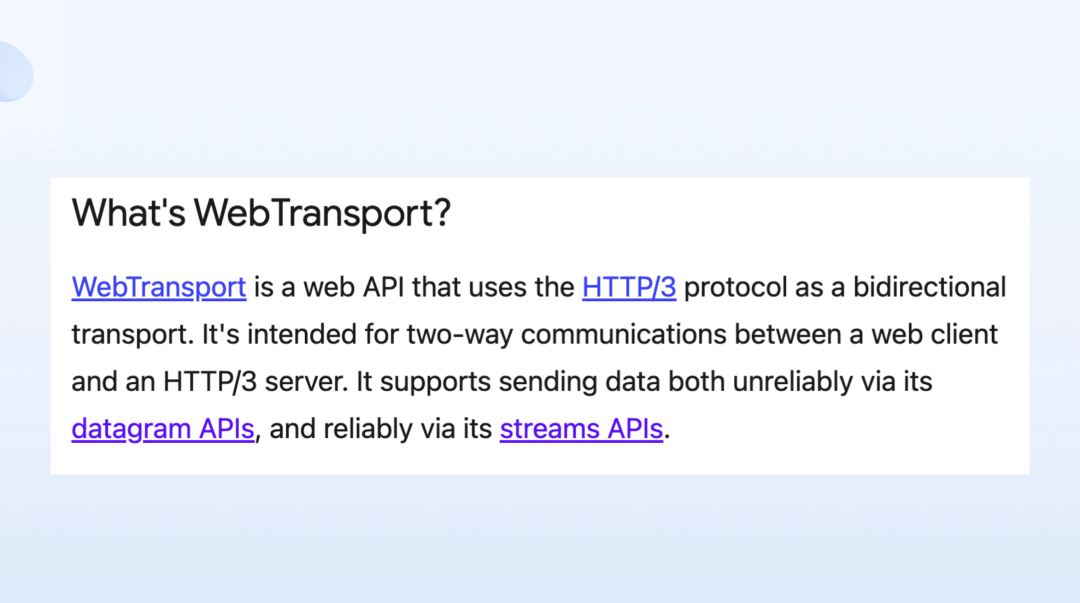
其中提到的 Datagrams 就非常有意思,很多基于 Web 去做游戏的人没法用 UDP ,开发者就要花很大的精力去解决这个领域的问题,所以后来很多应用都不得不选择去降级处理,大多都会选择通过牺牲产品体验的方式,就是因为技术上没法满足。
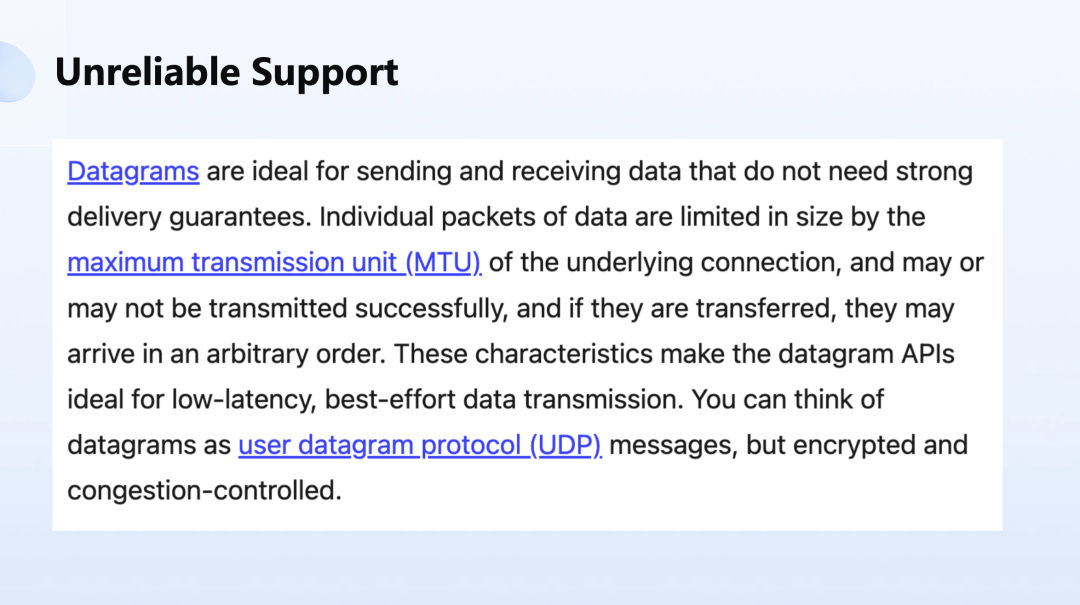
那今天有了像 Datagrams 的宝贝,我们就能像 UDP 一样的去高速的去传数据,这是给 Web 开发者引入了新的东西。

同样,Streams API 也非常的强大。今天我们可以用来去操作字节流,不需要去关注各种的对象的问题,我的音频、视频,我的各种流式的编解码器都能够放到前端去做。
下面我们来看看 Streams API 的使用方式。

上图所示是如何发数据到 WebTransport。能看到需要先创建一个 SendStream,然后拿到这个 Stream 要去 getWriter。第二行、第三行、第四行是要准备好我的数据要按照 Uint8Array 的形式准备好,然后要把它 write 过去,还要去看控制 error 的问题。
如果要接收读取更费事了。

要读的时候要先去创建一个 receiveStream,拿到他的 reader 后,要一直去 read 数据。但这个时候就有一个问题了,如果我的 server 和我的客户端去交互的时候,我怎么知道我的每一个数据包的边界是什么?像我连续的传两个 json 过去,我怎么知道如何区分这两个 json 什么时候开始做反序列化?这些都使得前端的开发者不得不要自己去设计一些数据结构。
那么这种非常底层,low level 的 API,这就像我们直接在用 TCP、用 UDP、用 QUIC 是一个道理,我们需要做大量的基础工作来去支撑我们的上层建筑的开发。
但 Strams API 有一个非常好的功能是他支持双向流,那么支持双向流的时候呢,我们的开发逻辑就会变得更复杂了。我们一边要控制 ReadableStream,一边还要控制 WritableStream,往往我收到的数据要做一些工作,而我还要完成一些异步的操作,这会使得我们的编程模型变得更加的复杂,尤其是业务逻辑复杂的时候,这个就非常难控制了。
那么 WebTransport 虽然看起来使用方式很简单,但是要做大型项目的时候,还是有困难的。我们可以在官方推荐的 WebTransport.day 上面去体验一下 WebTransport 的速度如何。
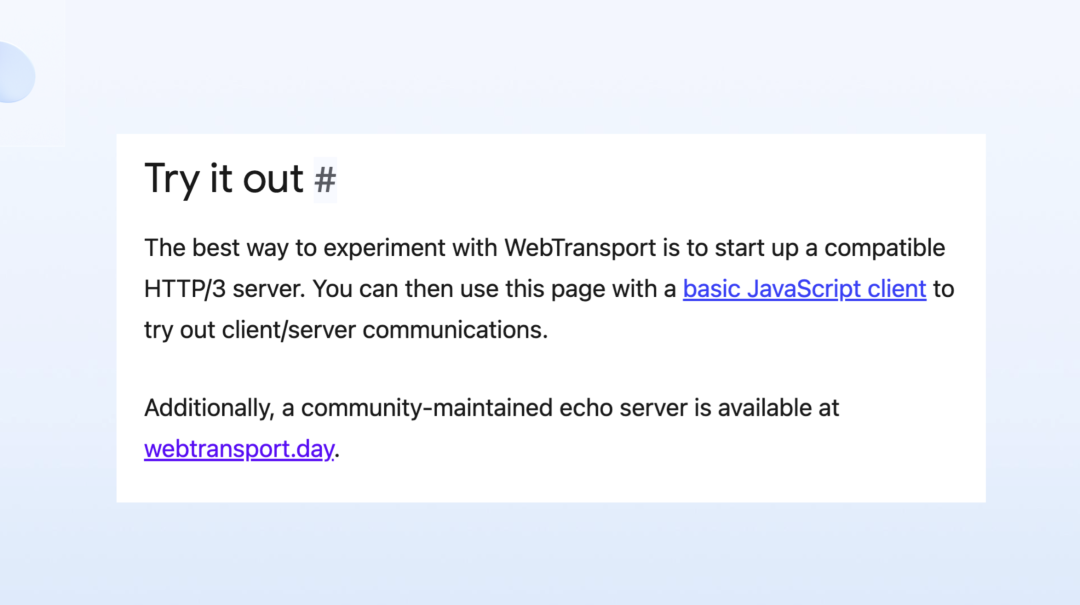
在 WebTransport 之外,我们也是可以使用 YoMo 去写一个 Serverless 的方式看到整个 Server 端的逻辑开发。做过前端实时通讯的同学一定都非常困恼当年我们去写 WebSocket 的业务逻辑,比如说基于 SocketIO,要处理很多很多的问题,然后还可能要在 WebSocket 上做 RTC 类的数据等等。
体验过后,能明显感受到 WebTransport 的使用比 WebSocket 是难了很多的,那么如何能让 WebTransport 在 server 端的开发变得异常的容易,并且可以不去关心整个的网络层、流这些复杂的 API,只是简单的就像前面的全球响应的模型一样,去写我们的代码。?同时我写完的代码能不能分别部署在不同的区域里边,能使得就近去服务不同区域的用户?
这些是可以借助于 YoMo 来完成的。
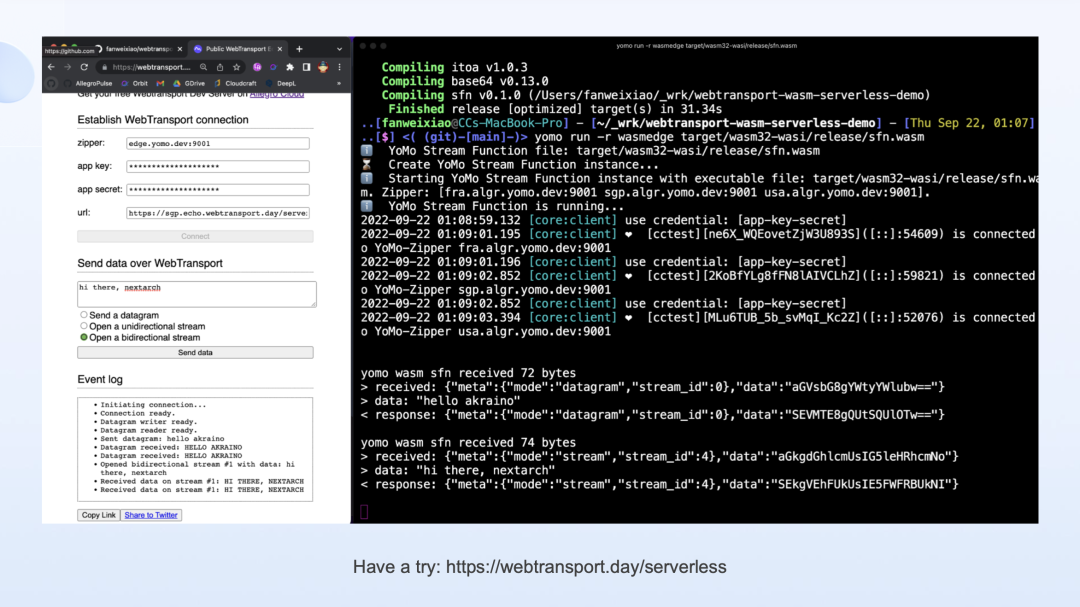
进入 https://webtransport.day/serverless 页面,我们可以去创建一个 serverless ,用 rust 来写,然后编译成一个 WebAssembly 文件,用 YoMo 在本地运行起来。
这样全球的用户都可以把数据发到 YoMo 的开发者服务的节点上,这是一个免费的为开发者提供测试服务,这个服务会把数据推到你本机的 webAssembly 进程中去,执行并拿到数据的结果。
以上就是我今天跟大家的一些分享,这也是在过去的两年里边我们服务了一些 Metaverse 产品的开发者后的经验。这些开发者有的是做 VR 的、有的做 AR 的,有的基于 Web 在做游戏和办公协作(Collaborative SaaS),也有的是基于手机设备和移动设备来做 Metaverse 的游戏应用等等。
针对于这些不同产品的构建方式以及复杂程度,我们在整个的开发者程序里边打磨出来的开发模式 Stream Serverless,可以基于 Streaming Stateful Serverless 的开发方式。
欢迎大家跟我们一起来打造未来实时全球互联网的新浪潮!
![【GO】 K8s 管理系统项目[API部分--Deployment]](https://img-blog.csdnimg.cn/c25de7f500664a7a82e9c567a04c2d57.png)

![[附源码]Node.js计算机毕业设计服装创意定制管理系统Express](https://img-blog.csdnimg.cn/8b11594b51f14a1e87280eefef888051.png)