汇编语言是一种面向机器的低级语言,用于编写计算机程序。汇编语言与计算机机器语言非常接近,汇编语言程序可以使用符号、助记符等来代替机器语言的二进制码,但最终会被汇编器编译成计算机可执行的机器码。
相较于高级语言(如C、Python等),汇编语言学习和使用难度相对较大,需要对计算机内部结构、指令集等有深入的了解,以及具有良好的编程习惯和调试能力。但对于需要对计算机底层进行操作的任务,汇编语言是极其高效的,因为其可以实现对计算机底层资源的精细控制,极大地提高了计算机运行效率。
尽管在当今计算机界已经不再使用汇编语言来开发程序,但作为一名安全从业者掌握汇编语言将会是高手与专家之间最大的差距,汇编语言作为底层语言,具有直接访问计算机硬件和系统资源的能力,因此在系统级漏洞挖掘、内核安全、计算机反病毒等领域中具有非常重要的作用。
以下是关于汇编语言的应用场景:
-
系统级漏洞挖掘:许多系统级漏洞,如堆栈溢出、整数溢出等,都是由于程序员没有理解底层操作系统和硬件的工作原理而导致的。因此,理解汇编语言可以帮助安全研究人员更好地了解底层的操作系统和硬件原理,从而更好地挖掘漏洞。
-
内核安全:汇编语言是编写内核模块或驱动程序所必需的语言,例如,Linux内核中的大部分代码都是使用汇编语言实现的。因此,对于理解内核原理和进行内核安全研究来说,掌握汇编语言非常重要。
-
计算机反病毒:许多计算机病毒和恶意软件都使用汇编语言编写,因此掌握汇编语言可以帮助研究人员更好地理解这些恶意软件的工作原理和行为,并提高反病毒软件的捕获率和准确性。
总之,熟练掌握汇编语言对于进行系统级漏洞挖掘、内核安全研究、计算机反病毒等领域都非常有帮助。虽然汇编语言相对来说比较底层和难以理解,但是深入掌握汇编语言将会极大地提高软件安全研究人员的技能和水平,让读者从一个高手蜕变成一名安全专家。
本章中所提到的汇编语言为Windows汇编,在Windows平台下读者可使用MASM工具对汇编语言进行编译测试,也可以使用通用的集成开发环境实现编译,笔者推荐使用RadASM工具,RadASM 是一个面向汇编编程的开发环境,提供了一系列工具和功能,用于编写、调试和优化汇编语言程序。该工具具有良好的可定制性和扩展性,且能提供丰富的工具和功能,方便程序员进行汇编语言的开发和调试工作。
1.1 RadASM
当读者准备好开发环境后可打开RadASM工具,选择文件新建工程按钮,并选择ConsoleApp选项填入自定义工程名称并一直点击下一步即可,当读者进入到主页面后会看到如下图所示的窗体,其中最右侧则是我们的项目目录,该目录下的Resources则是我们需要测试代码的地方,读者可自行点开*.asm文件并在此处写代码,当读者需要编译代码可使用快捷键Ctrl+Shift+V快速构建,也可点击右上角的编译构建按钮自行构建;
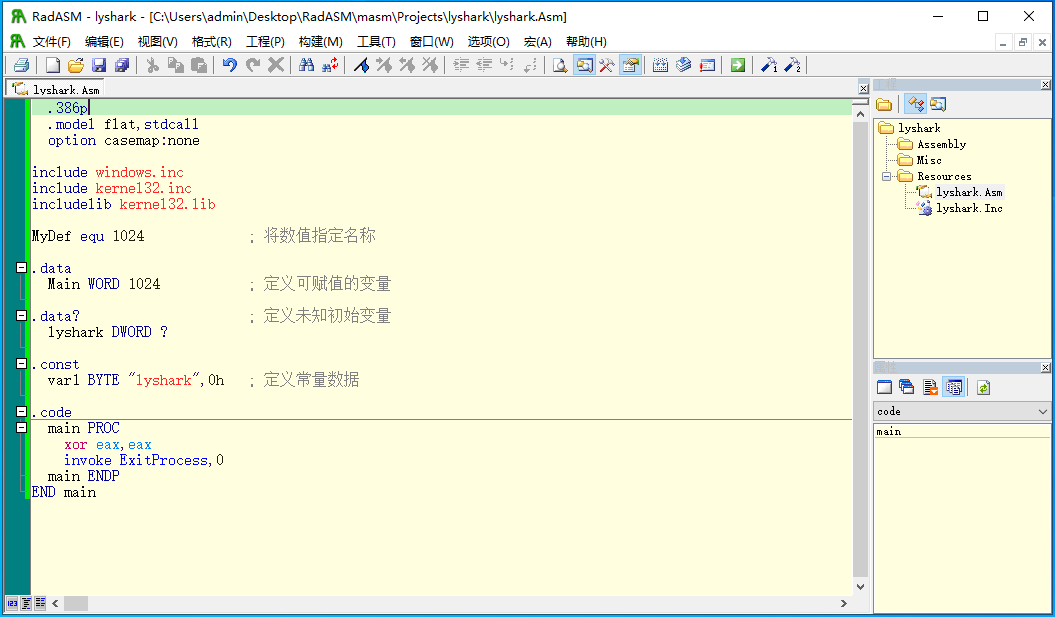
使用Win32汇编语言做开发其开发感觉与高级语言基本一致,并没有像大家想象中的那么困难,唯一的区别只是在高级语言中可以很容易实现的语句,而到了汇编语言这里将会变得较为繁琐,读者只要认真理解汇编语言中的每一条指令所代表的含义,则同样可以灵活的运用汇编语言开发大型项目,首先笔者来解释一下关于上述图片中代码的具体含义;
根据上述代码中第一行的定义.386p代表了指令集的选择,此处代表我们选用Intel 80386处理器的指令集,其中的p则代表将代码对齐到32位指令上,接着看第二行.model flat, stdcall此处代表了调用约定采用stdcall模式,并设置代码和数据段都使用平坦模型(flat model)来处理内存,第三行option casemap:none代表后续程序不区分大小写,当有了上述这三行定义后汇编语言的预定义部分也就结束了。
接着就是比较熟悉的定义语法了,这里的include/includelib分别代表头文件以及库文件的引用,如果读者需要调用Windows系统内的函数定义,则此处的头文件则是必须要包含windows.inc以及kernel32.inc头的,此外还需要导入kernel32.lib库来完成头文件功能的导入;
- .data:定义已初始化变量。该指令定义了一个16位的可赋值变量Main,并将其初始化为1024。
- .data?:定义未初始化变量。该指令定义了一个32位的未初始化变量lyshark。
- .const:定义常量。该指令定义了一个以0h(十六进制)为结尾的字符串常量var1,内容为“lyshark”。
- .code:代码段开始。该指令表示代码段的开始。
接下来就是main PROC以及main ENDP定义了,此处的定义部分读者可理解为int main()函数,此处的功能同样是定义主程序入口和结束,而当我们需要编写应用程序时只需要在上方不同的段内填充参数即可,其开发流程可以与高级语言一致。
1.2 汇编中的变量
MASM 定义了多种内部数据类型,每种数据类型都描述了该类型的变量和表达式的取值集合,汇编语言中数据类型的基本特征是以数据位数为度量单位,8,16,32,48,64,80位,而除此之外其他的特征如(符号,指针,浮点数)主要是为了方便我们记忆变量中存储的数据类型,如下表中所定义的部分,则是IEEE委员会发布的标准内部数据类型;
| 数据类型 | 作用(无符号) | 数据类型 | 作用(有符号) |
|---|---|---|---|
| BYTE | 8位无符号整数 | SBYTE | 8位有符号整数 |
| WORD | 16位无符号整数 | SWORD | 16位有符号整数 |
| DWORD | 32位无符号整数 | SWORD | 32位有符号整数 |
| FWORD | 48位整数(远指针) | QWORD | 64位整数定义 |
| REAL4 | 32位(4字节)短实数 | REAL8 | 64位(8字节)长实数 |
数据类型定义语句为变量在内存中保留存储空间,并且可以选择为变量指定一个名字,在汇编语言中所有的数据无非就是BYTE的集合,数据的定义语句格式如下;
[变量名] 数据定义伪指令 初始值[....]
在数据定义语句中使用BYTE(定义字节)和SBYTE(定义有符号字节)伪指令,可以为每一个或多个有符号或无符号字节分配存储空间,每个初始值必须是8位整数表达式或字符常量,例如下面的定义:
.data
var1 BYTE 'A' ; 定义字符常量
var2 BYTE ? ; 定义未初始化变量
var3 BYTE 0 ; 最小的无符号字节常量
var4 BYTE 255 ; 最大的无符号字节常量
var5 SBYTE -128 ; 最小的有符号字节常量
var6 SBYTE +127 ; 最大的有符号字节常量
如果一条数据定义语句中有多个初始值,那么标号仅仅代表第一个初始值的偏移,如下我们首先定义一个BYTE数组,然后通过反汇编查看地址的偏移变化就能看到效果啦:
.data
list BYTE 10,20,30,40,50
00E71000 | B8 0030E700 | mov eax,main.E73000 | E73000=10
00E71005 | B8 0130E700 | mov eax,main.E73001 | E73001=20
00E7100A | B8 0230E700 | mov eax,main.E73002 | E73002=30
00E7100F | B8 0330E700 | mov eax,main.E73003 | E73003=40
00E71014 | B8 0430E700 | mov eax,main.E73004 | E73004=50
并非所有的数据定义都需要标号,如果想继续定义以list开始的字节数组,可以在随后的行上接着上面的定义:
.data
list BYTE 10,20,30,40,50
list BYTE 60,70,80,90,100
当然除了定义整数字符以外,还可以定义字符串,要想定义字符串应将一组字符用单引号或双引号括起来,最常见的字符串是以空格结尾0h,在C/C++中定义字符串无需添加结尾0h,这是因为编译器会在编译的时候自动的在字符串后面填充了0h,在汇编语言中我们需要手动添加字符串结尾的标志,以告诉汇编器字符串的结束。
.data
string1 BYTE "hello lyshark",0h
string2 BYTE "good night",0h
00F23000 68 65 6C 6C 6F 20 6C 79 73 68 61 72 6B 00 67 6F hello lyshark.go
00F23010 6F 64 20 6E 69 67 68 74 00 00 00 00 00 00 00 00 od night........
字符串也可以占用多行,而无须为每行都提供一个编号,如下代码也是合法的:
.data
string1 BYTE "welcom to the Demo program"
BYTE "created by lyshark",0dh,0ah,
BYTE "url:lyshark"
BYTE "send me a copy",0dh,0ah,0
十六进制0dh,0ah也称为CR/LF(回车换行符),或者是行结束的字符,在向标准输出设备上写的时候,回车换行符可以将光标移动到下一行的开头位置,从而继续填充新的字符串。
有时我们需要初始化一些空值的内存空间,在为内存地址分配空间的时候,DUP伪指令就显得尤为重要,初始化和未初始化数据均可使用DUP指令定义,其定义语法如下:
.data
string1 BYTE 20 DUP(0) ; 分配20字节,全部填充0
BYTE 20 DUP(?) ; 分配20字节,且未初始化
BYTE 50 DUP("stack") ; 分配50字节,"stackstack..."
.data
smallArray DOWRD 10 DUP(0) ; 分配40字节
bigArray DOWOR 5000 DUP(?) ; 分配20000字节
除了上面的例子以外,我们也可以直接定义常量,常量是不可以动态修改的数据类型,一般情况下一旦定义,那么在程序运行期间不可以被修改,常量的定义很简单,只需要将.data换成.const即可。
.const
var1 BYTE "hello world",0h ; 初始化为BYTE的字符串
var2 DWORD 10 ; 初始化为10的DWORD类型
var3 DWORD 100 dup(1,2) ; 200个DWORD的缓冲区
var4 BYTE 1024 dup(?) ; 1024字节的缓冲区
var5 BYTE "welcome",0dh,0ah,0 ; 0dh,0ah为换行符
有时我们需要计算一个指定数组的所占空间的大小,但手动计算显得特别麻烦,此时我们可以使用MASM提供的$符号来进行数组大小的计算过程,如下定义汇编器会将其进行预处理后回写到变量中存储。
.data
list BYTE 10,20,30,40,50
listsize = ($ - list) ; 计算字节数据大小
.data
list WORD 1000h,2000h,3000h,4000h
listsize = ($ - list) /2 ; 计算字数据大小
.data
list DWORD 100000h,200000h,300000h,400000h
listsize = ($ - list) /4 ; 计算双字数据大小
.data
MyString BYTE "hello lyshark",0h
MyString_len = ($ - MyString)
1.3 标准输入与输出
在汇编语言中,有时我们需要获取到数据的输入输出,由于汇编中并不存在屏幕打印功能,此处如果读者需要使用此功能,则必须调用系统所提供的库函数来实现,一般要想实现输入输出有多种图形,具体来说,StdIn和StdOut分别代表标准输入流和标准输出流;WriteFile函数用于向文件或其他输出设备写入数据;crt_scanf和crt_printf是格式化输入/输出函数,这些库函数的调用都可以使用invoke这个伪指令来实现,invoke是MASM中提供的调用关键字,使用它可实现调用各类API函数的目的。
StdIn/StdOut
如果读者需要使用该函数输出,则需要包含masm32.inc头文件,该头文件为汇编语言程序员提供了一组常用的宏和函数,在这个头文件中,定义了StdIn、StdOut和StdErr三个宏,它们分别代表标准输入流、标准输出流和标准错误流。
使用masm32.inc中的这些宏,可以方便地将输入输出重定向到控制台或文件中,而无需直接调用Windows API函数。例如,可以使用StdIn宏从控制台读取用户输入,使用StdOut宏向控制台输出字符流。这些宏的使用方式与在C语言中使用 stdin 和 stdout 类似。
下面是一些示例代码,使用masm32.inc头文件来实现标准的输入输出:
.386
.model flat, stdcall
include masm32.inc
include kernel32.inc
includelib masm32.lib
includelib kernel32.lib
.data
len equ 20
OutText dw ?
ShowText db "请输入一个数: ",0
.code
main PROC
invoke StdOut, addr ShowText ; 输出提示信息
invoke StdIn, addr OutText,len ; 等待用户的输入
invoke StdOut, addr OutText ; 输出刚才输入的内容
ret
main ENDP
END main
crt_printf/crt_scanf
除了使用MASM定义的宏之外,读者也可以使用C语言库函数中的一些输出函数,为了使用crt_printf,需要在程序中包含msvcrt.inc头文件,并将msvcrt.lib库作为链接器参数之一。然后,可以使用crt_printf宏来输出格式化的文本信息到控制台或文件中。
下面是一个简单的使用crt_printf的示例程序:
.386
.model flat, stdcall
include msvcrt.inc
includelib msvcrt.lib
.data
PrintText db "EAX=%d;EBX=%d;EDX=%d | InPut ->: ",0
ScanFomat db "%s",0
PrintTemp db ?
.code
main PROC
mov eax,10
mov ebx,20
mov ecx,30
invoke crt_printf,addr PrintText,eax,ebx,ecx ; 打印提示内容
invoke crt_scanf, addr ScanFomat, addr PrintTemp ; 输入内容并接收参数
invoke crt_printf, addr PrintTemp ; 输出输入的内容
ret
main ENDP
END main
本文作者: 王瑞
本文链接: https://www.lyshark.com/post/9d939a6f.html
版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!