文章目录
- Pandas的数据结构
- Series --- 由数据和索引组成(索引(index)在左,数据(values)在右)
- DataFrame --- 索引包括行索引和列索引,每列数据可以是不同的类型
- Pandas的索引操作 --- 索引对象index
- Series
- DataFrame
- Pandas的对齐运算
- Series
- DataFrame
- Pandas的函数应用
- 层级索引
- Pandas的统计和计算
- Pandas分组与聚合
- 分组
- 聚合
- 时间序列
- 分组和连接
- 数据合并
Pandas的数据结构
Series — 由数据和索引组成(索引(index)在左,数据(values)在右)

import pandas as pd
# 生成一个series
ser_obj = pd.Series(range(10, 20))
print(ser_obj)
print("--" * 20)
# 获取数据
print(ser_obj.values)
print("--" * 20)
# 获取索引
print(ser_obj.index)
print("--" * 20)
# 下面对ser_obj的计算都不改变ser_obj的实际值
# 所有的值 * 2 注:索引不变
print(ser_obj * 2)
print("--" * 20)
# 值满足条件的为True 不满足为False 注:索引不变
print(ser_obj > 15)
print("--" * 20)
# 通过索引下标访问值 索引下标不存在报错
print(ser_obj[1]) # 11 上面的运算 并没有 改变ser_obj的值
# ser_obj[10] # KeyError: 10
print("---------------- 通过字典变series --------------------")
# 字典变为series
year_data = {2001: 1, 2013: 13, 2016: 16, 2019: 19, 2023: 23}
ser_obj2 = pd.Series(year_data)
print(ser_obj2)
print("--" * 20)
print(ser_obj2.index)
print("--" * 20)
print(ser_obj2.values)
print("--" * 20)
print(type(ser_obj2.values)) # <class 'numpy.ndarray'>
print(type(ser_obj2.index)) # <class 'pandas.core.indexes.base.Index'>
print("--" * 20)
print(ser_obj2[2023]) # 23
print("***" * 14)
# index.name 索引列的名字 name 整个Series的名字
# head 所有的名字 值 类型
print(ser_obj2.name)
ser_obj2.name = "temp"
print(ser_obj2.index.name)
ser_obj2.index.name = "year1"
print("--" * 20)
print(ser_obj2.head())
# print(ser_obj2.head(n)) # 打印前n行的信息,但是索引列的名字和 series的名字都会显示 还有dtype

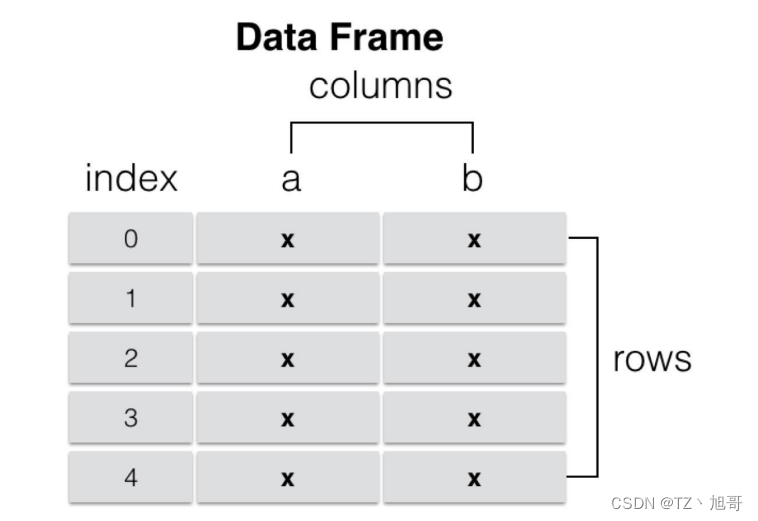
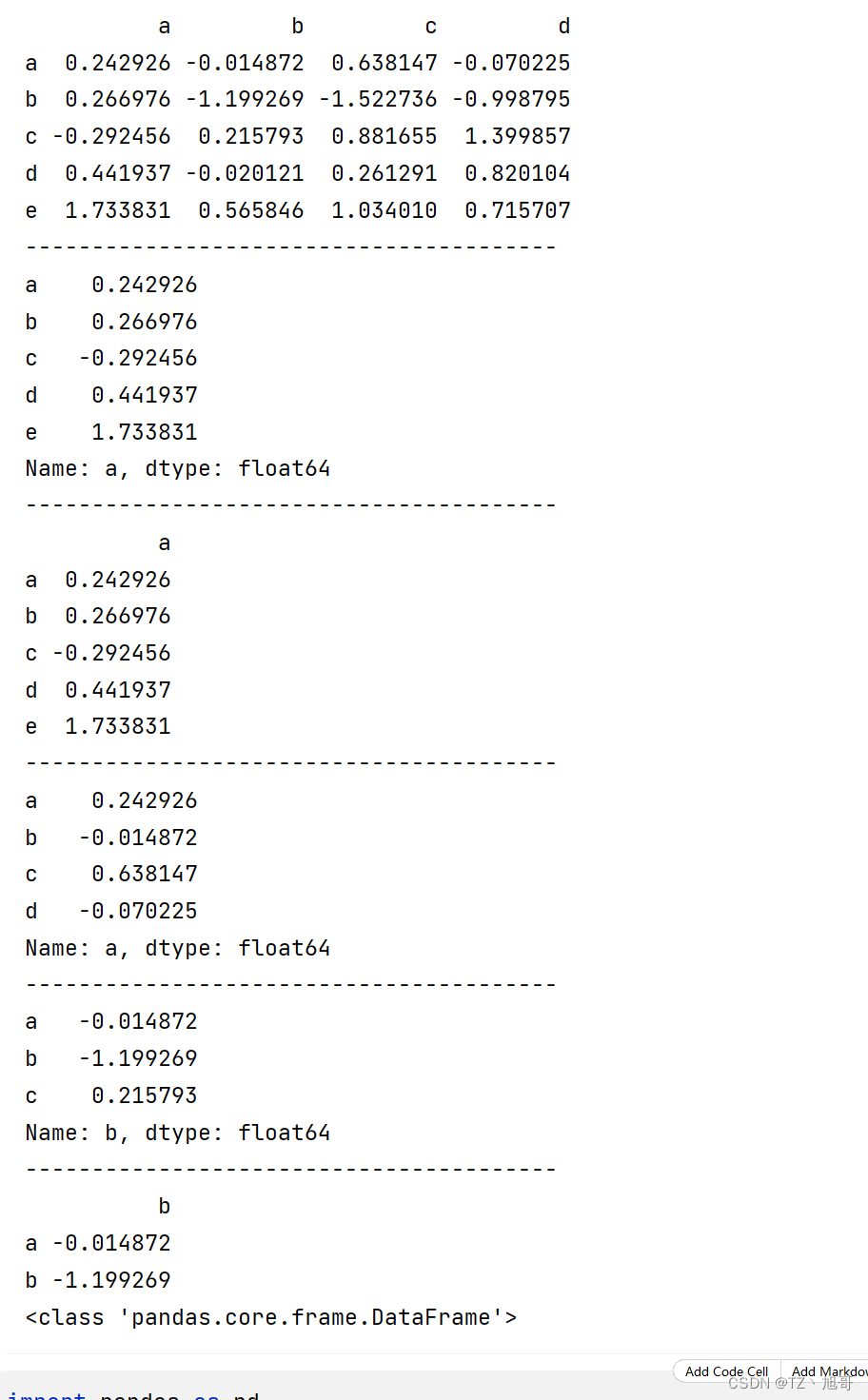
DataFrame — 索引包括行索引和列索引,每列数据可以是不同的类型
import pandas as pd
import numpy as np
# 通过 ndarray 构建 DataFrame
arr = np.arange(18).reshape((3, 6))
print(pd.DataFrame(arr))
print("---" * 20)
# 通过 dict 构建 DataFrame
d = [{"name": "xiaohong", "age": 23, "tel": 10086},
{"name": "xiaogang", "tel": 10087},
{"name": "xiaowang", "age": 22, "tel": 10088}]
df = pd.DataFrame(d)
print(df)
print("---" * 20)
# 列 要不相等 要不为1
dict_data = {'A': 1,
'B': pd.Timestamp("20190926"),
'C': pd.Series(1.5, index=list(range(4))),
'D': np.array([3] * 4, dtype='int32'),
'E': ["python", "c", "c++", "java"],
'F': 'wangdao'}
df_obj = pd.DataFrame(dict_data)
print(df_obj)
print("--" * 20)
print(df_obj.columns) # Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
print("--" * 20)
# 感受日期 date_range
# random.randn(x,y) 生成 x行 y列 随机数
dates = pd.date_range('20130101', periods=6)
df1 = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df1)
print("--" * 20)
# 把df的某一列取出来是Series 且 名字是 series的名字
print(df_obj['B'])
print(type(df_obj['B']))
print("--" * 20)
# 增加列数据 列名 自定义
df_obj['G'] = df_obj['D'] + 4
print(df_obj)
# 删除列
del (df_obj['G'])
print("--" * 20)
print(df_obj)
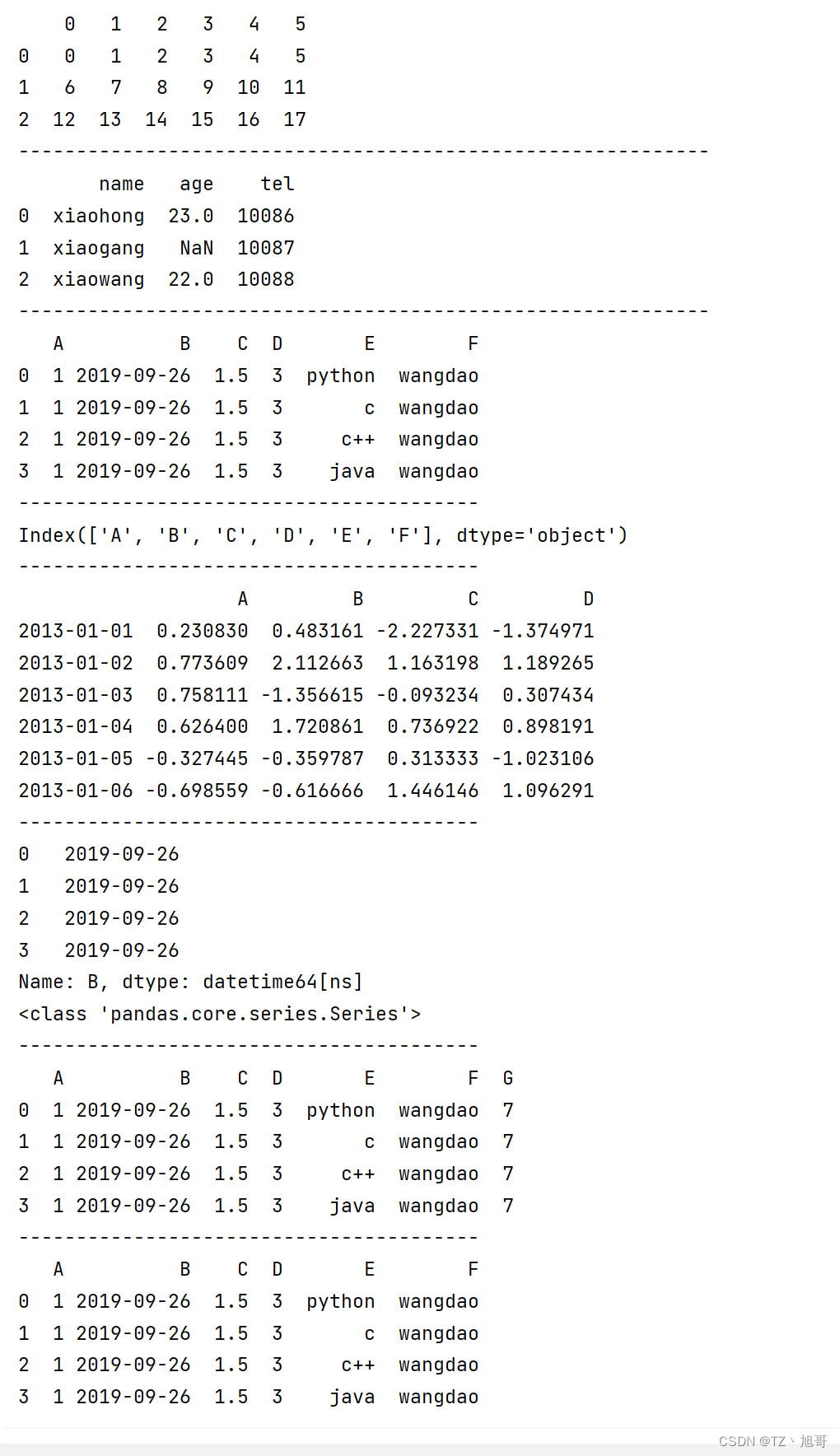
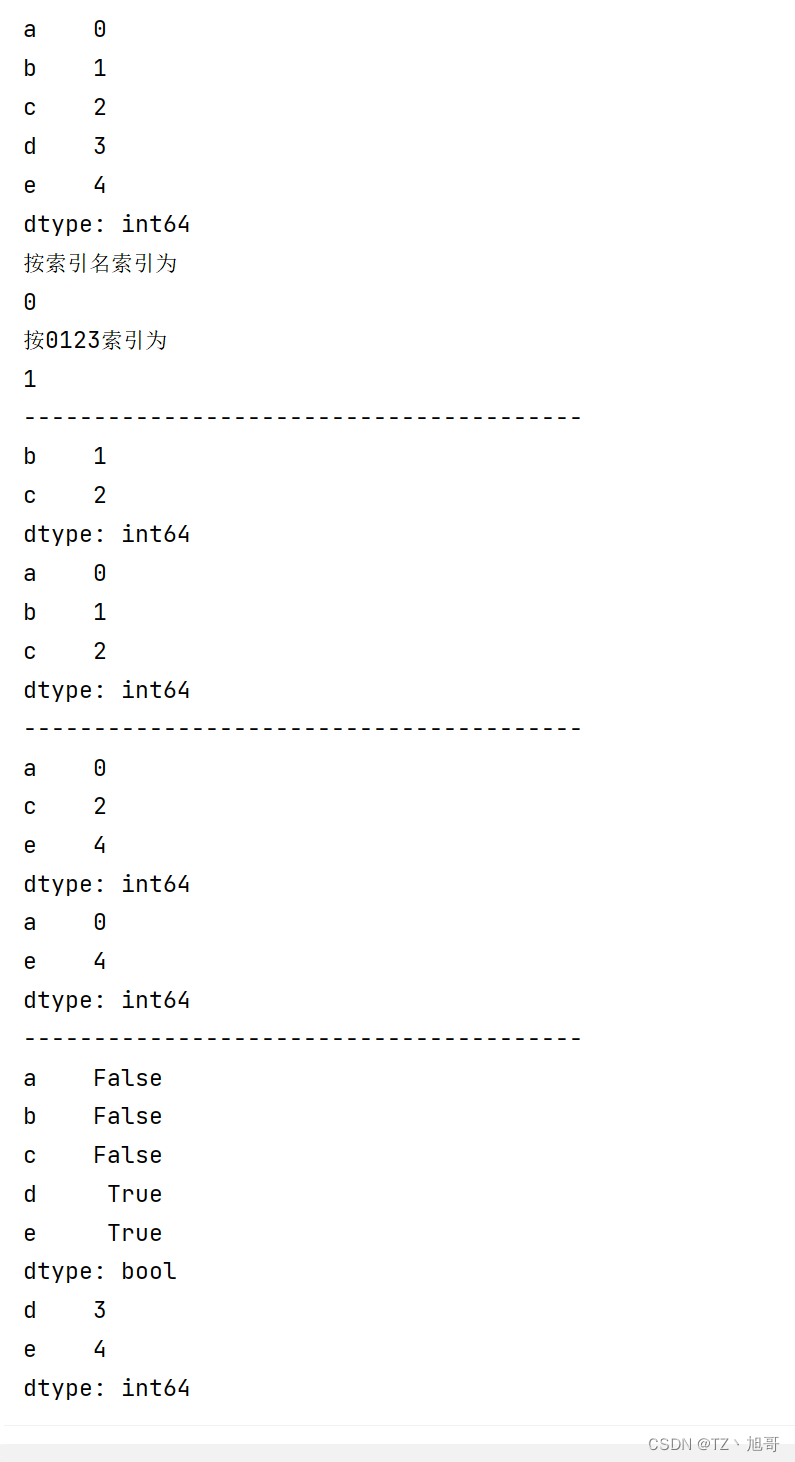
Pandas的索引操作 — 索引对象index

Series
import pandas as pd
# Series 索引
# Series(值,索引)
# ser_obj = pd.Series(range(5), index=['a', 'b', 'c', 'd', 'e']) # 和下面这句功能一样
ser_obj = pd.Series(range(5), index=list("abcde"))
print(ser_obj)
# 行索引 可以用索引名 也可以用0123(默认都有 即使取了别名)
print("按索引名索引为")
print(ser_obj['a'])
print("按0123索引为")
print(ser_obj[1])
print("--" * 20)
# 切片索引
print(ser_obj[1:3]) # 按0123索引 左闭右开
print(ser_obj['a':'c']) # 按索引名 左右都闭---因为你不知道c前面是谁 所以不知道到哪停止
print("--" * 20)
# 不连续索引 [[]]
print(ser_obj[[0, 2, 4]])
print(ser_obj[['a', 'e']])
print("--" * 20)
# 布尔索引
ser_bool = ser_obj > 2
print(ser_bool)
# 下面两个结果一样
print(ser_obj[ser_bool])
# print(ser_obj[ser_obj > 2])
DataFrame
import numpy as np
import pandas as pd
# DataFrame索引 index=行 columns=列
df_obj = pd.DataFrame(np.random.randn(5, 4),
index=['a', 'b', 'c', 'd', 'e'],
columns=['a', 'b', 'c', 'd'])
print(df_obj)
print("--" * 20)
# 列索引
print(df_obj['a']) # []返回Series类型
print("--" * 20)
print(df_obj[['a']]) # [[]]返回DataFrame类型
print("--" * 20)
# 标签索引 loc 索引---(名) [] 左右都是闭区间 名只能用名字 不能用0123
# Series
print(df_obj.loc['a']) # 推荐 取---行
# print(df_obj['a']) # 建议不用 取---列
print("--" * 20)
# 第一个参数是行,第二个参数是列
print(df_obj.loc['a':'c', 'b'])
print("--" * 20)
# iloc ---(位置) 索引 是 前闭后开 [) 位置只能用 数字0123
print(df_obj.iloc[0:2, 1:2])
print(type(df_obj.iloc[0:2, 1:2]))
Pandas的对齐运算
Series
import pandas as pd
# 对齐运算 缺失数据 默认是nan 注:只有float类型才有nan和inf
# Series
s1 = pd.Series(range(10, 20), index=range(10))
s2 = pd.Series(range(25, 30), index=range(5))
s3 = s1 + s2
print(s3) # 缺失数据 默认是nan
print("--" * 20)
# 未对齐的数据(nan) 和 填充值fill_value ---做 ---运算
# 注:不是---计算完 ---以后 在把nan填充成fill_value
print(s1.add(s2, fill_value=0))

DataFrame
import pandas as pd
# np.ones(x,y) 用 1. 填充x行y列
df1 = pd.DataFrame(np.ones((2, 2)), columns=list('ab'))
df2 = pd.DataFrame(np.ones((3, 3)), columns=['a', 'b', 'c'])
print(df1 - df2)
print("--" * 20)
print(df1.sub(df2, fill_value=2.)) # nan 的位置用 2. 来计算 (写成2也行)

Pandas的函数应用
import pandas as pd
import numpy as np
# 函数应用 Series
df = pd.DataFrame(np.random.randn(5, 4) - 1)
print(df)
print("绝对值如下np.abs():")
print(np.abs(df)) # 绝对值
print("--" * 20)
# apply 作用在 列上 axis 默认为0
print(df.apply(lambda x: x.max()))
print("--" * 20)
# apply 作用在 行上
print(df.apply(lambda x: x.max(), axis=1))
print("--" * 20)
# applymap 作用到 每个数据
print(df.applymap(lambda x: '%.2f' % x)) # 保留两位小数
# print(df.dtypes)
print("--" * 20)
s = pd.Series(range(10, 15), index=np.random.randint(5, size=5)) # 必须加size=5
print(s)
print("--" * 20)
# 索引排序(sort_index)
print(s.sort_index())
print("--" * 20)
# DataFrame
df = pd.DataFrame(np.random.randn(5, 5),
index=np.random.randint(5, size=5),
columns=np.random.randint(5, size=5))
print(df)
print("--" * 20)
# 轴0是行索引排序
# sort_index 默认是升序排序 ascending=False 为降序排序
df_rSort = df.sort_index(axis=0, ascending=False)
print(df_rSort)
print("--" * 20)
# 轴1是列索引排序
df_cSort = df.sort_index(axis=1, ascending=False)
print(df_cSort)
print("--" * 20)
# 按值排序(sort_values) by后是column的值
import random
l = [random.randint(0, 100) for i in range(24)]
df2 = pd.DataFrame(np.array(l).reshape(6, 4))
print(df2)
print("--" * 20)
# 按轴0排序 by后是列名 ---结果以 行的形式展示
df2_cSort = df2.sort_values(by=3, axis=0, ascending=False)
print(df2_cSort)
print("--" * 20)
# 按轴1排序 by后是行名 ---结果以 列的形式展示
df2_rSort = df2.sort_values(by=3, axis=1, ascending=False)
print(df2_rSort)

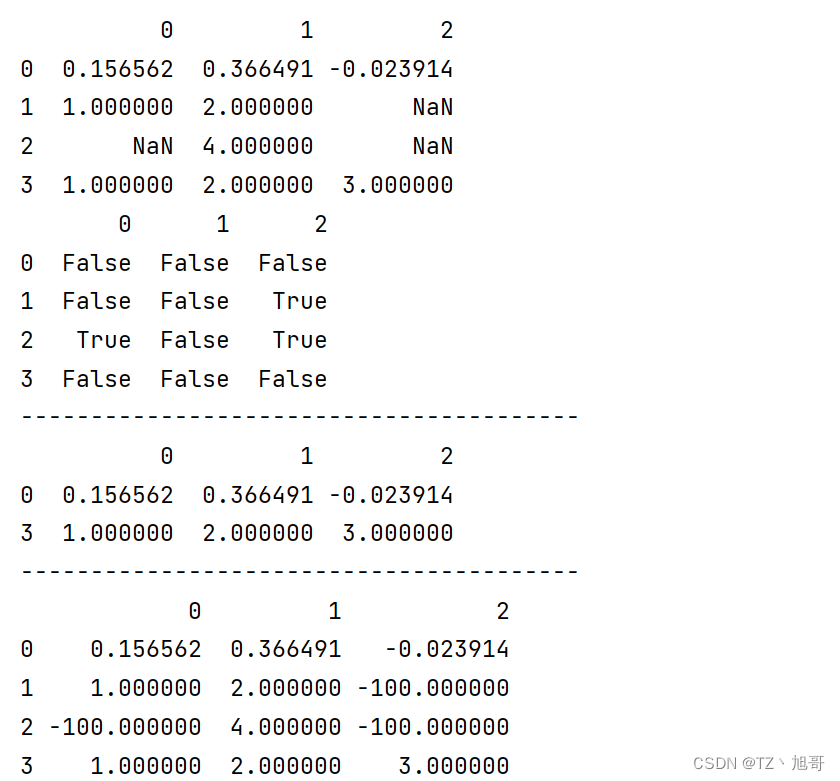
# 处理缺失数据
df = pd.DataFrame([np.random.randn(3), [1., 2., np.nan], [np.nan, 4., np.nan], [1., 2., 3.]])
print(df.head())
# df.isnull() nan 为True 其他为 False
print(df.isnull())
print("--" * 20)
# df.dropna() 默认是删除行 ---加axis=1 就是删除列(一般不用)
print(df.dropna())
print("--" * 20)
# fillna 把nan填成某值
print(df.fillna(-100.))
print("--" * 20)
层级索引
index1 = pd.MultiIndex.from_arrays([['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c'], [0, 1, 2, 0, 1, 2, 0, 1, 2]],
names=['cloth', 'size'])
ser_obj = pd.Series(np.random.randn(9), index=index1)
print(ser_obj)
print("--" * 20)
print(ser_obj.index)
# [['a', 'b', 'c'], [0, 1, 2]]
print(ser_obj.index.levels)
print("--" * 20)
# 层级索引如何获取数据
print(ser_obj['c']) # 外层索引
print("--" * 20)
print(ser_obj['c', 1]) # 内层索引
print("--" * 20)
print(ser_obj[:, 2])
print("--" * 20)
# 交换层级 swaplevel()
print(ser_obj.swaplevel())
print("--" * 20)
print(ser_obj)
print("--" * 20)
# 层级索引按那个索引级别排序
print(ser_obj.sort_index(level=1))
# unstack 可以放索引名 或者索引位置
print("--" * 20)
df_obj = ser_obj.unstack(1) # 把1层索引 放到上面 变成dataframe
print(df_obj)
print("--" * 20)
# stack 把行、列索引进行堆叠 变成Series
print(df_obj.stack())
Pandas的统计和计算
import numpy as np
import pandas as pd
# pandas统计和计算
# axis = 1 统计每一行 axis = 0 统计每一列
df_obj = pd.DataFrame(np.random.randn(5, 4), columns=list('abcd'))
print(df_obj)
df_obj.loc[1, 'b'] = np.nan
print(df_obj)
print("--" * 20)
# skipna 是否跳过nan 默认是True axis=1 表示每一行的最小值 axis=0表示每一列的最小值
print(df_obj.min(axis=1, skipna=False))
print("--" * 20)
# describe() 最大值 最小值 数值的个数 方差 等等都有
print(df_obj.describe())
print("--" * 20)
# 计算最大值或者最小值的 位置
# argmin 和 argmax 只能是Series 不能是 DataFrame
print(type(df_obj.loc[:, 'c'])) # Series
print(df_obj.loc[:, 'c'].argmin())
print("--" * 20)
# 计算最大值或者最小值的 索引 idxmax idxmin
print(df_obj.idxmax(axis=0)) # axis=0 表示每一 列

Pandas分组与聚合
分组
import numpy as np
import pandas as pd
# 分组 都是按 轴1分组 因为每一列代表一种类型
# 字典默认作为列名
dict_obj = {'key1': ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
print("--" * 20)
# dataframe根据key1进行分组,分组后的对象类型
print(df_obj.groupby('key1'))
print(type(df_obj.groupby('key1')))
print("--" * 20)
print(df_obj['data1'])
# dataframe 的 data1 列 根据key1 进行分组
print(type(df_obj['data1'].groupby(df_obj['key1'])))
print("--" * 20)
# 分组运算
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())
print("--" * 20)
# 按自定义的key分组
self_def_key = [0, 1, 2, 3, 3, 4, 4, 7]
print(df_obj.groupby(self_def_key).size()) # 等于mysql的count
print(df_obj.groupby(self_def_key).sum())
print("--" * 20)
# 按自定义key分组,多层列表
print(df_obj.groupby([df_obj['key1'], df_obj['key2']]).size())
print("--" * 20)
# 按多个列 多层分组
grouped3 = df_obj.groupby(['key1', 'key2'])
print(grouped3.size())
print("--" * 20)
# 多层分组 按key的顺序进行
grouped4 = df_obj.groupby(['key2', 'key1'])
print(grouped4.size())
print(grouped4.mean())
print("--" * 20)
# unstack 可以将多层索引的结果换成单层的dataframe
print(grouped4.mean().index)
print(type(grouped4.mean().unstack()))
print(grouped4.mean().unstack())
print(grouped4.mean().unstack().columns)
print("--" * 20)
# 多层分组,根据key1 和 key2
for group_name, group_data in grouped4:
print(group_name)
print(group_data)
print(type(group_data))
print("--" * 20)
# 按类型分组
print(df_obj.dtypes)
# 一列数据类型必须一致,对应现实生活的一个特征
df_obj['data3'] = df_obj['data2'] + 1
print(df_obj)
print("--" * 20)
print(df_obj.groupby(df_obj.dtypes, axis=1).size()) # 按轴0没有意义
print(df_obj.groupby(df_obj.dtypes, axis=1).sum())
self_column_key = [1, 2, 3, 3, 4]
print(df_obj.groupby(self_column_key, axis=1).sum()) # 通过自定义索引去让不同列相加
print("--" * 20)
# 通过字典分组 randint(1, 10, (5, 5)) 1-10之间 5行5列
df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=list('abcde'), index=list('ABCDE'))
print(df_obj2)
# 给指定某个部分的数据重新赋值为np.NaN
df_obj2.loc['B', 'b':'d'] = np.nan
print(df_obj2)
print("**" * 20)
# 通过字典分组
mapping_dict = {'a': 'python', 'b': 'python', 'c': 'java', 'd': 'c', 'e': 'java'}
print(df_obj2.groupby(mapping_dict, axis=1).size()) # 值 对应的个数 c -- 1 java -- 2 python -- 2
print(df_obj2.groupby(mapping_dict, axis=1).count()) # 非nan的个数
print(df_obj2.groupby(mapping_dict, axis=1).sum()) # 求和不记录nan nan当作0了
print("--" * 20)
# 通过函数分组
df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=list('abcde'),
index=['AA', 'BBBB', 'CCC', 'D', 'EEE'])
print(df_obj3)
def group_key(idx):
return len(idx) # 默认传的是行索引 因为列索引都是1
print(df_obj3.groupby(group_key).size()) # axis 默认是0
# 上面自定义函数等价于
print(df_obj3.groupby(len).size())
print("--" * 20)
# 通过索引级别分组
columns = pd.MultiIndex.from_arrays([['python', 'java', 'python', 'java', 'c'], ['A', 'A', 'C', 'B', 'B']],
names=['language', 'index1'])
df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)
print(df_obj4)
print("--" * 20)
# 根据language进行分组
print(df_obj4.groupby(level='language', axis=1).sum())
print("--" * 20)
# 根据index进行分组
print(df_obj4.groupby(level='index1', axis=1).sum())


聚合
import numpy as np
import pandas as pd
# 聚合
# 字典默认作为列名
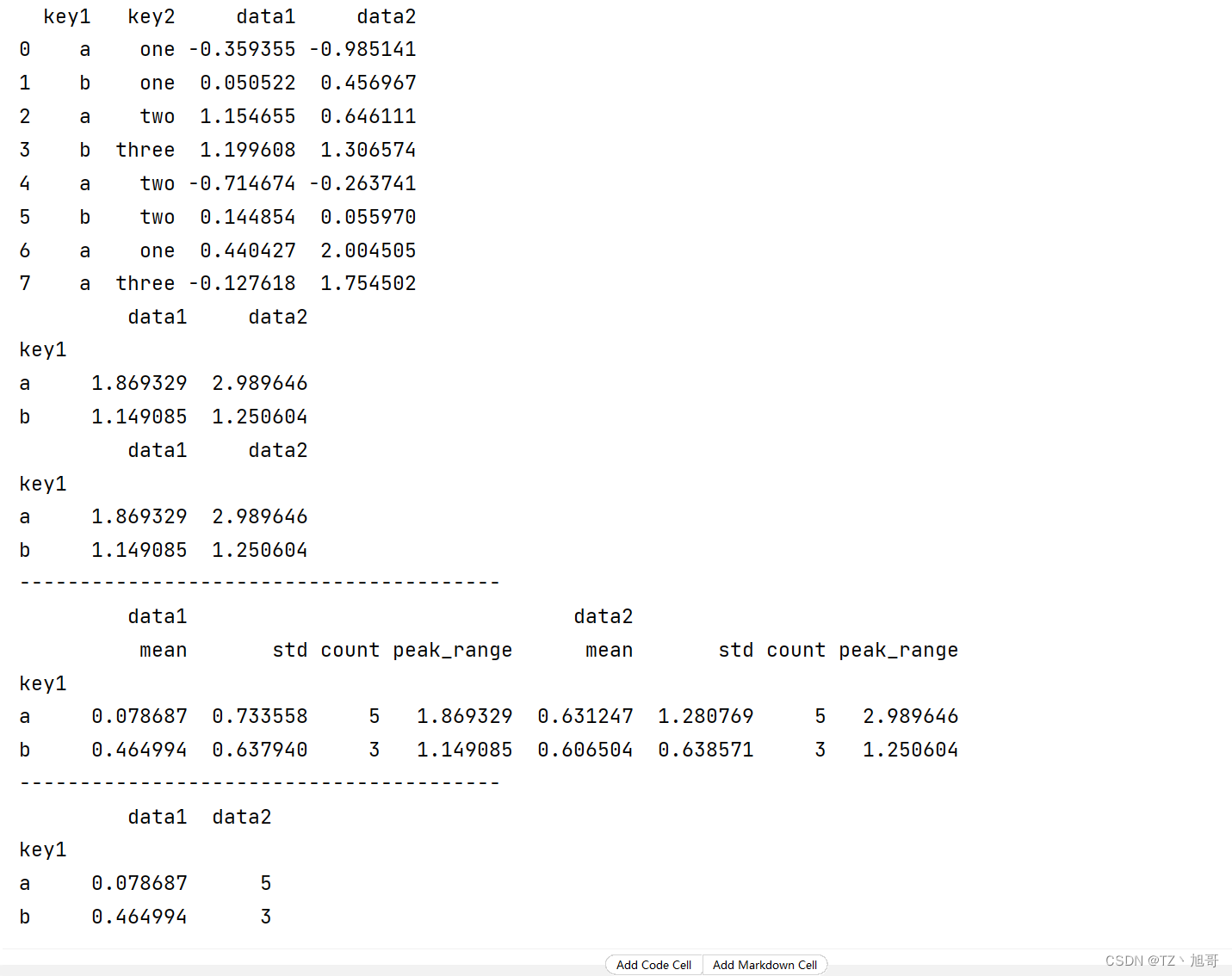
dict_obj = {'key1': ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'key2': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
# 自定义聚合函数
def peak_range(df):
'''
df 参数是 groupby后的groupby对象
:param df:
:return:
'''
return df.max() - df.min()
df_obj2 = df_obj.loc[:, ['key1', 'data1', 'data2']]
print(df_obj2.groupby('key1').agg(peak_range))
print(df_obj2.groupby('key1').agg(lambda df: df.max() - df.min()))
print("--" * 20)
# 同时应用多个聚合函数
print(df_obj2.groupby('key1').agg(['mean', 'std', 'count', peak_range]))
print("--" * 20)
# 每列作用不同的聚合函数
dict_mapping = {
'data1': 'mean',
'data2': 'count'
}
print(df_obj2.groupby('key1').agg(dict_mapping))
时间序列

import numpy as np
import pandas as pd
# 设置索引
# 索引中单项不可以改变,但是整体可以换掉
a = pd.DataFrame({'a': range(7), 'b': range(7, 0, -1),
'c': ['one', 'one', 'two', 'one', 'two', 'two', 'two'],
'd': list("hjklmno")
})
print(a)
c = a.copy()
a.index = list("abcdefg")
print("c的索引没变")
print(c)
print(a) # a的索引变了
print("--" * 20)
b = c.reindex(list('abcdefg')) # 返回一个新的df,b没有值,c的索引不变
print(b)
print("--" * 20)
# 让某些列变为索引
print(a)
print(a.set_index(['c', 'd'])) # a没变,返回修改后的df
print("a没变")
print(a)
print("--" * 20)
# 时间序列 date_range 注意是 date e
pd.date_range(start="20190101", end="20190924")
# periods 长度 B 工作日 M 每月最后一天 W 每周周日
pd.date_range(start="20190101", periods=10, freq="B")
pd.date_range(start="20190819", periods=8, freq="M")
pd.date_range(start="20230819", periods=8, freq="W")

分组和连接
import numpy as np
import pandas as pd
# 分组和连接
dict_obj = {'key1': ['a', 'b', 'a', 'b', 'a', 'b', 'a', 'a'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
print("--" * 20)
# add_prefix 增加前缀
key1_sum = df_obj.groupby('key1').sum().add_prefix('sum_')
print(key1_sum)
print("--" * 20)
# 两个df之间进行连接
# 和mysql的join是一致的 on 连接条件
# 左边以key1为关键词进行连接,右边选True
key1_sum_merge = pd.merge(df_obj, key1_sum, left_on='key1', right_index=True)
print(key1_sum_merge)
print("--" * 20)
# 方法二 使用transform 把分组后的结果放到原处
key1_sum_tf = df_obj.groupby('key1').transform(np.sum).add_prefix('sum_')
print(key1_sum_tf)
print("--" * 20)
# 算自己比平均值高多少 或者少多少
def diff_mean(s):
return s - s.mean()
print(df_obj.groupby('key1').transform(diff_mean))
# 星际争霸
dataset_path = "starcraft.csv"
df_data = pd.read_csv(dataset_path, usecols=['LeagueIndex', 'Age', 'HoursPerWeek', 'TotalHours', 'APM'])
print(df_data)
print("--" * 20)
def top_n(df, n=3, column='APM'):
'''返回每个分组按 column 的 top n 数据'''
return df.sort_values(by=column, ascending=False)[:n]
# apply 可以用自定义函数
print(df_data.groupby('LeagueIndex').apply(top_n))
# group_keys 为 False后,groupby的列不会变为索引
print(df_data.groupby('LeagueIndex', group_keys=False).apply(top_n))
# 可以自己传参
print(df_data.groupby('LeagueIndex').apply(top_n, n=4, column='Age'))
print("---" * 20)
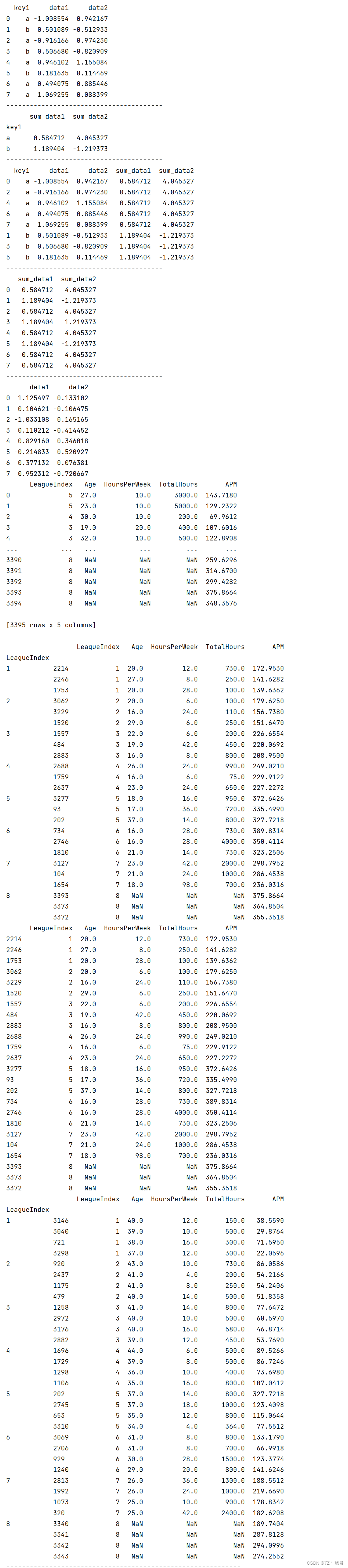
# 连接两个dataframe
df_obj1 = pd.DataFrame({'key': list('bbacaab'),
'data1': np.random.randint(0, 10, 7)})
df_obj2 = pd.DataFrame({'key': list('abd'),
'data2': np.random.randint(0, 10, 3)})
print(df_obj1)
print(df_obj2)
print("--" * 20)
# 1 默认使用相同的列命进行连接,连接方式是内连接
print(pd.merge(df_obj1, df_obj2))
# 2 左表索引和右表索引进行连接 _index 索引连接
print(pd.merge(df_obj1, df_obj2, left_index=True, right_index=True))
# 3 使用相同的列命进行连接,连接方式是内连接 和 1 一样
pd.merge(df_obj1, df_obj2, on='key')
print("--" * 20)
# 4 左右只能出现一次,但是连接方式可以任意
df_obj1 = df_obj1.rename(columns={'key': 'key1'})
df_obj2 = df_obj2.rename(columns={'key': 'key2'})
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2'))
print("--" * 20)
# 全外连接
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='outer'))
print("--" * 20)
# left join 等价于 left outer join 左表为主
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='left'))
print("--" * 20)
# right 等价于 right outer join 右表为主
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='right'))
print("--" * 20)
# 处理重复列命
df_obj3 = pd.DataFrame({'key': list('bbacaab'),
'data': np.random.randint(0, 10, 7)})
df_obj4 = pd.DataFrame({'key': list('abd'),
'data': np.random.randint(0, 10, 3)})
# 给相同的数据列添加后缀 on=列
print(pd.merge(df_obj3, df_obj4, on='key', suffixes=('_left', '_right')))
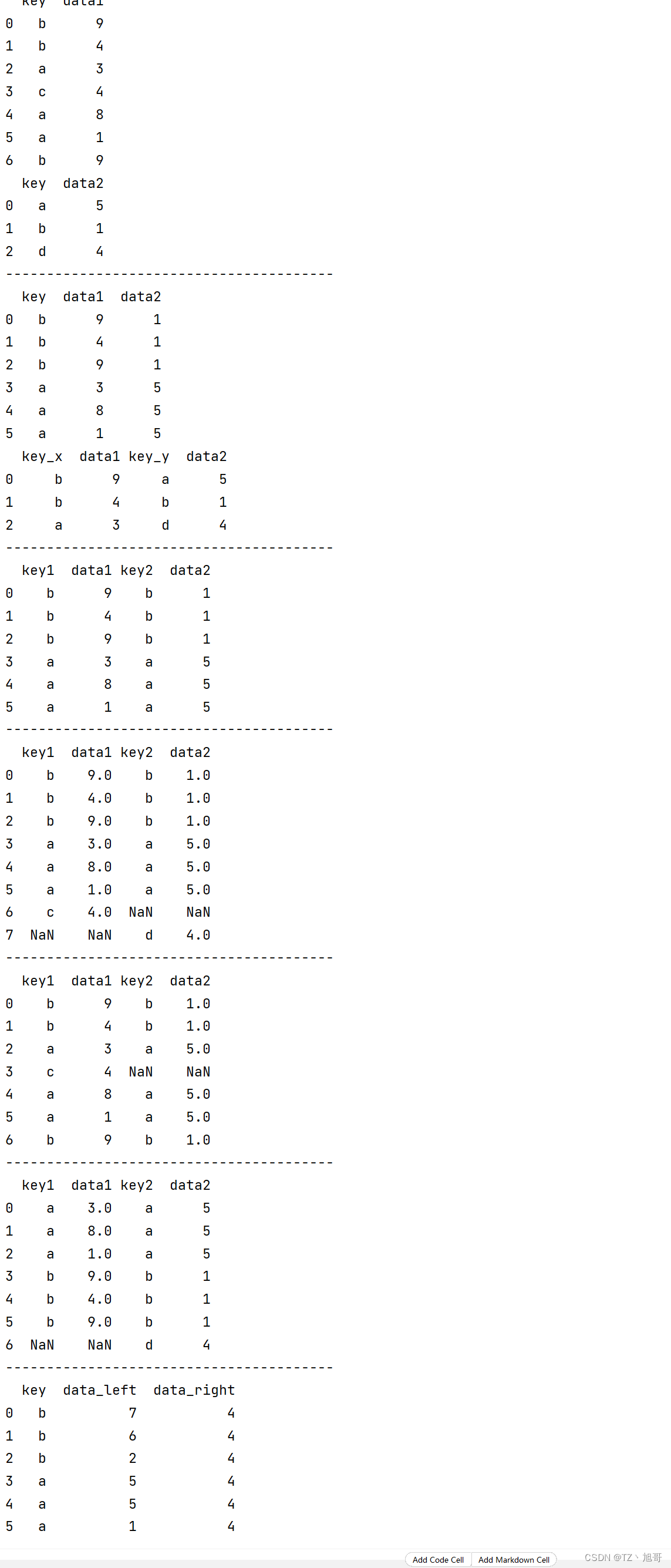
数据合并
import numpy as np
import pandas as pd
# 数据合并
# numpy 里面的合并
arr1 = np.random.randint(0, 10, (3, 4))
arr2 = np.random.randint(0, 10, (3, 4))
print(arr1)
print(arr2)
print("--" * 20)
# 默认按轴0合并
print(np.concatenate([arr1, arr2]))
print(np.concatenate([arr1, arr2], axis=1))
print("--" * 20)
# pandas 合并
# index 没有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0, 5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 5), index=range(5, 10))
ser_obj3 = pd.Series(np.random.randint(0, 10, 5), index=range(10, 15))
print(ser_obj1)
print(ser_obj2)
print(ser_obj3)
print("--" * 20)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
print("---" * 20)
# index 有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0, 5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 5), index=range(3, 8))
ser_obj3 = pd.Series(np.random.randint(0, 10, 5), index=range(6, 11))
print("--" * 20)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
print("--" * 20)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join='inner')) # 内连接 没有nan
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join='outer')) # 全外连接 有 nan
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1)) # 默认外连接 有nan
print("--" * 20)
# 数据重构
df_obj = pd.DataFrame(np.random.randint(0, 10, (5, 2)), columns=['data1', 'data2'])
print(df_obj)
# 对df进行stack,就会变成mutiindex的series
stacked = df_obj.stack() # stack 内部带的参数是 level 选择哪一个 column 变为 index
print(stacked)
print(stacked.unstack()) # 又回去了
print("--" * 20)
print(stacked.unstack(level=0))
print("--" * 20)
# 处理重复数据
df_obj = pd.DataFrame({'data1': ['a'] * 4 + ['b'] * 4, 'data2': np.random.randint(0, 4, 8)})
print(df_obj)
print(df_obj.duplicated()) # 把从上到下重复的变为True
df_obj[~df_obj.duplicated()] # 取出不重复行
# 按某列去重
print(df_obj.duplicated('data2'))
print("--" * 20)
df_obj1 = pd.DataFrame({'data1': [np.nan] * 4,
'data2': list('1234')})
print(df_obj1)
print(df_obj1.duplicated('data1')) # 空值认为相等 实际上 np.nan != np.nan 为True
print(df_obj1.drop_duplicates('data1')) # 去除重复行
print("--" * 20)
# series 替换值
ser_obj = pd.Series(np.arange(10))
print(ser_obj)
# 单个值替换成单个值
print(ser_obj.replace(1, -100))
# 多个值替换成单个值
print(ser_obj.replace(range(6, 9), -100))
# 多个值替换成多个值
print(ser_obj.replace([4, 6], [-100, -200]))
print("--" * 20)
# dataframe 替换值
df = pd.DataFrame({'A': [0, 1, 2, 3],
'B': [4, 5, 6, 7],
'C': list('abcd')})
print(df)
# regex=True 正则表达式 前面用了正则 就需要变为True
print(df.replace(to_replace=r'^a', value=100, regex=True))
print(df.dtypes) # C列变为object类了





![[保研/考研机试] KY212 二叉树遍历 华中科技大学复试上机题 C++实现](https://img-blog.csdnimg.cn/39a1403c94a349c0b5200197e7bf3965.png)