同样适用于recall、F1
分类任务种类
先说一下分类任务分几种,分类任务主要分为二分类、多分类和多标签这三种。
现在假设我们有一个样本,叫s
二分类是最常见的,将s分给A或B这两类。
多分类是将s分给A或B或C或更多的类别。
多标签是有A、B、C等多个标签,s可能是A、也可能是AB,总之s可能会被分给不止一类。
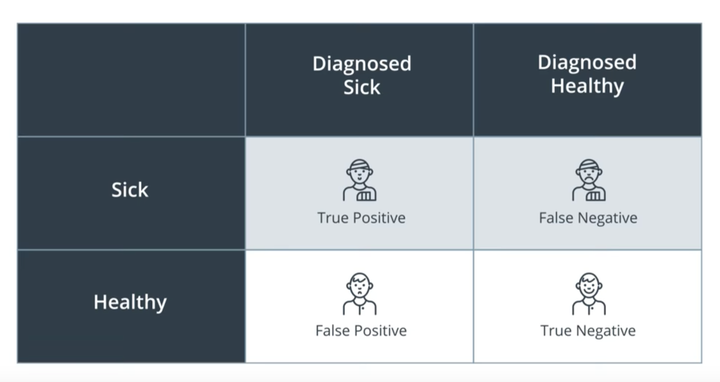
TP、FN、FP、TN
在分类问题中,accuracy往往不是唯一适用的指标,有时我们更关注precision、recall或F1(还有ROC、PR などなど)
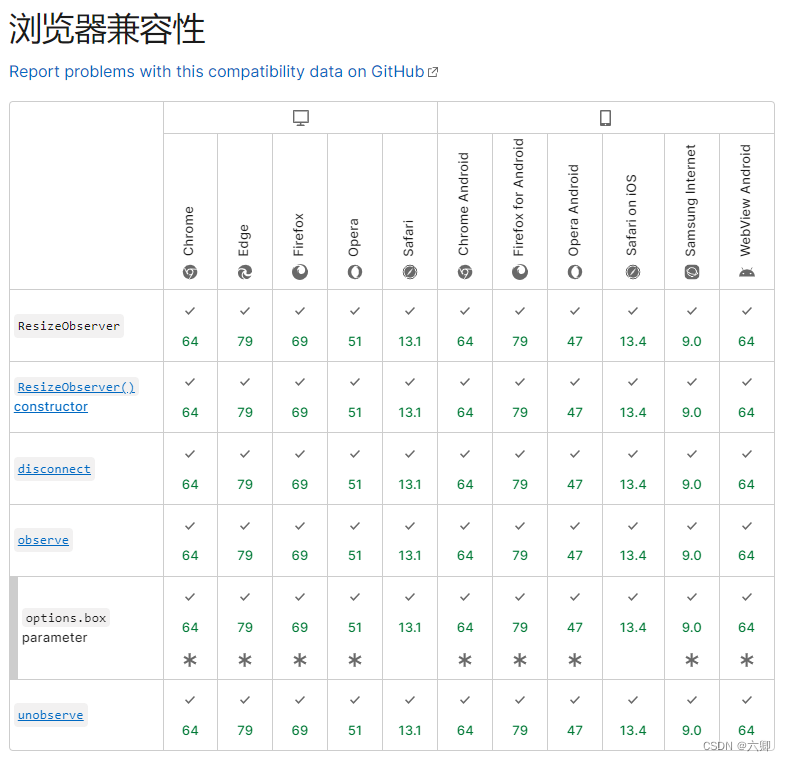
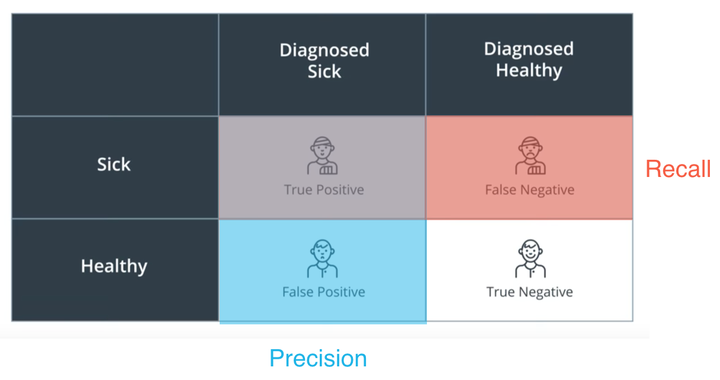
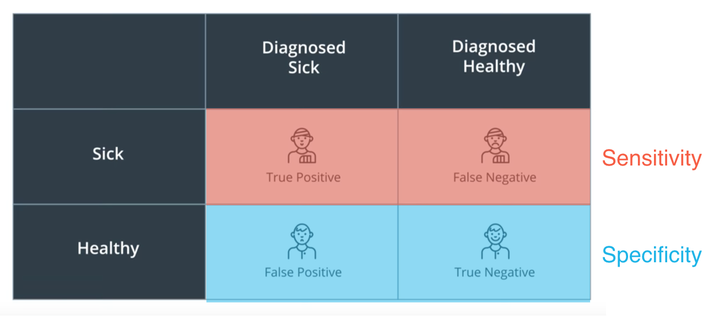
precision、recall、F1都通过TP、FN、FP、TN四个值来计算,直接上图理解四个值的含义
average参数
在sklearn的precision指标中有average参数有六种取值,分别是
‘micro’, ‘macro’, ‘samples’, ‘weighted’, ‘binary’, None(pytorch metrics也差不多,不同的是将binary拆分了出去,None以字符串’none’赋值)
下面依次讲解:
‘binary’:
只适用于二分类任务,也是二分类最常用的。
只报告正例(pos_label)的结果
‘micro’:
先计算出全局TP、FP等的总数,再代入公式进行计算
‘macro’:
计算每个标签的对应指标,在对指标求平均值(由于是求平均,所以对样本不平衡不敏感,这个也是多分类中最常用的)
‘weighted’:
和macro差不多,只不过在求平均时给每个标签按照支持度赋予了权重,这可能会导致F1指标不再precision和recall之间
举个例子:
假如在三分类中,用macro是每个类别的precision乘以1/3。用weighted是乘以该类别在总样本中的占比。(说白了,weighted会更重视占比多的类别)
‘samples’:
只对多标签任务有效
None:
计算出每个类别的precision值,返回一个列表(在多分类中这种方法可以让你查看你重点关注的类别信息)
Custom Weights:
这并不属于average的参数,这是利用None返回的列表乘以自定义的权重后返回一个值。这让模型可以更加关注我们所感兴趣的标签的指标。当然这个权重的设置是一个玄学问题,最好在我们关注的指标在总样本中占比少时使用。(更好的解决办法或许是将你的多分类问题转化为二分类问题,或者利用过采样等方法增加你所感兴趣的标签在样本中的占比。)