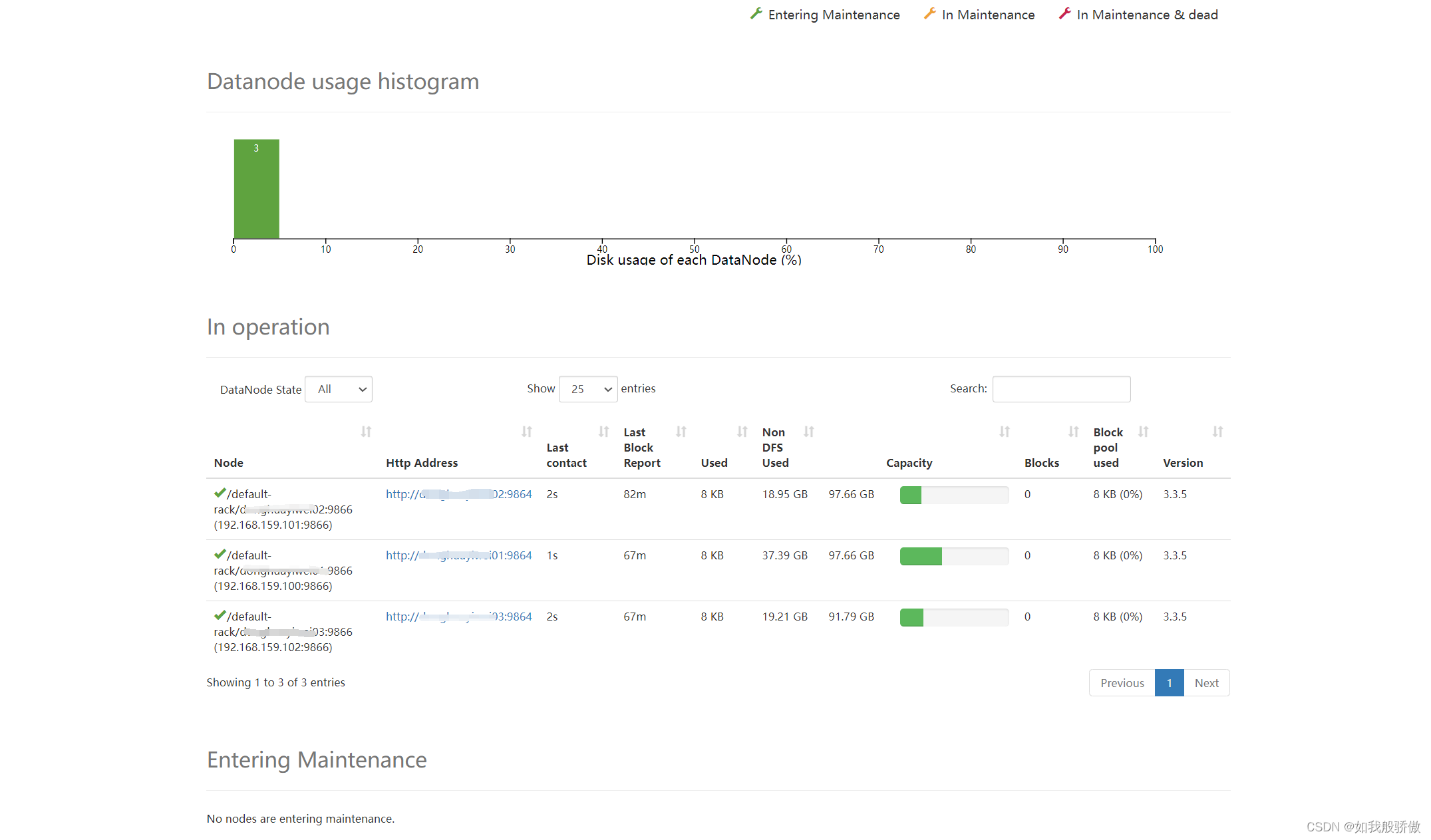
打开网址http://www.luoxu.cc/dmplay/C888H-1-265.html
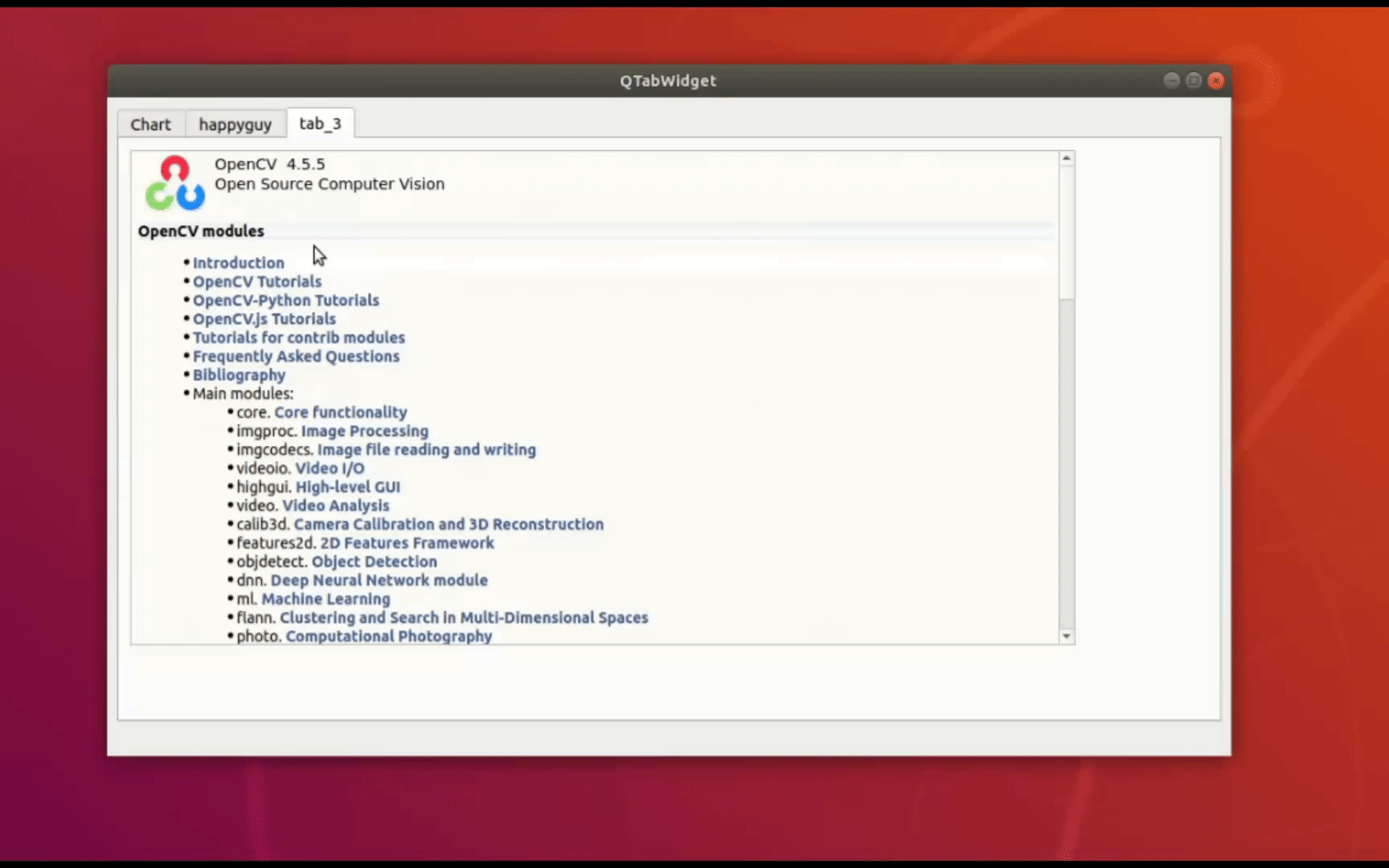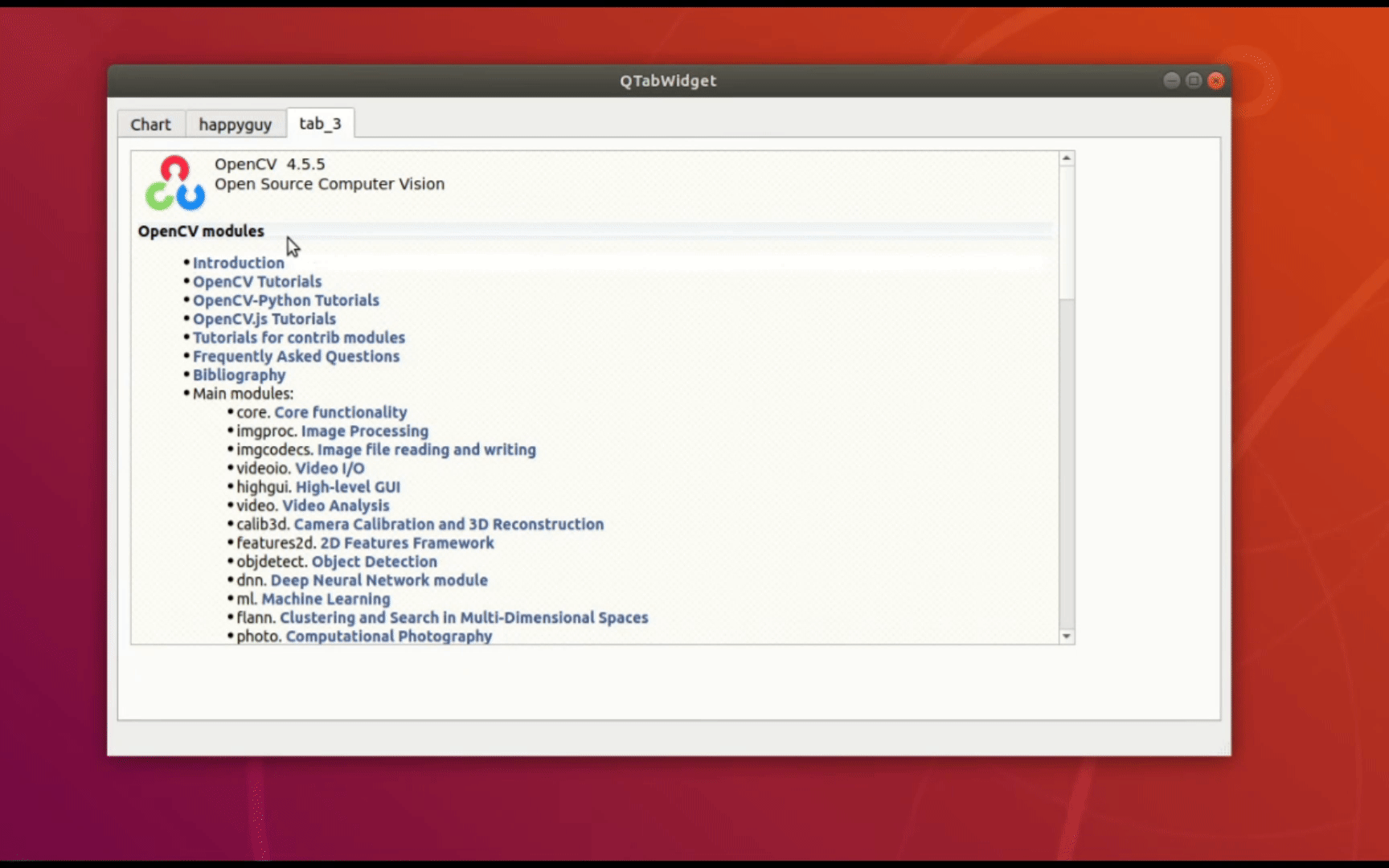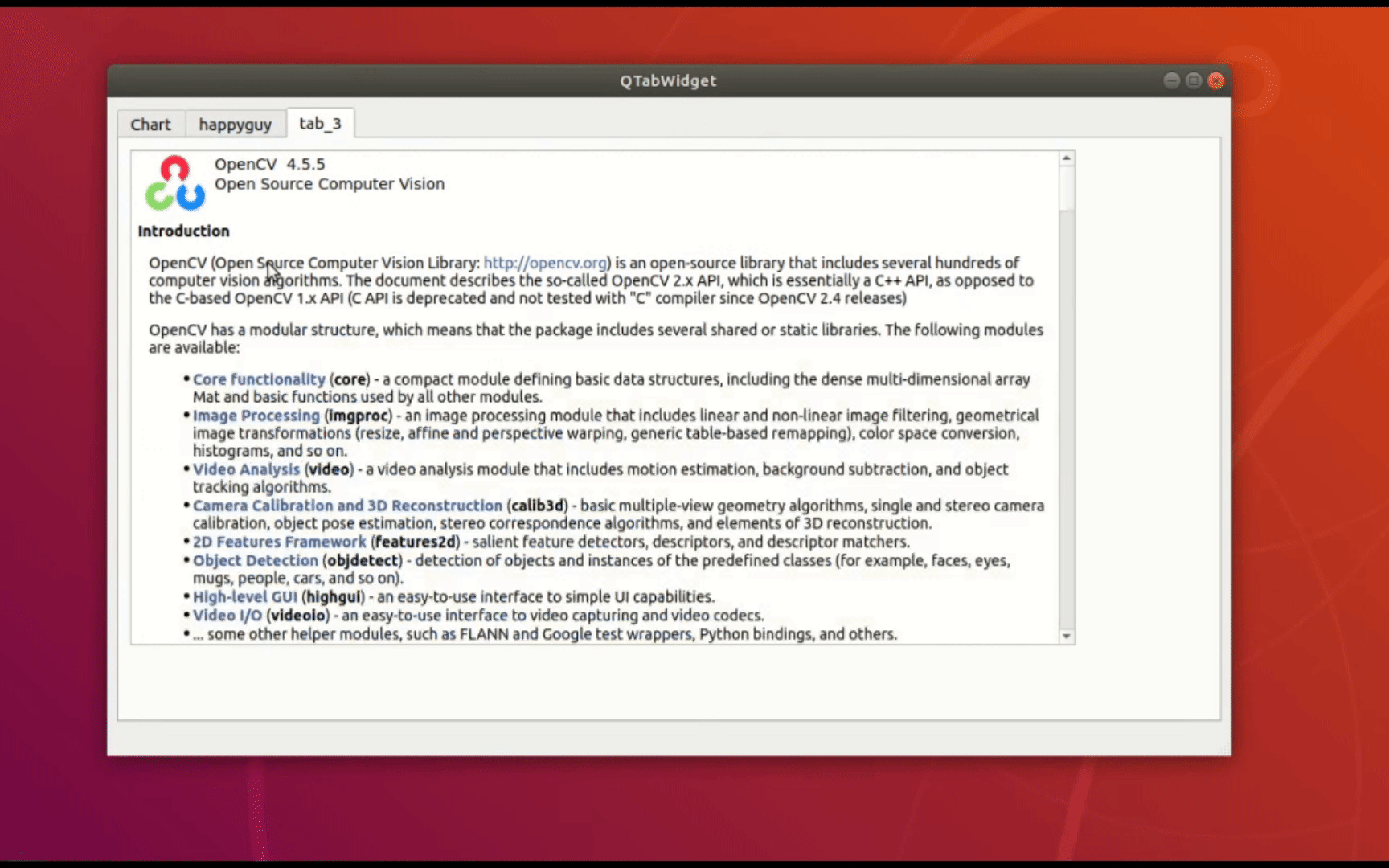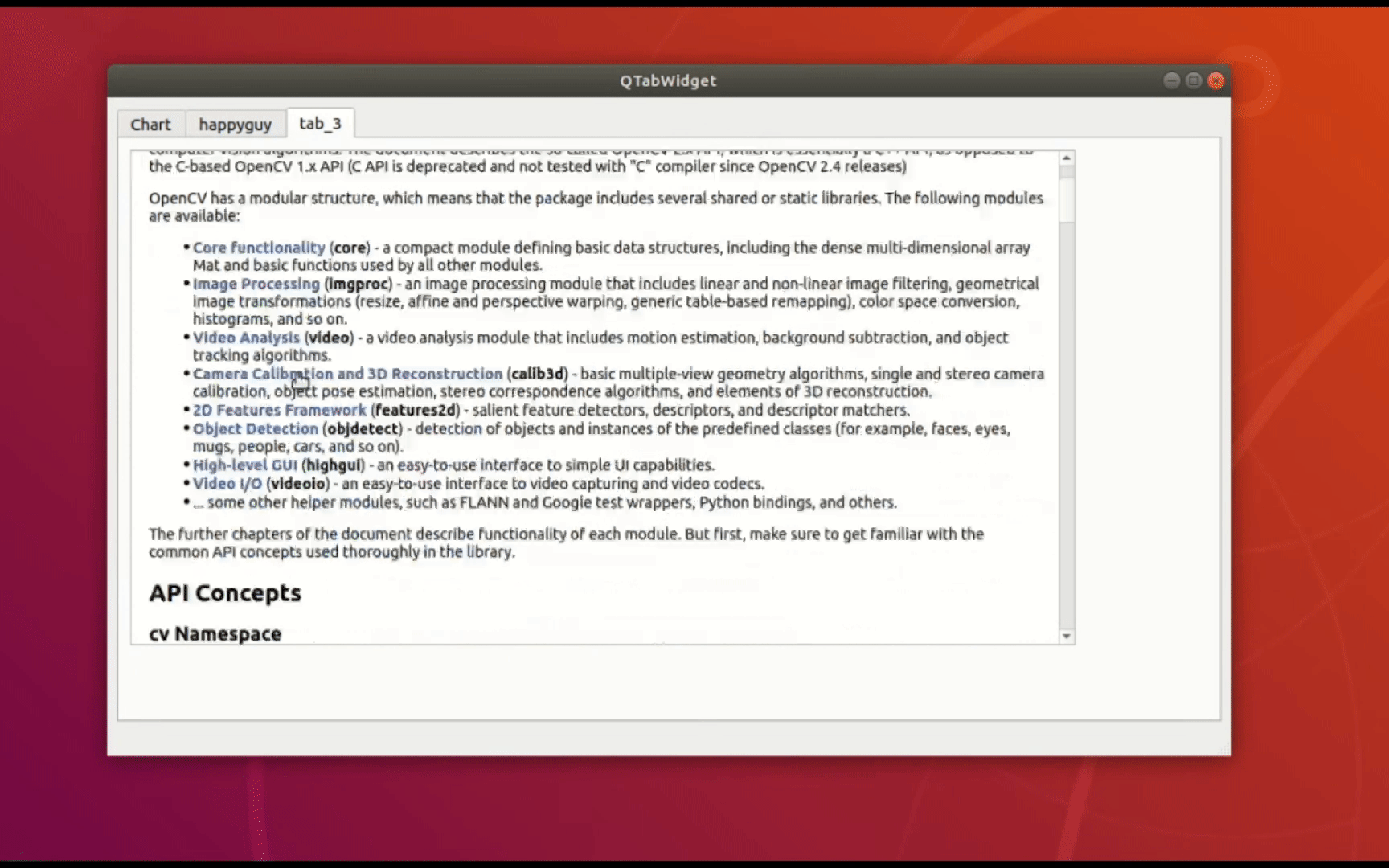
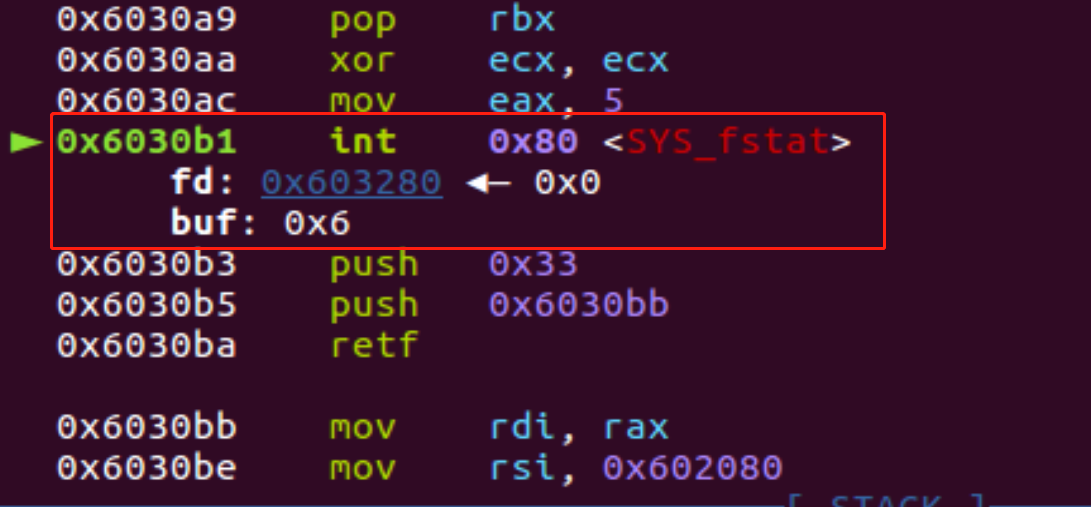
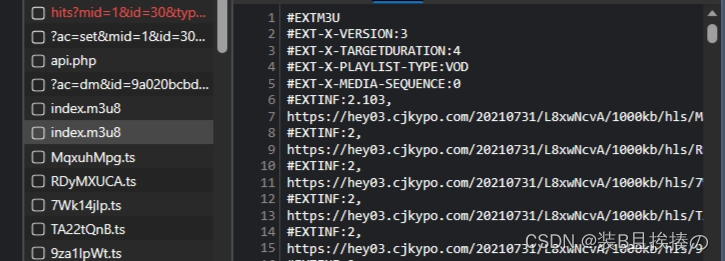
F12打开Fetch/XHR,看到m3u8,ts,一眼顶真,打开index.m3u8
由第一个包含第二个index.m3u8的地址,ctrl+f在源代码中一查index,果然有,不过/前总有个\,这个用replace替换为空
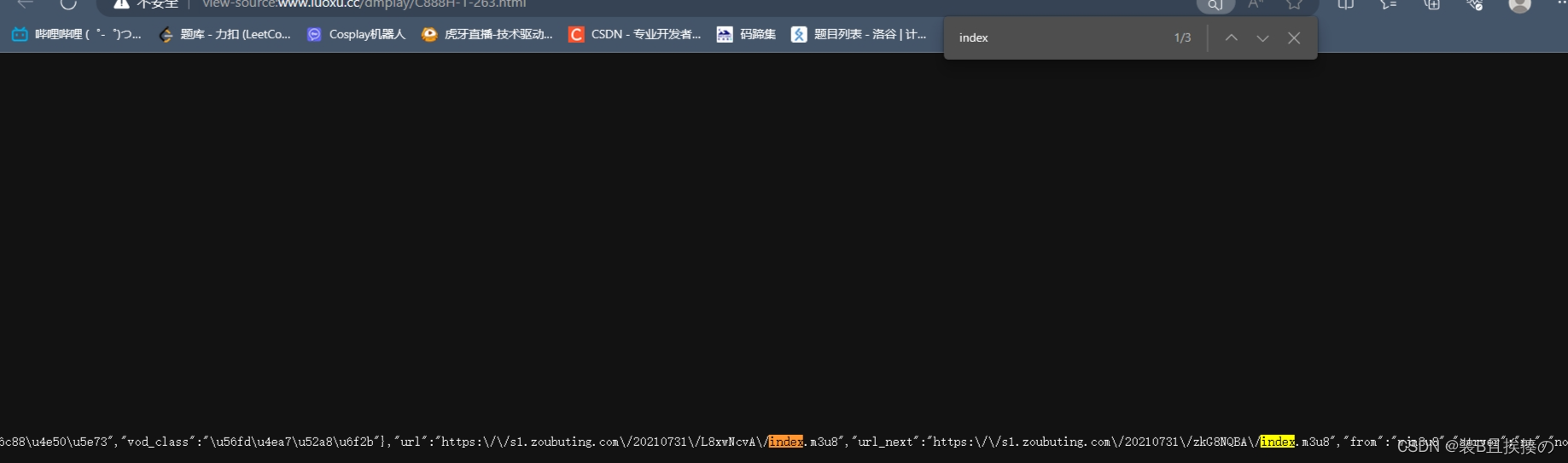
查到第一个index.m3u8,就可以依次找到.ts地址
①爬取原网页,利用re找到第一个index地址
②再利用re找到第二个,然后爬取ts网页内容,添加到mp4文件中
③正则查找要用非贪婪模式,还有记得加上time.sleep()和timeout,以及user-agent要随机取(参考源码),要不然会有connection aborted,被反爬。。
④查看每一集的url的不同点,最后利用线程池一次性爬好几集(这里爬了1-10集),只要你内存够(
源码:
import requests from bs4 import BeautifulSoup import os import re import numpy as np from concurrent.futures import ThreadPoolExecutor import time headers=[ {'user-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}, {'user-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"}, {'user-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) Gecko/20100101 Firefox/61.0"}, {'user-agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"}, {'user-agent':"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36"}, {'user-agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"}, {'user-agent':"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"}, {'user-agent':"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15"}, {'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'} ] def fun(url,index): r=requests.get(url,headers=np.random.choice(headers),timeout=5) index_m3u8=re.findall('https:.*?/index.m3u8',r.text)[0] index_m3u8=index_m3u8.replace("\\",'') r=requests.get(index_m3u8,np.random.choice(headers),timeout=5) index_m3u8=index_m3u8.replace('index.m3u8','') index_m3u8=index_m3u8+re.findall('/(.*)?',r.text)[0].split('/')[-3]+'/hls/index.m3u8' r=requests.get(index_m3u8,np.random.choice(headers),timeout=5) ts=re.findall('https://(.*)\.ts',r.text) with open(f"D:/dl/{index}.mp4",'ab') as f: for node in ts: time.sleep(np.random.randint(1,3)) node='https://'+node+'.ts' r=requests.get(node,np.random.choice(headers),timeout=5) f.write(r.content) print('ok') pool=ThreadPoolExecutor(10) for i in range(1,11): url=f'http://www.luoxu.cc/dmplay/C888H-1-{266-i}.html' pool.submit(fun,url,i)