一、修改服务器配置文件
1、配置环境变量
vim /etc/profile
#java环境变量
export JAVA_HOME=/usr/local/jdk/jdk8
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
#hadoop环境变量
export HADOOP_HOME=/usr/local/hadoop-3.3.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2、修改host映射
这里我准备了三台虚拟机
192.168.159.100
192.168.159.101
192.168.159.102
vim /etc/hosts
# 添加本机的静态IP和本机的主机名之间的映射关系
192.168.159.100 t1
192.168.159.101 t2
192.168.159.102 t2
二、开放端口
#NameNode 内部通信端口
firewall-cmd --zone=public --add-port=8020/tcp --permanent
firewall-cmd --zone=public --add-port=9000/tcp --permanent
firewall-cmd --zone=public --add-port=9820/tcp --permanent
#Secondary NameNode
firewall-cmd --zone=public --add-port=9868/tcp --permanent
#NameNode HTTP UI 端口
firewall-cmd --zone=public --add-port=9870/tcp --permanent
#YARN 查看执行任务端口
firewall-cmd --zone=public --add-port=8088/tcp --permanent
#历史服务器通信端口(jobHistory)
firewall-cmd --zone=public --add-port=10020/tcp --permanent
#历史服务器通信WEB端口(jobHistory.webapp)
firewall-cmd --zone=public --add-port=19888/tcp --permanent
#重新加载防火墙
firewall-cmd --reload
# 查看开放端口
firewall-cmd --list-ports
三、修改HADOOP配置文件
1、core-site.xml
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端口9000 hadoop2.x时代默认端口8020 hadoop3.x时代默认端口 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://t2:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.5/tmp</value>
</property>
</configuration>
2、hdfs-site.xml
<configuration>
<!-- 块的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>t3:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局,需要配置中namenode的服务器上 -->
<property>
<name>dfs.namenode.http-address</name>
<value>t2:9870</value>
</property>
</configuration>
3、hadoop-env.sh
#这里必须配置JAVA_HOME,否则胡报错。
export JAVA_HOME=/usr/local/jdk/jdk8
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
4、works
t1
t2
t3
四、启动集群
1、格式化集群
#每次修改文件之后,都要进行格式化。
hdfs namenode -format
2、启动集群
start-dfs.sh # 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh # 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
# hdfs --daemon start 单独启动一个进程
hdfs --daemon start namenode # 只开启NameNode
hdfs --daemon start secondarynamenode # 只开启SecondaryNameNode
hdfs --daemon start datanode # 只开启DataNode
# hdfs --daemon stop 单独停止一个进程
hdfs --daemon stop namenode # 只停止NameNode
hdfs --daemon stop secondarynamenode # 只停止SecondaryNameNode
hdfs --daemon stop datanode # 只停止DataNode
# hdfs --workers --daemon start 启动所有的指定进程
hdfs --workers --daemon start datanode # 开启所有节点上的DataNode
# hdfs --workers --daemon stop 启动所有的指定进程
hdfs --workers --daemon stop datanode # 停止所有节点上的DataNode
3、进程查看
#查看java进程指令
jps
#t1
3378 DataNode
2082 org.elasticsearch.bootstrap.Elasticsearch
1192 QuorumPeerMain
5756 Jps
1215 QuorumPeerMain
#t2
3872 NameNode
2037 org.elasticsearch.bootstrap.Elasticsearch
4072 DataNode
9791 Jps
#t3
4566 DataNode
1976 org.elasticsearch.bootstrap.Elasticsearch
16520 Jps
4671 SecondaryNameNode
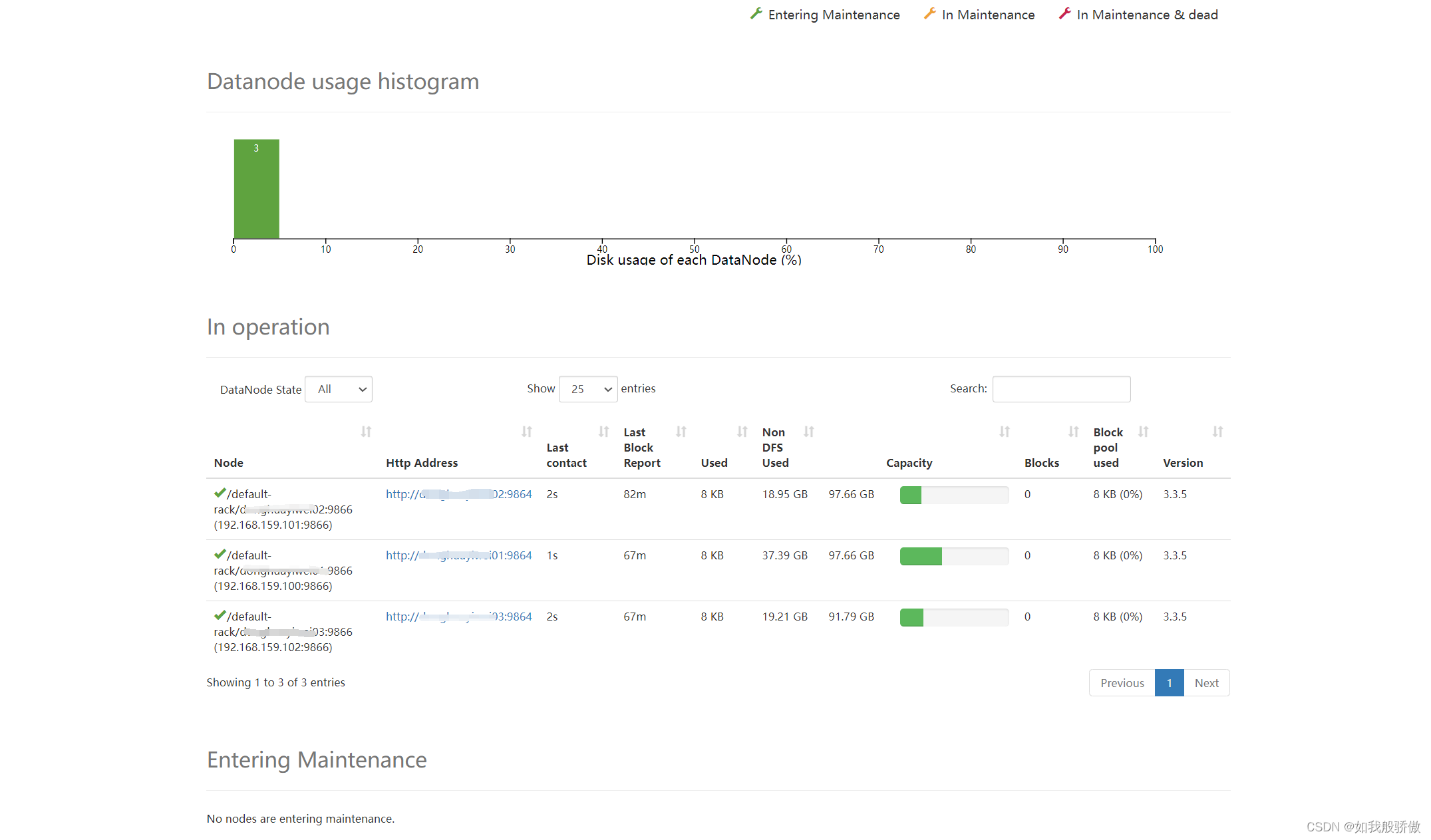
4、浏览器查看
http://192.168.159.101:9870/dfshealth.html#tab-datanode