1.什么是限流
限流是对某一时间窗口内的请求数进行限制,保持系统的可用性和稳定性,防止因流量暴增而导致的系统运行缓慢或宕机。
为什么需要限流
其实限流思想在生活中随处可见,例如景区限流,防止人满为患。热门餐饮需要排队就餐等。回到互联网网络上,同样也是这个道理,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统最多可以支撑200万访问,那么就要执行限流规则,保证系统是一个可用的状态,不至于服务器崩溃导致所有请求不可用。还有12306购票系统,每年的618,双11等场景都需要限流来抗住高并发的瞬时流量,保证系统能正常服务,不被冲垮宕机瘫痪。
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记
交流探讨群:Shepherd_126
2.限流算法
- 计数器算法
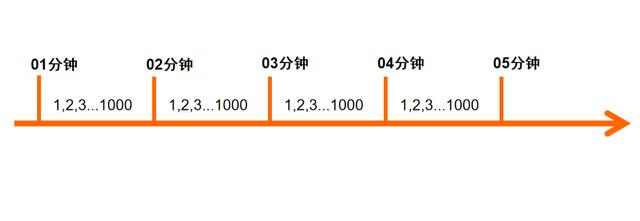
计数器限流算法是最为简单粗暴的解决方案,主要用来限制总并发数,比如数据库连接池大小、线程池大小、接口访问并发数等都是使用计数器算法。一般我们会限制一秒钟能够通过的请求数。比如我们规定,对于A接口来说,我们1分钟的访问次数不能超过1000个。那么我们可以这么做:在一开始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候, counter就加1,如果counter的值大于1000并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多; 如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter。
代码实现如下:
/**
* 固定窗口时间算法
* @return
*/
public class Counter {
public long timeStamp = System.currentTimeMillis(); // 当前时间
public int reqCount = 0; // 初始化计数器
public final int limit = 1000; // 时间窗口内最大请求数
public final long interval = 1000 * 60; // 时间窗口ms
public boolean limit() {
long now = System.currentTimeMillis();
if (now < timeStamp + interval) {
// 在时间窗口内
reqCount++;
// 判断当前时间窗口内是否超过最大请求控制数
return reqCount <= limit;
} else {
timeStamp = now;
// 超时后重置
reqCount = 1;
return true;
}
}
}
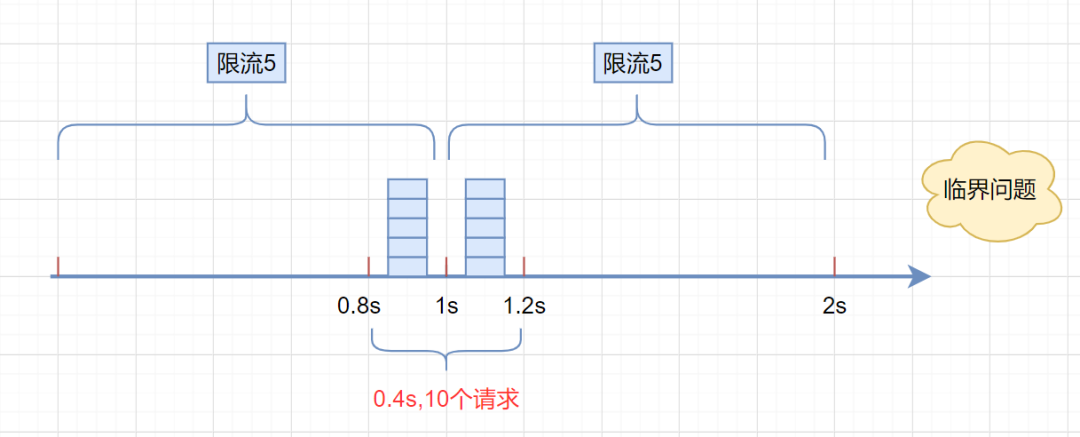
但是,这种上面的固定时间窗口算法有一个很明显的临界问题:假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义啦。
滑动窗口限流算法
滑动窗口限流解决固定窗口临界值的问题。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。如下图所示:展示了滑动窗口算法对时间区间的划分
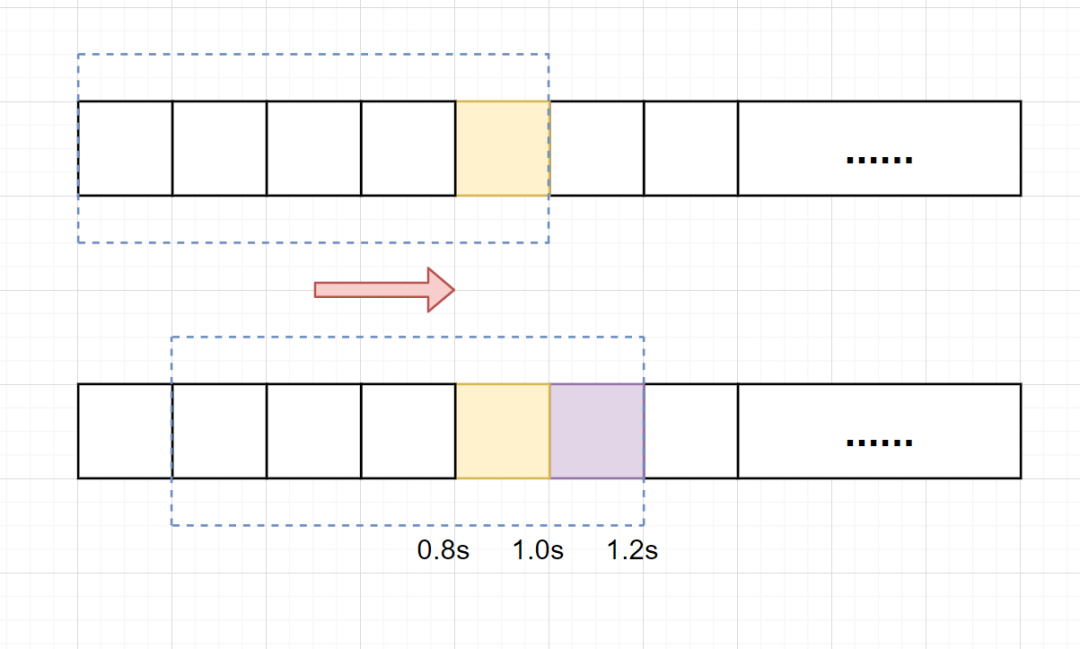
假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。
假设我们1s内的限流阀值还是5个请求,0.81.0s内(比如0.9s的时候)来了5个请求,落在黄色格子里。时间过了1.0s这个点之后,又来5个请求,落在紫色格子里。如果**是固定窗口算法,是不会被限流的**,但是**滑动窗口的话,每过一个小周期,它会右移一个小格**。过了1.0s这个点后,会右移一小格,当前的单位时间段是0.21.2s,这个区域的请求已经超过限定的5了,已触发限流啦,实际上,紫色格子的请求都被拒绝啦。
TIPS: 当滑动窗口的格子周期划分的越多,那么滑动窗口的滚动就越平滑,限流的统计就会越精确。
/**
* 单位时间划分的小周期(单位时间是1分钟,10s一个小格子窗口,一共6个格子)
*/
private int SUB_CYCLE = 10;
/**
* 每分钟限流请求数
*/
private int thresholdPerMin = 100;
/**
* 计数器, k-为当前窗口的开始时间值秒,value为当前窗口的计数
*/
private final TreeMap<Long, Integer> counters = new TreeMap<>();
/**
* 滑动窗口时间算法实现
*/
boolean slidingWindowsTryAcquire() {
long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE; //获取当前时间在哪个小周期窗口
int currentWindowNum = countCurrentWindow(currentWindowTime); //当前窗口总请求数
//超过阀值限流
if (currentWindowNum >= thresholdPerMin) {
return false;
}
//计数器+1
counters.get(currentWindowTime)++;
return true;
}
/**
* 统计当前窗口的请求数
*/
private int countCurrentWindow(long currentWindowTime) {
//计算窗口开始位置
long startTime = currentWindowTime - SUB_CYCLE* (60s/SUB_CYCLE-1);
int count = 0;
//遍历存储的计数器
Iterator<Map.Entry<Long, Integer>> iterator = counters.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Long, Integer> entry = iterator.next();
// 删除无效过期的子窗口计数器
if (entry.getKey() < startTime) {
iterator.remove();
} else {
//累加当前窗口的所有计数器之和
count =count + entry.getValue();
}
}
return count;
}
滑动窗口算法虽然解决了固定窗口的临界问题,但是一旦到达限流后,请求都会直接暴力被拒绝
- 漏桶算法
漏桶算法思路很简单,我们把水比作是请求,漏桶比作是系统处理能力极限,水先进入到漏桶里,漏桶里的水按一定速率流出,当流出的速率小于流入的速率时,由于漏桶容量有限,后续进入的水直接溢出(拒绝请求),以此实现限流。

- 令牌桶算法
令牌桶算法则是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。桶中存放的令牌数有最大上限,超出之后就被丢弃或者拒绝。当流量或者网络请求到达时,每个请求都要获取一个令牌,如果能够获取到,则直接处理,并且令牌桶删除一个令牌。如果获取不同,该请求就要被限流,要么直接丢弃,要么在缓冲区等待。

令牌桶和漏桶算法区别:
1)令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
2)令牌桶限制的是平均流入速率,允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌;漏桶限制的是常量流出速率,即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2,从而平滑突发流入速率;
3)令牌桶允许一定程度的突发,而漏桶主要目的是平滑流出速率;
3.guava实现限流
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法实现流量限制,使用十分方便,而且十分高效。RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)。
依赖包
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
使用示例
/**
* @author fjzheng
* @version 1.0
* @date 2021/9/1 10:38
*/
@Slf4j
@RestController
@RequestMapping("/test")
@ResponseResultBody
public class TestController {
/**
* 限流策略 :1秒钟2个请求
*/
private final RateLimiter limiter = RateLimiter.create(2.0);
private DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@GetMapping("/rateLimit")
public String testLimiter() {
//500毫秒内,没拿到令牌,就直接进入服务降级
boolean tryAcquire = limiter.tryAcquire(50, TimeUnit.MILLISECONDS);
if (!tryAcquire) {
log.warn("进入服务降级,时间{}", LocalDateTime.now().format(dtf));
return "当前排队人数较多,请稍后再试!";
}
log.info("获取令牌成功,时间{}", LocalDateTime.now().format(dtf));
return "请求成功";
}
}
以上用到了RateLimiter的2个核心方法:create()、tryAcquire(),以下为详细说明
- acquire() 获取一个令牌, 该方法会阻塞直到获取到这一个令牌, 返回值为获取到这个令牌花费的时间
- acquire(int permits) 获取指定数量的令牌, 该方法也会阻塞, 返回值为获取到这 permits 个令牌花费的时间
- tryAcquire() 判断时候能获取到令牌, 如果不能获取立即返回 false
- tryAcquire(int permits) 获取指定数量的令牌, 如果不能获取立即返回 false
- tryAcquire(long timeout, TimeUnit unit) 判断能否在指定时间内获取到令牌, 如果不能获取立即返回 false
- tryAcquire(int permits, long timeout, TimeUnit unit) 判断能否在指定时间内获取到permits个令牌,如果不能则返回false。
这时候调用上面的测试接口,一秒钟只能通过2个接口,同时每隔0.5s产生一个令牌,调用过于频繁贼会被限制。但是上面的使用方式不够优雅,因为我们需要在每个需要限流的接口重复使用tryAcquire()方法,然后根据是否获取到令牌做逻辑判断
优雅使用
所谓优雅就是统一处理,使用aop实现一个拦截器即可,如下所示:
首先我们的创建一个注解,该注解可以配置限流信息
/**
* @author fjzheng
* @version 1.0
* @date 2021/10/25 00:06
*/
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
@Documented
public @interface RateLimit {
/**
* 资源的key,唯一
* 作用:不同的接口,不同的流量控制
*/
String key() default "";
/**
* 最多的访问限制次数
*/
double permitsPerSecond () ;
/**
* 获取令牌最大等待时间
*/
long timeout();
/**
* 获取令牌最大等待时间,单位(例:分钟/秒/毫秒) 默认:毫秒
*/
TimeUnit timeunit() default TimeUnit.MILLISECONDS;
/**
* 得不到令牌的提示语
*/
String msg() default "系统繁忙,请稍后再试.";
}
然后使用aop拦截带有RateLimit注解的方法,进行统一处理即可。
/**
* @author fjzheng
* @version 1.0
* @date 2021/10/25 00:10
*/
@Slf4j
@Component
@Aspect
public class RateLimitAop {
/**
* 不同的接口,不同的流量控制
* map的key为 Limiter.key
*/
private final Map<String, RateLimiter> limitMap = Maps.newConcurrentMap();
@Around("@annotation(com.shepherd.mall.seckill.annotation.RateLimit)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable{
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
//拿limit的注解
RateLimit limit = method.getAnnotation(RateLimit.class);
if (limit != null) {
//key作用:不同的接口,不同的流量控制
String key=limit.key();
RateLimiter rateLimiter = null;
//验证缓存是否有命中key
if (!limitMap.containsKey(key)) {
// 创建令牌桶
rateLimiter = RateLimiter.create(limit.permitsPerSecond());
limitMap.put(key, rateLimiter);
log.info("新建了令牌桶={},容量={}",key,limit.permitsPerSecond());
}
rateLimiter = limitMap.get(key);
// 拿令牌
boolean acquire = rateLimiter.tryAcquire(limit.timeout(), limit.timeunit());
// 拿不到命令,直接返回异常提示
if (!acquire) {
log.debug("令牌桶={},获取令牌失败",key);
this.responseFail(limit.msg());
return null;
}
}
return joinPoint.proceed();
}
/**
* 直接向前端抛出异常
* @param msg 提示信息
*/
private void responseFail(String msg) {
HttpServletResponse response=((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getResponse();
ResponseVO<Object> responseVO = ResponseVO.failure(400, msg);
WebUtil.writeJson(response, responseVO);
}
}
优雅使用示例
/**
* @author fjzheng
* @version 1.0
* @date 2021/9/1 10:38
*/
@Slf4j
@RestController
@RequestMapping("/test")
@ResponseResultBody
public class TestController {
@GetMapping("/limit2")
@RateLimit(key = "limit2", permitsPerSecond = 1, timeout = 50, timeunit = TimeUnit.MILLISECONDS, msg = "当前排队人数较多,请稍后再试!")
public String limit2() {
log.info("令牌桶limit2获取令牌成功");
return "ok";
}
}
其测试结果和上面的示例是差不多的。
guava的rateLimit限流只能使用与单机版,如果是分布式系统,部署多个节点就不行了
4.分布式限流
分布式限流服务最关键是将限流服务做成原子化的,防止redis在分步执行命令时部分成功执行部分失败问题导致逻辑错误。lua脚本可以保证操作的原子性
redis+lua实现
local key = "rate.limit:" .. KEYS[1]
local limit = tonumber(ARGV[1])
local expire_time = ARGV[2]
local is_exists = redis.call("EXISTS", key)
if is_exists == 1 then
if redis.call("INCR", key) > limit then
return 0
else
return 1
end
else
redis.call("SET", key, 1)
redis.call("EXPIRE", key, expire_time)
return 1
end
nginx+lua实现
local locks = require "resty.lock"
local function acquire()
local lock =locks:new("locks")
local elapsed, err =lock:lock("limit_key") --互斥锁 保证原子特性
local limit_counter =ngx.shared.limit_counter --计数器
local key = "ip:" ..os.time()
local limit = 5 --限流大小
local current =limit_counter:get(key)
if current ~= nil and current + 1> limit then --如果超出限流大小
lock:unlock()
return 0
end
if current == nil then
limit_counter:set(key, 1, 1) --第一次需要设置过期时间,设置key的值为1,
--过期时间为1秒
else
limit_counter:incr(key, 1) --第二次开始加1即可
end
lock:unlock()
return 1
end
ngx.print(acquire())
对于Nginx接入层限流可以使用Nginx自带了两个模块:连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。
控制并发数:ngx_http_limit_conn_module
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流设置
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
#根据IP地址来限制,存储内存大小10M
limit_conn_zone $binary_remote_addr zone=addr:1m;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location /brand {
limit_conn addr 2;
proxy_pass http://192.168.211.1:18081;
}
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4 nodelay;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
limit_conn_zone $binary_remote_addr zone=addr:10m; 表示限制根据用户的IP地址来显示,设置存储地址为的内存大小10M
limit_conn addr 2; 表示 同一个地址只允许连接2次。
控制速率:ngx_http_limit_req_module
user root root;
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#cache
lua_shared_dict dis_cache 128m;
#限流设置
limit_req_zone $binary_remote_addr zone=contentRateLimit:10m rate=2r/s;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
location /update_content {
content_by_lua_file /root/lua/update_content.lua;
}
location /read_content {
limit_req zone=contentRateLimit burst=4 nodelay;
content_by_lua_file /root/lua/read_content.lua;
}
}
}
burst 译为突发、爆发,表示在超过设定的处理速率后能额外处理的请求数,当 rate=10r/s 时,将1s拆成10份,即每100ms可处理1个请求。
此处,**burst=4 **,若同时有4个请求到达,Nginx 会处理第一个请求,剩余3个请求将放入队列,然后每隔500ms从队列中获取一个请求进行处理。若请求数大于4,将拒绝处理多余的请求,直接返回503.
不过,单独使用 burst 参数并不实用。假设 burst=50 ,rate依然为10r/s,排队中的50个请求虽然每100ms会处理一个,但第50个请求却需要等待 50 * 100ms即 5s,这么长的处理时间自然难以接受。
因此,burst 往往结合 nodelay 一起使用。