目录
一、Vulkan开发理论基础知识
接口设计理念 Host&Device
基础设施——元数据和设备
基础设施——交换链
编辑交换链 SwapChain编辑
渲染管线 Pipeline
RenderPass
CommandBuffer
二、Vulkan DescriptorSet
创建DescriptorPool
运行时绑定DescriptorSet
三、SPIR-V
Shader管线
SPIR-V
一、Vulkan开发理论基础知识
接口设计理念 Host&Device
客户端 + 服务端 / 逻辑段 + 渲染端 / CPU + GPU
Host:一切由CPU与内存为基础进行的操作,例如模型的读取,鼠标键盘的事件响应,游戏引擎碰撞的逻辑,定时器等等。
Device:一切由GPU与显存为基础的图形渲染、后处理等操作
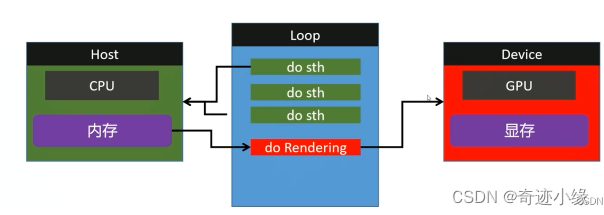
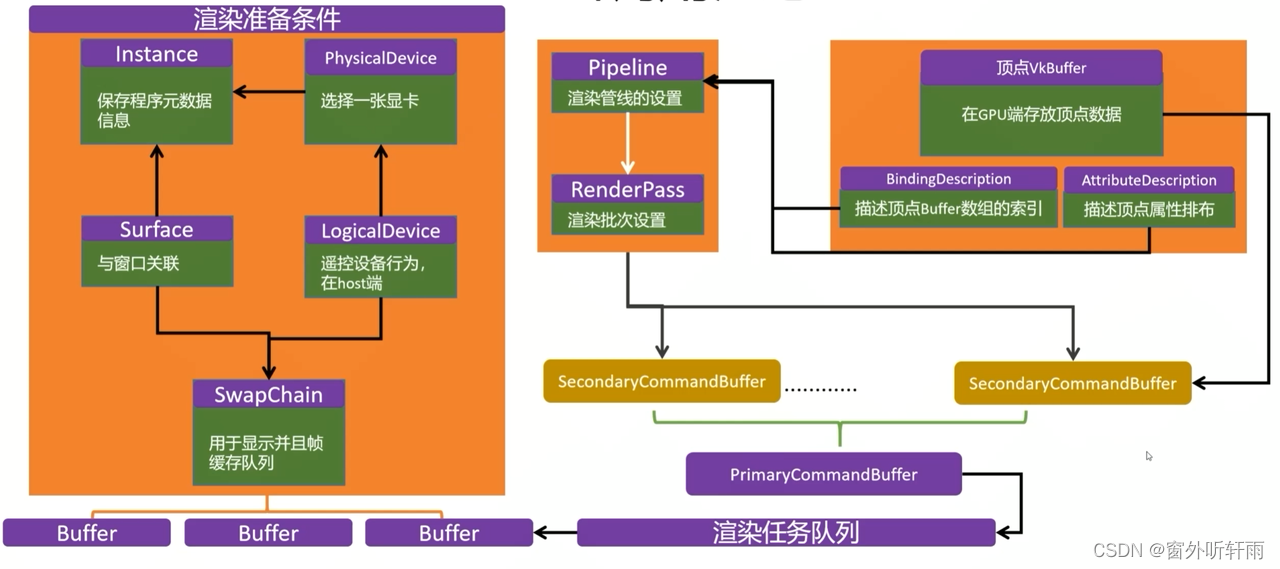
基础设施——元数据和设备
- Instance:渲染程序的元数据,存有Vulkan版本号,引擎版本号,是否启用Debug,启动哪些拓展等基础数据。
- Surface:用来链接操作系统相关的窗口与Vulkan渲染出来的图像组件。GPU渲染完一帧将结果存入到显存中,想要显示到窗口中就需要Surface起到链接的作用,将渲染出来的图形组件放入窗口中。
- PhysicalDevice:物理设备显卡,多显卡时可以根据特性挑选一张进行渲染
- LogicalDevice:逻辑设备显卡,由逻辑设备在Host端远程发送句柄操控Device端的物理设备

基础设施——交换链
水平消隐和垂直消隐
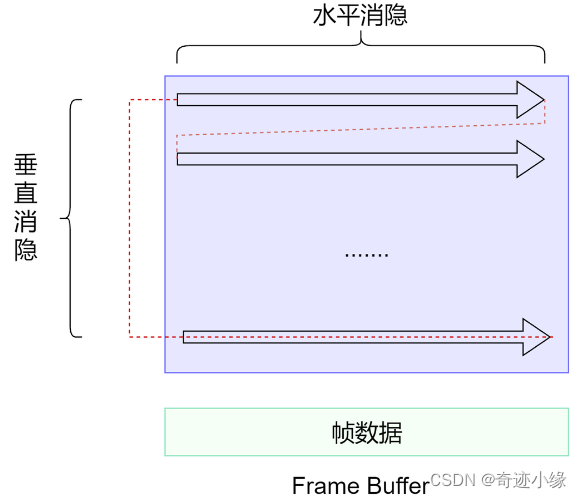
显示设备一般是从帧数据中读取显示的内容(RGB,纹理坐标…),然后一行一行的填充每个像素刷新屏幕
水平消隐:扫描完毕一行,回到下一行开头的时间
垂直消隐:一页扫描显示完毕,回到左上角的时间
存在的问题:
- 如果在垂直消隐来临之前就更新了Buffer中的数据,屏幕就会产生撕裂和花屏现象。在垂直消隐来临前,屏幕还没有完全刷新完,当改变Buffer时就会造成屏幕已经刷新的部分是上一帧的画面,即将刷新的是下一帧的画面,造成撕裂现象。
- 如果将Buffer的更新阻塞,直到垂直消隐来临才进行更新,那么 一帧的时间 = 刷新屏幕的时间 + 更新渲染Buffer的时间,速度会受到十分严重的影响。
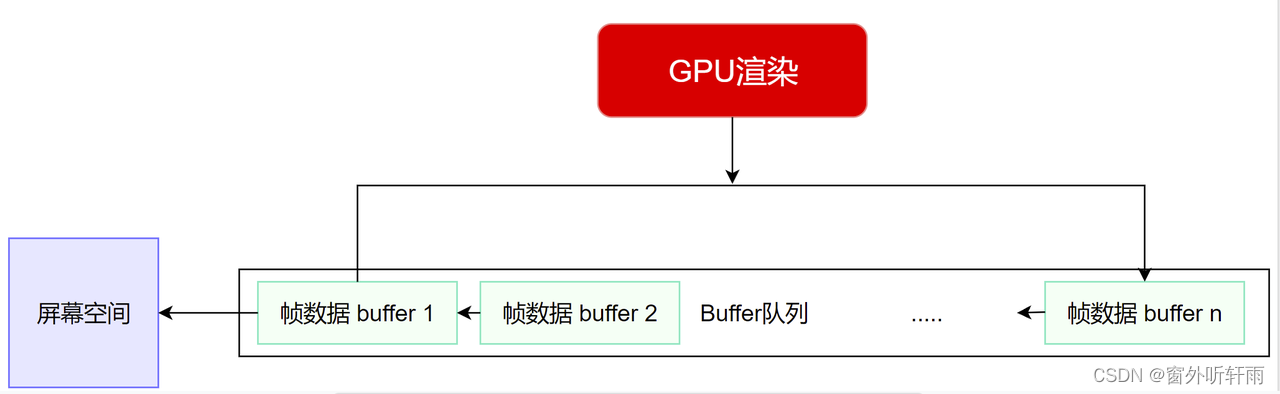
解决方案——双Buffer缓存:
Buffer1:用于和屏幕空间交互,被读取显示到屏幕上
Buffer2:缓存GPU的渲染数据
当屏幕空间进入垂直消隐期间,就可以交换两个缓冲区,从而实现无缝对接与并行工作
此时 一帧的时间 = 刷新屏幕的时间,省去了等待更新渲染Buffer的时间
这个过程就是由交换链(SwapChain)进行管理的

交换链 SwapChain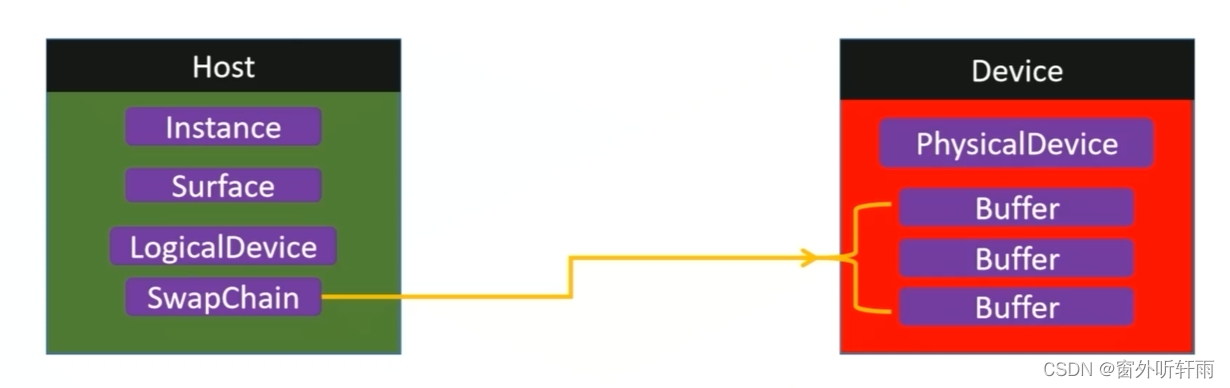
交换链管理着显存当中的N个渲染Buffer,它们组成Buffer队列交替使用
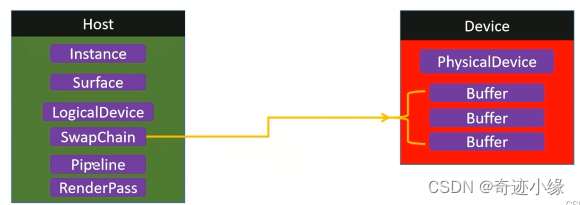
渲染管线 Pipeline
Unity的渲染管线流程大致如下图

- 渲染管线在Vulkan中属于一个对象,代表了从顶点一直到屏幕上生成像素的整个处理过程。
- Pipeline对象的每个阶段都提供了很多参数可以进行设置,以产生多种多样的渲染效果。
RenderPass
RenderPass定义为一个渲染步骤,其不关心具体渲染的细节,只定义了渲染的大方向,定义渲染完毕的东西的去处,也就是渲染目标Render Targets
- 功能:指定渲染目标,指定批次,指定依赖等
- 在开启延迟渲染时,会将第一帧的结果暂存在缓冲区并作为下一帧的输入,第二帧的结果才真正显示到屏幕上,两个批次渲染一帧。
- RenderPass在Vulkan中也是一个对象。
Vertex的描述方法

- VkBuffer:GPU端开辟的一块显存,用于存放顶点数据
- BindingDescription:描述VkBuffer数组的索引
- VkBuffer可能不唯一,例如顶点可以将position存入到一个buffer中,color存到另一个buffer中,多个buffer以数组的形式传入管线,需要对每个buffer编号。
- AttributeDescription:描述顶点数据结构内的属性排布
- 对于单个顶点内部可能有多个属性,如图中就有position和color,需要编号进行指示。
Index缓冲–顶点索引
- 顶点索引:存储着构成三角形的点的索引,每三个索引对应的点构成一个三角形。
- 索引VkBuffer: 顶点索引也会存进一个VkBuffer,即索引VkBuffer,在需要获取时,需要根据每个元素的大小进行分割,即根据顶点的类型得知一块元素的大小(uint16等)
CommandBuffer
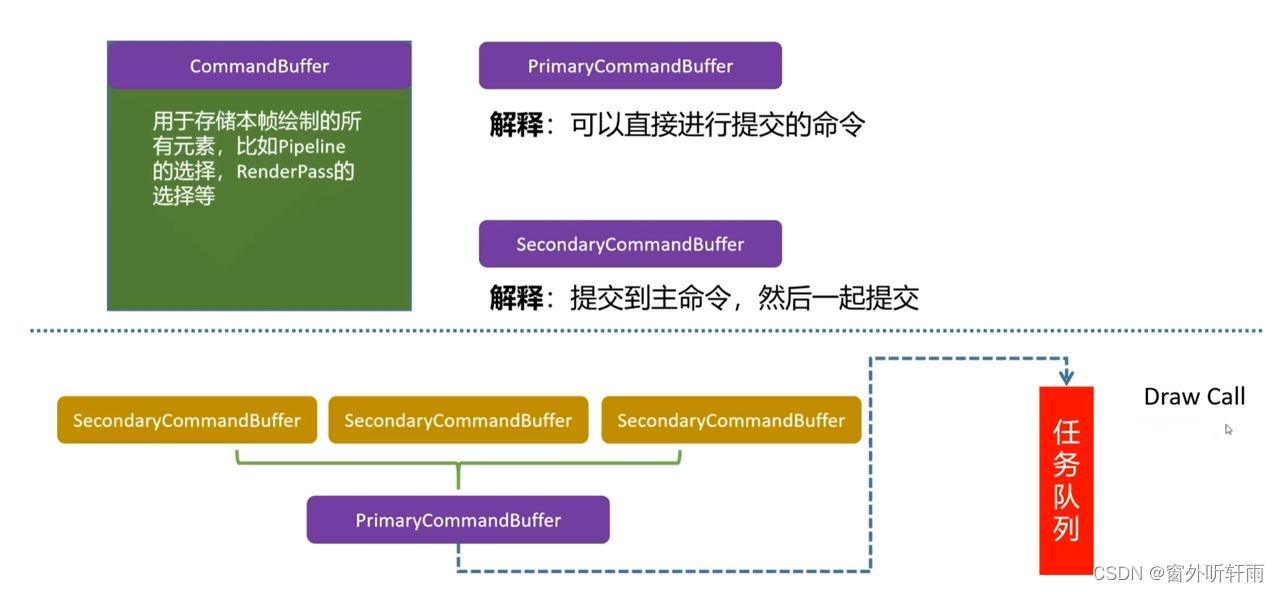
CommandBuffer:存储本帧需要绘制的所有命令
- 一般每个需要绘制的物体的命令都会先绘制到一个SecondaryCommandBuffer中,再统一绘制到PrimaryCommandBuffer中进而提交到任务队列,这个过程就是DrawCall。
- 拆分成多个Secondary有利于进行多线程工作,提高效率。
参考:一、Vulkan开发理论基础知识_vulkan 开发_窗外听轩雨的博客-CSDN博客
二、Vulkan DescriptorSet
- Descriptor
- Descriptor Set
- Descriptor Set Layout
- Descriptor Pool
- Pipeline Layout
- Set and Binding in Shader
Descriptor是一个不透明的数据结构,代表一个着色器资源,如Buffer、Buffer View、Imgae、Sampler、Combined Image Sampler。Descriptor不是无意义的概念,Vulkan将通过Descriptor告诉GPU这些资源在哪里,以及着色器该如何访问这些资源。其实也就是认为Descriptor为一个句柄(Handle)或者一个指向资源的指针。
Descriptor会被组织成DescriptorSet,在Command Record过程中被绑定,以便在随后的DrawCall中使用。每个DescriptorSet的内容安排是由DescriptorSet Layout决定的,它决定了哪些Descriptor可以被存储在其中。如下图所示:

Vulkan Descriptor概念是在开发过程中经常遇到的性能瓶颈以及硬件商希望能足够的灵活的前提下设计的。当场景特别复杂的时候(几何多,材质复杂,参数多)的情况下同时带来了很多的资源绑定以及渲染状态设置行为:
// example for typical loops in rendering
for each view {
bind view resources // camera, environment...
for each shader {
bind shader pipeline
bind shader resources // shader control values
for each material {
bind material resources // material parameters and textures
for each object {
bind object resources // object transforms
draw object
}
}
}
}资源将组合为DescriptorSet并具有指定的布局,并且每个着色器可以使用多个DescriptorSet并可以单独绑定(DescriptorSet最少需要一个Descriptor)。开发者有责任管理DescriptorSet,以确保CPU不会更新GPU正在使用的DescriptorSet,并提供DescriptorSet Layout,在CPU端更新成本和GPU端访问成本之间实现最佳平衡。
传统的API将不得不在改变着色器时检查所有的资源绑定,而对哪些是被覆盖的,哪些是需要保留的,因为它没有足够信息可以用来判断并做出优化。如下图所示,DescriptorSet还允许你有部分兼容的PipelineLayout,只要这些PipelineLayout使用的DescriptorSet是相同的,已绑定DescriptorSet就会保持使用。这将大大减少资源绑定的次数。

把许多更新频率非常不同的资源放在同一个DescriptorSet中对整体性能不利。比如一个DescriptorSet有几个Texture和Uniform Buffer,其中只有一个资源需要变化,但仍需要更新整个DescriptorSet这将导致大量的数据被发送到GPU,而这些大部分数据实际上什么都没有修改。
创建DescriptorPool
在Vulkan当中是通过VkDescriptorPool来管理所有的DescriptorSet并分配DescriptorSet。并且DescriptorPool是外部同步的,这意味不能在多个线程中同时分配和/或释放同一池中的DescriptorSet。

- 首先我们先确定层级关系,Set 高于Descriptor。一个Set下有若干个Binding Point,Binding Point下有一个Descriptor Array,Descriptor Array中含有一个或多个Descriptor,最终利用Command绑定的单位是Set.
- 在DescriptorSetLayout的指导下,利用Descriptor Pool提供的Descriptors,组装成一个符合DescriptorSetLayout的Set(即图中红色的DescriptorSet A)。
- 此时,DescriptorSet A中不包含任何的数据,只是一个空框架。接下来,我们根据WriteDescriptorSet来写入信息
- binding和DescriptorSetLayoutBinding0.binding相对应
- 0 <= ArrayElement < DescriptorSetLayoutBinding0.Count,表示写入Array中的第几个对象,这里我们只想写入index=1位置(对应DescriptorSetA.Bind0.DescriptorArray[1]),图中只写入了一个,理论上可以写入连续的多个Descriptor。
正是通过DescriptorBinding,DescriptorSet才实现了Shader和资源的绑定,方便了Shader对资源的读写操作。在Shader可以根据相对应的Binding去访问到相应的数据。

运行时绑定DescriptorSet
这里对应的Command就是vkCmdBindDescriptorSets。至于为什么是BindDescriptorSets而不是BindDescriptorSet,显然,在图中也有所体现,Pipeline Layout的Set不止一个,允许一次绑定多个也是合情合理。
而在Shader中,我们最终通过:
layout(set = 0, binding = 0) uniform MyBuffer
{
mat4 model;
mat4 view;
mat4 proj;
} ubo[];
void main()
{
mat4 trans = ubo[1].proj * ubo[1].view * ubo[1].model;
//...
}
来获取我们写入的对应数据。问:为什么我在Vulkan中找不到VkDescriptor这样一个Handle?
答:Vulkan并不单独处理一个Descriptor,所有的操作都以Descriptor Set为单位,不论是Bind到Pipeline还是更新Set中的一个Descriptor。所以Vk并没有给出一个Descriptor的Handle,而是以WriteDescriptorSet的形式来完成一个Buffer和Descriptor的binding工作
三、SPIR-V
Vulkan是一个底层3D图形API,允许开发者获得硬件底层控制能力,同时减少性能开销,Vulkan为开发人员提供通常留给驱动程序的控制能力,如线程管理,内存管理和错误检查等等功能。
Shader管线
Vulkan中shader渲染管线和OpenGL是相同的,至少需要顶点着色器(Vertex Shader)和片元着色器(Fragment Shader),其他的着色器stage的缺失是没有问题的。
每一层的输出结果将会是下一层的输入,在最后一层片元着色器前,会进行光栅化,所谓光栅化就是将几何数据经过一系列变换后最终转化为像素的过程,光栅化后的结果会被送入片元着色器。VkPipelineStageFlagBits
SPIR-V
Vulkan编译是需要外部GLSL编译器做前半段预编译,然后shader会以中间形式存在,这种中间形态就是SPIR-V(Standard Portable Intermediate Representation),在程序运行的时候,SPIR-V会完全编译。

- SPIR-V有几个明显的优势,开发者再也不会暴露shader源文件,语法错误也会在SPIR-V步骤就会显示,而不是运行时才会报错,因为有预编译过程,程序运行也会更快。
- 在编译SPIR-V二进制码时,我们需要用到glslangValidator进行编译。glslangValidator是Khronos Group定制的GLSL参考编译器,命令行编译模式方便了用户直接测试GLSL语法而绕过C/C++的相关依赖库编译,也不需要在主文件编写大量初始化代码。
.vert Vertex
.tesc Tessellation Control
.tese Tessellation Evaluation .geom Geometry
.frag Fragment
.comp Compute
下面准备创建着色器模块,在开始将代码传递到管线之前,我们需要将其包装到VkShaderModule对象中,创建一个createShaderModule方法。该方法会接收一个字节码缓冲作为参数,创建一个VkShaderModule出来。创建着色器模块是很容易的,只需要指定一个指向到缓冲的指针,以及它的长度。这些信息都在VkShaderModuleCreateInfo结构体中,有一点要注意的是字节码的大小是用字节指定的,但是字节码指针是uint32_t类型的指针而不是char类型的指针,类似以下代码:
- 传入spv数据,传出VkShaderModule
VkShaderModule createShaderModule(const std::vector<char>& code) {
VkShaderModuleCreateInfo createInfo{};
createInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
createInfo.codeSize = code.size();
createInfo.pCode = reinterpret_cast<const uint32_t*>(code.data());
VkShaderModule shaderModule;
if (vkCreateShaderModule(device, &createInfo, nullptr, &shaderModule) != VK_SUCCESS) {
throw std::runtime_error("failed to create shader module!");
}
return shaderModule;
}