前言
在信息爆炸的时代,网络上充斥着大量的小说资源,让人们能够随时随地尽享阅读的乐趣。然而,有些小说网站要求用户付费才能获取完整的内容,这给许多人带来了困扰,尤其是像我这类对金钱概念模糊的人。不过,我们也许可以尝试使用爬虫技术来获取我们想要的小说内容。
然而,实际操作中,我们可能会遇到各种各样的困难,使得爬取小说的任务变得异常艰难,让人望而却步。下面是我在准备过程中考虑到的一些问题。
首先,我们需要面对的第一个问题就是网站的动态加载。许多小说网站为了提高用户体验,会使用JavaScript来动态加载和展示内容。这使得我们传统的爬虫方法无法有效地抓取我们需要的数据。为了解决这个问题,
其次,我们需要面临的问题是网站的防爬机制。一些小说网站为了防止机器人访问,会设置防爬机制,比如检测请求的频率、检查User-Agent等。我通过调整爬虫的请求频率、伪装User-Agent以及随机化请求头等方式来规避这些防爬机制。
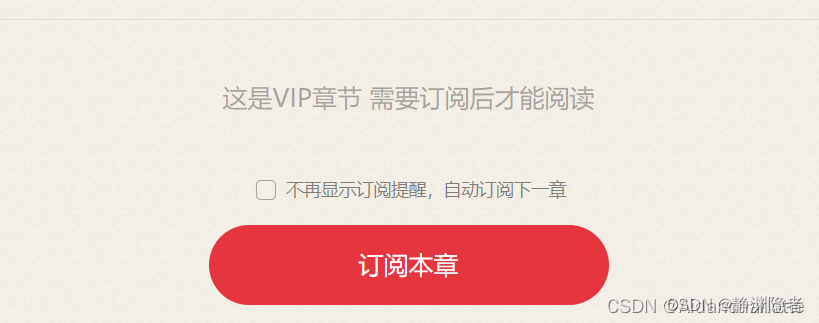
最后,我们需要处理的问题是内容的版权问题。在进行爬取的过程中,我们必须尊重网站的版权规定,避免侵犯他人的知识产权。
第一步.选择合适的爬取工具
我最初的尝试是使用Python中的BeautifulSoup模块。这是一个非常强大的HTML解析库,能够方便地从网页中提取出需要的信息。然而,在爬取小说网站时,我很快发现了问题。这些小说网站通常会使用JavaScript动态加载内容,而BeautifulSoup并不能很好地处理这种情况。因此,我需要寻找一种能够处理JavaScript动态加载内容的爬虫工具。
第二步.尝试使用Selenium库
为了应对动态加载的问题,我转而使用了Selenium库。Selenium可以模拟浏览器的行为,包括执行JavaScript代码,从而能够获取到完整的页面内容。我发现,通过Selenium,我可以获取到想要的小说内容,但是又遇到了新的问题。
第三步:Webdriver变量路径安装问题
在使用Selenium时,我需要指定一个Webdriver,它相当于一个浏览器的实例,用于加载网页并执行操作。然而,我在安装过程中遇到了Webdriver变量路径的问题。我尝试了多种方法,但始终无法成功地将Webdriver正确地配置到我的环境中。
在我尝试解决Webdriver变量路径问题时,我遇到了一些挫折。我尝试按照Selenium官方文档的指导,将Webdriver的路径设置到浏览器的安装目录下,但仍然无法成功。
后来,我意识到问题可能出在环境变量上。我需要在系统环境变量中添加Webdriver的路径,才能让Selenium正确地找到并使用它。于是,我按照这个思路进行了操作,并成功地将Webdriver正确地配置到了我的环境中。
具体来说,我按照以下步骤操作:
法①
-
找到Webdriver的路径。
在Windows系统中,Webdriver通常位于浏览器的安装目录下,例如:C:\Program Files (x86)\Mozilla Firefox\geckodriver.exe -
在系统环境变量中添加Webdriver的路径。
在Windows系统中,可以在系统属性->高级->环境变量中添加新的系统环境变量,将Webdriver的路径添加到其中 -
重新启动Selenium并测试是否成功。
法②
1. 下载合适版本的Webdriver,并将其解压到一个目录中。(我是解压到python安装目录下,记住复制一份并改名,添加变量才能成功)
2. 将Webdriver的路径添加到系统的环境变量中。这样,无论在哪个目录下,系统都能够找到Webdriver的位置。
通过以上步骤,我终于成功地将Webdriver正确地配置到了我的环境中,可以正常地使用Selenium进行网页内容的爬取了。
最终代码
注意事项:
1.一次只能下一本,如果要下一本你需要把txt文本提到一个文件夹中,清空。
2.一定要安装相应的库
import os
import re
from selenium import webdriver
from bs4 import BeautifulSoup
import time
from tqdm import tqdm
# 作者信息
from termcolor import colored
author_name = "作者:O2Ethereal"
author_url = "https://gitee.com/o2ethereal"
print(f"{author_name}\n{author_url}")
print("网站举例:\nhttps://www.biqukan8.cc/38_38836/")
# 用户输入小说目录下载地址
directory_url = input("请输入小说目录下载地址(回车键继续):")
# 创建 Edge WebDriver,使用无痕模式
options = webdriver.EdgeOptions()
options.add_argument('--inprivate')
driver = webdriver.Edge(options=options)
# 打开小说目录页面
driver.get(directory_url)
time.sleep(5) # 等待页面加载
# 获取页面源码
directory_html = driver.page_source
soup = BeautifulSoup(directory_html, 'html.parser')
# 获取章节链接和标题
chapter_data = []
in_content_div = False
for element in soup.find_all(['dt', 'dd']):
if "正文卷" in element.get_text():
in_content_div = True
elif in_content_div and element.name == 'dd':
link = element.a.get('href')
if link.startswith("/"):
link = link[1:] # 去除开头的斜杠
chapter_url = f"https://www.biqukan8.cc/{link}"
title = element.a.get_text()
chapter_data.append((title, chapter_url))
# 创建文件夹
output_folder = "novel_chapters"
os.makedirs(output_folder, exist_ok=True)
# 正则表达式模式
pattern = re.compile(r'(我们会尽快处理\.举报后请耐心等待,并刷新页面。|\(\)章节错误,点此举报\(免注册\)我们会尽快处理\.举报后请耐心等待,并刷新页面。|笔趣阁手机版阅读网址:m\.biqukan8\.cc|请记住本书首发域名:www.biqukan8.cc。)')
# 保存每个章节的内容到文件
for idx, (title, link) in enumerate(
tqdm(chapter_data, desc="Downloading", ncols=100, bar_format="{l_bar}%s{bar:10}{r_bar} {percentage:3.0f}%",
colour="cyan"), start=1):
# 打开章节页面
driver.get(link)
time.sleep(0.5) # 等待页面加载
chapter_soup = BeautifulSoup(driver.page_source, 'html.parser')
# 获取章节内容
content_div = chapter_soup.find('div', class_='showtxt')
if content_div:
chapter_content = content_div.get_text()
# 去除章节链接
chapter_content = chapter_content.replace(link, "")
# 使用正则表达式清理文本
chapter_content = re.sub(pattern, '', chapter_content)
# 去除空行
lines = [line.strip() for line in chapter_content.split('\n') if line.strip()]
cleaned_content = '\n'.join(lines)
# 保存到文件
file_name = os.path.join(output_folder, f"{title}.txt")
with open(file_name, "w", encoding="utf-8") as file:
file.write(cleaned_content)
print(f"Downloading: {idx / len(chapter_data) * 100:.0f}%|▏ {title} 已下载")
# 关闭 WebDriver
driver.quit()效果
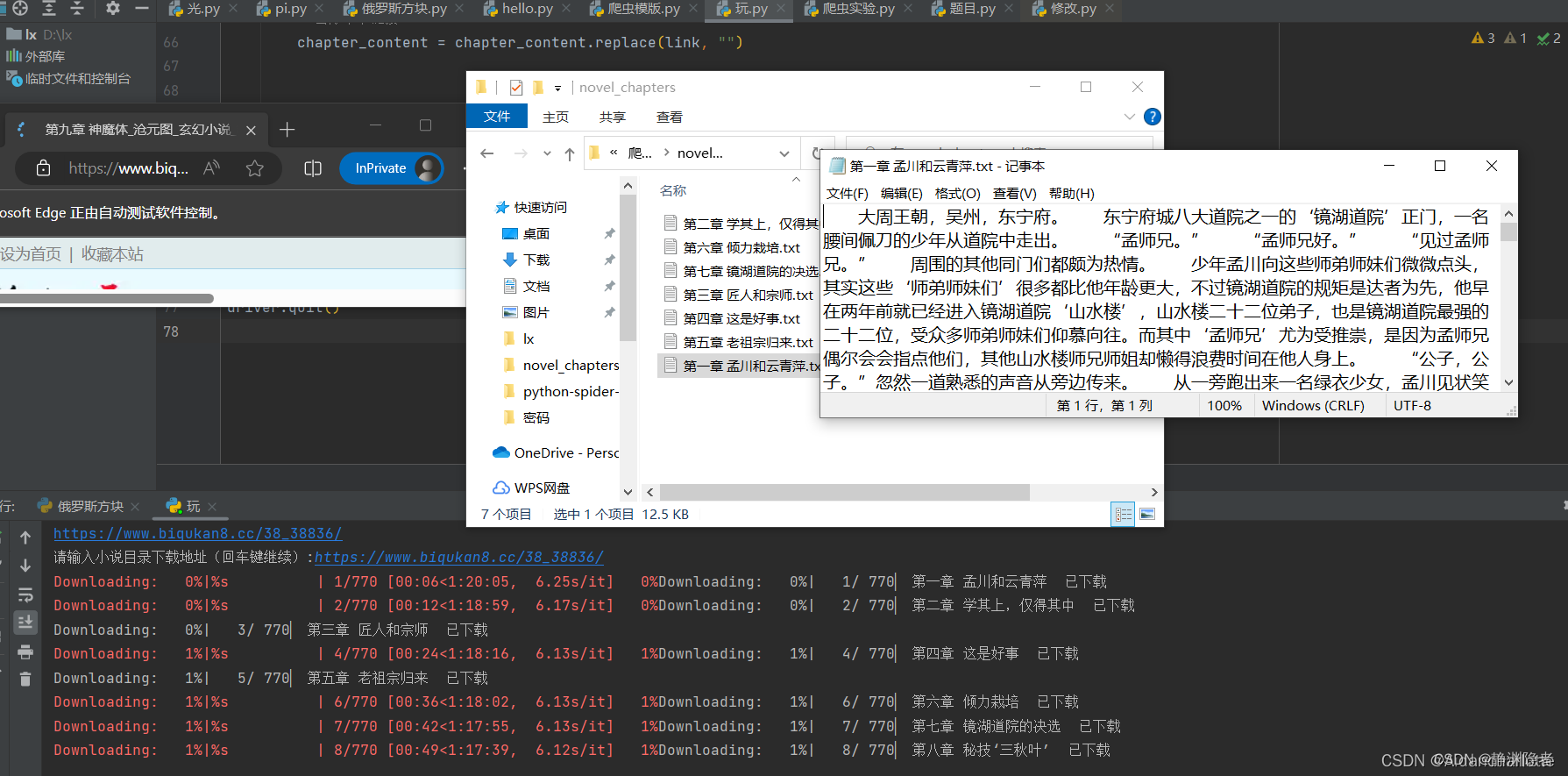
好东西,偷偷用