网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach[1]

第4章 控制算法(Control-Based Algorithms)
本章将介绍目前占主导地位的网络拥塞控制算法。Van Jacobson和Mike Karels在1988年提出了这种方法,并进行了持续多年的改进。目前广泛使用的是被称为CUBIC的变体,稍后将详细介绍。
控制算法的总体思路相当简单,简单来说就是基于当前估计的可用带宽传输一组数据包,然后TCP发送方对两组网络信号作出反应。首先是ACK,收到ACK表明一个包已经离开网络,可以安全的传输一个新包,而不会增加拥塞程度。通过ACK控制数据包的传输节奏,被称为自时钟(self-clocking) 。其次,超时意味着数据包丢失,从而意味着发生了网络拥塞,因此需要降低TCP的发送速率。因为通过丢包作为信号,意味着拥塞已经发生,而我们是在事后才做出反应,所以将这种方法称为基于控制(control-based) 的方法。
作为实际使用的拥塞控制方法,还有需要解决许多微妙的问题,本章将介绍处理这些问题的技术,因此也可以作为识别和解决一系列问题的经验的案例研究。在接下来的章节中,我们将在介绍每种技术时追溯其历史背景。
4.1 超时计算
超时和重传是TCP实现可靠字节流的核心方法,但超时在拥塞控制中也扮演着关键角色,因为可以表示丢包,而丢包又表明拥塞的可能性。换句话说,TCP超时机制是其整体拥塞控制方法的构建块。
请注意,发生超时时,可能是因为丢了一个包,或者丢了相应的ACK,或者什么都没丢,但是ACK到达时间比预期要长。因此,重要的一点是要知道ACK到达需要多长时间,否则就有可能在没有发生拥塞的时候做出发生拥塞一样的响应。
TCP有一种根据测量的RTT进行计算的自适应方法来设置超时。虽然听起来很简单,但完整实现比想象的要复杂得多,并且多年来经过了多次改进,本节将回顾这一经验。
4.1.1 初始算法
我们从TCP规范中描述的简单算法开始,其思想是保存RTT的平均值,然后用RTT的函数计算超时。具体来说,TCP每发送一个分片,就会记录时间,当该分片的ACK到达时,再次读取时间,然后将这两次时间的差值作为SampleRTT,然后计算EstimatedRTT,作为前一个估计和新样本之间的加权平均值。也就是说,
参数α是为了平滑EstimatedRTT。小的α值可以感受到RTT的微小变化,但可能会容易受到暂时波动的影响。另一方面,大的α值更稳定,但可能不够快,无法适应真正的变化。TCP初始规范建议在0.8到0.9之间取值,然后基于EstimatedRTT以一种相当保守的方式计算超时:
4.1.2 Karn/Partridge算法
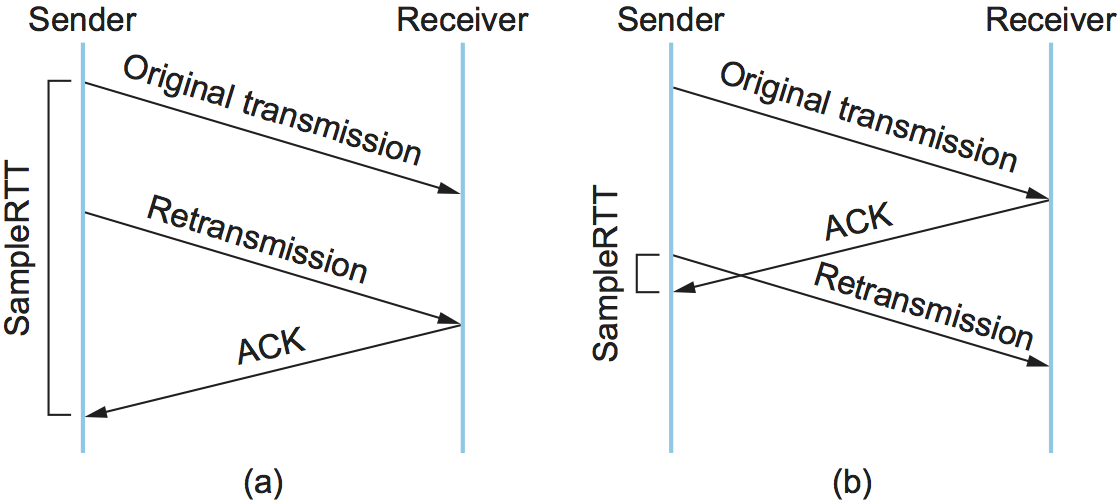
几年后,在这种简单方法中发现了一个相当明显的缺陷: ACK实际上并不响应传输,而是响应对数据的接收。换句话说,当重传了某个分片,然后收到一个ACK,发送端在测量样本RTT时,无法确定这个ACK应该与第一次还是第二次传输的分片匹配。
为了计算出准确的SampleRTT,必须知道ACK与哪次传输相关联。如图21所示,如果假设ACK匹配初始传输,但实际上应该匹配第二次传输,那么SampleRTT就太大了(a);如果假设ACK匹配第二次传输,但实际上是匹配第一次传输,那么SampleRTT就太小了(b)。
解决方案以其发明者的名字命名,被称为Karn/Partridge算法,乍一看出奇的简单。在这种算法中,每当TCP重传一个分片,就停止采集RTT样本,即只对只发送过一次的分片测量SampleRTT。但该算法还包括对TCP超时机制的第二个更改。每次TCP重传时,将下一个超时设置为上一次超时的两倍,而不是基于上一次EstimatedRTT,即Karn和Partridge提出超时计算采用指数后退方法。使用指数后退的动机是,超时会导致重传,而重传分片不再有助于更新RTT估算。因此,在宣布丢包时要更加谨慎,而不是进入一个可能的快速超时然后重传的周期。在后面的章节中,我们将再次在一个更复杂的机制中看到指数后退的概念。
4.1.3 Jacobson/Karels算法
Karn/Partridge算法是对RTT估算的一种改进,但并没有解决拥塞问题。Jacobson和Karels在1988年提出的拥塞控制机制(以及其他几个组件)定义了一种决定何时超时以及重传的新方法。
原始算法的主要问题是没有考虑样本RTT的方差。直观的说,如果样本之间的变化很小,那么EstimatedRTT更值得信任,没有理由将这个估计值乘以2来计算超时。另一方面,样本的方差较大就表明超时值不应该与EstimatedRTT耦合得太紧密。
在新方法中,发送方像以前一样测量新的SampleRTT,然后将新采样加入超时计算中,如下所示:
δ在0到1之间取值,即,计算RTT及其变化的移动加权平均值,然后以EstimatedRTT和Deviation的函数计算超时,如下所示:
根据经验值,μ一般设为1,
一般设为4。因此,当方差很小时,TimeOut接近EstimatedRTT,较大的方差会导致Deviation主导计算。
4.1.4 实现
关于TCP中超时的实现,有两点需要注意。首先,不使用浮点运算就可以实现EstimatedRTT和Deviation的计算。相反,整个计算被扩展为
,δ被设为
,从而允许我们进行整数运算,通过移位实现乘除法,获得更高的性能。计算结果由下面的代码片段给出,其中n=3(即δ=1/8)。注意,EstimatedRTT和Deviation以扩展形式存储,而代码开头的SampleRTT值以及末尾的TimeOut值都是真正的、未扩展的值。如果发现代码难以理解,可能需要尝试将一些实数代入其中,并验证给出的结果是否与上面的方程相同。
{
SampleRTT -= (EstimatedRTT >> 3);
EstimatedRTT += SampleRTT;
if (SampleRTT < 0)
SampleRTT = -SampleRTT;
SampleRTT -= (Deviation >> 3);
Deviation += SampleRTT;
TimeOut = (EstimatedRTT >> 3) + (Deviation >> 1);
}
其次,该算法精度和读取当前时间的算法一样。在典型Unix实现中,时钟精度高达500毫秒,比100到200毫秒的平均跨国RTT要大得多。更糟的是,TCP的Unix实现只在这个500毫秒的时钟间隙检查是否发生超时,并且只对每个RTT进行一次往返时间采样。这两个因素的结合可能意味着在传输分片1秒后才会发生超时。下一节将介绍使RTT计算更加精确的TCP扩展。
关于TCP超时实现的更多细节,我们向读者推荐权威的RFC:
延伸阅读:
RFC 6298: Computing TCP’s Retransmission Timer[2]. June 2011.
4.1.5 TCP时间戳扩展
到目前为止所介绍的对TCP的更改只是对发送方计算超时的方式进行了调整,协议本身并没有更改。不过,也有一些对TCP报头的扩展,可以帮助改进管理超时和重传的能力。我们在这里讨论的扩展与RTT估算有关,在2.3节中介绍过另一个为AdvertisedWindow建立比例因子的扩展,接下来还将介绍第三种扩展,用于发送可选ACK或SACK。
TCP时间戳扩展有助于改进TCP超时机制。与粗粒度事件测量RTT不同,TCP可以在即将发送一个分片时读取实际的系统时钟,并将这个时间(可以将其看作一个32位时间戳)放入分片头部。然后,接收方将这个时间戳在其确认中回传给发送方,发送方用当前时间减去这个时间戳来测量RTT。本质上,时间戳选项为TCP提供了一个方便的地方来存储一个分片何时被传输的记录。注意,连接中的端点不需要同步时钟,因为时间戳是在连接的同一端写入和读取的。这改进了RTT的测量,从而降低了由于较差的RTT估算而导致不正确超时的风险。
时间戳扩展还有第二个用途,即提供了一种创建64位序列号字段的方法,解决了2.3节中介绍的32位序列号的缺点。具体来说,TCP根据64位逻辑标识符(SequenceNum字段为低32位,时间戳为高32位)来决定是否接受或拒绝一个分片。由于时间戳总是增加的,因此可以用来区分相同序列号的两个不同版本。请注意,在此设置中使用时间戳只是为了防止重复,不作为序列号的一部分用于排序或确认数据。
4.2 线性增加/指数减少(Additive Increase/Multiplicative Decrease)
更好超时计算方法是必要的构建模块,但不是拥塞控制的核心。拥塞控制最主要的挑战是计算出发送者可以安全的传输多少流量。为此,TCP为每个连接维护一个新的状态变量,称之为CongestionWindow(但在文献中通常被称为cwnd,这是基于代码中使用的变量名),发送端通过它来限制在给定时间内允许传输的数据量。
拥塞窗口是拥塞控制机制的流控通告窗口。TCP发送端未确认的最大字节数是拥塞窗口和通告窗口的最小值。因此,使用第2章定义的变量,TCP的有效窗口修改如下:
也就是说,在计算EffectiveWindow时,MaxWindow取代了AdvertisedWindow。因此,TCP发送端的发送速度不允许超过最慢的组件(网络或目标主机)所能适应的速度。
当然,问题是TCP如何为CongestionWindow学习一个合适的值。不像AdvertisedWindow是由连接的接收端发送的,没有人给TCP发送端发送一个合适的CongestionWindow。答案是TCP发送端根据感知到的网络中存在的拥塞级别来设置CongestionWindow,这意味着到当拥塞水平上升时减小拥塞窗口,当拥塞水平下降时增加拥塞窗口。综合起来,基于其所采用的方法,该机制通常被称为线性增加/指数减少(AIMD, additive increase/multiplicative decrease) 。
那么关键问题就变成了: 发送端如何确定网络是拥塞的,以及应该怎样减小拥塞窗口?根据观察,报文无法递送以及超时的主要原因是由于拥塞而丢包,数据包在传输过程中由于错误而被丢弃的情况非常罕见,因此TCP将超时解释为拥塞的标志,并降低传输速率。具体来说,每次发生超时时,发送端将CongestionWindow设置为以前值的一半。对于每个超时,将拥塞窗口减半对应于AIMD的"指数减少"部分。
虽然CongestionWindow以字节为单位,但如果我们从整个包的角度来考虑,它是最容易理解指数减少的。例如,假设CongestionWindow当前设置为16个包,如果检测到丢包,CongestionWindow被设置为8。(通常,当超时发生时,会检测到丢包,但正如下面所看到的,TCP有另一种机制来检测丢包。) 额外的丢包导致拥塞窗口减少到4个,然后是2个,最后是1个包。CongestionWindow不允许小于一个包的大小,在第2章我们知道这是MSS。
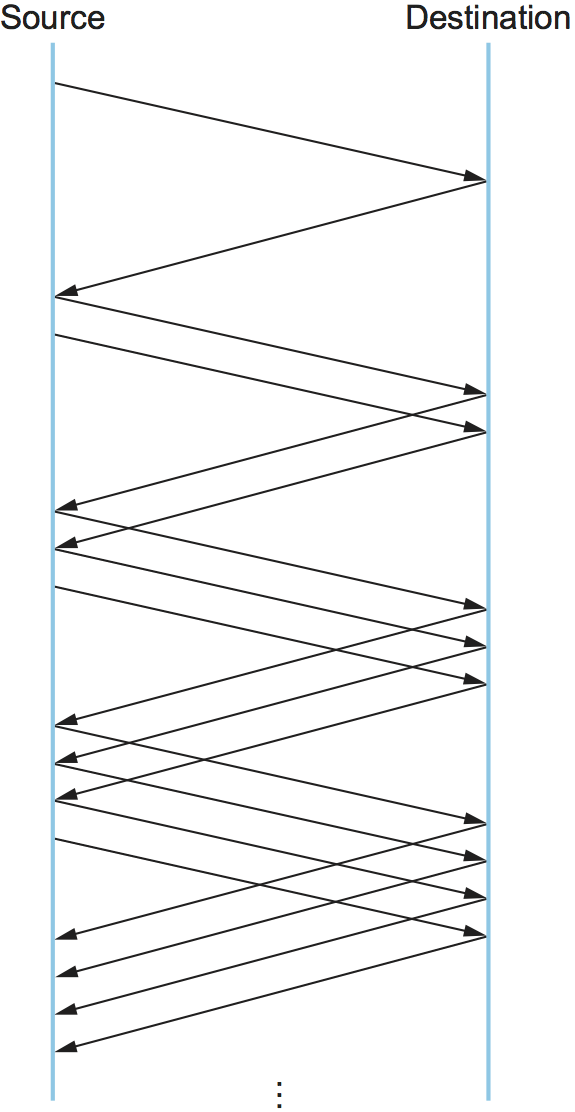
只减少窗口大小的拥塞控制策略显然过于保守,我们还需要能够增加拥塞窗口,以利用网络中新近可用的容量。这是AIMD的"线性增加"部分。其工作原理如下,每次发送端成功发送一个CongestionWindow值的包时,也就是说,在上一个往返时间(RTT)发送出去的每个包都被ACK了,就会给CongestionWindow增加相当于一个包的值,这种线性增长如图22所示。
实践中,TCP不会等到收到整个窗口的ACK值才给拥塞窗口增加一个包,而是每收到一个ACK就增加一点拥塞窗口。具体来说,每次ACK到达时,拥塞窗口按如下方式递增:
也就是说,不是在每个RTT中给CongestionWindow增加整个MSS字节,而是在每次接收到ACK时增加MSS的一小部分。假设每个ACK都响应收到了MSS字节,那么这个部分就是MSS/CongestionWindow。
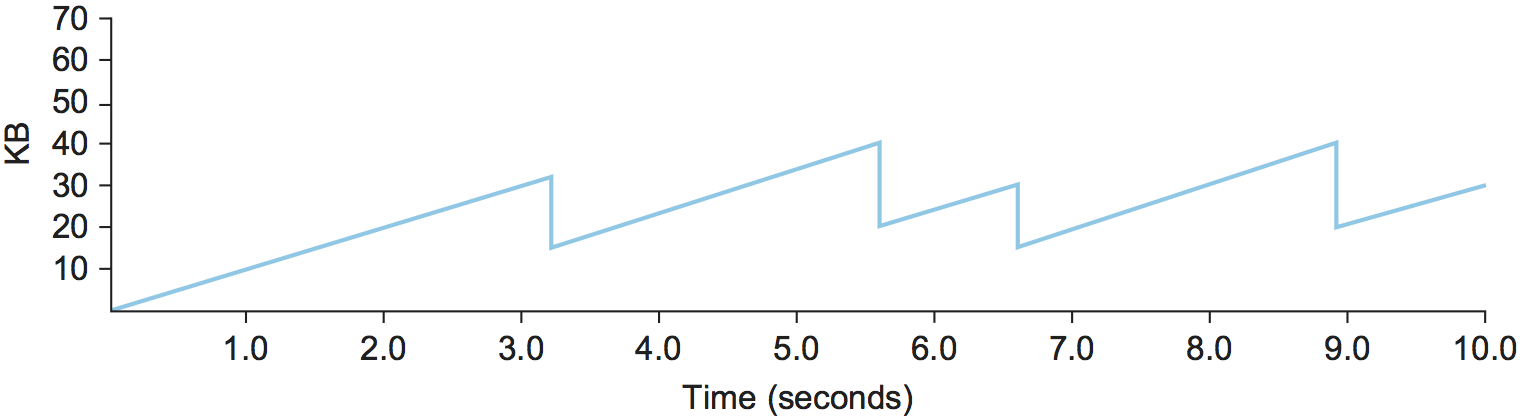
这种不断增加和减少拥塞窗口的模式在连接的整个生命周期中持续存在。事实上,如果我们将CongestionWindow的当前值作为时间的函数绘制出来,会得到一个如图23所示的锯齿状图形。关于AIMD需要理解的重要概念是,发送端愿意以比增加拥塞窗口更快的速度减少拥塞窗口。我们可以想象另一种增加/减少策略,在ACK到达时窗口增加1个包,超时发生时减少1个包,但这被证明太激进了。快速响应拥塞对稳定性非常重要。
对于TCP为什么对减少窗口很积极而对增加窗口很保守,直观解释是,窗口太大会造成很多后果。因为当窗口太大时,丢失的包将被重传,从而使拥塞更加严重,尽快摆脱这种状态非常重要。可以将AIMD看作是缓慢增加数据,以探测拥塞开始的级别,然后当通过超时检测到该级别时,从拥塞崩溃的边缘快速后退。
最后,由于超时是引发指数减少的拥塞的标志,TCP需要它所能承受的最精确的超时机制。我们已经在第4.1节中介绍了TCP的超时机制,但是请回忆一下,超时被设置为平均RTT和平均偏差的函数。
4.3 慢启动(Slow Start)
当发送端使用了接近网络的可用容量时,刚刚介绍的增加机制是一种合理的方法,但如果从头开始时,需要花费太长的时间。因此,TCP提供了第二种机制,被反直觉的称为*慢启动(slow start)*,用于从冷启动快速增加拥塞窗口。慢启动可以成倍增加拥塞窗口,而不是线性增加。
具体来说,发送端首先将CongestionWindow设置为一个包。当这个包的ACK到达时,TCP将CongestionWindow加1,然后发送两个包。在收到相应的两个ACK后,TCP将CongestionWindow加2,然后发送4个数据包。最终的结果是,TCP在每次RTT传输中有效增加了一倍的数据包数量。图24显示了慢启动期间传输的数据包数量的增长,可以将其与图22所示的线性增长进行比较。
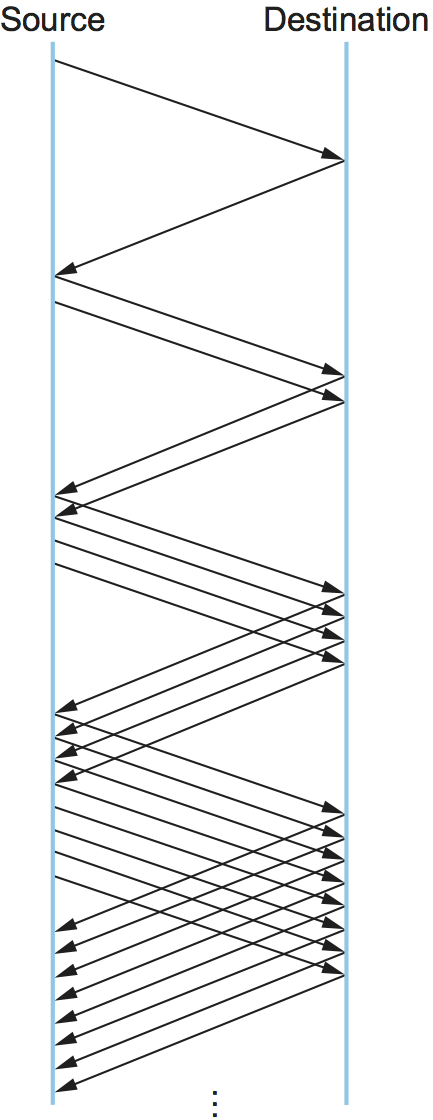
为什么指数机制会被称为"慢"确实令人费解,但从其历史背景来看,这是有道理的。不要将慢启动与前一节的线性机制进行比较,而是与TCP的原始行为进行比较。考虑一下,当建立连接时,发送端首先(即当前没有信息包在传输时)开始发送数据包,会发生什么情况。如果发送端发送的包数量和窗口允许的数量一样多(也正是TCP在开发慢启动之前所做的),那么即使网络中有相当大的可用带宽,路由器也可能无法消耗这些突发的包,因为这完全取决于路由器上有多少缓冲空间可用。因此,慢启动被设计为间隔发送数据包,这样就不会发生突发流量。换句话说,尽管它的指数增长比线性增长要快,但慢启动比一次性发送整个通告窗口的数据要"慢"得多。
实际上,慢启动有两种不同的情况。第一种情况是在连接刚开始建立的时候,此时发送端不知道在给定时间里能传输多少包。(请记住,今天TCP链接运行在从1 Mbps到40 Gbps的各种网络情况下,所以发送端没有办法知道网络容量。)在这种情况下,慢启动每过一个RTT就加倍CongestionWindow,直到发生了丢包,然后由于超时导致指数减少并将CongestionWindow除以2。
第二种情况更微妙一些,当连接在等待超时失效,就会发生这种情况。回想一下TCP的滑动窗口算法是如何工作的,当一个包丢失时,发送端最终会到达一个状态,在这个状态上它已经发送了通告窗口允许的尽可能多的数据,因此在等待一个不会到达的ACK时阻塞。最终会发生超时,但此时没有包在传输,这意味着发送端将不会收到ACK来触发新包的传输。相反,发送端将接收一个累积的ACK,从而重新打开整个通告窗口,但是,如上所述,发送端将使用慢启动来重新启动数据流,而不是一次将整个窗口的数据全部发送到网络上。
虽然发送端再次使用慢启动,但现在知道的信息比连接开始时更多。具体来说,发送端具有当前(且有用)的CongestionWindow值,作为丢包的结果,这个值是上次丢包之前存在的CongestionWindow值除以2,我们可以把它看作目标拥塞窗口。慢启动快速增加发送速率到达这个值,然后增加的窗口将超过这个值。注意,我们需要小小的记录一下,因为我们想要记住由指数减少导致的目标拥塞窗口,以及慢启动使用的实际拥塞窗口。为了解决这个问题,TCP引入了一个临时变量来存储目标窗口,通常称为CongestionThreshold,被设置为与CongestionWindow的值相等,这个值是由指数减少产生的。然后,变量CongestionWindow被重置为一个包,并且随着每一个ACK的接收而增加一个包,直到到达CongestionThreshold,然后每过一个RTT再增加一个包。
换句话说,以下代码段定义了TCP如何增加拥塞窗口:
{
u_int cw = state->CongestionWindow;
u_int incr = state->maxseg;
if (cw > state->CongestionThreshold)
incr = incr * incr / cw;
state->CongestionWindow = MIN(cw + incr, TCP_MAXWIN);
}
其中state表示特定TCP连接的状态,并定义了允许增加的拥塞窗口的上限。
图25显示了TCP的CongestionWindow是如何随着时间的推移而增加和减少的,并用来说明慢启动和线性增加/指数减少的相互作用。这个图是从实际的TCP连接中获取的,并显示了随着时间推移的CongestionWindow的当前值(带颜色的线)。

关于这个图示,有几个地方需要注意。首先是连接开始时,拥塞窗口快速增加。这对应于最初的慢启动阶段。慢启动阶段继续,直到在大约0.4秒时丢了几个包,此时CongestionWindow在大约34 KB时变平。(下面将讨论为什么这么多数据包在慢启动过程中丢失。) 拥塞窗口变平的原因是由于丢失了几个包,没有ACK到达。事实上,在此期间没有发送任何新数据包,这一点从顶部缺少散列标记就可以看出。超时最终大约在2秒发生,此时拥塞窗口被除以2(即从大约34 KB削减到大约17 KB),并且将CongestionThreshold设置为这个值,慢启动导致CongestionWindow被重置为一个包,并从那里开始加速。
图中没有足够的细节来查看当两个数据包在2秒后丢失时到底会发生什么,所以我们直接跳到发生在2秒到4秒之间的拥塞窗口的线性增加。大约4秒时,同样是由于丢包,拥塞窗口变平。在5.5秒的时候:
-
发生了超时,导致拥塞窗口被除以2,从大约22 KB下降到11 KB,而 CongestionThreshold被设置为这个值。 -
CongestionWindow被重置为一个包,发送方进入慢启动。 -
慢启动导致 CongestionWindow指数增长,直到达到CongestionThreshold。 -
然后 CongestionWindow线性增长。
当大约8秒时再次发生超时,重复相同的模式。
现在我们回到这个问题: 为什么在最初的慢启动期间会丢失这么多包。此时,TCP试图了解网络上有多少带宽可用,这是一项艰巨的任务。如果发送端在这个阶段不主动,例如,如果只是线性增加拥塞窗口,那么需要很长时间才能发现有多少带宽可用。这可能会对此连接的吞吐量产生重大影响。另一方面,如果发送端在这个阶段比较激进,那么就需要冒着被网络丢弃半个窗口的数据包的风险。
为了了解指数增长过程中会发生什么,考虑这样一种情况: 发送端仅仅能够成功通过网络发送16个包,导致网络的拥塞窗口翻倍至32。然而,假设网络恰好有足够的容量支持来自这个发送端的16个数据包。可能的结果是,在新的拥塞窗口下发送的32个数据包中,有16个将被网络丢弃,实际上这是最坏的结果,因为一些数据包会被缓冲到某个路由器中。随着网络带宽时延积的增加,问题将变得越来越严重。例如,1.8 MB的带宽时延积意味着每个连接在开始时都有可能丢失高达1.8 MB的数据。当然,需要假定发送端和接收端都实现了"大窗口(big windows)"扩展。
也有人探索慢启动的替代方案,即发送端试图通过更复杂的方法估计可用带宽。其中一个例子叫做快启动(quick-start) 。其基本思想是,TCP发送端通过将请求的速率作为IP选项放入SYN包中,从而要求比慢启动所允许的更大的初始发送速率。沿路路由器可以检查该选项,评估该流出口链路当前的拥塞水平,并决定该速率是否可以接受,或者是否可以接受较低的速率,或者是否应该使用标准慢启动。当SYN到达接收端时,要么包含路径上所有路由器都可以接受的速率,要么包含路径上一个或多个路由器不能支持快启动请求的指示。在前一种情况下,TCP发送方使用该速率开始传输,在后一种情况下,回到标准慢启动状态。如果允许TCP以更高速率开始发送,会话可以更快到达填满流水线的状态,而不用花费许多往返时间来完成此操作。
显然,对TCP进行这种增强的挑战之一是,与标准TCP相比,需要来自路由器的更多合作。如果路径中的某个路由器不支持快启动,则整个系统将恢复到标准慢启动。因此,在这类增强进入互联网之前可能还需要很长一段时间,目前更可能用于受控的网络环境(例如,研究网络)。
4.4 快速重传和快速恢复
目前为止所介绍的机制是将拥塞控制添加到TCP的最初提议的一部分,因为相应实现被包含在1988年的4.3 BSD Unix的Tahoe发行版中,因此被统称为TCP Tahoe。一旦被广泛部署,经验表明Tahoe的一些问题随后被1990年初的TCP Reno (4.3BSD-Reno版本的一部分)解决。本节将介绍相关经验以及Reno解决问题的方法。
简言之,TCP超时的粗粒度实现导致长时间的连接在等待计时器过期时失效。一种称为快速重传(fast retransmit) 的启发式方法有时会比常规超时机制更早触发丢失数据包的重传。快速重传机制不替换常规超时,只是增加了另一种可以更及时检测丢包的方法。
其思想是,每当一个数据包到达接收端,接收端回应一个ACK,即使这个序列号已经被确认。因此,当一个乱序包到达,TCP还不能确认包中包含的数据(因为之前的数据还没有到达),TCP会重新发送和上次相同的ACK。
相同ACK的第二次传输称为重复ACK(duplicate ACK) 。当发送端看到一个重复ACK时,就知道另一方一定收到了一个顺序错误的包,这表明前一个包可能已经丢失了。不过也有可能之前的包只是被延迟了而不是丢失了,所以发送端会等待,直到看到一定数量的重复ACK(实际上是3个),然后重新发送丢失的包。这里内置的假设(在实践中得到了很好的验证)是,乱序数据包比丢失的数据包要少得多。
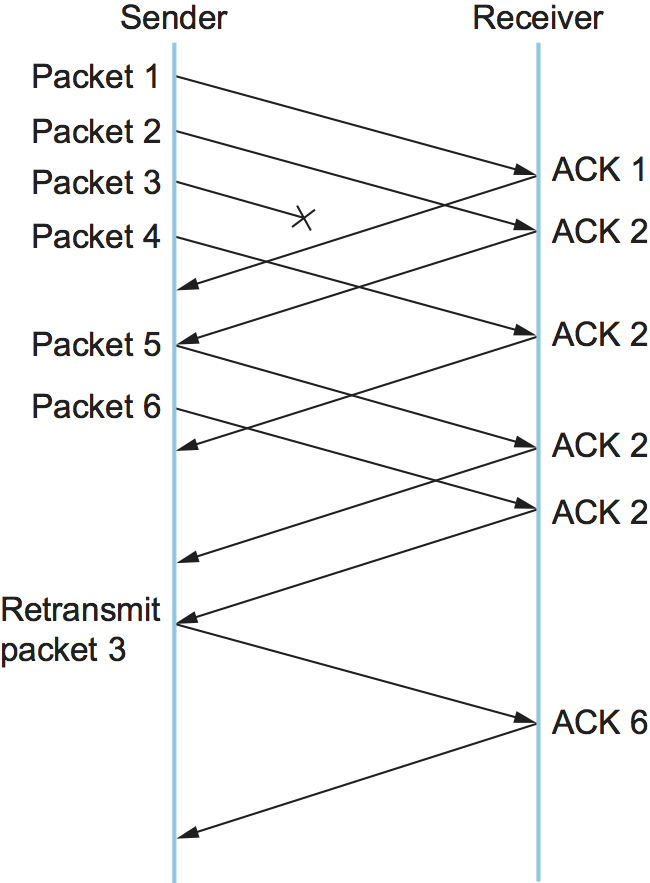
图26说明了重复ACK如何触发快速重传。本例中,目的地接收到包1和包2,但包3在网络中丢失。因此,当数据包4到达时,目的地将对数据包2发送一个重复ACK,当数据包5到达时再次发送,以此类推。(为了简化示例,我们从包1、2、3等的角度考虑,而不是考虑每个字节的序列号。) 当发送方看到数据包2的第三个重复ACK(因为接收方收到了数据包6而发送的ACK)时,会重新发送数据包3。请注意,当包3的重传副本到达目的地时,接收方随后将包括包6在内的所有内容的累积ACK发送回发送端。
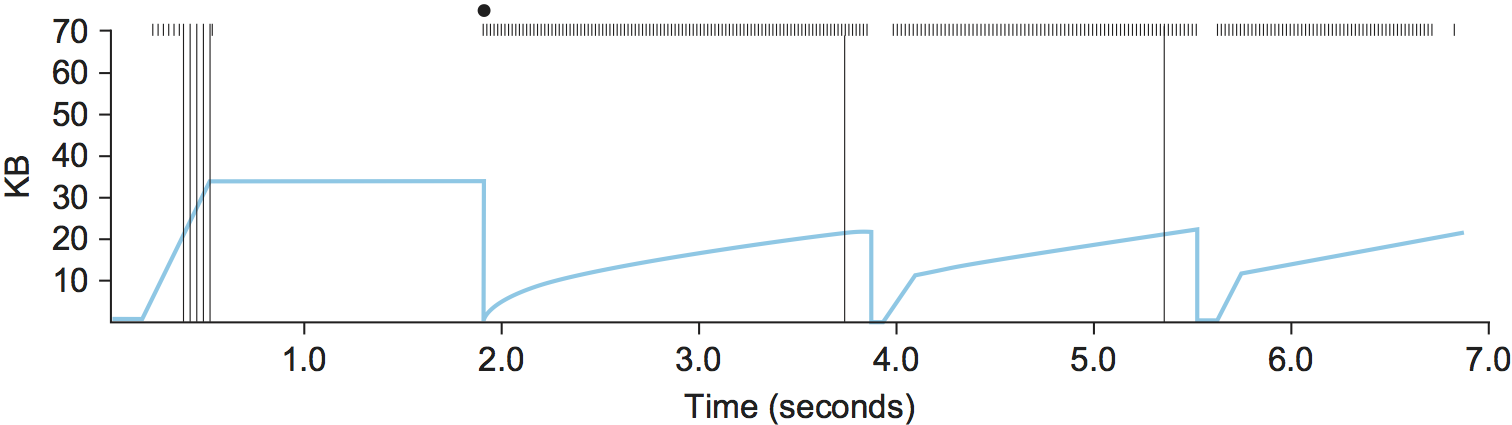
CongestionWindow;实心标记=超时;散列标记=每个数据包传输的时间;竖线=最终重传的数据包第一次传输的时间。
图27展示了具有快速重传机制的TCP版本的行为。将此图示与图25进行比较是很有意思的事情,拥塞窗口保持扁平且消除了无法发送数据包的时间。通常,这种技术能够消除典型TCP连接上大约一半的粗粒度超时,从而使吞吐量比使用其他方法可以实现的性能提高约20%。但请注意,快速重传策略并不能消除所有粗粒度超时,这是因为对于小窗口来说,在传输过程中没有足够多的包来导致发送足够多的重复ACK。如果有足够多的丢包(例如,在初始慢启动阶段发生的情况),滑动窗口算法最终会阻塞发送方,直到出现超时。在实践中,TCP的快速重传机制可以在每个窗口中检测到最多三个丢包。
还可以做进一步改进。当快速重传机制发出了拥塞信号,可以基于还在流水线中的ACK来触发包的发送,而不是将拥塞窗口设为一个包并开始慢启动。这一被称为快速恢复(fast recovery) 的机制有效消除了快速重传机制检测到丢包并开始慢启动的阶段。例如,快速恢复避免了图27中3.8到4秒之间的慢启动周期,而是简单的将拥塞窗口减少一半(从22 KB到11 KB),并重新开始增加拥塞窗口。换句话说,慢启动只在连接开始时和发生粗粒度超时时使用,其他任何时候,拥塞窗口都遵循纯粹的线性增加/指数减少模式。
4.5 增量改进
如果对TCP拥塞控制的研究只教会了我们一件事,那就是认识到这个问题有多么复杂,以及需要正确处理多少细节。只有通过一系列经过经验检验的结果,即渐进的改进才能实现。下面给出了这一教训的两个额外例子。
4.5.1 TCP SACK
原始TCP规范使用累积确认,意味着接收方在任何丢包之前只确认收到的最后一个包。可以认为接收方拥有接收包的集合,其中任何丢失的包都由接收字节流中的空洞表示。根据原始规范,即使丢失了几个包,也只能告诉发送方第一个洞开始。直观的说,这种细节的缺乏可能会限制发送方对丢包作出有效响应的能力。解决这个问题的方法被称为选择性确认(selective acknowledgments) 或SACK。SACK是TCP的一个可选扩展,最初是在Jacobson和Karels的早期工作完成后不久提出的,但因为很难证明有用,因此花了几年时间才被接受。
在没有SACK的情况下,当分片被无序接收时,发送方只有两种合理的策略。对于重复ACK或超时,悲观策略不仅会重传明显丢失的分片(接收方丢失的第一个包),还会重传随后传输的任何分片。实际上,悲观策略假设了最坏的情况: 所有这些部分都消失了。悲观策略的缺点是可能不必要的重传第一次成功接收到的分片。另一种策略是对丢失信号(超时或重复ACK)做出响应,方法是只重传触发该信号的分片。乐观方法假设了最乐观的情况: 只有一个部分丢失了。乐观策略的缺点是,当一系列连续分片丢失时,恢复非常缓慢,在拥堵情况下就可能发生这种情况。之所以慢,是因为在发送方收到重传前一段的ACK之后,才会发现每一个分片的丢失。这意味着它每个分片都需要消耗一个RTT,直到重传丢失序列中的所有分片。使用SACK选项,发送方可以使用一种更好的策略: 只重传那些填补已选择性确认的分片之间空白的分片。
连接开始时,发送方首先协商SACK,告诉接收方它可以处理SACK选项。当使用SACK选项时,接收方继续正常确认分片,Acknowledge字段的含义不会改变,但是也会对任何无序接收的块使用额外的确认扩展报头。这允许发送方识别在接收方存在的空洞,并只重传丢失的分片,而不是之后的所有分片。
SACK被证明可以提高TCP Reno的性能,尤其是在一个RTT中丢弃多个包的情况下(因为当只丢弃一个包时,累积ACK和SACK是一样的)。随着时间的推移,随着带宽时延积的增加,这种情况变得更可能发生,给定RTT可能丢弃更多的数据包。因此,在1996年被提议成为IETF标准的SACK是对TCP的及时补充。
4.5.2 NewReno
从麻省理工学院的Janey Hoe在20世纪90年代中期的一些研究开始,这种被称为NewReno的增强技术通过在某些包丢失的情况下对重传哪些包做出更智能的决定,逐步提高了TCP的性能。
延伸阅读:
J. Hoe. Improving the start-up behavior of a congestion control scheme for TCP[3]. SIGCOMM ‘96. August 1996.
NewReno背后的关键见解是,即使没有SACK,重复ACK也可以向发送方传递丢弃了多少包以及丢弃了哪些包的信息,因此发送方可以在何时重传包方面做出更明智的选择。此外,在单个窗口出现多次丢包的情况下,NewReno可以避免以前版本中出现的对拥塞窗口多次减半。
NewReno有很多细节,但简单来说,如果丢了一个包,发送方需要重复3次ACK,才会重新发送丢失的包。当接收端收到重传时,因为现在已经填满了接收缓冲区中的空洞,因此将ACK所有缓冲区中的包。相反,如果丢失了多个包,则在收到重传包之后的第一个ACK将只能部分覆盖未响应的包。由此,发送方可以推断有更多的包丢失,并立即开始尝试通过发送下一个尚未得到确认的包来填补空白。这可以减少的超时,减少阻塞时间并且缓解对拥塞窗口的减少。
值得注意的是,NewReno在1999年至2012年发布了三次RFC,每一次都修复了之前算法中的一些问题。这是一个关于理解拥塞控制的细节是多么复杂的案例研究(特别是关于TCP重传机制的微妙之处),也增加了部署新算法的挑战。
4.6 TCP CUBIC
现在应该很清楚,试图找到向网络发送流量的适当速率是拥塞控制的核心,而在任何一个方向上都有可能出错。比如发送流量过少,网络利用率不高,会导致应用程序性能下降。而发送过多流量会导致网络拥塞,最坏的情况下会导致拥塞崩溃。在这两种故障模式之间,发送过多流量通常会导致更严重的问题,并且由于重传丢失的数据包,拥塞会迅速加重。Tahoe、Reno和NewReno采用的AIMD方法反映了这一点: 缓慢增加窗口(线性增加),迅速减少窗口(指数减少),以便在拥塞崩溃变得过于严重之前从崩溃的边缘退回。但是在高带宽延迟环境中,探测拥塞时过于保守的代价是相当高的,因为在"流水线满"之前可能需要许多RTT。因此,这导致了对如何探测适当的窗口大小的一些反思。
一种被称为Binary Increase Congestion Control (BIC) 的新方法提出,窗口应该在某些时候快速打开,而在其他时候慢一些的想法。BIC并没有像TCP Reno那样突然的从指数窗口增长切换到线性窗口增长,而是对"正确"的窗口大小进行二分查找。在丢包之后,拥塞窗口以指数参数β截断。每次在新的窗口大小上成功发送报文,窗口就会增加到其当前值和造成拥塞的旧值的中点。通过这种方式,以先快后慢的速度逐渐接近旧值。(极端情况下,窗口将永远不会恢复到原来的值,类似于芝诺的悖论,但当达到某个阈值时,会被设置为原来的值)。
在这一点上,如果没有拥塞,可以得出结论,网络条件已经改变,可以探测新的拥塞窗口大小。BIC先慢一点,然后快一点。可以在图28中看到BIC增加窗口的大致形状,渐近接近 (最后一次丢包之前的旧拥塞窗口),然后超越它。
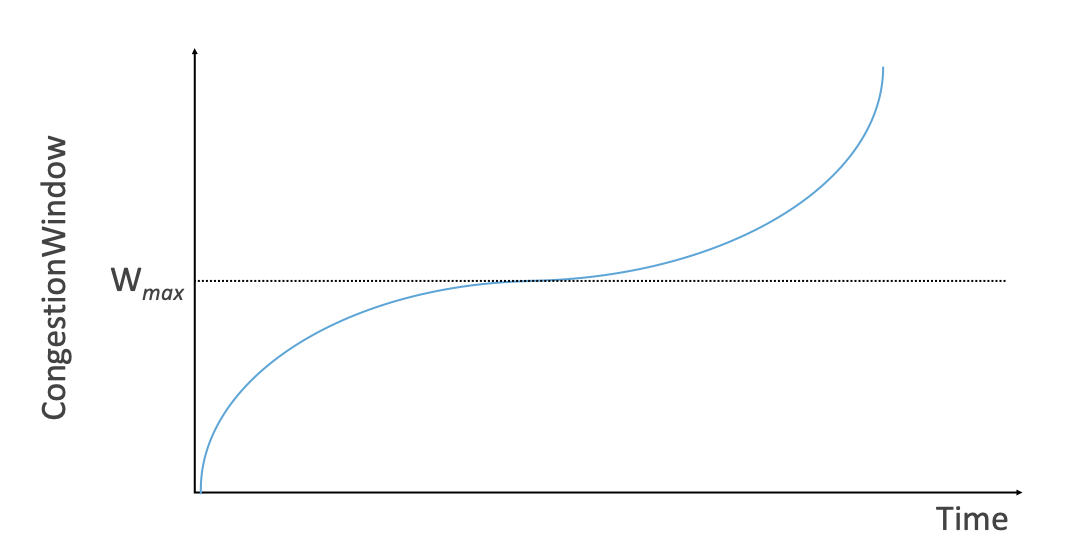
三次函数,如图28所示,有三个阶段: 缓慢增长,平台阶段,快速增长。在最后一次拥塞事件之前实现的最大拥塞窗口大小是初始目标(表示为 )。可以看到窗口一开始快速增长,但随着越来越靠近 ,增长越来越平缓,最后阶段开始探索新的可实现的 目标。
具体来说,CUBIC用自上次拥塞事件发生以来时间(t)的函数计算拥塞窗口(CongestionWindow)
其中,
C是一个比例常数,β是指数递减因子。CUBIC将后者设为0.7,而不是标准TCP使用的0.5。回头看看图28,CUBIC通常被描述为在凹函数和凸函数之间转换(而标准TCP的线性函数仅是凸函数)。
有趣的是,与TCP早期变体相比,CUBIC要么更激进,要么更不激进,这取决于具体条件。短RTT TCP Reno流往往能有效获取瓶颈带宽,因此CUBIC包含了一个"TCP友好"模式,其目标是像TCP Reno一样激进。但在其他情况下,尤其是高带宽延迟网络,CUBIC能够获得更大的瓶颈带宽份额,因为CUBIC可以更快增加窗口大小。这让我们想到3.3节的讨论,即对现有算法的"公平"是否是正确的设计目标。最后,对CUBIC进行了广泛的分析,在许多条件下均表现出良好的性能,且不会造成不适当的伤害,因此得到了广泛应用。
延伸阅读:
S. Ha, I. Rhee, and L. Xu. CUBIC: a New TCP-friendly High-speed TCP Variant[4]. ACM SIGOPS Operating Systems Review, July 2008.
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
TCP Congestion Control: A Systems Approach: https://tcpcc.systemsapproach.org/index.html
[2]RFC 6298: Computing TCP’s Retransmission Timer: https://tools.ietf.org/html/rfc6298
[3]Improving the start-up behavior of a congestion control scheme for TCP: https://dl.acm.org/doi/10.1145/248156.248180
[4]CUBIC: a New TCP-friendly High-speed TCP Variant: https://www.cs.princeton.edu/courses/archive/fall16/cos561/papers/Cubic08.pdf
本文由 mdnice 多平台发布