如果cudaDeviceEnablePeerAccess函数不支持或不起作用,您仍然可以尝试其他方法来实现GPU之间的数据交换和通信。以下是一些替代方法:
通过主机内存进行数据传输:
如果GPU之间的数据交换不是非常频繁,您可以将数据从一个GPU复制到主机内存,然后再从主机内存复制到另一个GPU。这可以通过cudaMemcpy函数来实现。
使用Unified Memory:
CUDA的Unified Memory允许多个GPU共享同一块内存。您可以在多个GPU之间创建统一内存分配,并在它们之间共享数据。这可以通过cudaMallocManaged函数来实现。请注意,这种方法可能会引入一些性能开销。
使用NvLink:
如果您的GPU之间支持NvLink连接,您可以通过NvLink通道进行高速数据传输。NvLink是一种高速连接技术,适用于支持的NVIDIA GPU。它通常用于连接同一台服务器上的多个GPU。
使用MPI(Message Passing Interface):
如果您的系统中有多个计算节点,您可以使用MPI库来在不同的计算节点之间进行数据传输和通信。这对于在分布式系统中进行大规模并行计算非常有用。
使用CUDA库:
NVIDIA提供了一些用于GPU之间数据交换的库,如NCCL(NVIDIA Collective Communications Library)。这些库专门用于在多个GPU之间实现高效的数据交换和通信。
使用 Inter-Process Communication (IPC): 如果你的 GPUs 位于不同的进程中,你可以使用 Inter-Process Communication(IPC)机制来实现 GPU 之间的数据交换。CUDA 提供了 IPC 功能,允许不同进程中的 CUDA 上下文之间进行数据传输
Unified Memory
__global__ void initializeData(float* data, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
data[idx] = static_cast<float>(idx); // Initialize data with some values
}
}
float* unifiedData;
cudaMallocManaged(&unifiedData, totalSize * sizeof(float));
// Initialize data on all GPUs using Unified Memory
for (int gpuId = 0; gpuId < NUM_GPUS; ++gpuId) {
cudaSetDevice(gpuId);
initializeData<<<gridDims, blockDims>>>(unifiedData + gpuId * chunkSize, chunkSize);
}
使用CUDA进行并行计算和数据初始化。你先定义了一个名为initializeData的CUDA内核函数,然后使用Unified Memory在多个GPU上初始化数据。
-
initializeData内核函数:这个内核函数用于在每个线程块中初始化一部分数据。idx表示线程在数据中的索引,根据线程块和线程的索引计算出。只有当idx小于要初始化的数据大小时,线程会将其索引值转化为浮点数并赋值给数据数组中的相应位置。 -
cudaMallocManaged:使用 cudaMallocManaged 分配的统一内存数组,用于在多个GPU上共享数据。unifiedData将指向这块分配的内存,其大小为totalSize * sizeof(float)字节。 -
数据初始化循环:在这个循环中,你使用了多个GPU来执行初始化任务。通过使用
cudaSetDevice函数来指定每个GPU,并在每个GPU上使用initializeData内核函数来初始化数据。unifiedData + gpuId * chunkSize是将数组指针定位到每个GPU对应的位置,以便在统一内存中进行初始化
为了确保在所有GPU上都初始化数据完成,循环结束后使用cudaDeviceSynchronize来同步所有的GPU。
注意事项:
- 在使用CUDA进行并行计算时,确保你在代码中正确地处理内存分配、数据传输和同步操作,以避免出现内存泄漏、数据不一致等问题。
- 在实际应用中,还需要定义和初始化一些
NUM_GPUS、gridDims、blockDims、totalSize、chunkSize等。 -
下载 Linux 和 Unix 版本
在 Linux 上安装 Git 最简单的方法是使用 Linux 发行版的首选软件包管理器。如果你喜欢从源代码构建,可以在 kernel.org 上找到压缩包。最新版本为 2.41.0。
Debian/Ubuntu
获取您的 Debian/Ubuntu 发行版的最新稳定版本
# apt-get install git
对于 Ubuntu,该 PPA 提供最新稳定的上游 Git 版本
# add-apt-repository ppa:git-core/ppa # apt update; apt install git
Fedora
# yum install git(至 Fedora 21)
# dnf install git(Fedora 22 及更高版本)
Gentoo
# emerge --ask --verbose dev-vcs/git
Arch Linux
# pacman -S git
openSUSE
# zypper install git
玛吉娅
# urpmi git
尼克斯/尼克斯操作系统
nix-env -i git
FreeBSD
pkg install git
Solaris 9/10/11 (OpenCSW)
pkgutil -i git
Solaris 11 Express
pkg install developer/versioning/git
OpenBSD
pkg_add git
阿尔卑斯
$ apk add git
Red Hat Enterprise Linux、Oracle Linux、CentOS、Scientific Linux 等。
RHEL 及其衍生版本通常会提供旧版本的 git。你可以下载一个压缩包并从源代码开始构建,或者使用第三方软件源(如 IUS Community Project)来获取较新版本的 git。

要在 VS Code 中设置 CUDA 代码的调试,请按照以下步骤操作:
安装 CUDA 工具包和 VS Code:
确保您的 Ubuntu 22.04 系统上安装了 CUDA Toolkit 和 Visual Studio Code。
打开您的项目文件夹:
在 VS Code 中打开 CUDA 项目的根目录。
安装所需的扩展:
如果尚未安装,请在 VS Code 中安装 CUDA 调试所需的扩展:
微软的“C/C++”
NVIDIA 的“CUDA”
创建launch.json:
要生成用于调试 CUDA 代码的 launch.json 文件,请执行以下步骤:
单击窗口一侧活动栏中的“运行和调试”按钮(或按 F5)。
选择“创建 launch.json 文件”选项。
选择“CUDA C++ (CUDA-GDB)”作为环境。
配置launch.json:
选择环境后,会在项目的.vscode目录下生成launch.json文件。 您可以根据需要修改 launch.json 文件以匹配您的设置。 这是一个配置示例:
{
"version": "0.2.0",
"configurations": [
{
"name": "CUDA Debug",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/path/to/your/executable", // Path to your compiled CUDA executable
"args": [], // Command line arguments if any
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": false,
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for CUDA",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"miDebuggerPath": "/usr/local/cuda/bin/cuda-gdb" // Path to cuda-gdb executable
}
]
}
设置断点:
打开需要调试的CUDA源文件,根据需要设置断点。
开始调试:
再次单击“运行和调试”按钮(或按 F5)。
选择“CUDA 调试”配置。
调试器将启动,执行将在断点处停止。
launch.json文件的内容
{
"version": "0.2.0",
"configurations": [
{
"name": "CUDA C++ Launch",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/p2p", // 修正为 ${workspaceFolder}
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}" // 修正为 ${workspaceFolder}
}
]
}
https://blog.csdn.net/wohu1104/article/details/111464778
https://blog.csdn.net/weixin_42145502/article/details/107455999

用cuda c++(cuda dgb) 打断点
我的是打完断点不停,直接输出了,按着下面的步骤操作可以进行正常的打断点
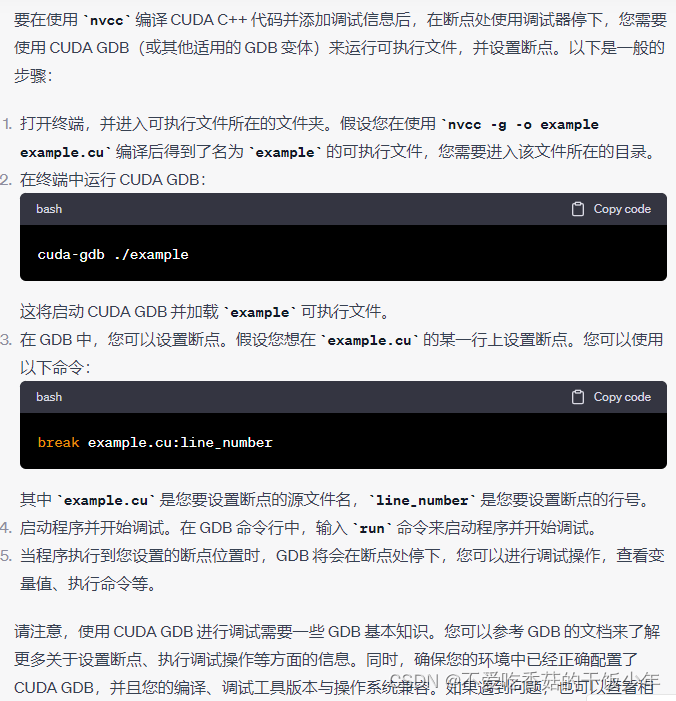
# user@user-SYS-420GP-TNR:~/lcr/try$ nvcc -g -o example example.cu
# user@user-SYS-420GP-TNR:~/lcr/try$ cuda-gdb ./example
# 输出
NVIDIA (R) CUDA Debugger
11.5 release
Portions Copyright (C) 2007-2021 NVIDIA Corporation
GNU gdb (GDB) 10.1
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
--Type <RET> for more, q to quit, c to continue without paging--
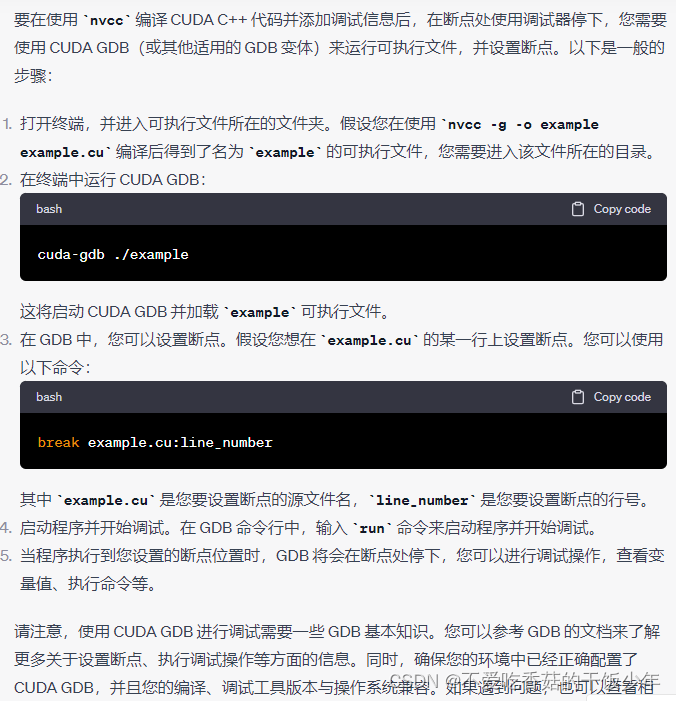
# user@user-SYS-420GP-TNR:~/lcr/try$ nvcc -g -o example example.cu
# user@user-SYS-420GP-TNR:~/lcr/try$ cuda-gdb ./example
# 输出
NVIDIA (R) CUDA Debugger
11.5 release
Portions Copyright (C) 2007-2021 NVIDIA Corporation
GNU gdb (GDB) 10.1
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
--Type <RET> for more, q to quit, c to continue without paging--
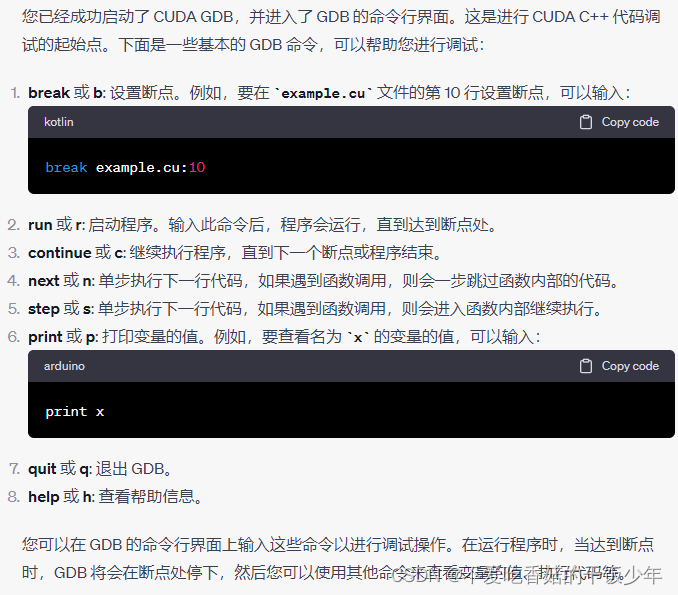
# user@user-SYS-420GP-TNR:~/lcr/try$ cuda-gdb ./example
# 输出
NVIDIA (R) CUDA Debugger
11.5 release
Portions Copyright (C) 2007-2021 NVIDIA Corporation
GNU gdb (GDB) 10.1
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<https://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
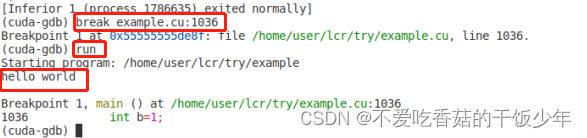
--Type <RET> for more, q to quit, c to continue without paging--break example.cu:1034
Type "apropos word" to search for commands related to "word"...
Reading symbols from ./example...
(cuda-gdb)
(cuda-gdb) run
Starting program: /home/user/lcr/try/example
hello world
1,1
[Inferior 1 (process 1786635) exited normally]
(cuda-gdb
在您的 CUDA GDB 会话中,看起来您已经成功地设置了断点并启动了程序。根据您提供的输出,程序似乎已经在断点处停下,并成功执行了打印语句。
在输出中,“hello world” 是您的程序输出的信息。然后,您可以看到调试器显示的行号是 1,1,这可能是因为 CUDA GDB 在 GPU 核心执行 CUDA 代码时可能不会显示准确的行号信息。