一、SQL窗口函数
1.是什么
OLAP(Online Anallytical Processing联机分析处理),对数据库数据进行实时分析处理。
2.基本语法:
- <窗口函数>OVER (PARTITION BY <用于分组的列名>
ORDER BY <用于排序的列名>)
注:
<窗口函数>都有哪些:
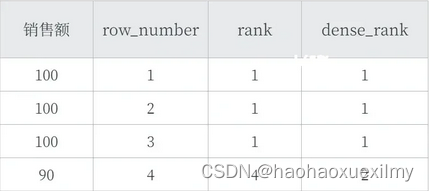
1.专用窗口函数:rank(相等的值排名相同,计数)、dense_rank(相等的值排名相同,不计数)、row_number(对相等的值不进行区分)、first_value(用于获取在分组内的第一个值)、last_value、lead(用于在查询结果集中访问当前行之后的行的数据)、lag(在查询结果集中访问当前行之前的行的数据)等
SELECT
order_id,
customer_name,
order_amount,
order_amount - LAG(order_amount) OVER (ORDER BY order_id) AS previous_order_difference
FROM orders;
2.聚合窗口函数:count, sum, avg, max, min等,除count,其他聚合函数忽略NULL。
- PARTITION BY:类似于聚合函数中的GROUP BY子句,但是在窗口函数中,要写成PARTITION BY
- ORDER BY:和普通查询语句中的ORDER BY没什么不同
3. 窗口函数和聚合函数的区别
1.用OVER关键字区分窗口函数和聚合函数。
2.聚合函数每组只返回一个值,窗口函数每组可返回多个值。
4.注意事项
1.原则上只能写在SELECT子句中,因为窗口函数是对WHERE或者GROUP BY子句处理后的结果进行操作。over()里的分组以及排序的执行,晚于where、group by、order by的执行。
2.常见主流数据库目前都支持窗口函数。
3.partition子句原则上可省略,但这就失去了窗口函数的意义。
5.为什么要用
group by分组汇总后改变了表的行数,一行只有一个类别。而partition by和rank函数不会减少原表中的行数。
窗口函数表示“范围”的意思,partition by分组后的结果。
二、A/B test
1. 原理
核心:假设检验。检验实验组和对照组的指标是否有显著性差异。
先做出假设,然后获取数据,最后根据数据来进行检验。
假设:
零假设:实验组 & 对照组:指标相同,无显著差异
备择假设:实验组 & 对照组: 指标不同,有显著差异
检验:根据指标的属性以及样本量的大小选择合适的检验方法。常用的检验方法有Z检验、t检验、卡方检验和F检验。
- t检验:总体正态分布、总体方差未知或独立小样本平均数的显著性检验、平均数差异显著性检验。
- Z检验:总体正态分布、总体方差已知或独立大样本平均数的显著性检验、平均数差异显著性检验。
- 卡方检验:检验实验组是否服从理论分布(将对照组看成理论分布)。
2. 流程
1.确定实验目标
评价指标和护栏指标
评价指标是驱动公司实现核心价值的指标,要具有可归因性、可测量性、敏感性和稳定性;
护栏指标也就是辅助指标。
评价指标重点关注一个目标,护栏指标可以选择多个作为辅助,避免达成一个目标造成别的利益的损失。
比如:要提升广告收入,我们在页面部分多插入一条或多条广告,虽然短期内是提高了收入,但是长期以来用户体验就会变差,造成用户反感继而流失。
2.设计实验:
- 建立假设:建立零假设和备选假设,零假设一般是没有效果,备择假设是有效果。
- 选取实验单位:有以下三种,常用用户粒度。
用户粒度:以一个用户的唯一标识来作为实验样本。好处是符合A/B实验的分桶单位唯一性,不会造成一个实验单位处于两个分桶,造成的数据不置信。
设备粒度:以一个设备标识为实验单位。相比用户粒度,如果一个用户有两个手机,那么也可能出现一个用户在两个分桶中的情况,所以会造成数据不置信。
行为粒度:以一次行为为实验单位,也就是用户某一次使用该功能,实验桶,下一次使用可能就被切换为基线桶,会造成大量的用户处于不同的分桶。不推荐。
- 计算样本量:很重要
太小:实验结果不会可信
太大:影响面越大。负面影响,流量和资源的浪费。
- 流量分配:分流(指直接将整体用户切割为几块,用户只能在一个实验中,不会相互影响。实验之间是互斥的)和分层(指将同一批用户,不停地随机后,处于不同的桶种。同一用户属于多个不同的实验,且相互之间不影响,企业中常用)
- 计算试验周期