Fisherfaces 人脸识别
PCA 方法是 EigenFaces 方法的核心,它找到了最大化数据总方差特征的线性组合。不可否认,EigenFaces
是一种非常有效的方法,但是它的缺点在于在操作过程中会损失许多特征信息。
因此,在一些情况下,如果损失的信息正好是用于分类的关键信息,必然会导致无法完成分类。Fisherfaces 采用 LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。线性判别识别最早由 Fisher 在 1936 年提出,是一种经典的线性学习方法,也被称为“Fisher 判别分析法”。
基本原理
线性判别分析在对特征降维的同时考虑类别信息。其思路是:在低维表示下,相同的类应该紧密地聚集在一起;不同的类别应该尽可能地分散开,并且它们之间的距离尽可能地远。简单地说,线性判别分析就是要尽力满足以下两个要求:
- 类别间的差别尽可能地大。
- 类别内的差别尽可能地小。
做线性判别分析时,首先将训练样本集投影到一条直线 A 上,让投影后的点满足:
- 同类间的点尽可能地靠近。
- 异类间的点尽可能地远离。
做完投影后,将待测样本投影到直线 A 上,根据投影点的位置判定样本的类别,就完成了识别。
例如,图 23-13 所示的是一组训练样本集。现在需要找到一条直线,让所有的训练样本满足:同类间的距离最近,异类间的距离最远。

图 23-14 的左图和右图中分别有两条不同的投影线 L1 和 L2,将图 23-13 中的样本分别投影到这两条线上,可以看到样本集在 L2 上的投影效果要好于在 L1 上的投影效果。
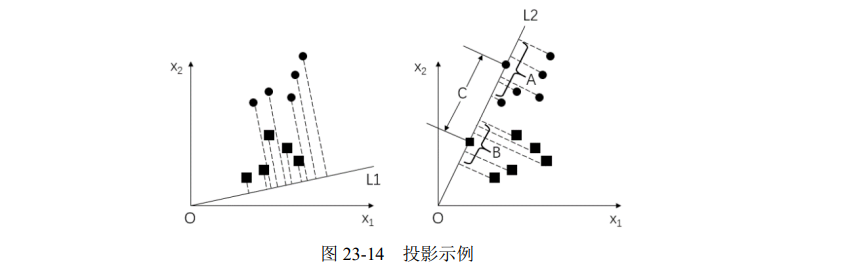
线性判别分析就是要找到一条最优的投影线。以图 23-14 中右图投影为例,要满足:
- A、B 组内的点之间尽可能地靠近
- C 的两个端点之间的距离(类间距离)尽可能地远
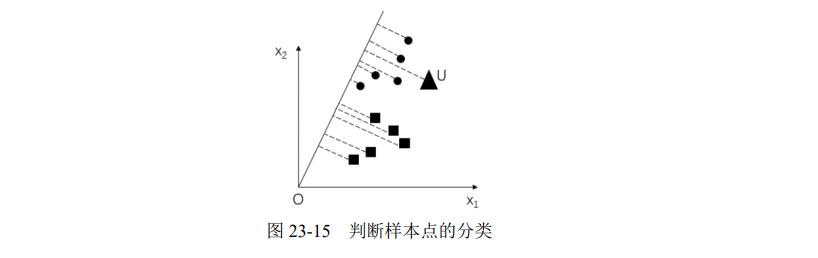
找到一条这样的直线后,如果要判断某个待测样本的分组,可以直接将该样本点向投影线投影,然后根据投影点的位置来判断其所属类别。
例如,在图 23-15 中,三角形样本点 U 向投影线投影后,其投影点落在圆点的投影范围内,则认为待测样本点 U 属于圆点所在的分类。
函数介绍
OpenCV 中,通过函数 cv2.face.FisherFaceRecognizer_create()生成 Fisherfaces 识别器实例模型,然后应用 cv2.face_FaceRecognizer.train()函数完成训练,用 cv2.face_FaceRecognizer.predict()函数完成人脸识别。
- 函数cv2.face.FisherFaceRecognizer_create()
函数 cv2.face.FisherFaceRecognizer_create()的语法格式为:
retval = cv2.face.FisherFaceRecognizer_create( [, num_components[,
threshold]] )
式中的两个参数都是可选参数,它们的含义为:
- num_components:使用 Fisherfaces 准则进行线性判别分析时保留的成分数量。可以采用默认值“0”,让函数自动设置合适的成分数量。
- threshold:进行识别时所用的阈值。如果最近的距离比设定的阈值 threshold 还要大,函数会返回“-1”。
- 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像进行 Fisherfaces 计算,得到一个向量。
每个人脸都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
式中各个参数的含义为:
- src:训练图像,即用来学习的人脸图像。
- labels:人脸图像所对应的标签。
该函数没有返回值。
- 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()在对一个待测人脸图像进行判断时,寻找与其距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。该函数的语法格式为:
label, confidence = cv2.face_FaceRecognizer.predict( src )
式中的参数与返回值的含义为:
- src:需要识别的人脸图像。
- label:返回的识别结果的标签。
- confidence:置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0 表示完全匹配。该值通常在 0 到 20 000 之间,若低于 5000,就认为是相当可靠的识别结果。需要注意,该评分值的范围与 EigenFaces 方法的评分值范围一致,与 LBPH 方法的评分值范围不一致。
示例:使用 FisherFaces 完成一个简单的人脸识别程序
import cv2
import numpy as np
images=[]
img1= cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE);
img1.resize((240,240))
images.append(img1)
img2= cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE);
img2.resize((240,240))
images.append(img2)
img3= cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE);
img3.resize((240,240))
images.append(img3)
img4= cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE);
img4.resize((240,240))
images.append(img4)
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.FisherFaceRecognizer_create()
recognizer.train(images, np.array(labels)) # 识别器训练
predict_image=cv2.imread("face\\face6.png",cv2.IMREAD_GRAYSCALE)
predict_image.resize((240,240))
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
运行结果:
label= 0
confidence= 1034.0276952694567
从结果中可以看出,他的准确度又比EigenFaces 人脸识别对比的化准确多了。
常见的OpenCV人脸算法以及它们的对比
Haar Cascade人脸检测(查找):
Haar Cascade是一种传统的人脸检测算法,它基于特征的级联分类器。尽管速度较快,但对于一些角度、光照和遮挡变化较大的情况,可能表现不够稳定和准确。
Dlib人脸检测和识别:
Dlib库提供了基于HOG特征的人脸检测和深度学习的人脸识别。Dlib在不同角度和轻微遮挡下有良好的检测性能。它还可以进行人脸特征点检测,如眼睛、嘴巴等。
深度学习模型:(后续讲解)
OpenCV也集成了一些深度学习模型用于人脸检测和识别,如基于CNN的人脸检测器和基于深度学习的人脸识别算法。这些模型通常在大规模数据集上进行了训练,具有更高的准确性,但可能需要更多的计算资源。
LBPH人脸识别:(应用少)
局部二值模式直方图(LBPH)是一种基于纹理的人脸识别算法,适用于小规模数据库。它不需要大量的训练数据,但在复杂场景下可能性能较差。
Eigenfaces和Fisherfaces:
Eigenfaces和Fisherfaces是基于PCA和LDA的经典人脸识别算法。它们在某些情况下可能表现出色,但在复杂环境中可能不如深度学习模型。
在选择OpenCV人脸算法时,需要考虑以下因素:
准确性: 算法的准确性是否满足你的应用需求?
速度: 算法的执行速度是否足够快?
复杂度: 算法的实现和使用是否容易?
数据规模: 你的数据集是大还是小?
场景: 你的应用场景中是否有遮挡、光照变化等因素?
一般来说,对于复杂的人脸检测和识别问题,深度学习模型可能会更加准确,但也需要更多的计算资源。对于一些简单的应用,传统的方法如Haar Cascade或Dlib可能已经足够。选择适合自己应用的算法需要根据具体情况进行权衡和评估。









![[JavaWeb]【八】web后端开发-Mybatis](https://img-blog.csdnimg.cn/7fd0499f84594fa4b9682a5e31397490.png)