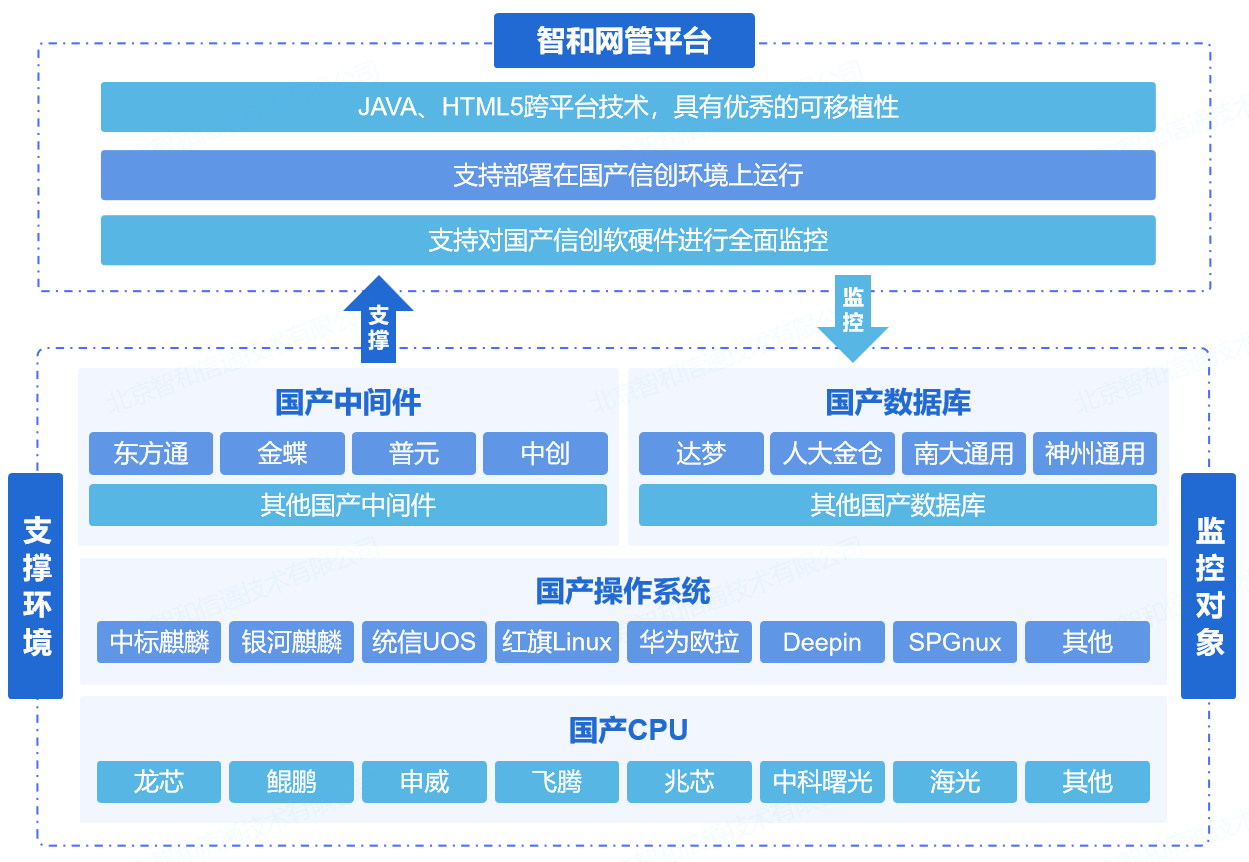
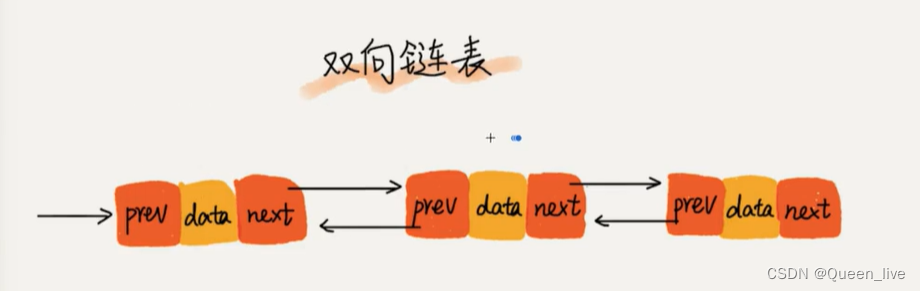
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems Approach》的中文版,完整介绍了拥塞控制的概念、原理、算法和实现方式。原文: TCP Congestion Control: A Systems Approach[1]

第6章 主动队列管理(Active Queue Management)
现在我们来看看路由器在拥塞控制中扮演的角色,这种方法通常被称为主动队列管理(AQM, Active Queue Management) 。就其本质而言,AQM引入了一个避免端到端解决方案的元素,即使与TCP Reno等基于控制的方法配合也能发挥作用。
尽管对路由器行为的改变从来不是互联网引入新功能的首选方式,但在过去30年里,这种方法始终令人感到紧张。问题在于,虽然人们普遍认为路由器处于检测拥塞开始的理想位置(即队列开始被填满),但对于什么才是最佳算法并没有达成一致意见。下面介绍了两种经典机制,并简要讨论了目前的情况。
6.1 DECbit
第一种机制是为数字网络体系架构(DNA, Digital Network Architecture)开发的,它是TCP/IP互联网的早期竞争者,也采用了无连接/尽力而为网络模型,由K.K. Ramakrishnan和Raj Jain共同发明,和Jacobson/Karels的论文同时发表在1988年的SIGCOMM会议。
延伸阅读:
K.K. Ramakrishnan and R. Jain. A Binary Feedback Scheme for Congestion Avoidance in Computer Networks with a Connectionless Network Layer[2]. ACM SIGCOMM, August 1988.
其想法是在路由器和终端主机之间更均匀的分担拥塞控制的责任。每个路由器监控正在处理的负载,并在拥塞即将发生时显式通知终端节点。这个通知是通过在流经路由器的数据包中设置一个二进制拥塞位来实现的,这个二进制拥塞位后来被称为DECbit。然后,目标主机将这个拥塞位复制到ACK中返回给发送端。最后,发送端通过调整发送速率避免拥塞。下面将从路由器开始详细的介绍该算法。
在包报头中增加一个拥塞位,如果数据包到达时,路由器的平均队列长度大于或等于1,则设置此位。平均队列长度是在跨越上一个繁忙/空闲周期,再加上当前繁忙周期的时间间隔内测量的。(路由器忙指的是正在传输数据,空闲指的是没有传输数据。) 图34显示了路由器上的队列长度随时间的变化。实际上,路由器将计算曲线下的面积,并将该值除以时间间隔来计算平均队列长度。使用队列长度为1作为设置拥塞位的触发器是在有大量排队(从而吞吐量较高)和大量空闲时间(从而延迟较低)之间的权衡。换句话说,长度为1的队列似乎优化了幂函数。
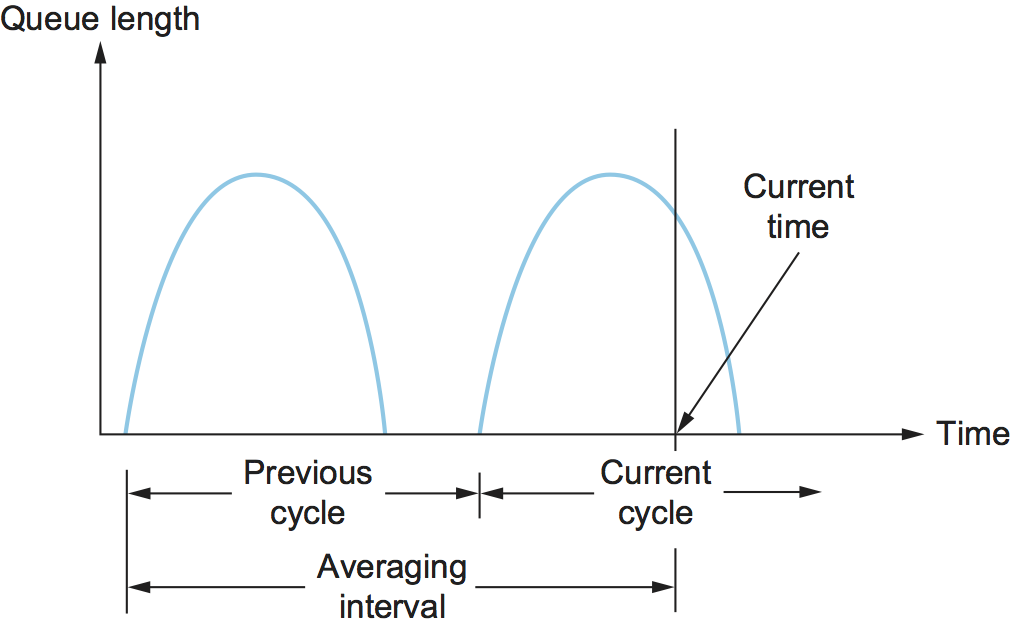
现在我们把注意力转移到该机制与主机相关的部分,发送端记录有多少包导致路由器设置了拥塞位,就像在TCP中一样维护了一个拥塞窗口,并观察最后一个窗口的数据包值中有多少导致拥塞位被设置。如果少于50%的包设置了拥塞位,则发送端的拥塞窗口就增加一个包。如果上一个窗口值的50%或更多的包设置了拥塞位,则发送端的拥塞窗口减小到前一个值的0.875倍。经过分析,选择50%作为阈值,与幂曲线的峰值相对应。之所以选择"增加1,减少0.875"规则,是因为线性增加/指数减少使机制更稳定。
6.2 随机早期检测(Random Early Detection)
第二种机制被称为随机早期检测(RED, Random Early Detection) ,类似于DECbit方案,每个路由器都被编程来监控自己的队列长度,当检测到拥塞即将发生时,通知发送端调整拥塞窗口。RED是由Sally Floyd和Van Jacobson在20世纪90年代早期发明的,与DECbit方案的不同之处在于以下两点。
延伸阅读:
S. Floyd and V. Jacobson Random Early Detection (RED) Gateways for Congestion Avoidance[3]. IEEE/ACM Transactions on Networking. August 1993.
首先,RED并不向发送端显示发送拥塞通知消息,而是丢弃一个包,通过后续的超时或重复ACK来隐式通知发送端。也许你会猜到,RED被设计成与TCP一起使用,TCP目前就是通过超时(或其他检测丢包的方法,比如重复ACK)来检测拥塞。正如RED首字母缩写的"早期"所暗示的那样,网关必须在不得不丢弃数据包之前丢弃数据包,以便通知发送端比正常情况下更早的减少拥塞窗口。换句话说,路由器在缓冲区空间完全耗尽之前通过丢弃部分数据包,从而使得发送端速度变慢,避免今后丢弃大量数据包。
RED和DECbit的第二个区别在于RED如何决定何时丢弃一个包以及丢弃什么包。为了理解基本思想,考虑一个简单的FIFO队列,与其等待队列完全填满,然后被迫丢弃每个到达的包(在第2.1.3节中描述的尾丢弃策略),我们可以决定在队列长度超过某个丢弃级别(drop level) 时,以一定的概率丢弃到达的包,这一理念被称为早期随机丢包(early random drop) 。RED算法定义了如何监控队列长度以及何时丢包的细节。
下面我们将介绍由Floyd和Jacobson最初提出的RED算法。我们注意到,发明者和其他研究人员已经提出了一些修改意见,然而,关键思想仍然与下面介绍的一样,而且当前大多数实现都接近下面的算法。
首先,RED使用与原始TCP超时计算中使用的加权运行平均值来计算平均队列长度,即AvgLen为
其中0 < Weight < 1, SampleLen为采样测量时的队列长度。在大多数软件实现中,每次有新数据包到达网关时都测量队列长度,在硬件中,可以以某个固定的采样间隔进行计算。
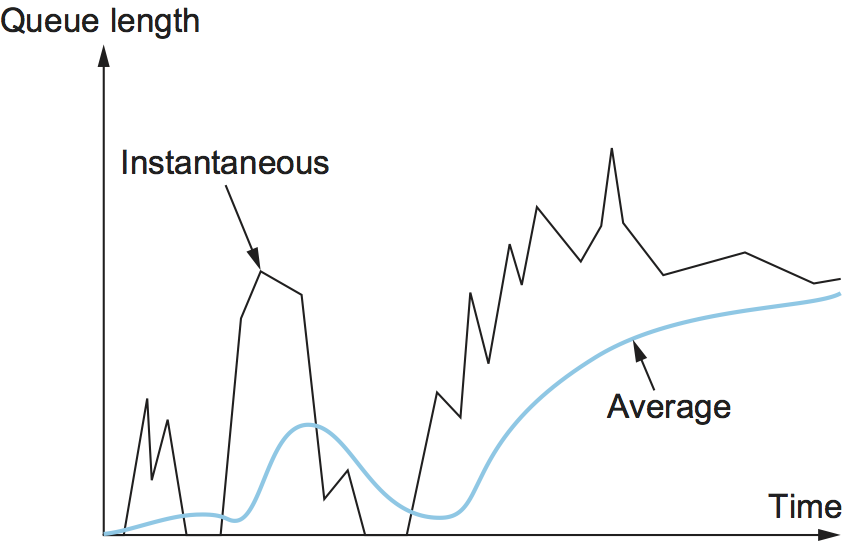
使用平均队列长度而不是瞬时队列长度的原因是它能够更准确的体现拥塞。由于互联网流量的爆发式特性,队列可能很快被塞满,然后又快速被清空。如果一个队列大部分时间都是空的,那么就不应该认为发生了拥塞。因此,加权运行平均计算试图通过过滤掉队列长度的短期变化来检测长期拥塞,如图35的右边部分所示。可以把运行平均值想象成低通滤波器,其中Weight决定滤波器的时间常数,如何选择这个时间常数的问题将在下面讨论。
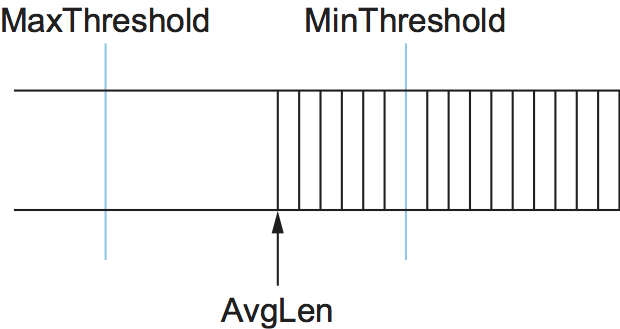
其次,RED有两个触发特定活动的队列长度阈值: MinThreshold和MaxThreshold。当报文到达网关时,RED将当前AvgLen与这两个阈值按照如下规则进行比较:
if AvgLen <= MinThreshold
queue the packet
if MinThreshold < AvgLen < MaxThreshold
calculate probability P
drop the arriving packet with probability P
if MaxThreshold <= AvgLen
drop the arriving packet
如果平均队列长度小于下限阈值,则不采取任何措施;如果平均队列长度大于上限阈值,则始终丢弃报文。如果平均队列长度在两个阈值之间,那么新到达的数据包以一定的概率P被丢弃,如图36所示。P与AvgLen的近似关系如图37所示。注意,当AvgLen处于两个阈值之间时,丢包概率会缓慢增加,在上限达到MaxP时,就会丢弃所有包。这背后的基本原理是,如果AvgLen达到了上阈值,那么温和的方法(丢弃一些包)就不起作用,需要采取严厉的措施,即丢弃所有到达的包。这里介绍的方法是从随机丢包直接跳跃到完全丢包,不过一些研究表明,从随机丢包平稳过渡到完全丢包可能更合适。
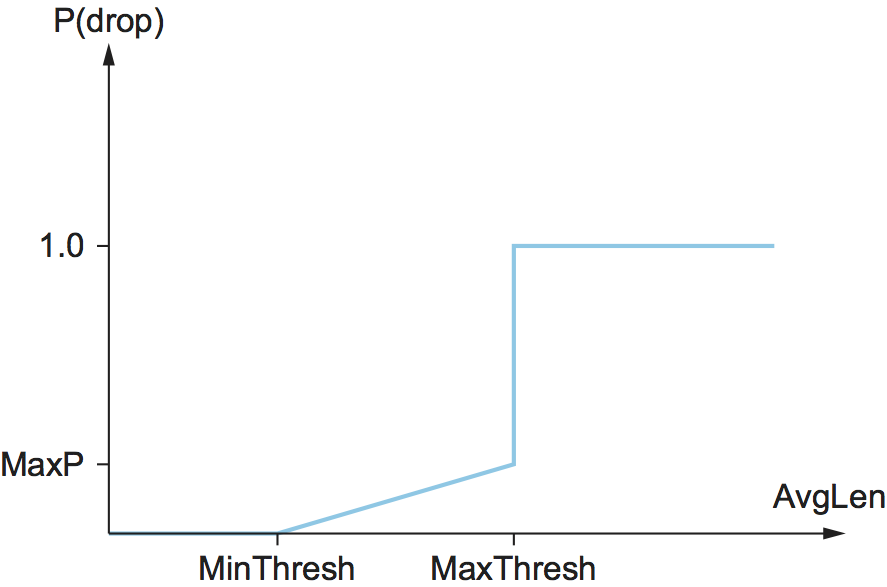
尽管图37显示的丢包概率只是AvgLen的一个函数,但实际情况要复杂一些。实际上,P是AvgLen以及最后一个丢包到现在的时间的函数。具体计算方法如下:
TempP是在图37中y轴上的变量,count计算排队(没有被丢弃)的新包,AvgLen位于两个阈值之间。P随着count的增加而缓慢增加,因此距离上一次丢包的时间越长,发生丢包的可能性就越来越大。这使得频繁丢包的可能性比间隔较长时间丢包的可能性更低。这个计算P的额外步骤是由RED的发明者引入的,他们观察到,如果没有这一参数,丢包就不能均匀分布,而是倾向于在集中发生。由于某个连接的数据包很可能是突然到达的,这种集中丢包很可能造成单个连接丢弃大量包,而这并不可取。每次往返时间发生一次丢包就足以导致连接减少窗口大小,而多次丢包可能会导致发送端切换到慢启动。
举个例子,假设我们将MaxP设置为0.02,count初始化为0。如果平均队列长度在两个阈值中间,那么TempP和P的初始值将是MaxP的一半,即0.01,意味着此时到达的数据包有99%的机会进入队列。随着每收到一个没有被丢弃的连续数据包,P会慢慢增加,当50个没有丢弃的数据包到达时,P会翻倍到0.02。虽然不太可能,但如果99个包都到达而没有丢包,P将变为1,从而保证下一个包一定会被丢弃。这部分算法的重要之处在于,可以确保随着时间的推移,丢包的分布大致均匀。
其目的是,当AvgLen超过MinThreshold时,如果RED丢弃一小部分数据包,导致某些TCP连接减少窗口大小,从而减少数据包到达路由器的速率。一切顺利的话,AvgLen将会变小,从而避免拥塞。这样可以保持较短的队列长度,同时维持较高的吞吐量。
注意,因为RED操作的是随时间变化的平均队列长度,所以瞬时队列长度可能比AvgLen长得多。在这种情况下,如果收到了一个包,但没有地方放它,那将不得不丢弃。当这种情况发生时,RED的行为和尾丢包模式一致。RED的目标之一是,在可能的条件下尽量避免尾丢包行为。
RED的随机性赋予了算法一个有趣的特性。因为RED是随机丢包的,所以决定丢弃特定流的包的概率大致与流在当前路由器上获得的带宽份额成正比。这是因为发送相对较多的包的流为随机丢弃提供了更多的候选者。因此,尽管并不精确,但RED具有某种公平的资源分配策略。虽然可以说是公平的,但因为RED对高带宽流的影响大于对低带宽流的影响,这增加了TCP重启的可能性,从而有可能对高带宽流造成额外的影响。
为了优化幂函数(吞吐量-延迟比),我们对各种RED参数进行了大量分析,例如MaxThreshold、MinThreshold、MaxP和Weight,通过仿真验证了这些参数的性能,结果表明算法对这些参数不太敏感。但是,所有这些分析和模拟都取决于网络工作负载的特定表征。RED的真正贡献是提出了一种路由器可以更准确管理其队列长度的机制,而对于不同的流量组合的最优排队长度还是一个正在研究的课题。
考虑两个阈值MinThreshold和MaxThreshold的设置。如果流量相当大,那么MinThreshold应该足够大,以允许链路利用率保持一个可接受的高水平。此外,两个阈值之间的差值应该大于一个RTT中计算的平均队列长度的典型增长值。对于今天的互联网流量模型来说,将MaxThreshold设置为MinThreshold的两倍似乎比较合理。此外,由于我们期望平均队列长度在高负载期间可以在两个阈值之间波动,因此在MaxThreshold之上应该有足够的空闲缓冲区空间来吸收突发的互联网流量,避免路由器被迫进入尾丢包模式。
上面提到Weight决定了运行平均低通滤波器的时间常数,从而为如何选择合适的Weight值提供了线索。回想一下,RED试图在拥塞期间通过丢包向TCP流发送信号。假设路由器丢弃了来自某个TCP连接的数据包,然后立即转发来自同一连接的更多数据包。当这些包到达接收端时,开始向发送端发送重复的ACK。当发送端看到足够多的重复ACK时,将减少窗口大小。因此,路由器从丢弃一个数据包直到开始看到受影响连接的窗口大小有所减少,该连接至少需要一个往返时间。如果路由器对拥塞的响应时间比连接往返时间短得多,可能没有多大意义。正如前面提到的,100ms是对互联网平均往返时间的一个不错的估算。因此,Weight的选择应该能够过滤掉小于100ms的队列长度变化。
由于RED通过向TCP流发送信号来通知它们减速,你可能想知道如果忽略这些信号会发生什么,这通常被称为无响应流(unresponsive flow) 问题。无响应流使用的网络资源超过了公平的份额,就像没有TCP拥塞控制那样,如果有很多无响应流,可能会导致拥塞崩溃。一些排队技术,如加权公平排队,可以通过隔离某些类别的流量来帮助解决这个问题。还有一些讨论考虑创建RED的变体,对于无响应流丢弃更多的包。然而,挑战性在于,很难区分非响应行为和"正确"行为,特别是当流具有各种不同的RTT和瓶颈带宽时。
作为一个注脚,15位著名的网络研究人员在1998年敦促广泛采用受RED启发的AQM。这一建议在很大程度上被忽略了,原因我们将在下文谈到。然而,基于RED的AQM方法已经在数据中心得到了一些成功的应用。
延伸阅读:
R. Braden, et al. Recommendations on Queue Management and Congestion Avoidance in the Internet[4]. RFC 2309, April 1998.
6.3 可控延迟(Controlled Delay)
如上一节所述,RED从未被广泛采用,当然,也从来没有达到对互联网拥塞产生重大影响的必要水平。一个原因是,RED很难以一种增量的方式进行配置。影响其操作的参数有很多(MinThreshold、MaxThreshold、Weight),有足够的研究表明,RED会根据流量类型和参数设置产生不同的结果(并非所有结果都是有益的),这就造成了对RED的部署有不确定性。
在过去一段时间里,Van Jacobson(因其在TCP拥塞方面的工作和最初的RED论文的合著者而闻名)与Kathy Nichols和其他研究人员合作,最终提出了一种改进RED的AQM方法。这项工作被称为CoDel(发音为coddle)控制延迟(Controlled Delay) AQM,其基础建立对TCP和AQM几十年研究经验的关键见解上。
延伸阅读:
K. Nichols and V. Jacobson. Controlling Queue Delay[5]. ACM Queue, 10(5), May 2012.
首先,队列是网络的重要组成部分,网络中时不时的就会有队列堆积。例如,新打开的连接可能会将一个窗口的数据包发送到网络中,可能会在瓶颈链路处形成队列。这本身不是问题,网络应该有足够的缓冲能力来吸收这样的突发流量。但如果没有足够的缓冲能力时,就会出现问题,导致过量丢包。在20世纪90年代,这被理解为一种需求,即缓冲区至少能够保存一个带宽时延积的包,这一要求可能太大了,随后受到进一步研究的质疑。但事实是,用来吸收突发流量的缓冲区是必要的。CoDel的作者将其称为"好队列",如图38 (a)所示。
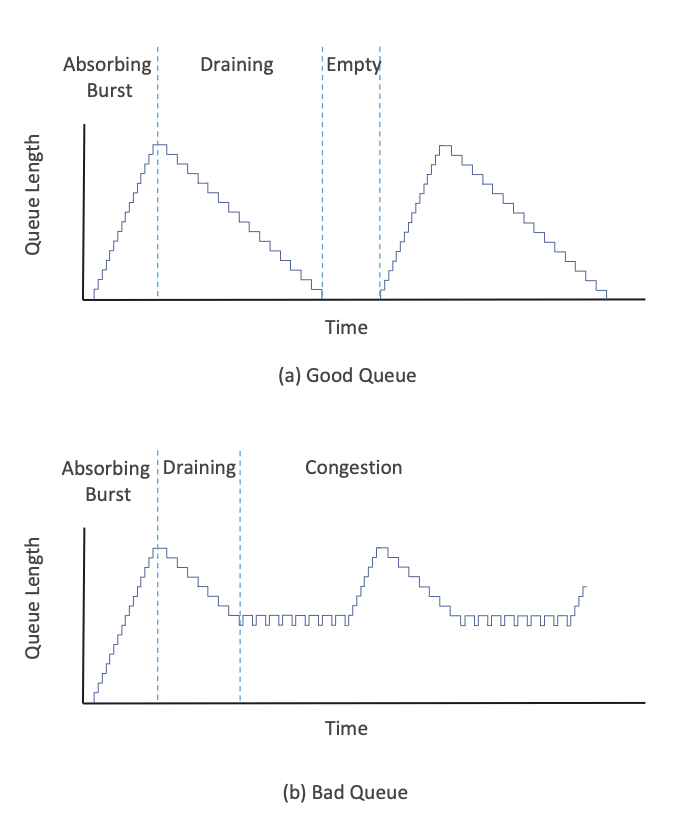
当队列长期处于满状态时,就会成为问题。一个保持满的队列除了给网络增加延迟外什么用也没有,而且如果永远不会完全清空,吸收突发流量的能力也会降低。在这些缓冲区中,大型缓冲区和持久化队列的组合是一种现象,Jim Gettys将其命名为Bufferbloat。很明显,设计良好的AQM机制会试图避免长期满队列状态。不出意外,长时间保持满队列而无法清空的队列被称为"坏队列",如图38 (b)所示。
延伸阅读:
J. Gettys. Bufferbloat: Dark Buffers in the Internet[6]. IEEE Internet Computing, April 2011.
因此在某种意义上,AQM算法的挑战是区分"好"和"坏"队列,并且只有当确定队列是"坏"时才会触发丢包。实际上,这就是RED试图用weight参数(过滤掉暂态队列长度)做的事情。
CoDel的创新之一是关注停留时间(sojourn time): 任何给定包在队列中的等待时间。停留时间与链路带宽无关,即使在带宽随时间变化的链路(如无线链路)上,停留时间也能提供有用的拥塞指示。一个运行良好的队列将频繁清空,因此,数据包的停留时间接近于零,如图38 (a)所示。相反,拥塞队列将延迟每个数据包,并且最小停留时间永远不会接近于零,如图38 (b)所示。因此,CoDel测量停留时间(很容易对每个数据包采样),并跟踪其是否始终处于某个阈值之上,这一阈值被定义为"持续时间比典型RTT更长"。
该算法自己选择合理的默认值,而不要求运营商确定使CoDel正常工作的参数。算法使用5ms作为目标停留时间,以及100ms的滑动测量窗口。与RED一样,直觉上,100ms是互联网流量的典型RTT,如果拥塞持续时间超过100ms,可能会进入"坏队列"区域。所以CoDel监控相对于目标5ms的逗留时间,如果目标超过100ms,就是采取行动的时候,通过丢包减少队列(或显式标记拥塞通知)。选择5ms是因为接近于零(为了更好的延迟),但不会小到队列会会清空。值得注意的是,有关于这些数值选择的大量实验和模拟,但更重要的是,算法似乎对它们不太敏感。
总之,CoDel在很大程度上忽略了持续时间小于RTT的队列,但一旦队列持续时间超过RTT,就开始采取行动。该算法对互联网RTT进行了合理的假设,并且无需配置参数。
另一个微妙之处在于,只要观察到的停留时间保持在目标上方,CoDel就会缓慢增加丢包占流量的百分比。正如第7.4节中进一步讨论的那样,TCP吞吐量已被证明与丢包率的平方根成反比。因此,只要停留时间保持在目标上方,CoDel就会稳步增加丢包率,与丢包次数的平方根成正比。理论上,这样做的结果是导致受影响的TCP连接的吞吐量线性下降,最终将导致流量减少,从而允许队列清空,使停留时间回到目标以下。
在Nichols和Jacobson的论文中有更多关于CoDel的细节,包括大量模拟,表明其在各种场景中的有效性。该算法已经在RFC 8289中被IETF标准化为"实验性"算法,也实现在了Linux内核中,从而有助于它的部署。特别是,CoDel在家庭路由器(通常基于Linux)中提供了价值,这是端到端路径上的一个点(请参见图39),通常会受到缓冲区膨胀的影响。
6.4 显式拥塞通知
虽然TCP拥塞控制机制最初是基于丢包作为主要拥塞信号,但人们早就认识到,如果路由器发送更明确的拥塞信号,TCP可以做得更好。也就是说,与其丢弃一个数据包并假设TCP最终会注意到(例如,由于重复ACK的到来),如果能够标记数据包并继续将其发送到目的地,任何AQM算法都可以做得更好。这个想法体现在了IP和TCP报头的变化中,被称为显式拥塞通知(ECN, Explicit Congestion Notification) ,在RFC 3168中定义。
延伸阅读:
K. Ramakrishnan, S. Floyd, and D. Black. The Addition of Explicit Congestion Notification (ECN) to IP[7]. RFC 3168, September 2001.
具体来说,通过将IP TOS字段中的两个比特作为ECN比特来实现反馈机制。发送端设置一个比特表示具有ECN能力,即能够响应拥塞通知,这被称为ECT位(ECN-Capable Transport)。当发生拥塞时,另一个比特位由端到端路径上的路由器基于所运行的AQM算法计算并设置,被称为CE位(Congestion Encountered)。
除了IP报头中的这两位(与传输层无关),ECN还包括向TCP报头添加两个可选标志。一个是ECE(ECN-Echo),接收端通过设置这个选项向发送端表示其收到了一个设置了CE位的数据包。另一个是CWR(Congestion Window Reduced),发送端向接收端表示已经减小了拥塞窗口。
虽然ECN现在是IP报头TOS字段8位中的2位的标准定义,并且强烈建议支持ECN,但并不是必需的。此外,还没有推荐的AQM算法。好的AQM算法应该满足一系列要求,和TCP拥塞控制算法一样,每种AQM算法都有其优缺点,所以需要大量讨论。
6.5 入口/出口队列
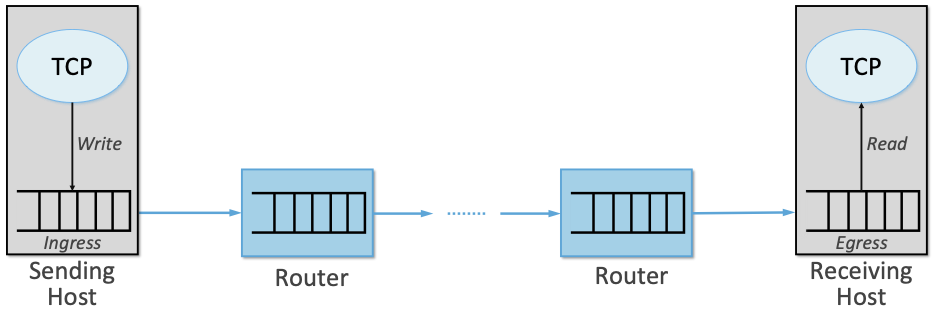
我们已经在网络内部(即本章中介绍的AQM算法)和网络边缘(即前几章中介绍的基于TCP的算法)的拥塞控制方法之间画了一条清晰的线,但线条并不一是那么明确。要了解这一点,只需将端到端路径想象为在发送主机的内核/设备接口上有一个入口队列(ingress queue) ,在接收主机的设备/内核接口上有一个出口队列(egress queue)[1]。随着虚拟交换机和网卡对虚拟化的支持变得越来越普遍,这些边缘队列可能会变得越来越重要。
[1] 容易混淆的是,从网络路径的角度来看,入口队列是发送主机上的出站(出口)队列,而出口队列是接收主机上的入站(入口)队列。如图40所示,我们从网络的角度使用术语入口和出口。
图40展示了这一观点,两个队列都位于TCP之下,提供了向端到端路径注入第二段拥塞控制逻辑的机会。CoDel和ECN就是这个想法的例子,并且已经在Linux内核的设备队列级别实现。
这能起作用吗?一个问题是数据包是在入口丢弃还是在出口丢弃。当在入口(在发送主机上)丢弃时,TCP会在Write函数的返回值中收到通知,从而导致"忘记"发送了数据包,尽管TCP确实减少了拥塞窗口来响应失败的写操作,但接下来还会发送这个包。相反,在出口队列(在接收主机上)丢弃数据包,意味着TCP发送方将不知道重传数据包,直到使用其标准机制之一(例如,三个重复ACK或者超时)检测到丢包。当然,在出口实现ECN是有好处的。
当我们把这个讨论放在拥塞控制的大环境中考虑时,可以得出两个有趣的结论。首先,Linux提供了一种方便而安全的方式将新代码(包括拥塞控制逻辑)注入内核,即使用eBPF(extended Berkeley Packet Filter) 。eBPF在许多其他环境中也正在成为一项重要的技术。用于拥塞控制的标准内核API已经移植到eBPF,大多数现有的拥塞控制算法也已经移植到这个框架上。这简化了试验新算法的工作,也可以避开在Linux内核里部署现有算法优化的障碍。
延伸阅读:
The Linux Kernel. BPF Documentation.
其次,通过显式的将入口/出口队列暴露给决策过程,我们为构建拥塞控制机制打开了大门,该机制包含一个"决定何时传输数据包"的组件和一个"决定排队还是丢弃数据包"的组件。在第7.1节介绍On-Ramp时,我们会看到一个采用创新方法使用这两个组件的机制示例。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
TCP Congestion Control: A Systems Approach: https://tcpcc.systemsapproach.org/index.html
[2]A Binary Feedback Scheme for Congestion Avoidance in Computer Networks with a Connectionless Network Layer: https://dl.acm.org/doi/pdf/10.1145/52324.52355
[3]Random Early Detection (RED) Gateways for Congestion Avoidance: http://www.icir.org/floyd/papers/early.twocolumn.pdf
[4]Recommendations on Queue Management and Congestion Avoidance in the Internet: https://tools.ietf.org/html/rfc2309
[5]Controlling Queue Delay: https://queue.acm.org/detail.cfm?id=2209336
[6]Bufferbloat: Dark Buffers in the Internet: https://ieeexplore.ieee.org/document/5755608
[7]The Addition of Explicit Congestion Notification (ECN) to IP: https://datatracker.ietf.org/doc/html/rfc3168
本文由 mdnice 多平台发布