背景
早在大语言模型如 GPT-3.5 等的兴起和被日渐广泛地采用之前,教育行业已经在 AI 辅助教学领域有过各种各样的尝试。在教育行业,人工智能技术的采用帮助教育行业更好地实现教学目标、提高教学质量、提高学习效率、提高学习体验、提高学习成果。例如,人工智能技术可以帮助教师更好地管理课堂、更好地识别学生的学习需求、更好地提供个性化的学习内容、更好地评估学生的学习成果、更好地提供学习支持。此外,人工智能技术还可以帮助教育行业更好地实现自动化,提高教育行业的效率和效果。总之,人工智能技术在教育行业的采用将会带来巨大的变化,为教育行业带来更多的发展机遇。
亚马逊云科技也一直致力于提供更方便快捷,功能更强大的 AI 服务来支持教育行业客户的技术创新和业务创新。特别是 Amazon Transcribe, Amazon Polly, Amazon Textract, Amazon Translate, Amazon Personalize, Amazon Rekognition, Amazon SageMaker 等产品分别从自然语言处理,图形图像处理,模型研发部署等方面为教育行业提供了强有力的技术支持。
本文结合 Amazon Transcribe, Amazon Polly,以及 OpenAI 的大语言模型和 D-ID.com 公司的 2D 数字人生成技术,介绍了一个演示用的可语音对话的智能 2D 数字人设计的服务,和具体的实现过程。
方案架构
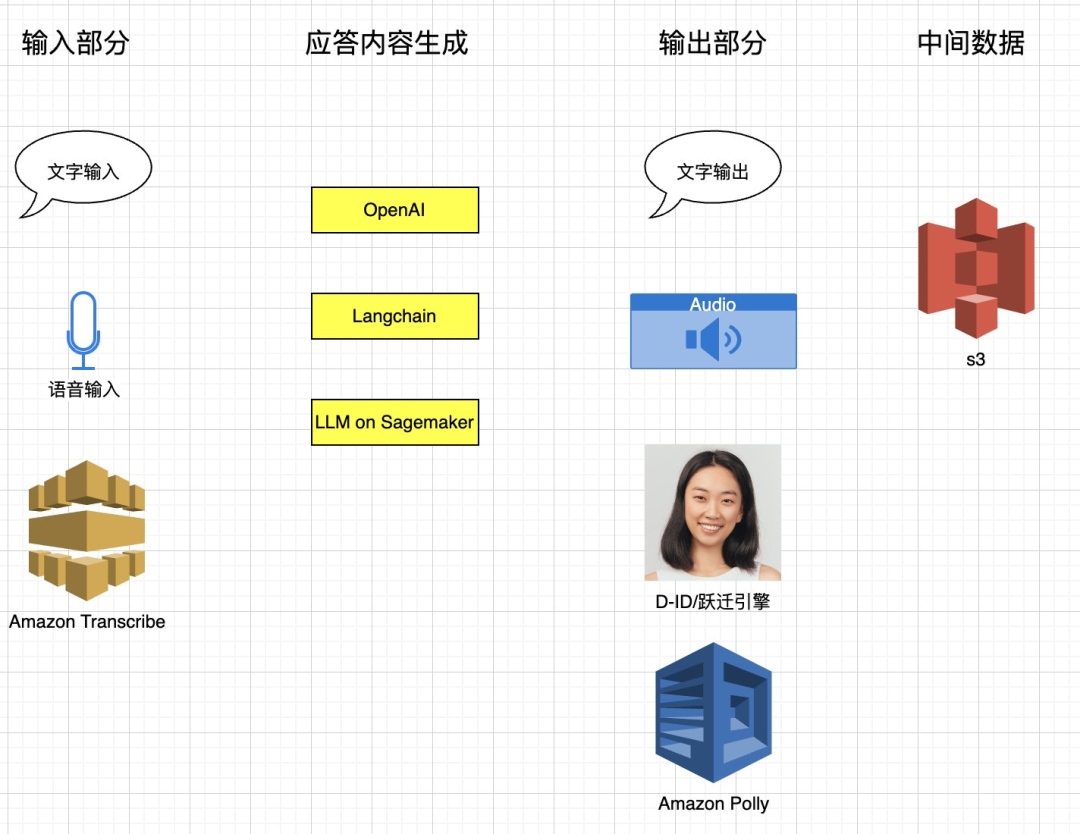
为了能在一个统一的用户界面呈现语音输入,语音输出,以及 2D 数字人视频播放的整体效果,本方案选择 Gradio 框架实现 WebUI 的功能。呈现的 WebUI 如下:
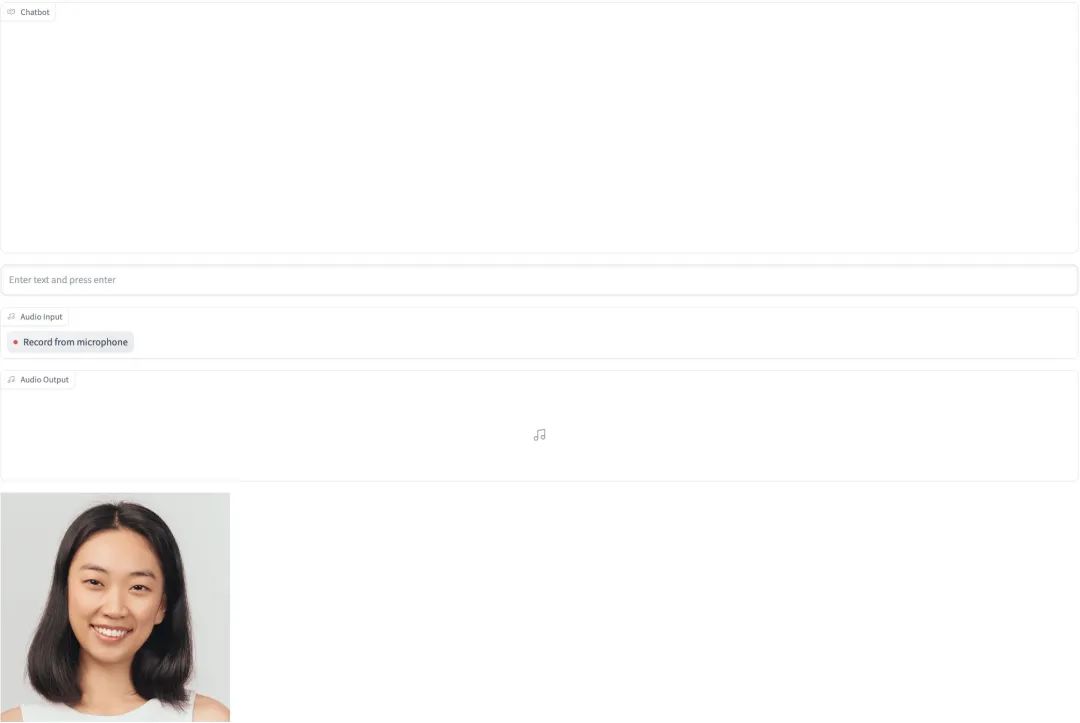
用户可以通过直接输入文字内容或者使用麦克风输入语音,文字内容会使用 Langchain 附加上一定的上下文后送给 OpenAI 的 GPT 接口调用,语音输入会先调用 Amazon Transcribe 服务进行语音到文字的转换。经过 GPT 接口返回的文字内容,会调用 Amazon Polly 形成语音文件,同时语音文件会作为 D-ID.com 提供的 API 渲染出 2D 的动态视频在前端自动展示和播放。
本方案中语音输入,语音输出,文字响应生成,以及数字人视频生成的功能都可以做自由的组合和替换。特别是对于 OpenAI 接口的调用可以置换为对自部署的大语言模型的调用,同时 2D 数字人视频的生成也可以考虑其他类似服务,如 Heygen 等。
具体实现
语音输入部分
Amazon Transcribe 支持实时转录语音(流式传输),也可以转录 Amazon S3 存储桶中的语音文件(批处理)。Transcribe 支持多达几十种的不同国家的语言。
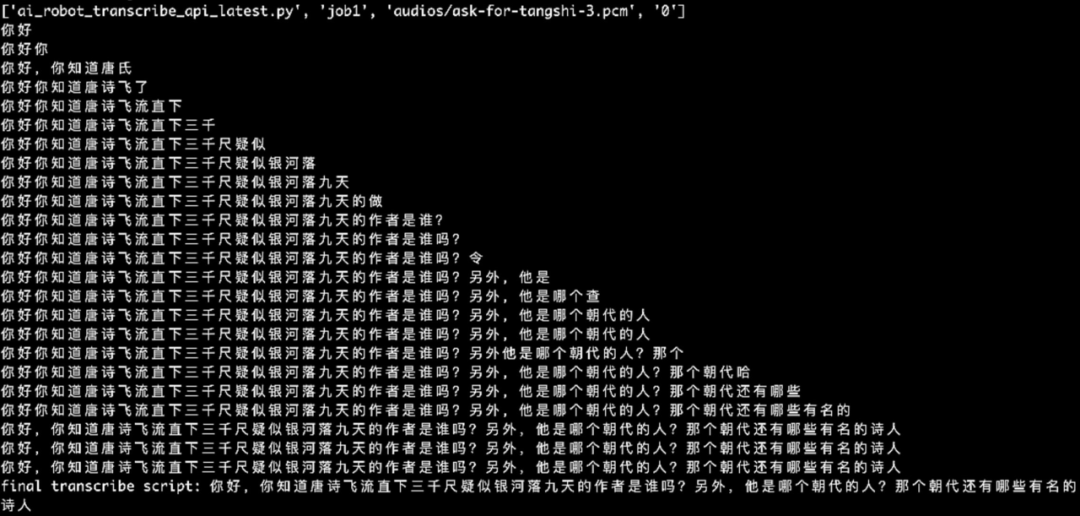
Transcribe 的实时转录能力非常的强大,处理流数据的同时,不断的利用之前的上下文进行结果的实时矫正,你可以通过下面这个截图看到 Transcribe 实时转录输出的效果:
在本方案中,我们使用批处理的方式处理输入的语音转录,具体代码如下:
def transcribe_func_old(audio):
audio_file = open(audio, "rb")
file_name = audio_file.name
print("audio_file: "+file_name)
# Set up the job parameters
job_name = "ai-bot-demo"
text_output_bucket = 'ai-bot-text-material' #this bucket is in us-west-1
text_output_key = 'transcriptions/question.json'
text_output_key = 'transcriptions/'+job_name+'.json'
language_code = 'zh-CN'
# Upload the file to an S3 bucket
audio_input_bucket_name = "ai-bot-audio-material"
audio_input_s3_key = "questions/tmp-question-from-huggingface.wav"
s3.upload_file(file_name, audio_input_bucket_name, audio_input_s3_key)
# Construct the S3 bucket URI
s3_uri = f"s3://{audio_input_bucket_name}/{audio_input_s3_key}"
response = transcribe.list_transcription_jobs()
# Iterate through the jobs and print their names
for job in response['TranscriptionJobSummaries']:
print(job['TranscriptionJobName'])
if job['TranscriptionJobName'] == job_name:
response = transcribe.delete_transcription_job(TranscriptionJobName=job_name)
print("delete transcribe job response:"+str(response))
# Create the transcription job
response = transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': s3_uri},
MediaFormat='wav',
LanguageCode=language_code,
OutputBucketName=text_output_bucket,
OutputKey=text_output_key
)
print("start transcribe job response:"+str(response))
job_name = response["TranscriptionJob"]["TranscriptionJobName"]
# Wait for the transcription job to complete
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)['TranscriptionJob']['TranscriptionJobStatus']
if status in ['COMPLETED', 'FAILED']:
break
print("Transcription job still in progress...")
time.sleep(1)
# Get the transcript
#transcript = transcribe.get_transcription_job(TranscriptionJobName=job_name)
transcript_uri = transcribe.get_transcription_job(TranscriptionJobName=job_name)['TranscriptionJob']['Transcript']['TranscriptFileUri']
print("transcript uri: " + str(transcript_uri))
transcript_file_content = s3.get_object(Bucket=text_output_bucket, Key=text_output_key)['Body'].read().decode('utf-8')
print(transcript_file_content)
json_data = json.loads(transcript_file_content)
# Extract the transcript value
transcript_text = json_data['results']['transcripts'][0]['transcript']
return transcript_text左滑查看更多
以上代码主要完成了几个步骤的工作:
将要处理的语音文件上传到 Amazon S3
创建 Amazon Transcribe 的工作任务并轮询检查任务状态
从 Amazon S3 获取 Amazon Transcribe 已完成任务的解析结果
应答内容生成部分
在本方案里,应答内容的生成借助 Langchain 这个开源框架,调用基于 OpenAI 的 coversation 接口,同时使用 memory 库对对话的上下文做了 5 轮保存。在实际的客户场景里,可以考虑更丰富的方式来规范回复的内容的有效性和客观性。
比如可以使用 Langchain 的对话模版来对大模型的角色进行预设,或者使用 Amazon Kendra,Amazon Opensearch 这样的知识库构建和检索引擎,来进一步限制大模型应答的内容范围,本方案中和语言大模型相关的代码如下:
memory = ConversationBufferWindowMemory(k=5)
conversation = ConversationChain(
llm=OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], max_tokens=2048, temperature=0.5),
memory=memory,
)左滑查看更多
语音输出部分
Amazon Polly 可以将文本转化为逼真的语音。它支持多种语言并且包含各种逼真的声音模拟,也包含中文普通话语音的模拟。
你可以构建支持语音并能用于各种位置的应用程序,并选择适合客户的声音。Amazon Polly 也支持语音合成标记语言(SSML),它是一种基于 XML 的 W3C 标准标记语言,适用于语音合成应用程序,且支持使用通用 SSML 标签进行断句、重音和语调。自定义 Amazon SSML 标签提供了独特的选项,例如,能够以新闻播音员说话风格发出某些声音。这种灵活性能够帮助您创建逼真的语音,从而吸引并维持听众的注意力。
在本方案中,我们使用 Polly 的实时语音生成接口,使用了中文普通话发音的 VoiceID:Zhiyu,同时对特定的字符的发音做了定制化,这也是 Polly 一个非常有用的功能(Lexion)。
def polly_text_to_audio(audio_file_name, text, audio_format):
if os.path.exists(audio_file_name):
os.remove(audio_file_name)
print("output mp3 file deleted successfully.")
else:
print("output mp3 file does not exist.")
polly_response = polly.synthesize_speech(
Text=text,
OutputFormat=audio_format,
SampleRate='16000',
VoiceId='Zhiyu',
LanguageCode='cmn-CN',
Engine='neural',
LexiconNames=['xxxxCN']
)
# Access the audio stream from the response
if "AudioStream" in polly_response:
# Note: Closing the stream is important because the service throttles on the
# number of parallel connections. Here we are using contextlib.closing to
# ensure the close method of the stream object will be called automatically
# at the end of the with statement's scope.
with closing(polly_response["AudioStream"]) as stream:
try:
# Open a file for writing the output as a binary stream
with open(audio_file_name, "wb") as file:
file.write(stream.read())
except IOError as error:
# Could not write to file, exit gracefully
print(error)
sys.exit(-1)
else:
# The response didn't contain audio data, exit gracefully
print("Could not stream audio")
sys.exit(-1)左滑查看更多
2D 数字人视频的生成部分
这里我们使用了一个外部第三方的 SaaS 服务。该服务由 D-ID.com 公司提供,对应的 API 可以直接接收文本输入和一张人脸图片来生成对应的动态播报视频,也可以接受语音文件加图片作为输入。
当你输入文本的时候,该 API 接口可以选择制定 Amazon 的 Polly 服务中的不同的 Voice ID 来自动为你合成语音。
在本方案中,我们想体现中文的语音输出的效果,但是 D-ID 的 API 接口中暂时无法直接为中文文本指定中文的 Voice ID。所以我们选择了先用 Polly 的 API 生成语音,再把语音和图片传送给 D-ID 的接口生成视频,具体的代码如下:
def generate_talk_with_audio(input, avatar_url, api_key = did_api_key):
url = "https://api.d-id.com/talks"
payload = {
"script": {
"type": "audio",
"audio_url": input
},
"config": {
"auto_match": "true",
"result_format": "mp4"
},
"source_url": avatar_url
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"authorization": "Basic " + api_key
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
def get_a_talk(id, api_key = os.environ.get('DID_API_KEY')):
url = "https://api.d-id.com/talks/" + id
headers = {
"accept": "application/json",
"authorization": "Basic "+api_key
}
response = requests.get(url, headers=headers)
return response.json()
def get_mp4_video(input, avatar_url=avatar_url):
response = generate_talk_with_audio(input=input, avatar_url=avatar_url)
print("DID response: "+str(response))
talk = get_a_talk(response['id'])
video_url = ""
index = 0
while index < 30:
index += 1
if 'result_url' in talk:
video_url = talk['result_url']
return video_url
else:
time.sleep(1)
talk = get_a_talk(response['id'])
return video_url左滑查看更多
在实际应用中,如果希望 Amazon Polly 实现近乎实时的文本转语音,可以结合大语言模型的流式输出进行实时处理,示例代码如下:
response = generate_response(prompt)
# create variables to collect the stream of events
collected_events = []
completion_text = ''
sentance_to_polly = ''
separators = ['?','。',',','!']
already_polly_processed = ''
# iterate through the stream of events
for event in response:
collected_events.append(event) # save the event response
event_text = event['choices'][0]['text'] # extract the text
if event_text in separators:
sentance_to_polly = completion_text.replace(already_polly_processed,'')
#print("sentance_to_polly: "+sentance_to_polly)
polly_text_to_audio(response_audio_filename, sentance_to_polly, 'mp3')
already_polly_processed = completion_text
completion_text += event_text # append the text
print(event_text, end='', flush=True) # print the delay and text左滑查看更多
以上这段代码,利用了 Amazon Polly 的实时处理能力。根据返回的流文本数据,在发现‘?’,‘。’,‘,’,‘!’等分割标点的时候,立刻调用 Amazon Polly 进行最近的一段文字的语音生成,然后附加到当前的视频文件的最后。等文字流接收完毕,语音也基本上转换完毕了。
本方案目前托管在 huggingface 网站提供的工作空间:https://huggingface.co/spaces/xdstone1/ai-bot-demo,相应的代码也可以通过以下渠道来获取:
git lfs install
git clone https://huggingface.co/spaces/xdstone1/ai-bot-demo左滑查看更多
方案的演示视频可以通过以下链接观看:
https://d3g7d7eldf7i0r.cloudfront.net/。
总结
今年是 AIGC 爆发的一年,也是教育行业所在的客户看到行业拐点的一年。在这个关键的历史性节点上,亚马逊云科技愿意和客户一起面对这些新的机会和挑战,以客户的需求为导向,帮助客户抓住 AI 浪潮带来的红利。
目前除了本文展示的 2D 数字人方案,亚马逊云科技也可以帮助客户提供基于 3D 数字人或者其他 3D 数字形象的直播、互动等方案。同时我们也会引入更多的技术合作伙伴如跃迁引擎(https://www.warpengine.cc/)来丰富整个数字人、数字形象直播、点播、互动等场景的解决方案,助力更多教育行业客户加速 AI 技术的采用和落地。
本篇作者

薛东
亚马逊云科技解决方案架构师,负责基于亚马逊云平台的解决方案咨询和设计,目前在亚马逊云科技大中华区服务教育行业客户。专注于无服务,安全等技术方向。


听说,点完下面4个按钮
就不会碰到bug了!