目录
- 说明
- 摘要
- 引言
- 相关工作
- SISR
- Meta-Learning
- 本文的方法
- Meta-Upscale方法
- Location Projection
- Weight Prediction
- Feature Mapping
- 实验细节
- 总结
- 实现代码
- 参考链接
说明
作为一个读者,在阅读这篇文章后,按照自己的理解对其中内容做以总结(不然总感觉自己过一阵时间就遗忘了)。不是将原版英文照抄一字不落地翻译过来,而是自己进行整理总结。我只总结那些对我来说有价值的知识和我不知道的知识,其他的就省了。不喜勿喷且若出现错误,欢迎评论交流。我也是一个入门小白。

接收期刊及时间: 2019年CVPR论文
类型: 任意尺度超分
摘要
之间的大多数工作将不同倍数的超分视作为单独的任务。例如x2、x3、x4超分需要分别训练一个单独的模型,这在实际应用中很占空间且不高效,无法满足需求。因此,作者提出了Meta-SR,首次使用一个模型解决任意尺度超分问题。
引言
现有的超分方法在网络最后上采样时大多使用亚像素卷积,所以说当放大倍数不一样时,模型也就不一样。同时亚像素卷积只能应对整数放大倍数(x2、x3、x4),这就限制了这些模型在实际中的应用。
相关工作
SISR
EDSR的论文中还首次提出了一个MDSR,这是首次训练一个模型可以同时解决三种放大倍数(2倍、3倍、4倍)。
Meta-Learning
本文的方法
Meta-Upscale方法
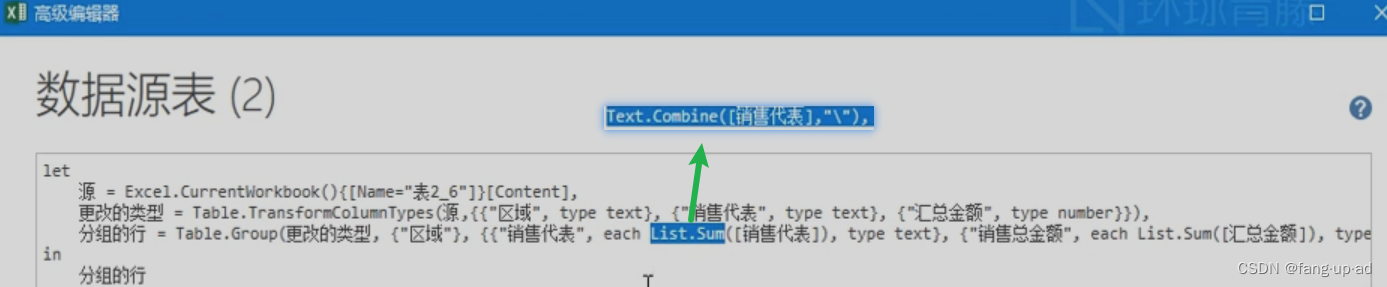
本文最主要的工作就是提出了Meta-Upscale模块来代替以前的上采样模块(例如亚像素卷积、反卷积)。Meta-Upscale模块的运作方式如下,主要分为两部分:位置映射(Location Projection)和权重预测(Weight Prediction)。
以前的方法是特征提取网络部分结束后,使用一个亚像素卷积或反卷积进行上采样。本工作特征提取部分不变,可以继续使用之前的特征提取模块(例如EDSR或者文中使用的RDN),之后将上采样模块换成Meta-Upscale即可。
上采样模块的具体算法细节如下图所示:

上图已经表达的很清楚了,下面分别对这两部分进行整理。
原文中的网络结构如下:

Location Projection
这部分说白了就是位置映射:SR图像中的一个像素点由特征提取网络出来的特征图中的几个点决定。 从上图中可以看到SR中的一个像素点对应特征图中的 k × k k\times k k×k个像素 F L R ( i ′ , j ′ ) F^{LR}\left(i^{\prime},j^{\prime}\right) FLR(i′,j′)。
Weight Prediction
SR图像中每个点都有自己的一个滤波器,也就是说,在Location Projection中定位出的那几个位置的像素值要乘以滤波器(权重)就等于SR中该点的像素值。这个权重怎么来的?
权重是通过一个预测网络
φ
(
.
)
\varphi\left(.\right)
φ(.)预测出来的。可以用下式描述:
W
(
i
,
j
)
=
φ
(
v
i
j
;
θ
)
W\left(i,j\right) = \varphi(\text{v}_{ij};\theta)
W(i,j)=φ(vij;θ)
v
i
j
\text{v}_{ij}
vij为
φ
(
.
)
\varphi\left(.\right)
φ(.)的输入,
θ
\theta
θ为
φ
(
.
)
\varphi\left(.\right)
φ(.)的参数。输入
v
i
j
\text{v}_{ij}
vij的表达式如下:
v
i
j
=
(
i
r
−
⌊
i
r
⌋
,
j
r
−
⌊
j
r
⌋
,
1
r
)
\text{v}_{ij} = \left(\frac{i}{r} - \lfloor \frac{i}{r} \rfloor, \frac{j}{r} - \lfloor \frac{j}{r} \rfloor, \frac{1}{r}\right)
vij=(ri−⌊ri⌋,rj−⌊rj⌋,r1)
(
i
,
j
)
\left(i,j\right)
(i,j)为SR图像上的位置,
(
i
′
,
j
′
)
\left(i^{\prime},j^{\prime}\right)
(i′,j′)为特征图
F
L
R
F^{LR}
FLR上的位置。
可以看到,输入是
(
i
,
j
)
\left(i,j\right)
(i,j)相对于
(
i
′
,
j
′
)
\left(i^{\prime},j^{\prime}\right)
(i′,j′)的偏移以及放大因子
r
r
r。
Feature Mapping
有了Location Projection得到的
F
L
R
(
i
′
,
j
′
)
F^{LR}\left(i^{\prime},j^{\prime}\right)
FLR(i′,j′)和Weight Prediction得到的
W
(
i
,
j
)
W\left(i,j\right)
W(i,j),通过矩阵相乘便可得到SR上
(
i
,
j
)
(i,j)
(i,j)点的像素值
I
S
R
(
i
,
j
)
I^{SR}(i,j)
ISR(i,j),如下式所示。
I
S
R
(
i
,
j
)
=
F
L
R
(
i
′
,
j
′
)
⋅
W
(
i
,
j
)
I^{SR}(i,j) = F^{LR}\left(i^{\prime},j^{\prime}\right) \cdot W\left(i,j\right)
ISR(i,j)=FLR(i′,j′)⋅W(i,j)
实验细节
| 参数 | 描述 |
|---|---|
| 训练集 | DIV2K |
| 测试集 | Set14、B100、Mange109、DIV2K的验证集 |
| 指标 | Y通道的PSNR和SSIM |
| 损失函数 | L1 loss |
| batch_size | [16,3,50,50],每个batch放大因子相同 |
| 数据增强 | 随机水平反转或者垂直反正和90度旋转 |
| 优化器 | Adam,初始学习率 1 0 − 4 10^{-4} 10−4,每两个epochs减半 |
| 训练放大因子 | 从1倍到4倍变化,步长为0.1 |
注:每一个batch内的数据是同一个放大尺度。
总结
本文提出的任意尺度的上采样模块的思路和传统图像处理的思路有点相似。比如我们在传统图像处理放大时,放大后的图像上的某个位置的像素值与原始图周围好几个像素有关,然后对这些像素做一些加减乘除的操作。而这里的这个权重是使用神经网络预测出来的。那么这里能否继续做一些工作呢?
实现代码
官方代码地址: github
因为官方代码的torch版本过于低,torch版本不匹配的话dataloader.py文件会报很多错误,这里我已经参考一些博客对其进行了修改,现在可以在torch1.12.1上面成功运行。不确定是否在更新的torch版本上可以成功运行。github地址如下:
https://github.com/zgaxddnhh/Meta-SR-Pytorch.git
参考链接
https://zhuanlan.zhihu.com/p/380373246