文章目录
- 概述
- dcnv3.py
- to_channels_first
- to_channels_last
- build_norm_layer
- build_act_layer
- _is_power_of_2
- CenterFeatureScaleModule
- DCNv3_pytorch
- DCNv3
- dcnv3_func.py
- DCNv3Function
- dcnv3_core_pytorch
- _get_reference_points
- _generate_dilation_grids
可变形卷积DCNv1 & DCNv2
✨✨✨论文及代码详解——可变形卷积(DCNv1)
✨✨✨论文及代码详解——可变形卷积(DCNv2)
DCNv3 是InternImage中提出的,DCNv3在DCNv2版本上进行了改进。
✨✨✨论文详解——《InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions》
InterImage官方代码: https://github.com/OpenGVLab/InternImage
概述
如下图,首先下载InterImage官方代码,然后在segmentation、detection、classification文件夹下均可以找到ops_dcnv3文件夹,该文件夹下的内容就是实现DCNv3算子的核心代码。

modules
如下图所示,modules文件夹中的dcnv3.py文件主要定义了DCNv3模块。
其中DCNv3_pytorch是DCNv3的pytorch实现版本,DCNv3是DCNv3的C++实现版本。

functions
如下图所示,function文件夹中的dcnv3_func.py文件定义了DCNv3的一些核心操作。
其中黄色部分的DCNv3Function类被c++版本的DCNv3调用。
其中红色部分的dcnv3_core_pytorch方法被pytorch版本的DCNv3_pytorch调用。

src
src下的代码是用C++来实现DCNv3中核心操作,其下的cpu和cuda分别表示cpu和cuda编程两种实现版本。c++实现的版本需要去编译,否则如上图所示,黄色箭头指向的import DCNv3有红色波浪线,无法正常导入。
如果想import DCNv3成功,有两种解决办法:
(1)需要编译:DCNv3具体编译方法是直接运行make.sh文件(但是这种方法很容易编译失败,对于pytorch,cuda的版本以及c++编译器的配置都有要求)
(2)不需要编译:去官网上下载轮子https://github.com/OpenGVLab/InternImage/releases/tag/whl_files (更推荐这种方法,但是也需要注意cuda和pytorch的版本)

本文重点介绍DCNv3的pytorch实现部分。
dcnv3.py
to_channels_first
- 功能:将通道维度放在前面,输入
(b,h,w,c),输出(b,c,h,w)
# 将通道维度放在前面:(b,h,w,c)->(b,c,h,w)
class to_channels_first(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x): # (b,h,w,c)
return x.permute(0, 3, 1, 2) #(b,c,h,w)
to_channels_last
- 功能:将通道维度放在后面,输入
(b,c,h,w),输出(b,h,w,c)
# 将通道维度放在后面 (b,c,h,w)->(b,h,w,c)
class to_channels_last(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x): # (b,c,h,w)
return x.permute(0, 2, 3, 1) # (b,h,w,c)
build_norm_layer
- 功能:构建归一化层,可以选择
Batch Norm或者Layer Norm
def build_norm_layer(dim,
norm_layer,
in_format='channels_last',
out_format='channels_last',
eps=1e-6):
layers = []
if norm_layer == 'BN':
if in_format == 'channels_last':
layers.append(to_channels_first())
layers.append(nn.BatchNorm2d(dim))
if out_format == 'channels_last':
layers.append(to_channels_last())
elif norm_layer == 'LN':
if in_format == 'channels_first':
layers.append(to_channels_last()) # (b,c,h,w)->(b,h,w,c)
layers.append(nn.LayerNorm(dim, eps=eps))
if out_format == 'channels_first':
layers.append(to_channels_first())
else:
raise NotImplementedError(
f'build_norm_layer does not support {norm_layer}')
return nn.Sequential(*layers)
build_act_layer
- 功能:构建激活函数层,可选择
RELU / SiLU / GELU激活函数
def build_act_layer(act_layer):
if act_layer == 'ReLU':
return nn.ReLU(inplace=True)
elif act_layer == 'SiLU':
return nn.SiLU(inplace=True)
elif act_layer == 'GELU':
return nn.GELU()
raise NotImplementedError(f'build_act_layer does not support {act_layer}')
_is_power_of_2
- 功能:检查n是否是2的某次方,且n不为0
如果n & (n - 1)为0,则说明n是2的某次方。
def _is_power_of_2(n):
if (not isinstance(n, int)) or (n < 0): # 如果n不为整数或者n小于0
raise ValueError(
"invalid input for _is_power_of_2: {} (type: {})".format(n, type(n)))
return (n & (n - 1) == 0) and n != 0
CenterFeatureScaleModule
- 功能:生成缩放系数。
F.linear的输出取决于传入的实参weight和bias,然后再通过sigmod函数归一化。
class CenterFeatureScaleModule(nn.Module):
def forward(self,
query,
center_feature_scale_proj_weight, # (group,channels)
center_feature_scale_proj_bias):
center_feature_scale = F.linear(query,
weight=center_feature_scale_proj_weight,
bias=center_feature_scale_proj_bias).sigmoid() # 全连接层+sigmod
# F.linear的输出取决于传入的实参weight和bias
# 输入:(*,channels) -> 输出:(*,group)
return center_feature_scale
DCNv3_pytorch
class DCNv3_pytorch 是分组可变形卷积DCNv3的pytorch的实现版。
'''分组可变形卷积 pytorch实现版'''
class DCNv3_pytorch(nn.Module):
def __init__(
self,
channels=64, # 通道数
kernel_size=3, # 卷积核大小
dw_kernel_size=None, # 深度可分离卷积核大小
stride=1, # 步长
pad=1, # 填充
dilation=1, #空洞率
group=4,# 分组数
offset_scale=1.0,
act_layer='GELU', # 激活函数
norm_layer='LN', # 归一化层
center_feature_scale=False):
super().__init__()
if channels % group != 0: # 分组卷积必须保证通道数可以被组数整除
raise ValueError(
f'channels must be divisible by group, but got {channels} and {group}')
_d_per_group = channels // group # 每个组数拥有的通道数
dw_kernel_size = dw_kernel_size if dw_kernel_size is not None else kernel_size # 设置深度可分离卷积核的大小
# 最好把_d_per_group设置为2的某次方,方便cuda的具体实现
if not _is_power_of_2(_d_per_group):
warnings.warn(
"You'd better set channels in DCNv3 to make the dimension of each attention head a power of 2 "
"which is more efficient in our CUDA implementation.")
self.offset_scale = offset_scale
self.channels = channels
self.kernel_size = kernel_size
self.dw_kernel_size = dw_kernel_size
self.stride = stride
self.dilation = dilation
self.pad = pad
self.group = group
self.group_channels = channels // group
self.offset_scale = offset_scale
self.center_feature_scale = center_feature_scale
# 深度可分离卷积
self.dw_conv = nn.Sequential(
# depth-wise 逐通道卷积
# H_out=H_in+2*padding-(kernel_size-1)
nn.Conv2d(
channels,
channels, # 输入输出的通道数不变
kernel_size=dw_kernel_size,
stride=1,
padding=(dw_kernel_size - 1) // 2, # 输出大小不变
groups=channels), # 分组数和输入通道数相等,也就实现了逐通道的卷积 !!!
# 归一化层
build_norm_layer(
channels,
norm_layer,
'channels_first', #如果是LN, (b,c,h,w)->(b,h,w,c)
'channels_last'),
# 激活层
build_act_layer(act_layer))
self.offset = nn.Linear( # offset: 偏移量
channels,
group * kernel_size * kernel_size * 2) # 输出通道数:group*2*kernel_size*kernel_size
self.mask = nn.Linear( # mask: 调制标量
channels,
group * kernel_size * kernel_size) # 输出通道数:group*kernel_size*kernel_size
self.input_proj = nn.Linear(channels, channels) # Linear层,输入输出通道数不变
self.output_proj = nn.Linear(channels, channels) # Linear层,输入输出通道数不变
self._reset_parameters() # 参数初始化
if center_feature_scale: # 如果需要对特征图进行缩放
self.center_feature_scale_proj_weight = nn.Parameter(
torch.zeros((group, channels), dtype=torch.float)) # weighit:大小为(group,channels)的全0 Tensor
self.center_feature_scale_proj_bias = nn.Parameter(
torch.tensor(0.0, dtype=torch.float).view((1,)).repeat(group, )) # bias: 大小为(group)的全0 tensor
self.center_feature_scale_module = CenterFeatureScaleModule()# (*,channels)->(*,groups)
_reset_parameters
- 功能:初始化参数,将bias设置为0,weights采用
xavier_uniform_分布进行初始化。
# 参数初始化
def _reset_parameters(self):
constant_(self.offset.weight.data, 0.)
constant_(self.offset.bias.data, 0.)
constant_(self.mask.weight.data, 0.)
constant_(self.mask.bias.data, 0.)
xavier_uniform_(self.input_proj.weight.data)
constant_(self.input_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.)
forward
功能:前向传播
def forward(self, input): # (N,H,W,C)
N, H, W, _ = input.shape
x = self.input_proj(input) #Linear层,通道不变 x: (N,H,W,C)
x_proj = x
x1 = input.permute(0, 3, 1, 2) # x1: (N,C,H,W)
'''
改进点1:将原始卷积权值w_k分离为depth-wise和point-wise两部分,其中depth-wise部分由原始的location-aware modulation scalar m_k负责,point-wise部分是采样点之间的共享投影权值w。
'''
# DW_conv(逐通道卷积)+Norm+Act
x1 = self.dw_conv(x1) # (N,H,W,C)
'''
改进点2:我们将空间聚集过程分成G组,每个组都有单独的采样偏移offset和调制规模mask
因此在一个卷积层上的不同组可以有不同的空间聚集模式,从而为下游任务带来更强的特征。
'''
offset = self.offset(x1) #生成偏移 (N,H,W,group*2*kernel_size*kernel_size)
mask = self.mask(x1).reshape(N, H, W, self.group, -1) # mask 表示调制标量
# mask后:(N,H,W,group*kernel_size*kernel_size)
# reshape后:(N,H,W,group,kernel_size*kernel_size)
mask = F.softmax(mask, -1).reshape(N, H, W, -1) # (N,H,W,group*kernel_size*kernel_size)
# softmax的dim=-1,表示在kernel_size*kernel_size个样本点进行归一化,其和等于1。
'''
改进点3:我们将基于element-wise的sigmoid归一化改为基于样本点的softmax归一化。这样,将调制标量的和限制为1,使得不同尺度下模型的训练过程更加稳定。
'''
x = dcnv3_core_pytorch( # 可变形卷积的核心代码
x, offset, mask,
# x: (N,H,W,C)
# offset: (N,H,W,group*2*kernel_size*kernel_size)
# mask: (N,H,W,group*kernel_size*kernel_size)
self.kernel_size, self.kernel_size,
self.stride, self.stride,
self.pad, self.pad,
self.dilation, self.dilation,
self.group, self.group_channels,
self.offset_scale) # (N_, H_out, W_out,group*group_channels)
if self.center_feature_scale: # 如果需要特征缩放
center_feature_scale = self.center_feature_scale_module(
x1, self.center_feature_scale_proj_weight, self.center_feature_scale_proj_bias)
# x1:(N,H,W,C) ->(N,H,W,groups)
center_feature_scale = center_feature_scale[..., None].repeat(
1, 1, 1, 1, self.channels // self.group).flatten(-2)
# (N, H, W, groups) -> (N, H, W, groups, 1) -> (N, H, W, groups, _d_per_group) -> (N, H, W, channels)
x = x * (1 - center_feature_scale) + x_proj * center_feature_scale
# x_proj和x按照一定的系数相加
x = self.output_proj(x) # (N,H,W,C)
return x
在forward函数中体现了InterImage论文中提出的三个改进点。
-
改进点1:将原始卷积权值w_k分离为depth-wise和point-wise两部分,其中depth-wise部分由原始的location-aware modulation scalar m_k负责,point-wise部分是采样点之间的共享投影权值w。
如下图所示,DCNv3的实现代码offset和mask是由经过dw_conv的depth-wise convolution得到的x1生成,但是一同输入dcnv3的是原始的x_proj。

如下图是DCNv2的实现代码,其中它的m(mask)和offset 是原始输入x分别通过普通卷积p_conv和m_conv生成。

假设卷积核的大小是(kernel_h,kernel_w), 输入的大小是(c_in,h,w)。卷积核需要滑动t次。
那么普通卷积需要的总乘法运算数是c_out*kernel_h*kernel_w*c_in*t
而depth-wise 卷积需要的总乘法数是kernel_h*kernel_w*c_in*t, 相比下减少了c_out倍。
因此用dw_conv生成offset和mask,可以提升模型的效率。 -
改进点2:我们将空间聚集过程分成 G G G组,每个组都有单独的采样偏移 ∆ p g k ∆p_{gk} ∆pgk和调制规模 m g k m_{gk} mgk,
DCNv3生成的mask大小是(N,H,W,group*kernel_size*kernel_size), offset的大小是(N,H,W,2*group*kernel_size*kernel_size),每个组都有不同的采样偏移和调制规模。
而DCNv2生成的mask大小是(N,H,W,kernel_size*kernel_size), offset的大小是(N,H,W,2*kernel_size*kernel_size)。 -
改进点3:将基于element-wise的sigmoid归一化改为基于样本点的softmax归一化。
如下图,DCNv3的softmax函数在最后一个维度上进行归一化,保证了最后一个维度的kernel_size*kernel_size个元素的和为1。

如下图所示,DCNv2的softmax函数只是将所有的element通过sigmod 函数,保证每个element的值在[0,1]范围内。
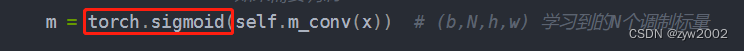
DCNv3
DCNv3是C++实现版本,唯一和DCNv3_pytorch不同的是, dcnv3_core_pytorch 被替换成了DCNv3Function类中的apply函数(这个是dcnv3_func.py中定义的autograd function)。

'''分组可变形卷积 C++实现版'''
class DCNv3(nn.Module):
def __init__(
self,
channels=64,
kernel_size=3,
dw_kernel_size=None,
stride=1,
pad=1,
dilation=1,
group=4,
offset_scale=1.0,
act_layer='GELU',
norm_layer='LN',
center_feature_scale=False):
"""
DCNv3 Module
:param channels
:param kernel_size
:param stride
:param pad
:param dilation
:param group
:param offset_scale
:param act_layer
:param norm_layer
"""
super().__init__()
if channels % group != 0:
raise ValueError(
f'channels must be divisible by group, but got {channels} and {group}')
_d_per_group = channels // group
dw_kernel_size = dw_kernel_size if dw_kernel_size is not None else kernel_size
# you'd better set _d_per_group to a power of 2 which is more efficient in our CUDA implementation
if not _is_power_of_2(_d_per_group):
warnings.warn(
"You'd better set channels in DCNv3 to make the dimension of each attention head a power of 2 "
"which is more efficient in our CUDA implementation.")
self.offset_scale = offset_scale
self.channels = channels
self.kernel_size = kernel_size
self.dw_kernel_size = dw_kernel_size
self.stride = stride
self.dilation = dilation
self.pad = pad
self.group = group
self.group_channels = channels // group
self.offset_scale = offset_scale
self.center_feature_scale = center_feature_scale
self.dw_conv = nn.Sequential(
nn.Conv2d(
channels,
channels,
kernel_size=dw_kernel_size,
stride=1,
padding=(dw_kernel_size - 1) // 2,
groups=channels),
build_norm_layer(
channels,
norm_layer,
'channels_first',
'channels_last'),
build_act_layer(act_layer))
self.offset = nn.Linear(
channels,
group * kernel_size * kernel_size * 2)
self.mask = nn.Linear(
channels,
group * kernel_size * kernel_size)
self.input_proj = nn.Linear(channels, channels)
self.output_proj = nn.Linear(channels, channels)
self._reset_parameters()
if center_feature_scale:
self.center_feature_scale_proj_weight = nn.Parameter(
torch.zeros((group, channels), dtype=torch.float))
self.center_feature_scale_proj_bias = nn.Parameter(
torch.tensor(0.0, dtype=torch.float).view((1,)).repeat(group, ))
self.center_feature_scale_module = CenterFeatureScaleModule()
def _reset_parameters(self):
constant_(self.offset.weight.data, 0.)
constant_(self.offset.bias.data, 0.)
constant_(self.mask.weight.data, 0.)
constant_(self.mask.bias.data, 0.)
xavier_uniform_(self.input_proj.weight.data)
constant_(self.input_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.)
def forward(self, input):
"""
:param query (N, H, W, C)
:return output (N, H, W, C)
"""
N, H, W, _ = input.shape
x = self.input_proj(input)
x_proj = x
dtype = x.dtype
x1 = input.permute(0, 3, 1, 2)
x1 = self.dw_conv(x1)
offset = self.offset(x1)
mask = self.mask(x1).reshape(N, H, W, self.group, -1)
mask = F.softmax(mask, -1).reshape(N, H, W, -1).type(dtype)
x = DCNv3Function.apply( # !!!
x, offset, mask,
self.kernel_size, self.kernel_size,
self.stride, self.stride,
self.pad, self.pad,
self.dilation, self.dilation,
self.group, self.group_channels,
self.offset_scale,
256)
if self.center_feature_scale:
center_feature_scale = self.center_feature_scale_module(
x1, self.center_feature_scale_proj_weight, self.center_feature_scale_proj_bias)
# N, H, W, groups -> N, H, W, groups, 1 -> N, H, W, groups, _d_per_group -> N, H, W, channels
center_feature_scale = center_feature_scale[..., None].repeat(
1, 1, 1, 1, self.channels // self.group).flatten(-2)
x = x * (1 - center_feature_scale) + x_proj * center_feature_scale
x = self.output_proj(x)
return x
dcnv3_func.py
DCNv3Function
DCNv3Function是一个自定义的autograd function, 用于C++实现的DCNv3。
class DCNv3Function(Function): # 自定义 autograd function
@staticmethod
@custom_fwd
def forward( # 前向传播
ctx, input, offset, mask,
kernel_h, kernel_w, stride_h, stride_w,
pad_h, pad_w, dilation_h, dilation_w,
group, group_channels, offset_scale, im2col_step):
ctx.kernel_h = kernel_h
ctx.kernel_w = kernel_w
ctx.stride_h = stride_h
ctx.stride_w = stride_w
ctx.pad_h = pad_h
ctx.pad_w = pad_w
ctx.dilation_h = dilation_h
ctx.dilation_w = dilation_w
ctx.group = group
ctx.group_channels = group_channels
ctx.offset_scale = offset_scale
ctx.im2col_step = im2col_step
output = DCNv3.dcnv3_forward(
input, offset, mask, kernel_h,
kernel_w, stride_h, stride_w, pad_h,
pad_w, dilation_h, dilation_w, group,
group_channels, offset_scale, ctx.im2col_step)
ctx.save_for_backward(input, offset, mask)
# # 保存所需内容,以备backward时使用,所需的结果会被保存在saved_tensors元组中;
# 此处仅能保存tensor类型变量,若其余类型变量(Int等),可直接赋予ctx作为成员变量,也可以达到保存效果
return output
@staticmethod
@once_differentiable
@custom_bwd
def backward(ctx, grad_output): # 反向传播
input, offset, mask = ctx.saved_tensors # 取出forward中保存的result
# 计算梯度并返回
grad_input, grad_offset, grad_mask = \
DCNv3.dcnv3_backward(
input, offset, mask, ctx.kernel_h,
ctx.kernel_w, ctx.stride_h, ctx.stride_w, ctx.pad_h,
ctx.pad_w, ctx.dilation_h, ctx.dilation_w, ctx.group,
ctx.group_channels, ctx.offset_scale, grad_output.contiguous(), ctx.im2col_step)
return grad_input, grad_offset, grad_mask, \
None, None, None, None, None, None, None, None, None, None, None, None
@staticmethod
def symbolic(g, input, offset, mask, kernel_h, kernel_w, stride_h,
stride_w, pad_h, pad_w, dilation_h, dilation_w, group,
group_channels, offset_scale, im2col_step):
"""Symbolic function for mmdeploy::DCNv3.
Returns:
DCNv3 op for onnx.
"""
return g.op(
'mmdeploy::TRTDCNv3',
input,
offset,
mask,
kernel_h_i=int(kernel_h),
kernel_w_i=int(kernel_w),
stride_h_i=int(stride_h),
stride_w_i=int(stride_w),
pad_h_i=int(pad_h),
pad_w_i=int(pad_w),
dilation_h_i=int(dilation_h),
dilation_w_i=int(dilation_w),
group_i=int(group),
group_channels_i=int(group_channels),
offset_scale_f=float(offset_scale),
im2col_step_i=int(im2col_step),
)
dcnv3_core_pytorch
def dcnv3_core_pytorch(
input, offset, mask, kernel_h,
kernel_w, stride_h, stride_w, pad_h,
pad_w, dilation_h, dilation_w, group,
group_channels, offset_scale):
# for debug and test only,
# need to use cuda version instead
'''
输入参数说明:
input: (N,H,W,C)
offset: (N,H,W,group*2*kernel_size*kernel_size)
mask: (N,H,W,group*2*kernel_size*kernel_size)
pad_h=pad_w 在h,w方向的填充(默认是1)
dilation_h,dilation_w : 空洞卷积率
group:分组数
group_channels: 每个组中的通道数
'''
input = F.pad(
input,
[0, 0, pad_h, pad_h, pad_w, pad_w]) # 用0填充 大小变为 (N_,H_in,W_in,C)
N_, H_in, W_in, _ = input.shape
_, H_out, W_out, _ = offset.shape # (N_,H_out,W_out,C)=(N,H,W,C)
ref = _get_reference_points(
input.shape, input.device, kernel_h, kernel_w, dilation_h, dilation_w, pad_h, pad_w, stride_h, stride_w)
# ref (1,H_out_cov,W_out_cov,1,2)
grid = _generate_dilation_grids(
input.shape, kernel_h, kernel_w, dilation_h, dilation_w, group, input.device)
# grid (1,1,1,group * kernel_h * kernel_w,2)
spatial_norm = torch.tensor([W_in, H_in]).reshape(1, 1, 1, 2).\
repeat(1, 1, 1, group*kernel_h*kernel_w).to(input.device)
# spatial_norm (1,1,1,group*kernel_h*kernel_w)
sampling_locations = (ref + grid * offset_scale).repeat(N_, 1, 1, 1, 1).flatten(3, 4) + \
offset * offset_scale / spatial_norm # 得到最终的采样点位置
# repeat 后(N_,H_out,W_out,group*kernel_h*kernel_w,2)
# flatten 后(N_,H_out,W_out,group*kernel_h*kernel_w*2)
# offset: (N_,H_out,W_out,group*kernel_h*kernel_w*2)
P_ = kernel_h * kernel_w
sampling_grids = 2 * sampling_locations - 1 # 把大小规范化到[-1,1]之间,方便F.grid_sample函数进行采样
input_ = input.view(N_, H_in*W_in, group*group_channels).transpose(1, 2).\
reshape(N_*group, group_channels, H_in, W_in)
# input: (N_,H_in,W_in,group*group_channels)
# view后:(N_, H_in*W_in, group*group_channels)
# transpose后:(N_, group*group_channels, H_in*W_in)
# reshape后:(N_*group, group_channels, H_in, W_in)
sampling_grid_ = sampling_grids.view(N_, H_out*W_out, group, P_, 2).transpose(1, 2).\
flatten(0, 1)
# sampling_grids:(N_, H_out, W_out, group*P_*2)
# transpose后:(N_, H_out*W_out, group, P_, 2)
# flatten后:( N_*group, H_out*W_out, P_, 2)
sampling_input_ = F.grid_sample( # 偏移后的采样位置
input_, sampling_grid_, mode='bilinear', padding_mode='zeros', align_corners=False) # 双线性插值
# input_: (N_*group, group_channels, H_in, W_in)
# sampling_grid_: (N_*group, H_out*W_out, P_, 2)
# sampling_input_: (N_*group, group_channels, H_out*W_out, P_)
mask = mask.view(N_, H_out*W_out, group, P_).transpose(1, 2).\
reshape(N_*group, 1, H_out*W_out, P_) # 调制标量
# mask: (N_, H_out, W_out, group*P_)
# view后: (N_, H_out*W_out, group, P_)
# transpose后:(N_, group, H_out*W_out, P_)
# reshape后:(N_*group, 1, H_out*W_out, P_)
output = (sampling_input_ * mask).sum(-1).view(N_,group*group_channels, H_out*W_out)
# *后:(N_*group, group_channels, H_out*W_out, P_)
# sum(-1)后:(N_*group, group_channels, H_out*W_out)
# view后:(N_,group*group_channels, H_out*W_out)
return output.transpose(1, 2).reshape(N_, H_out, W_out, -1).contiguous()
# transpose后:(N_, H_out*W_out,group*group_channels)
# reshape后:(N_, H_out, W_out,group*group_channels)=(N,H,W,C)
初始设置:
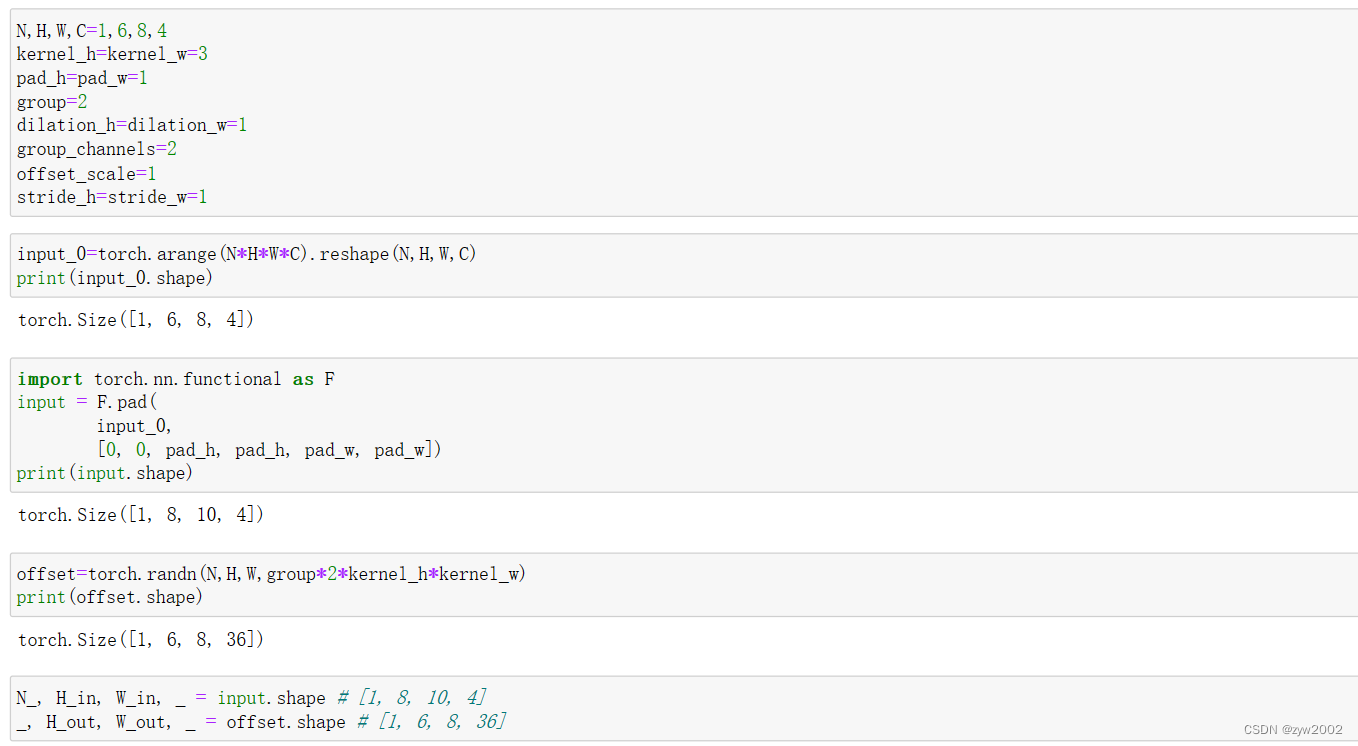
这里的sum(-1)是将kernel_size*kernel_size个像素的值简单求和,并没有和对应的weight相乘后再求和,因为此处对应的是上文所述=改进点1中的point-wise的操作。

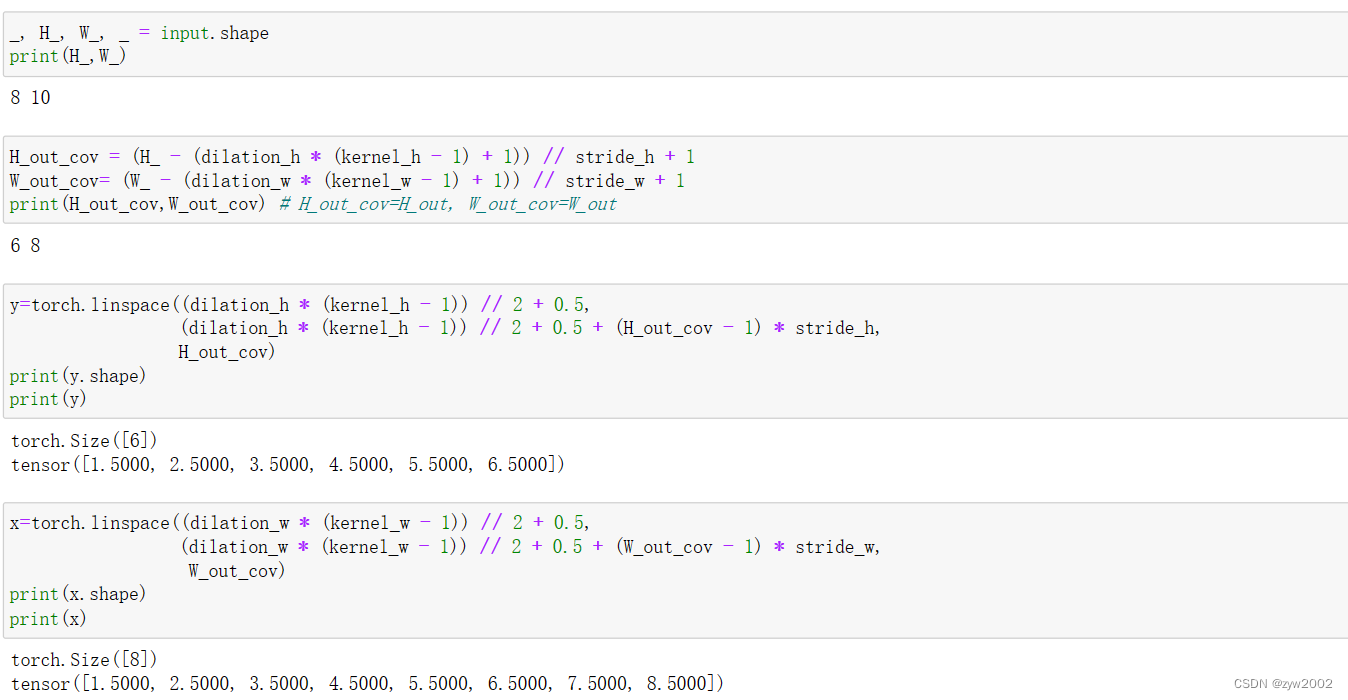
_get_reference_points
- 功能:生成大小为
(1,H_out,W_out,1,2)的reference_points, 其中H_out和W_out 和生成的offset的高宽相同。
def _get_reference_points(spatial_shapes, device, kernel_h, kernel_w, dilation_h, dilation_w, pad_h=0, pad_w=0, stride_h=1, stride_w=1):
# spatial_shapes: 原始输入pad后大小 (N_,H_in,W_in,C)
_, H_, W_, _ = spatial_shapes
# 等于offset的宽和高(pad=1,stride=1)
H_out = (H_ - (dilation_h * (kernel_h - 1) + 1)) // stride_h + 1 # H_out
W_out = (W_ - (dilation_w * (kernel_w - 1) + 1)) // stride_w + 1 # W_out
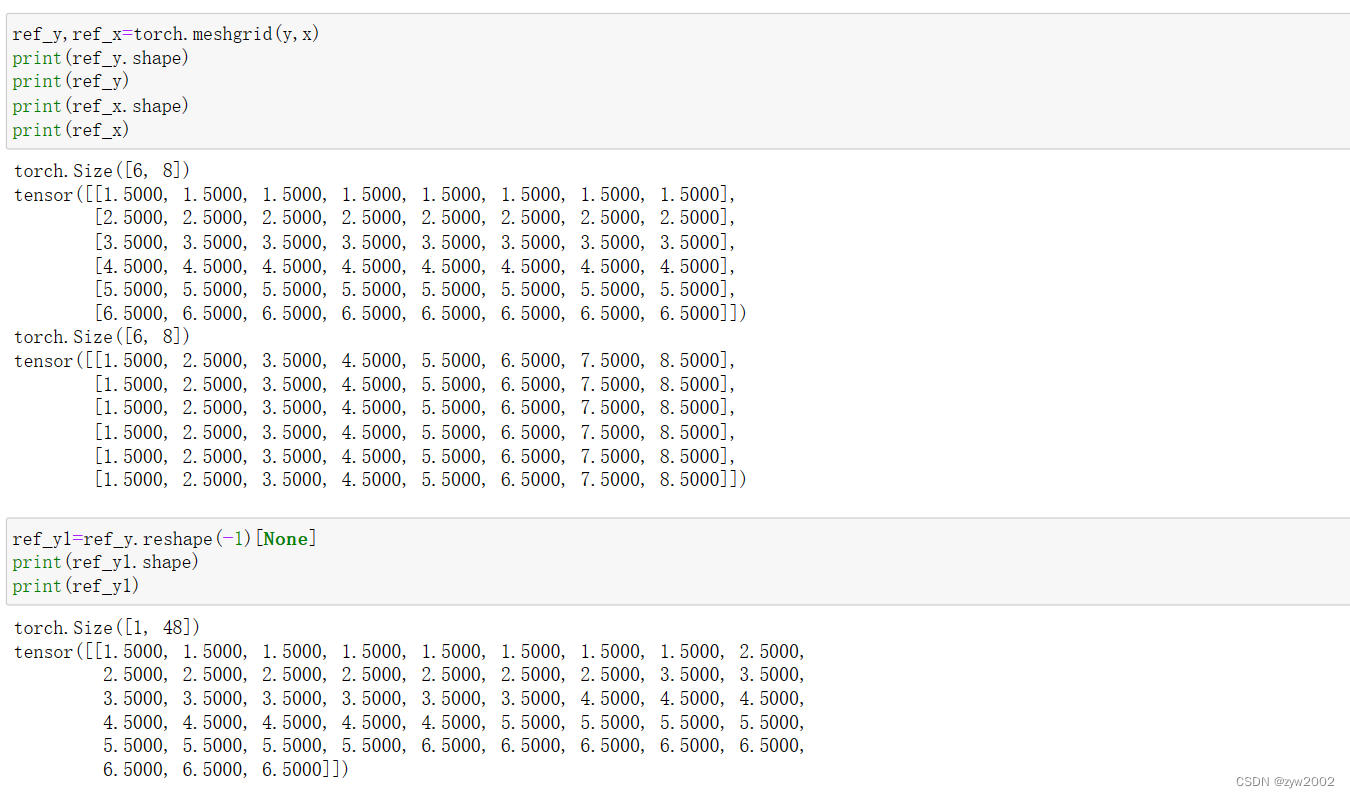
ref_y, ref_x = torch.meshgrid(
torch.linspace(
(dilation_h * (kernel_h - 1)) // 2 + 0.5,
(dilation_h * (kernel_h - 1)) // 2 + 0.5 + (H_out - 1) * stride_h,
H_out,
dtype=torch.float32,
device=device),
# 在[pad_h + 0.5,H_ - pad_h - 0.5]范围内,生成H_out个等分点
torch.linspace(
(dilation_w * (kernel_w - 1)) // 2 + 0.5,
(dilation_w * (kernel_w - 1)) // 2 + 0.5 + (W_out - 1) * stride_w,
W_out,
dtype=torch.float32,
device=device))
# 在[pad_w + 0.5,W_ - pad_w - 0.5]范围内,生成W_out个等分点
# ref_y:(H_out,W_out)
# ref_x:(H_out,W_out)
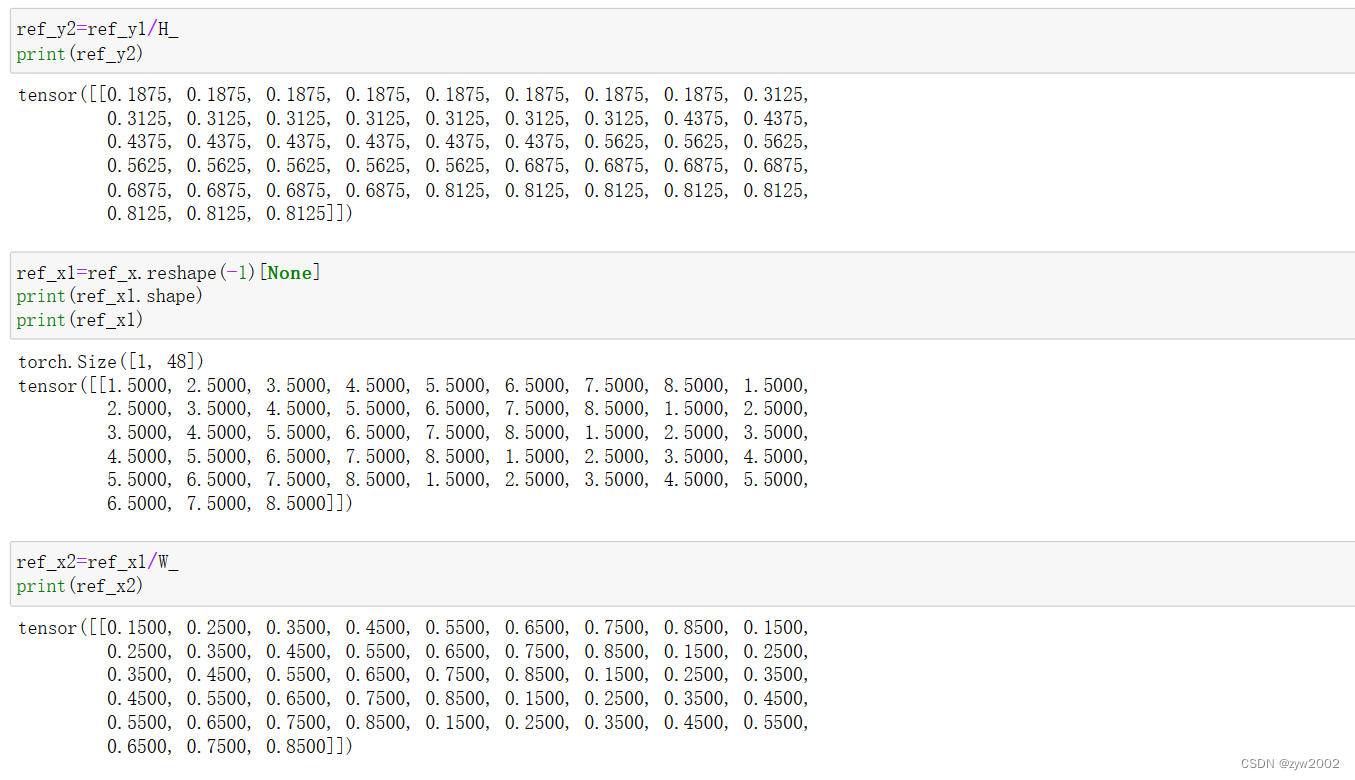
ref_y = ref_y.reshape(-1)[None] / H_ # 归一化
# reshape后(H_out*W_out)
# None后(1,H_out*W_out)
ref_x = ref_x.reshape(-1)[None] / W_
# (1,H_out*W_out)
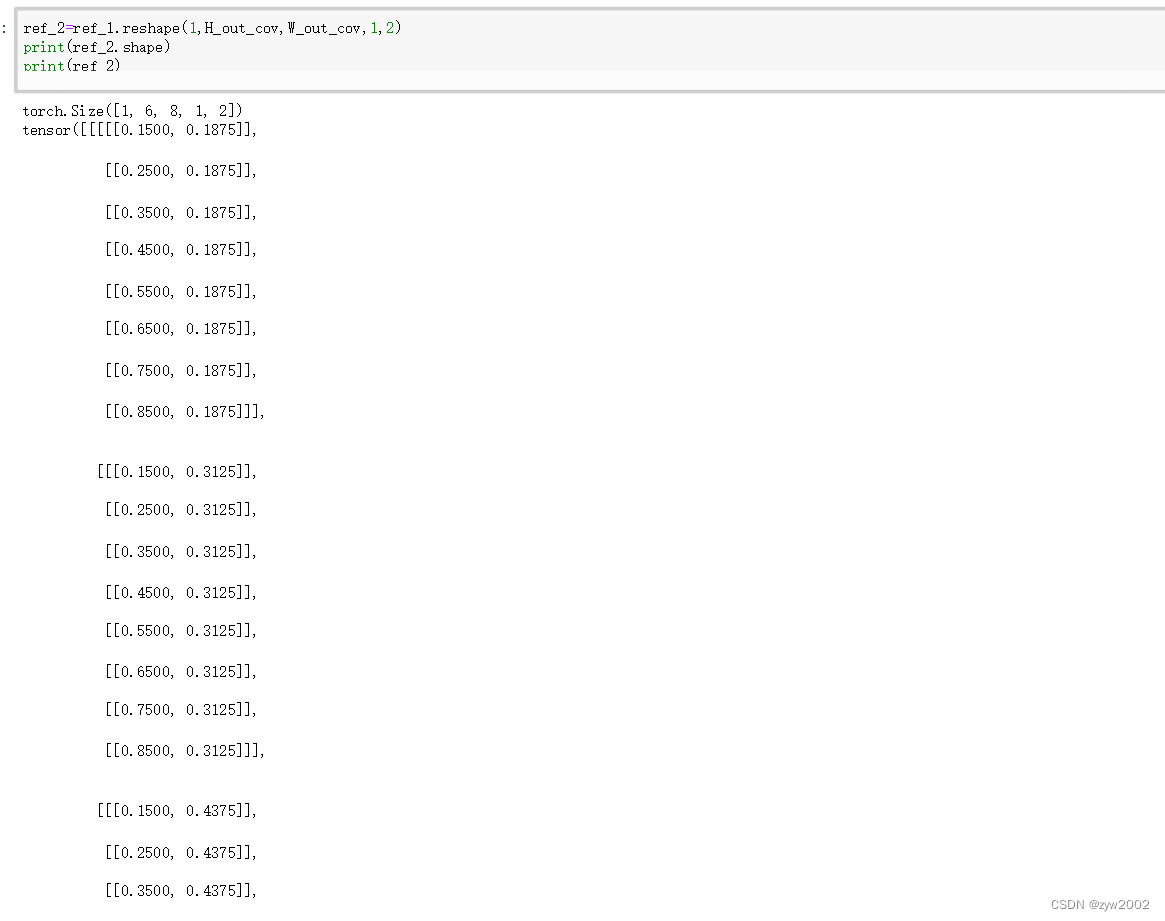
ref = torch.stack((ref_x, ref_y), -1).reshape(
1, H_out, W_out, 1, 2)
# stack后 (1,H_out*W_out,2)
# reshape 后 (1,H_out,W_out,1,2)
return ref # (1,H_out_cov,W_out_cov,1,2)

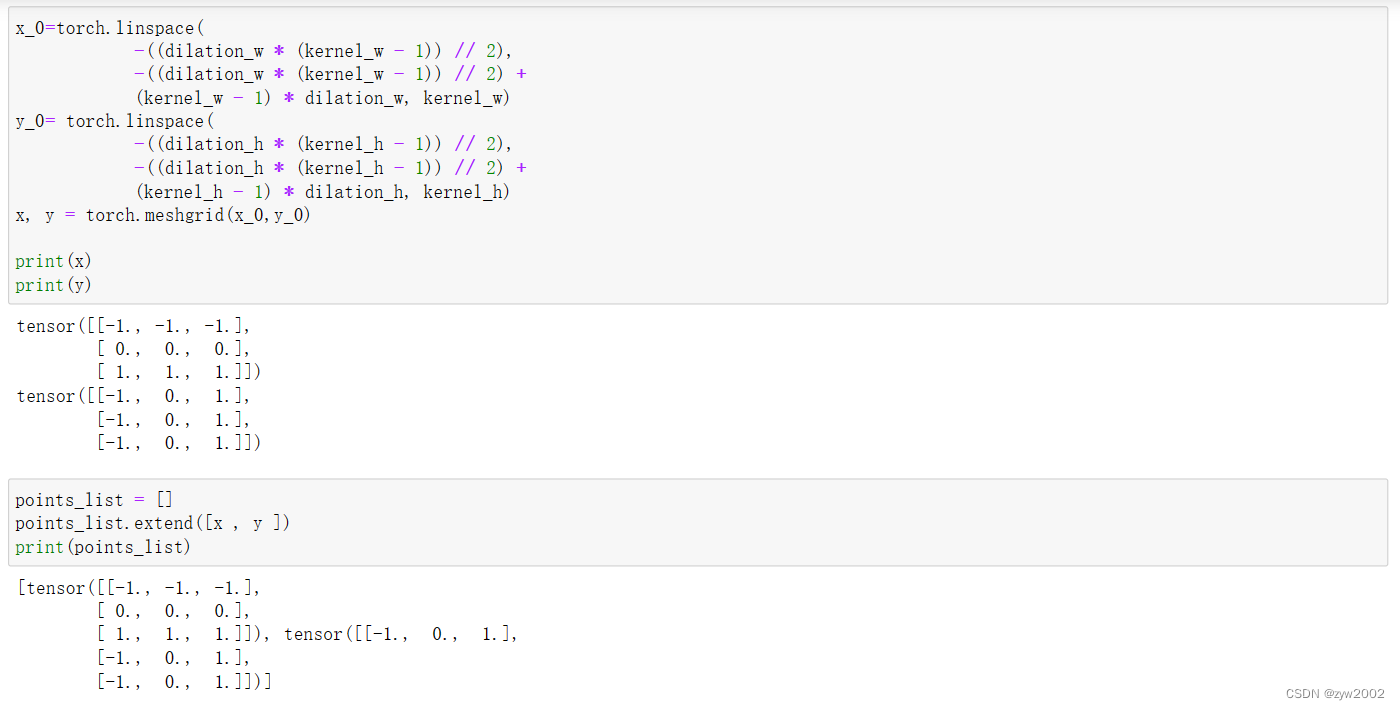
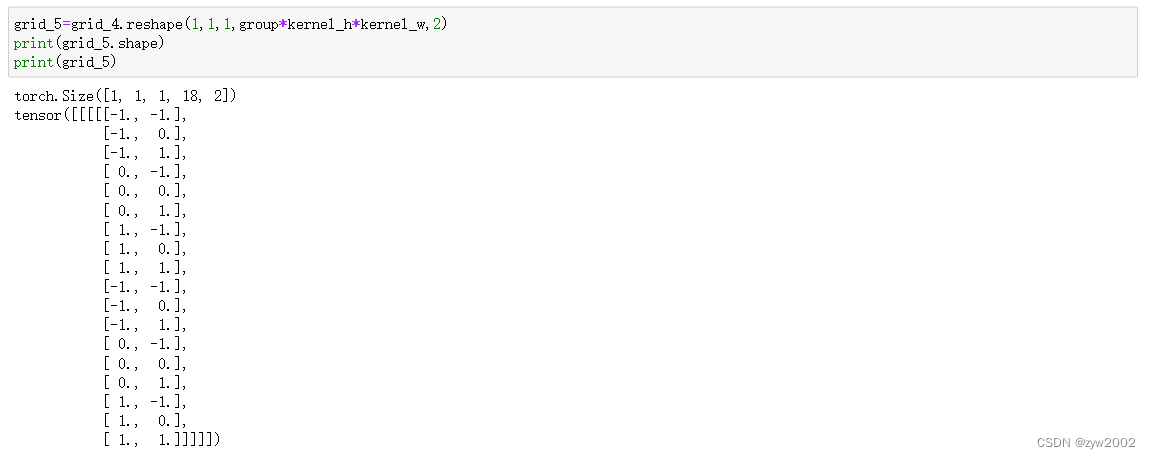
_generate_dilation_grids
- 功能:用于生成大小为
(1,1,1,group * kernel_h * kernel_w,2)的采样点。
def _generate_dilation_grids(spatial_shapes, kernel_h, kernel_w, dilation_h, dilation_w, group, device):
_, H_, W_, _ = spatial_shapes #(N_,H_in,W_in,C)
points_list = []
x, y = torch.meshgrid(
torch.linspace(
-((dilation_w * (kernel_w - 1)) // 2),
-((dilation_w * (kernel_w - 1)) // 2) +
(kernel_w - 1) * dilation_w, kernel_w,
dtype=torch.float32,
device=device),
torch.linspace(
-((dilation_h * (kernel_h - 1)) // 2),
-((dilation_h * (kernel_h - 1)) // 2) +
(kernel_h - 1) * dilation_h, kernel_h,
dtype=torch.float32,
device=device))
# x: (kernel_w,kernel_h)
# y: (kernel_w,kernel_h)
points_list.extend([x / W_, y / H_])
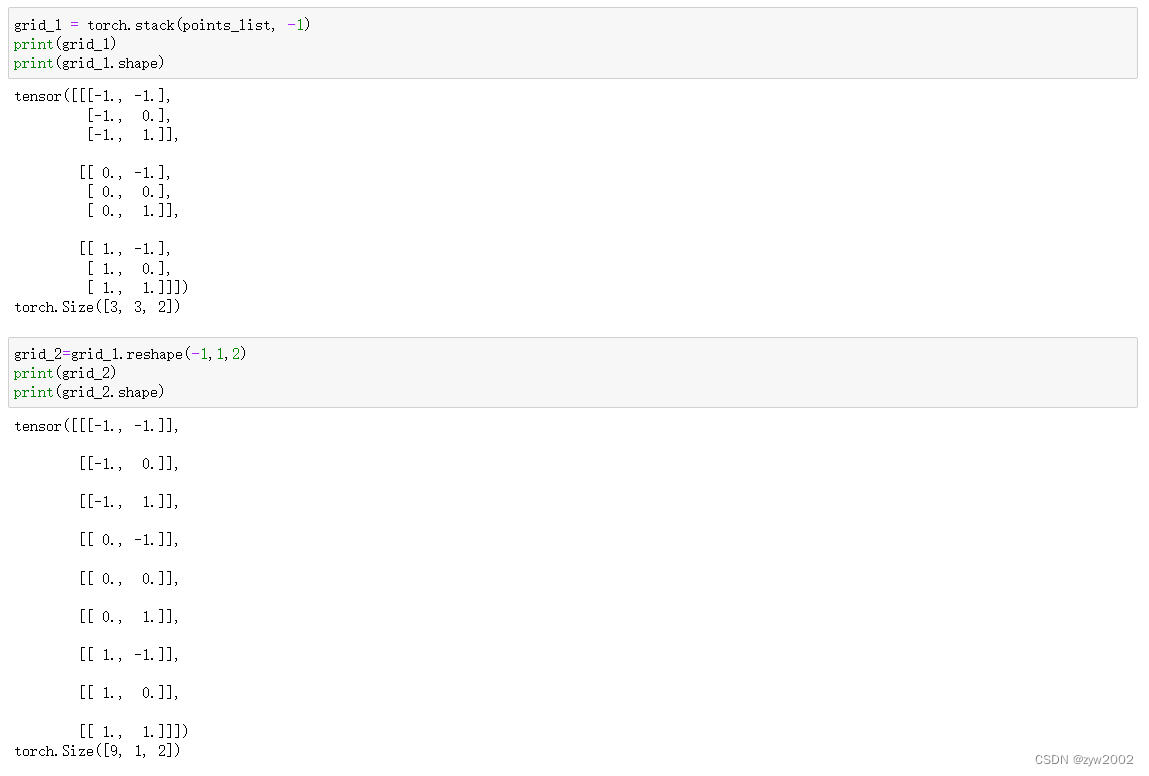
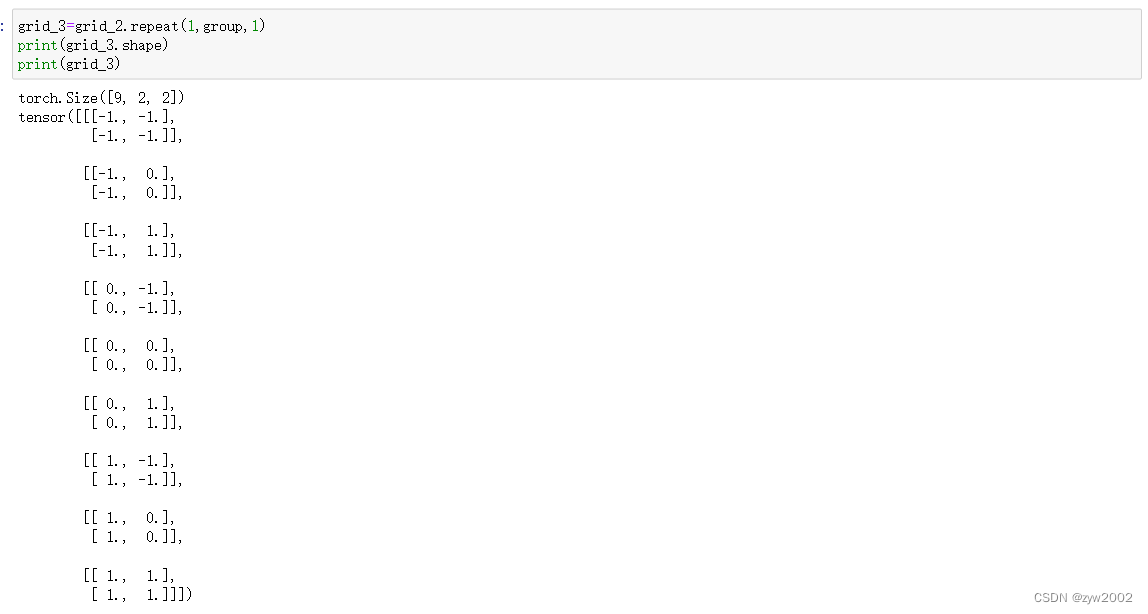
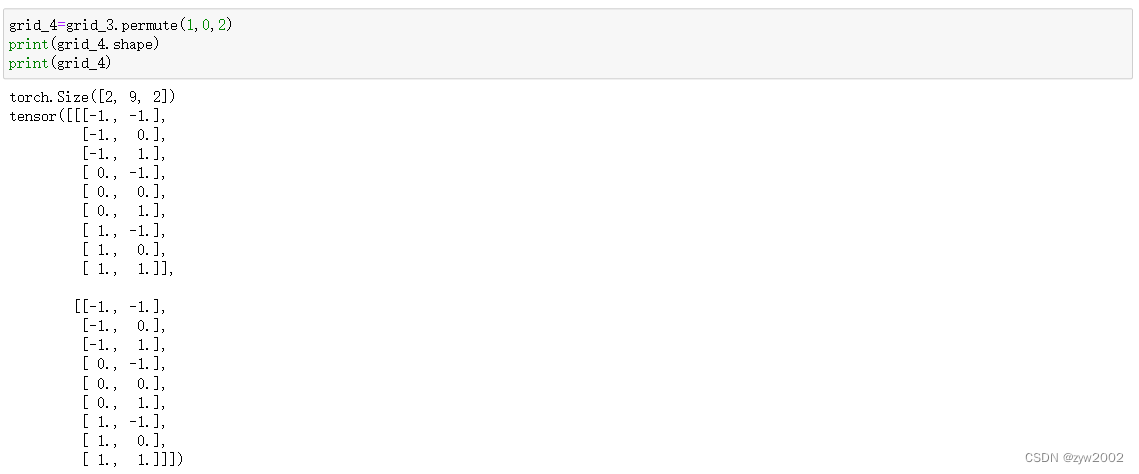
grid = torch.stack(points_list, -1).reshape(-1, 1, 2).\
repeat(1, group, 1).permute(1, 0, 2)
# stack后:(kernel_w,kernel_h,2)
# reshape后:(kernel_w*kernel_h,1,2)
# repeat后:(kernel_w*kernel_h,group,2)
# permute后:(group,kernel_w*kernel_h,2)
grid = grid.reshape(1, 1, 1, group * kernel_h * kernel_w, 2)
#(1,1,1,group * kernel_h * kernel_w,2)
return grid