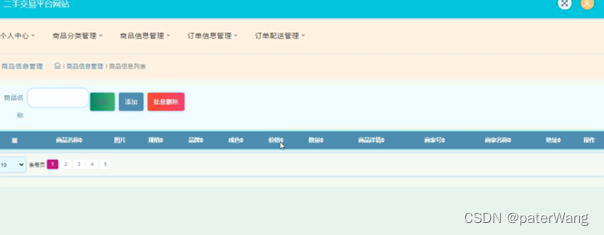
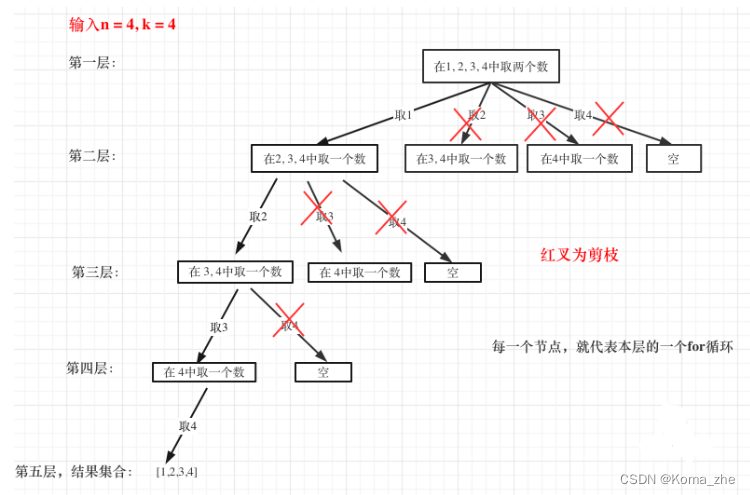
卷积神经网络在实际训练过程中,不可避免会遇到一个问题:随着网络层数的增加,模型会发生退化。
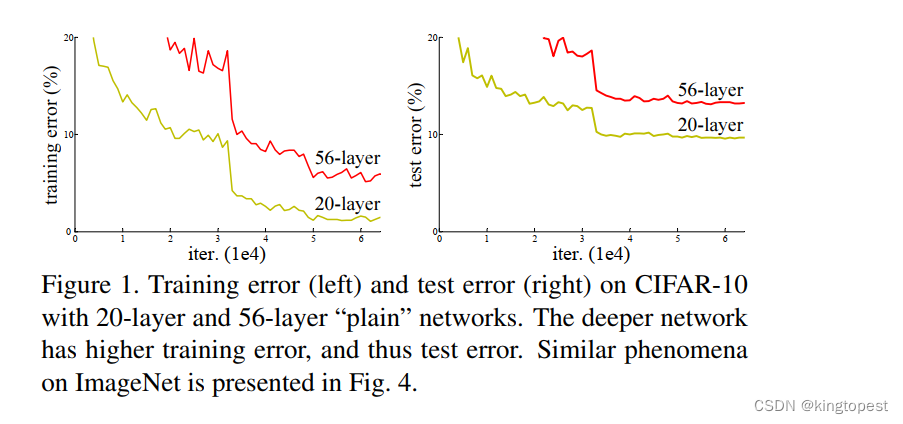
换句话说,并不是网络层数越多越好,为什么会这样? 不是说网络越深,提取的特征越多,网络的表达能力会更好吗?
要理解这个问题:需要对网络的BP反向传播算法有深入的理解。
在BP反向传播的过程中:因为链式法则的缘故,激活函数会存在连乘效应,非线性的激活函数在连乘过程中会最终趋近于0,从而产生梯度消失的问题。
我们可以选择线性激活函数,比如ReLu,以及正则化来缓解梯度消失的问题,但是并不能从根本解决问题。因为在深层网络的反向传播过程中,网络会逐渐饱和,在权重更新值极小的情况下,继续增加网络深度,反而会增加Loss, 这一点是由经验得来。
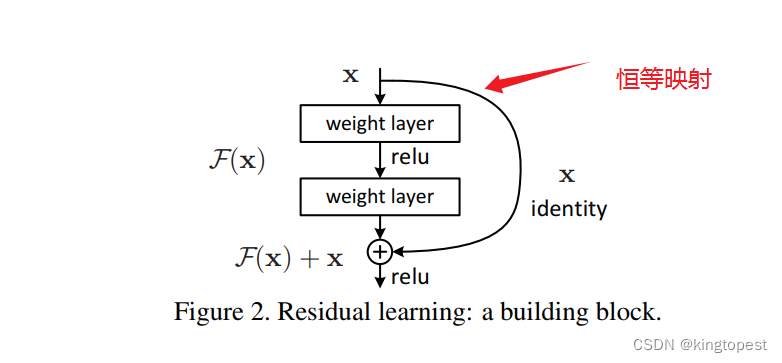
所以,我们可以有一种猜测: 深层网络中: 网络可能已经在中间某一层学习到最优解,只要能够在后续的隐藏层"什么都不学",透明传输到输入层就能解决Loss增加的问题。
这个就是恒等映射,学习到最优解后,激活函数y=x就什么都不做,把输入原样输出。 这就是残差网络的实质。
那个skip connection跳跃连接实际就是恒等映射的叠加。