auto的使用
严格来讲,在C语言中,如果某个函数中需要用到一些局部变量,那么局部变量都会集中定义在函数开头,而在C++中不必遵循这样的规则,随时用随时定义即可。当然,作用域一般就是从定义的地方开始到该函数结束为止。当然,也有例外,例如如果在一个循环中定义的变量就只在循环内有效,在一个{}包着的语句块中定义的变量就只能在该语句块内有效。典型的如for(int i=0;i<100;i++){…},i的作用域就仅仅限制在for循环体内。传统编码方式中,可以使用“=”在定义变量的时候进行初始化。代码如下:
int abc = 5;
在C++新标准中,可以使用“{}”在定义变量的时候进行初始化。代码如下:
int abc {5};
所以,针对刚才的for语句,可以换一种写法。代码如下:
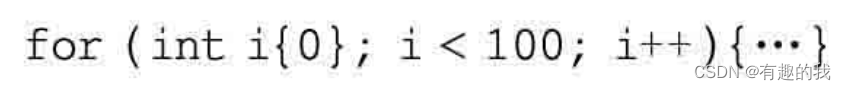
在看到了C++新标准中“{}”的用法后,需要额外说明的是,在“{}”之前还可以增加一个“=”号。如下代码:
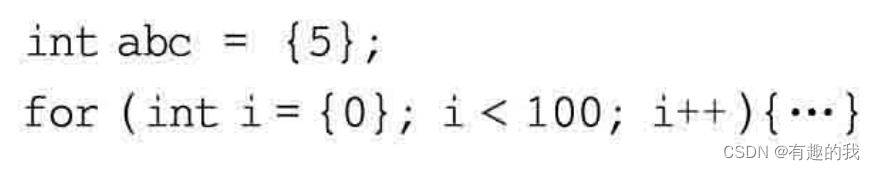
在上面的“{}”用法中,只涉及一个数据,因为只有一个变量来接收数据。实际上,如果定义一个数组,那么是可以在“{}”中包含一组数据的。代码如下:

建议在学习的时候,把这些新标准的写法单独整理和记录一下,新标准中引入“{}”这种给变量初值的方法也是有一些考虑和好处的。例如下面这行语句:
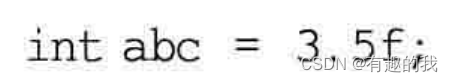
上面这行代码是可以编译通过的,但执行起来后会发现,实际上abc因为是int类型,所以3.5的小数部分会被截断,结果是abc的值等于3。那下面这种C++新标准语法呢?
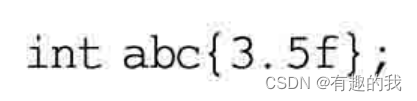
上面这行代码根本无法编译通过,直接报语法错,这样做的好处是不会使数据被误截断,进一步保证所写的代码的健壮性。
再看一例,用“()”也可以对变量进行初始化:

auto关键字简介
auto关键字其实在C++98中就已经有了,只是那时候这个关键字没什么作用,但是到了C++11中,auto被赋予了全新的含义——变量的自动类型推断。
auto可以在声明变量的时候根据变量初始值的类型自动为此变量选择匹配的类型(这表明在声明变量的同时也要给变量初始值)。auto的自动类型推断发生在编译期,所以使用auto并不会造成程序运行时效率的降低。
换句话说,在定义一个变量的时候,如果变量类型能够由系统推断出来,就不需要显示指定类型。看看如下范例:

有些类型名很长,如后面要学习到的泛型,那么,使用auto就能避免书写很长的类型名。
头文件防卫式声明
C/C++头文件中有关于#ifndef、#define、#endif的用法。
通过下面的语言描述创建一个范例:
(1)头文件head.h中有如下定义:
int g_globalh1 = 8;
(2)头文件head2.h中有如下定义:
int g_globalh2 = 5;
(3)在主源文件(MyProject.cpp)中需要用这两个全局变量,代码如下:
#include "head.h"
#include "head2.h"
int main() //主函数
{
cout <g_globalh1 <endl; //8
cout <g_globalh2 <endl; //15
}
执行上面这段代码,目前为止并没有什么问题。
(4)随着项目的增大,需要定义更多复杂的数据类型,假如现在因为一些原因需要在头文件head2.h中包含头文件head.h,于是头文件head2.h内容修改如下:
#include "head.h"
int g_globalh2 = 5;
此时编译,出现重定义错误。这是因为在源文件MyProject.cpp文件中有如下内容:
#include "head.h"
int g_globalh2 = 5;
如果上面这两行代码都展开,则结果如下:

显然globalh1被定义了两次,因此编译的时候提示出现重定义错误。
这非常让人头疼,因为保不准哪个头文件就#include了其他头文件,也保不准哪个.cpp源文件无意中就#include两次同一个头文件,上面这种是间接通过head2.h重复#include了head.h,那直接重复#include也是不可以的。例如如下代码,系统编译时也会报错:

既然重复#include的问题时有发生,无法避免,那么如何解决这个问题呢?
这就要从.h头文件本身入手,通过使用#ifndef、#define、#endif解决这个问题。首先,改造头文件head.h。改造后的内容如下:
#ifndef __HEAD__
#define __HEAD__
int g_globalh1 = 8;
#endif
接着,改造头文件head2.h。改造后的内容如下:
#ifndef __HEAD2__
#define __HEAD2__
#include "head.h"
int g_globalh2 = 5;
#endif
有一点必须说明:每一个.h头文件的#ifndef后面定义的名字都不一样,不可以重名。
如此修改后再次编译,不难发现,编译通过并能成功执行,奥妙在哪里?就在于通过使用#ifndef、#define、#endif的组合,避免了.h头文件中的内容被多次#include。例如当head.h第一次被#include到MyProject.cpp中时,#ifndef HEAD条件成立,因此下面两行代码都被#include到MyProject.cpp中:

但是假如第二次head.h被#include到MyProject.cpp中时,#ifndef HEAD条件就不成立了(因为#define HEAD代码行的存在),这样,上面两行内容就不会再次被#include到MyProject.cpp中,从而避免了重定义等错误的发生。
所以要求读者在书写.h头文件的时候,要习惯性地在文件头部增加#ifndef、#define语句行,在文件末尾增加#endif语句行。出现在.h头文件中的这三行代码,被习惯性地称为“头文件防卫式声明”。
引用
引用是为变量起的另外一个名字(别名),一般用“&”符号(以往看到过该符号,但含义与这里并不相同)表示。之后,该引用和原变量名代表的变量看成是同一个变量。所以,在理解时要理解成:定义引用并不额外占用内存。或者也可以理解成,引用和原变量占用的是同一块内存。
看看如下范例:

定义引用类型的时候必须进行初始化,不然给哪个变量起别名呢?看看如下范例,找找代码行中的错误:

看看如下范例,注意比较,看看“&”作为引用和作为取地址符时的使用区别:

再看一个比较完整的范例——引用作为函数形参:
#include <iostream>
using namespace std;
void func(int &ta,int &tb) //形参类型都是引用类型(整型引用) @
{
ta = 4; //改ta和tb值直接影响到main()中的a和b
tb = 5;
}
int main() //主函数
{
int a = 13;
int b = 14;
func(a, b);
cout << a <<" "<< b<< std::endl; //4 5
return 0;
}
常量
常量就是不变的量。前面讲解的常量一般都是具体的数值,如10、23.5等。
1.const关键字
该关键字有很多作用,但这里不准备多介绍,主要是先熟悉一下。const表示不变的意思。定义变量时,可以在前面增加const关键字,一旦增加该关键字,该变量的值就不可以发生改变。看看如下范例:

2.constexpr关键字
这是C++11引入的关键字,也代表一个常量的概念,意思是在编译的时候求值,所以能够提升运行时的性能。编译阶段就知道值也会带来其他好处,例如更利于做一些系统优化工作等。看看如下范例:
constexpr int var1 = 1;
constexpr int var2 = 11 * func1(12);
上面代码用到了func1函数,那func1函数要怎样写呢?这里必须注意,因为var2是常量,初始化时调用了func1函数,所以func1也得定义成constexpr。代码如下:
constexpr int func1(int abc)
{
abc = 16;
int a3 =5;
return abc * a3;
}
但是,在书写func1函数时必须小心,其中的代码尽可能简单。而且,某些代码出现在func1函数中还会导致编译无法通过。例如,在func1函数中定义一个未初始化的变量就会导致编译出错,必须在定义的时候初始化:
int unvar; //编译时会引发错误,必须在定义的时候初始化
再如,如果下面的for循环语句出现在func1函数中,那么for循环中的printf语句也同样会引发编译错误,
for (int i = 0;i < 100; i++)
{
//这句printf也会导致编译不过。不是这个函数有问题,而是constexpr关键字的问题
printf("good");
}
还可以进行一些尝试:
int k = 3;
constexpr int var= 11 * func1(k); //编译错误,不可以用变量k作为参数
int k2 = func1(k); //用变量k调用constexpr函数不会有问题,
//此时该函数相当于普通函数,结果当然也是在执行期间产生
可以看到,加了constexpr修饰的函数不但能用在常量表达式中,也能用在常规的函数调用中。