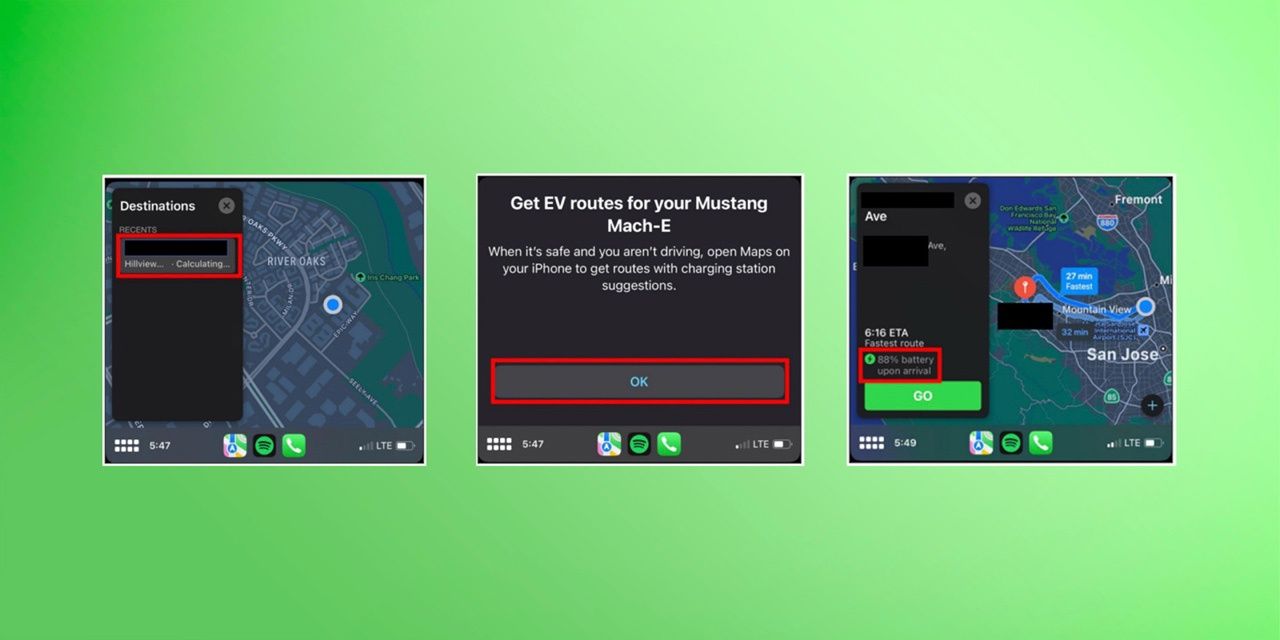
Bag of freebies 炼丹白嫖加油包
Bag of freebies、致力于解决数据集中语义分布可能存在偏差的问题。在处理语义分布偏差问题时,一个非常重要的问题是不同类别之间存在数据不平衡的问题。
一、数据增强篇 Data Augmentation
(1)图片像素调整:
- 光度失真: 调整图像的亮度、对比度、色调、饱和度、噪声
- 几何失真: 随机缩放、裁剪、翻转、旋转
(2)图片遮挡调整:
- Random Erase和 CutOut:矩形区域并填充随机或互补值零
- Hide-and-Seek和Grid Mask:随机或均匀地选择图像中的多个矩形区域并将它们替换为全零
- CutMix,MixUp :将裁剪后的图像覆盖到其他图像的矩形区域,并根据混合区域的大小调整标签,CutMix 混合 2 个输入图像。
- 风格迁移 GAN:减少 CNN 学习到的纹理偏差
- Mosaic:新的数据增强方法,它混合了 4 个训练图像。因此有 4 个不同的上下文混合,这允许检测其正常上下文之外的对象。
- 自我对抗训练 (SAT) 在 2 个前向后向阶段中运行。在第一阶段,神经网络改变原始图像而不是网络权重。通过这种方式,神经网络对其自身执行对抗性攻击,改变原始图像以制造图像上没有所需对象的欺骗。在第二阶段,训练神经网络以正常方式检测此修改图像上的对象。
二、边界框BBox的回归函数篇
(1)边界框 (BBox) 回归的目标函数。
- MSE : 传统的物体检测器通常使用均方误差(MSE)直接对BBox的中心点坐标和高宽进行回归,即{xcenter, ycenter, w, h},
- 偏移MSE : 左上点和左下点右点,即{xtop left t, ytop left t, xbottom right, ybottom right}。对于anchor‑based的方法,就是估计对应的偏移量。
但是直接估计BBox各点的坐标值,就是把这些点当成自变量,实际上并没有考虑对象本身的完整性。
(2)IOU loss损失函数
3. 传统IoU loss:将预测的 BBox 区域和 ground truth BBox 区域的覆盖范围考虑在内。 IoU损失计算过程会通过与ground truth执行IoU来触发BBox的四个坐标点的计算,然后将生成的结果连接成一个整体的代码。由于IoU是尺度不变表示,可以解决传统方法计算{x, y, w, h}的L1或L2损失时,损失会随着尺度增加的问题。
4. GIoU loss: 除了覆盖区域之外,还包括对象的形状和方向。他们提出寻找能同时覆盖预测BBox和ground truth BBox的最小面积BBox,并用这个BBox作为分母来代替原来在IoU loss中使用的分母。
5. DIoU loss ,额外考虑了物体中心的距离。
6. CIoU loss ,同时考虑了重叠区域,中心点之间的距离和纵横比,CIoU 可以在 BBox 回归问题上实现更好的收敛速度和准确性。
7. SIoU loss
———————————————————————————————————————————————————————————
Bag of specials 炼丹特价加油包
Bag of specials、只增加少量推理成本但能显着提高目标检测准确率的插件模块和后处理方法,我们称之为“ bag of specials ”。一般来说,
这些插件模块是为了增强模型中的某些属性,比如扩大感受野,引入注意力机制,或者加强特征整合能力等,而后处理是一种筛选模型预测结果的方法。
一、感受野扩大篇
用于增强感受野的常见模块有 SPP 、 ASPP和 RFB。
(1)SPP模块:起源于空间金字塔匹配(SPM),SPM最初的方法是将feature map分割成几个d×d相等的块,其中d可以是{1,2,3,…} ,从而形成空间金字塔,然后提取 bag-of-word 特征。 SPP 将 SPM 集成到 CNN中,并使用最大池操作代替bag-of-word 操作。由何凯明等人提出的 SPP 模块。
(2)ASPP [5]模块和改进的SPP模块在操作上的区别主要是从原来的k×k 卷积核,变成多个3×3 kernel size,dilated ratio等于k。
(3)RFB模块是利用多个k×k核的dilated 卷积,dilated ratio等于k,stride等于1,以获得比ASPP更全面的空间覆盖。 RFB 只需花费 7% 的额外推理时间即可将SSD 在 MS COCO 上的AP50提高5.7%。
二、注意力机制引入篇
注意力模块主要分为channel‑wise attention、point wise attention、, 这两种注意力模型的代表是Squeeze‑and‑Excitation (SE) [29]和Spatial Attention Module(SAM)。
(1)SE 模块可以提高 ResNet50 在 ImageNet 图像分类任务中 1% 的 top‑1 准确率,代价是只增加 2% 的计算量,但在GPU 上通常它会增加大约 10% 的推理时间。
(2) 对于SAM,只需要多出0.1%的额外计算,就可以提高图像分类任务上0.5%的top‑1准确率。最重要的是,它几乎不会影响 GPU 上的推理速度。
(3) CBAM
三、特征整合特征加强篇:
由于 FPN 等多尺度预测方法的流行,许多集成不同特征金字塔的轻量级模块被提出。此类模块包括 SFAM、 ASFF 和 BiFPN 。
(1) SFAM:主要思想是使用 SE 模块对多尺度级联特征图执行通道级重新加权。
(2) ASFF:使用softmax作为point‑wise level re weighting,然后加入不同尺度的feature maps。
(3) BiFPN:提出了多输入加权残差连接来执行scale‑wise level reweighting,然后添加不同尺度的feature maps。
四、激活函数篇
好的激活函数可以让梯度更高效地传播,同时不会造成太多额外的计算开销。
(1)2010年提出提出 ReLU 来实质性解决传统激活函数 tanh() 和 sigmoid() 激活函数中经常遇到的梯度消失问题
(2)LReLU和PReLU的主要目的是解决当输出小于零时ReLU的梯度为零的问题。
(3)ReLU6 和 hard‑Swish,专门为量化网络设计的,为自归一化神经网络工作。
(4)SELU 激活函数被提出来满足目标
(5)Swish 连续可微的激活函数
(6)Mish 连续可微的激活函数
五、后处理篇:
基于深度学习的物体检测常用的后处理方法是NMS,可以用来过滤掉对同一物体预测不好的BBox,只保留响应较高的候选BBox。NMS 尝试改进的方式与优化目标函数的方法很相似。 NMS 提出的原始方法没有考虑上下文信息因此出现如下优化方法:
(1)贪心NUM:加入分类置信度分数作为参考,并根据置信度分数的顺序,按照高分到低分的顺序进行过滤。
(2)SoftNUS:考虑了对象的遮挡可能导致具有 IoU 分数的贪婪 NMS 中的置信度分数下降的问题.
(3) DIoU NMS开发者的思路是在软NMS的基础上,在BBox筛选过程中加入中心点距离信息。
上述后处理方法都没有直接引用捕获的图像特征,因此后续开发的anchor‑free方法不再需要进行后处理。
————————————————————————————————————————————————————————————
BoF和BoS的选择:
为了改进目标检测训练,CNN 通常使用以下内容:
激活函数: ReLU、leaky‑ReLU、parametric‑ReLU、ReLU6、SELU、Swish 或 Mish。( PReLU和SELU难以训练,ReLU6是专门为量化网络设计的,一般不采用)
边界框回归损失: MSE、IoU、GIoU、CIOU,DIOU
数据扩充: CutOut、MixUp、CutMix
正则化方法: DropOut、DropPath 、空间 DropOut、DropBlock
通过均值和方差对网络激活函数进行归一化:批量归一化 (BN)、跨 GPU 批量归一化(CGBN 或 SyncBN、滤波器响应归一化 (FRN) 、交叉迭代批量归一化(CBN)(一个 GPU 的训练,不考虑别的归一化)
跳过连接:残差连接、加权残差连接、多输入加权残差连接或跨阶段部分连接 (CSP)
优化器篇
SGD 、Adam 、余弦退火
正则化论文篇
BN CBN CmBN
正则化篇
Backbone篇
主干负责从输入图像中提取有用的特征。它通常是在大规模图像分类任务(例如 ImageNet)上训练的卷积神经网络 (CNN)。
主干捕获不同尺度的层次特征,在较早的层中提取较低级别的特征(例如,边缘和纹理),在较深的层中提取较高级别的特征(例如,对象部分和语义信息)VGG16 、 ResNet‑50 、 SpineNet、EfficientNet‑B0/B7、 CSPResNeXt50、CSPDarknet53
Neck 论文篇
颈部是连接脊柱和头部的中间部件。它聚合并提炼了骨干网提取的特征,通常侧重于增强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔网络 (FPN) [49]或其他改进特征表示的机制。
附加块Additional blocks:SPP 、 ASPP 、RFB、SPPF、SimSPPF、ASPP、RFB、SPPCSPC、SPPFCSPC、
路径聚合块Path-aggregation blocks:FPN 、 PAN、NAS‑FPN、Fully-connected FPN、BiFPN、ASFF、SFAM、
- FPN 特征金字塔:https://arxiv.org/abs/1612.03144
提出了自顶向下和自底向上的双向融合骨干网络
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He,Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. CVPR, 2017.
- PANet路径聚合网络 : https://arxiv.org/abs/1612.03144
在 FPN 之上添加了一个额外的自下而上的路径聚合网络,即在最底层和最高层之间添加了一条“short-cut”,用于缩短层之间的路径。
Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. CVPR,2018.
- BiFPN : https://arxiv.org/abs/1911.09070
高效双向跨尺度连接和加权特征融合
Tan, Mingxing, Ruoming Pang, and Quoc V. Le. “Efficientdet: Scalable and efficient object detection.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
- SPP: https://arxiv.org/abs/1406.4729
输出固定长度的特征传给下一层
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. “Spatial pyramid pooling in deep convolutional networks for visual recognition.” IEEE transactions on pattern analysis and machine intelligence 37, no. 9 (2015): 1904-1916.
Head篇
头部是物体检测器的最后一个组成部分;它负责根据骨干和颈部提供的特征进行预测。它通常由一个或多个特定于任务的子网络组成,这些子网络执行分类、定位,以及最近的实例分割和姿态估计。头部处理颈部提供的特征,为每个候选对象生成预测。最后,诸如非最大抑制 (NMS) 之类的后处理步骤会过滤掉重叠的预测并仅保留最有信心的检测.
聚合的Dense Prediction (one-stage):
基于锚框的(anchor based) : RPN , SSD , YOLO , RetinaNet
非锚框的(anchor free):CornerNet , CenterNet , MatrixNet、, FCOS
分离的Sparse Prediction (two-stage)
基于锚框的(anchor based): Faster R-CNN , R-FCN, Mask R-CNN
非锚框的(anchor free):RepPoints
注意力机制论文篇
- SE:Squeeze-and-Excitation Networks :
Hu, J., Shen, L., Albanie, S., Sun, G., & Wu, E. (2017). Squeeze-and-Excitation Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42, 2011-2023.
- SAM: https://arxiv.org/pdf/1904.05873.pdf
Zhu, X., Cheng, D., Zhang, Z., Lin, S., & Dai, J. (2019). An Empirical Study of Spatial Attention Mechanisms in Deep Networks. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 6687-6696.
- SimAM :http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
Yang, L., Zhang, R., Li, L., & Xie, X. (2021). SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. International Conference on Machine Learning.
- CBAM: https://arxiv.org/pdf/1807.06521.pdf
结合特征空间和特征通道两种维度的注意力机制
Woo, S., Park, J., Lee, J., & Kweon, I. (2018). CBAM: Convolutional Block Attention Module. European Conference on Computer Vision.
- ECA:https://arxiv.org/abs/1910.03151
参数少,效果好
Wang, Q., Wu, B., Zhu, P.F., Li, P., Zuo, W., & Hu, Q. (2019). ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11531-11539.
- CA:https://arxiv.org/abs/2103.02907
将横向纵向的位置信息编码到通道注意力中,使得网络能关注大范围的位置信息且不会带来过多的计算量
https://doi.org/10.48550/arXiv.2103.02907
- SOCA:https://openaccess.thecvf.com/content_CVPR_2019
- s2-MLPv2:https://arxiv.org/abs/2108.01072
https://doi.org/10.48550/arXiv.2108.01072
- :NAM:https://arxiv.org/abs/2111.12419
NAM: Normalization-based Attention Module
-
:CC-Net: https://arxiv.org/abs/1811.11721
-
: GAM https://arxiv.org/pdf/2112.05561v1.pdf
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
- : Selective Kernel Networks: https://arxiv.org/pdf/1903.06586.pdf
南京理工
- :SA-NET shuffleattention: https://arxiv.org/pdf/2102.00240.pdf
SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
- A2-Nets: https://arxiv.org/pdf/1810.11579.pdf
Double Attention Networks
YOLO论文篇
- YOLOv1: https://arxiv.org/pdf/1506.02640.pdf
提出1阶段的快速检测算法,无锚框,损失函数使用MSE
Redmon, Joseph et al. “You Only Look Once: Unified, Real-Time Object Detection.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015): 779-788.
- YOLOv2:https://arxiv.org/abs/1612.08242
增加新的设计,Darknet19,为了提升召回率,应用锚框,中心点位置设置为S*S个格子的偏移+sifmoid(x)
Redmon, Joseph and Ali Farhadi. “YOLO9000: Better, Faster, Stronger.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 6517-6525.
- YOLOv3 : https://arxiv.org/pdf/1804.02767v1.pdf
干货不多,但是效果很好,主要是增加了Darknet53,残差网络.bounding box用率logic regression.
Redmon, Joseph and Ali Farhadi. “YOLOv3: An Incremental Improvement.” ArXiv abs/1804.02767 (2018): n. pag.
- YOLOv4 : https://arxiv.org/abs/2004.10934
Bochkovskiy, Alexey et al. “YOLOv4: Optimal Speed and Accuracy of Object Detection.” ArXiv abs/2004.10934 (2020): n. pag.
特别篇:YOLOv5
- YOLOv6 : https://arxiv.org/abs/2209.02976
Li, C., Li, L., Jiang, H., Weng, K., Geng, Y., Li, L., Ke, Z., Li, Q., Cheng, M., Nie, W., Li, Y., Zhang, B., Liang, Y., Zhou, L., Xu, X., Chu, X., Wei, X., & Wei, X. (2022). YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. ArXiv, abs/2209.02976.
- YOLOv7 : https://arxiv.org/abs/2207.02696
Wang, C., Bochkovskiy, A., & Liao, H.M. (2022). YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. ArXiv, abs/2207.02696.
- PP-YOLO : https://arxiv.org/abs/2007.12099
百度padlepaddle 框架下推出的
Long, X., Deng, K., Wang, G., Zhang, Y., Dang, Q., Gao, Y., Shen, H., Ren, J., Han, S., Ding, E., & Wen, S. (2020). PP-YOLO: An Effective and Efficient Implementation of Object Detector. ArXiv, abs/2007.12099.
- PP-YOLOE : https://arxiv.org/abs/2203.16250
Xu, S., Wang, X., Lv, W., Chang, Q., Cui, C., Deng, K., Wang, G., Dang, Q., Wei, S., Du, Y., & Lai, B. (2022). PP-YOLOE: An evolved version of YOLO. ArXiv, abs/2203.16250.
- YOLOX : https://arxiv.org/abs/2107.08430
Ge, Z., Liu, S., Wang, F., Li, Z., & Sun, J. (2021). YOLOX: Exceeding YOLO Series in 2021. ArXiv, abs/2107.08430.
- YOLOV6 V3.0: https://arxiv.org/abs/2301.05586
Li, C., Li, L., Geng, Y., Jiang, H., Cheng, M., Zhang, B., Ke, Z., Xu, X., & Chu, X. (2023). YOLOv6 v3.0: A Full-Scale Reloading. ArXiv, abs/2301.05586.
YOLO应用 论文篇:
论文话术:
1.For all experiments, we only use one GPU for training, so techniques such as syncBN that optimizes
multiple GPUs are not used.对于所有实验,我们只使用一个 GPU 进行训练,因此没有使用优化多个 GPU 的 syncBN 等技术。
2.消融实验
- yolov4 研究了不同主干模型对检测器精度的影响,如表6 所示具有最佳分类精度的模型在检测器精度方面并不总是最好的。分类好不等于检测好。BoF 和 Mish 进行 CSPResNeXt50 分类器训练可提高其分类精度,但进一步应用这些预训练权重进行检测器训练会降低检测器精度。,我们发现在加入 BoF 和 BoS 训练策略后,mini‑batch size对检测器的性能几乎没有影响。这个结果表明,在引入 BoF 和 BoS 之后不再需要使用昂贵的 GPU 进行训练
- YOLOV6
为不同场景下的工业应用而闻名。
不同尺寸的模型通常通过缩放技术获得。RepVGG 块的简单模型缩放变得不切实际,
为此我们认为小型和大型网络之间的网络设计的优雅一致性是不必要的
基于重新参数化的检测器的量化也需要细致的处理,否则在训练和推理期间由于其异构配置而难以处理性能下降。
可以容忍训练策略的调整,以提高准确率性能但不增加推理成本,例如知识蒸馏。注入了自蒸馏策略,在分类任务和回归任务上执行。同时动态调整来自教师和标签的知识,以帮助学生模型在所有训练阶段,更有效地学习知识。
网络设计、标签分配、损失函数、数据增强、行业便利的改进以及量化和部署.
骨干网络的设计对检测模型的有效性和效率有很大的影响。以前,已经表明多分支网络39 ]通常可以比单路径网络实现更好的分类性能,但它通常伴随着并行性的降低并导致增加推理延迟。相反,像VGG [37]这样的普通单路径网络具有高并行性和较少内存占用的优势,从而提高推理效率。最近在 RepVGG [3] 中,提出了一种结构重新参数化方法,将训练时间多分支拓扑与推理时间平面架构分离,以实现更好的速度精度权衡。
YOLOv5 是一个耦合头,其参数在分类和定位分支之间共享,而其FCOS [41]和 YOLOX [7]中的对应物解耦了两个分支,并且在每个分支中引入了额外的两个 3×3 卷积层以提高性能。在 YOLOv6 中,我们采用混合通道策略来构建更高效的 decoupledhead。
具体来说,我们将中间 3×3 卷积层的数量减少到只有一个。头部的宽度由脊柱和颈部的宽度乘数共同缩放。这些修改进一步降低了计算成本,以实现更低的推理延迟。
Anchor‑free Anchor‑free 检测器因其更好的泛化能力和解码预测结果的简单性而脱颖而出。其后处理的时间成本大大降低。有两种类型的无锚检测器:基于锚点的和基于关键点的[16、在 YOLOv6 中,我们采用了基于锚点的范式,其框回归分支实际上预测了锚点到边界框四个边的距离。
TOOD [5] 中提出,其中设计了分类分数和预测框质量的统一度量。
目标检测包含两个子任务:分类和定位,对应两个损失函数:分类损失和框回归损失。对于每个子任务,近年来都有各种损失函数。
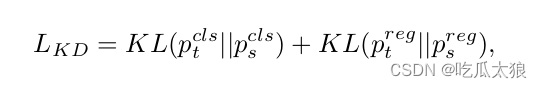
- YOLOV7
CPU 上使用的实时目标检测器,它们的设计大多基于 MobileNet ShuffleNet或 GhostNet
GPU开发的,大多使用 ResNet 、 DarkNet 或DLA ,然后使用 CSPNet策略优化网络结构
本文的贡献总结如下:(1)我们设计了几种可训练的免费赠品袋方法,使得实时目标检测可以在不增加推理成本的情况下大大提高检测度; (2) 对于目标检测方法的演进,我们发现了两个新问题,即重新参数化的模块如何替换原始模块,以及动态标签作为符号策略如何处理分配给不同的输出层。此外,我们还提出了解决这些问题所带来的困难的方法; (3) 我们提出了可以有效利用参数和计算的实时目标检测器“扩展”和“复合缩放”方法; (4) 我们提出的方法可以有效地减少 state‑of‑the‑art 实时目标检测器的大约 40% 的参数和 50% 的计算量,并且具有更快的推理速度和更高的检测精度。
The contributions of this paper are summarized as fol-lows: (1) we design several trainable bag-of-freebies meth-ods, so that real-time object detection can greatly improvethe detection accuracy without increasing the inferencecost; (2) for the evolution of object detection methods, wefound two new issues, namely how re-parameterized mod-ule replaces original module, and how dynamic label as-signment strategy deals with assignment to different outputlayers. In addition, we also propose methods to address the difficulties arising from these issues; (3) we propose “ex-tend” and “compound scaling” methods for the real-time object detector that can effectively utilize parameters and computation; and (4) the method we proposed can effec-tively reduce about 40% parameters and 50% computation of state-of-the-art real-time object detector, and has faster inference speed and higher detection accuracy.
- YOLOX
- PPYOLO