性能分析的终极目标是找到性能瓶颈,并定位到与之相关的代码段。
性能剖析可以快速让人了解应用程序热点。有时,性能剖析是开发者解决性能问题的唯一手段,尤其是针对较高层次性能问题。然而,即使解决了所有的主要性能问题,仍然需要进一步提升应用程序性能,此时只有类似于某个函数执行时间的基本信息是不够的。这时,需要从CPU角度获得额外的信息以挖掘性能瓶颈。因此,在使用本章介绍方法之前,请确保优化的应用程序已经解决了主要的性能缺陷,否则使用CPU监控特性来进行底层调优是没有意义的,这会把你引向错误的方向,而不是解决高层的性能问题,你将调试错误的方向,只会浪费时间。
介绍Intel CPU的硬件性能监控功能:
1. 自顶向下微架构分析(Top-Down Microarchitecture analysis,TMA)是一种识别应用程序低效使用CPU微架构的强大技术。它能识别负载的瓶颈,并能定位出现问题的代码的具体位置。
2. 最后分支记录(Last Branch Record, LBR)是一种在执行程序的同时连续记录最新分支结果的机制。它经常用来采集调用栈,识别热点分支,计算每个分支的错误预测率等等。
3. 基于处理器事件的采用(Processor Event-Based Sampling)是一种增强的采样技术。他的主要优势是降低采样开销和提供“精确异常”的能力。“精确事件”可以定位导致特定性能事件的具体指令。
4. Intel处理器追踪(Processor Trace)是一种基于每条指令的时间戳记录和重建程序执行过程的工具,它的主要用途是对性能故障进行事后分析和原因定位。
6.1 自顶向下微架构分析技术
最大优点在于:不需要开发者对CPU的微架构和PMC有深入的理解,就能有效地找到CPU性能瓶颈。
TMA能够识别程序中每个热点停滞执行的原因。导致停滞的瓶颈可能跟前端绑定、前端绑定、退休和错误投机相关。
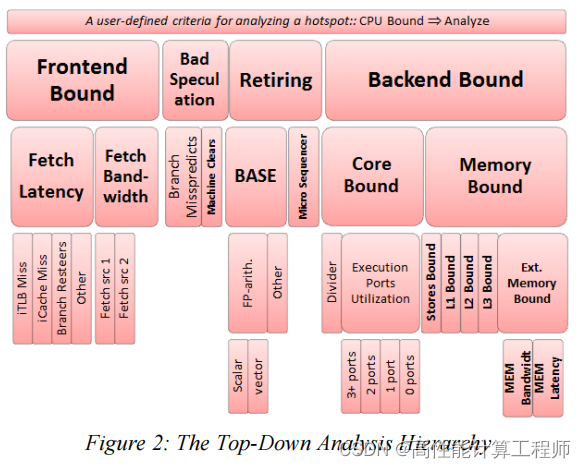
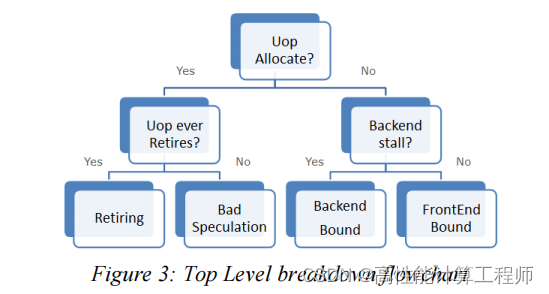
如果在指定执行时钟周期中指令对应的微操作没有被分配,可能有2种原因:不能对它进行取指和译码(前端绑定);后端负载过重导致无法为新的微操作分配资源(后端绑定)。被分配和调度执行但没有退休的微操作跟错误的投机相关。最后一种就是退休,是我们希望全部的微操作都能大到的状态,但也有例外,例如非向量化代码的高退休率可能是需要用户进行向量化的很好提示。当然,也存在非规范的浮点值进行操作会导致程序极慢,此时尽管退休率高,但整体性能却很差。
TMA通过采集特定指标(如PMC的比率)来观察程序的执行情况。通过将应用程序关联到某个分支来表征其类型,层层深入更细致分类。多次运行被测试程序,每次都关注特定的指标并向下钻,直到找到更详细的性能瓶颈分类。
在真实的应用场景中,性能可能受到多个因素。例如,它可能存在大量的分支预测错误(错误投机)和缓存未命中(后端绑定)。此时,TMA需要同时钻取多个类别,并确定每个类别瓶颈对程序性能的影响。分析工具Intel VTune Profiler、AMD uprof和linux perf可以在一次基准测试中计算所有相关指标。
前两层的TMA指标都是通过所有流水线槽位利用率来表示的。在确定程序的性能瓶颈后,TMA的第二阶段是准确定位出现问题的代码行和汇编指令。
6.1.2 Linux perf中的TMA
从Linux4.8开始,perf增加了一个--topdown参数,它可用于perf stat命令中,即perf stat --topdown -a -- taskset -c 0 ./a.exe b从而打印TMA第一层指标。-a可以剖析整个系统,taskset -c 0可以将基准测试绑定在core 0.该层只有4个类别:retiring、bad speculat、FE bound、BE bound。toplev工具获得TMA的第2、3及其他层指标,toplev是AndiKleen开发的pmu-tools工具的一部分。
6.1.3 第一步:确定瓶颈
首先,执行程序并采集指定的指标以帮助我们表征它,即查看TMA的第一层指标,然后toplev的查看更下面层级,直到TMA最底层。
6.1.4 第二步: 定位具体代码
使用与第一步中确认的瓶颈类型相关的PMU事件采集程序的负载。查找此类事件的推荐方法是--show-sample选项运行toplev工具,它们会给出perf record命令行,以定位这个问题。如果TMA方法的第一步所得出的指标是DRAM_Bound指标,则TMA的第二步采样如下perf record -e cpu/event=0xd1,umask=0x20,name=MEM_LOAD_RETIRED.L3_MISS/PPP ./a.out。和perf record -n --stdio。如果结果显示是在foo函数中,继续使用perfannotate --stdio -M intel foo查看foo中那条指令导致的性能缺陷。
6.1.5 第三步:解决问题
foo函数中问题是在将要访问的地址和实际加载指令之间有个时间窗口,所以我们添加一个预取提示给编译器。再次测试后发现L3_MISS事件变为之前的1/10。
TMA是一个迭代过程,接下来就是从第一步开始重复这个过程,虽然这可能会把瓶颈移到另一个类别中。
6.1.6 小结
不建议在有明显性能缺陷的代码上使用TMA方法,因为这可能误导你进入错误的方法。类似地,不要让环境扰乱你对程序的性能剖析。例如,文件系统的缓存被清除后,TMA很视程序为内存bound。
TMA提供的负载表征结果可以扩大除源代码之外的优化范围。例如程序是内存bound,并且所有可能的软件层面的优化方法都已经验证过了,也许可以使用更快的内存提升内存子系统。
6.2 最后分支记录LBR
为什么如此关注分支指令?因为分支控制着程序的控制流。如果我们记录了每个分支的输出,就有可能逐行重建程序的执行路径。这也就是Intel Processor Trace技术所做的。
硬件记录每条分支跳转指令的“起点”和“终点”地址以及一些附加的元数据。这些硬件寄存器像环形缓冲区,会被持续地覆写,只提供最近32个分支跳转输出。如果能够采集足够长时间的起始和终点对,就可以展开程序的控制流,类似一个有限深度的调用栈。
并不是所有被执行分支跳转指令都能被检查到,通常CPU执行得太快以至于LBR有时并不能正常工作。
6.2.1 采集LBR栈
perf record -b -e cycles./a.exe命令采集LBR栈。也可以用perf record--call-graph lbr采集信息,但是采集不到分支预测错误和时钟周期的数据。perf script -F brstack &> dump.txt导出采集的分支栈内容。
6.2.2 获取调用图
perf record --call-graph lbr -- ./a.exe和perf report -n --stdio获得调用图信息。使用LBR特性,可以识别超块hyper block,即整个程序中一条执行最频繁的基本块链条。链条中的基本块在物理上不一定连续,但是在执行顺序上是连续的。
6.2.3 识别热点分支
perf record -e cycle -b -- ./a.exe命令识别最频繁选取的分支。
6.2.4 分析分支预测错误率
perf record -e cycle -b -- ./a.exe和perf report -n --sort symbol_from,symbol_to -F +mispredict,srcline_from,srcline_to --stdio命令查看热点分支的错误预测率。其中的N代表预测错误。
perf工具通过分析每个LBR条目和解析其中的错误预测位来计算分支预测错误率。基于采样的原因,可能有些分支只有一个N行单没有对应的Y行,这意味这分支对应的LBR条目没有被错误预测。
6.2.5 机器码的准确计时
Intel从Skylake架构之后,LBR条目有了Cycle count信息,记录两个被选中的分支之间的时钟周期计数。如果前一个LBR条目中的目标地址是某个基本块的开始,而当前LBR条目中的源地址是该基本块中的最后一个指令,那么时钟周期计数就是该基本块的时延。
6.2.6 评估分支输出的概率
让热代码以直通的方式运行将会极大地提升程序的性能。
LBR特性可以在没有插桩代码的情况下获得分支真假的信息,
6.2.7 其他应用场景
1. 基于剖析文件的编译优化, LBR特性可以给编译器优化提供剖析反馈数据。考虑到运行开销问题,相比静态代码插桩方法,LBR是一个更好的选择。
2. 采集函数的参数,当LBR特性和PEBS特性一起使用时,有可能采集到函数参数。
3. 基本块执行次数,由于LBR栈中分支IP源地址和上一个目标地址之间的基本块只会执行一次,因为有可能评估程序中基本块的执行率。
6.3 基于处理器事件的采样PEBS
PEBS提供多种方法来增强性能分析。与LBR类似,PEBS被用来在每个采样点获取更多的补充数据。
补充数据有定义好的格式,被称为PEBS记录。为PEBS配置性能计数器后,处理器会保存PEBS缓冲区的内容,并最终将之转存到内存中。记录的信息包括处理器的架构状态。
用户执行dmesg命令检查PEBS是否开启。
perf工具只提供一些从原始采样数据处理后的PEBS数据,可以通过命令perf report -D获得。要获得原始PEBS记录,可以使用pebs-grabber工具。
6.3.1 精准事件
性能剖析的一个最大问题是定位导致某个性能事件的具体指令。
之前基于中断的采样是让处理器标记触发溢出的指令,这对现代复杂CPU而言,实现很困难。因此引入skip距离概念(触发性能事件的IP与标记事件的IP)。skip使得寻找导致性能问题的指令变得困难。
skip的问题让处理器自身记录PEBS记录中的指令地址得到了缓解,但是需要硬件支持,并且通常只支持一部分性能事件。这部分事件被称为“精准事件”。
TMA分析方法严重依赖于精准事件来定位低效率执行代码的具体位置。perf需要再事件后面添加ppp后缀来启动精准标注:perf record -e cpu/event=0xd1,,umask=0x20,name=MEM_LOAD_RETIRED.L3_MISS/ppp -- ./a.exe
6.3.2 降低采样开销
频繁产生中断并让分析工具采集被中断服务过程中的程序状态,都需要与操作系统交互,消耗非常多系统资源。这也是为何有些硬件允许无中断地自动对特定的缓冲区采样多次。只有当特定的缓冲区满了,处理器才会发起中断把缓冲区内容刷新到内存中。这种方式的开销低于传统基于中断的采样。
6.3.3 分析内存访问
如果性能事件支持数据线性地址功能并且启用了该功能,CPU会导出被采样内存访问的地址和时延。请注意,这个功能不会记录所有的加载和加载功能,否则开销会非常大。
PEBS扩展的重要使用场景之一就是检测真/伪共享,perf c2c工具严重依赖DLA数据来寻找有争议、可能导致真/伪共享的内存访问。
6.4 Intel处理器跟踪技术
Intel处理器PT跟踪技术是记录程序执行过程的技术,它把记录信息编码报文件存到高压缩率的二进制文件中,该二进制文件结合每条指令的时间戳重建执行流。PT技术覆盖度大、开销小(通常小于5%)。它主要用于性能问题的事后分析和根因定位。
6.4.1 工作流
类似于采样技术,PT技术不需修改任何源码。只要在支持PT技术的工具下运行目标程序,然后抓取跟踪文件即可。
在分析时,将应用程序的二进制文件和采集的PT跟踪信息汇总到一起。
6.4.2 时间报文
Intel PT不仅可以跟踪执行流,还可以记录时间信息。作为保存跳转目标地址的补充,PT工具还可以产生时间报文。
6.4.3 采集和解析跟踪文件
perf record -e intel_pt/cyc=1/u ./a.out命令请求PT机制来更新每个时钟周期的时间信息。但是,它可能不会大幅度提升准确性,因为时间报文只有跟其他控制流报文配对的时候才会被发送。然后用perf report -D > trace.dump获得原始PT跟踪文件。最后再用perf script --ns --itrace=ilt -F time,srcline,insn,srccode将处理器跟踪文件解析为可读格式。
6.4.4 用法
可能使用PT技术处理的几个例子:
1. 分析性能问题,分析在应用程序无响应的一段时间内发生了什么,
2. 事后调试, PT跟踪文件可以使用传统的调试工具gdb重放。此外,PT还会提供调用栈信息,计时在栈被破坏的情况下也总是有效的。PT跟踪文件可以在远程机器上收集,然后再离线分析。当问题很难复现或很难访问设备时,这会非常有用。
3. 程序执行的回溯:
a. 快速发现那些代码路径从未被执行;
b. 借助时间戳,当发生自旋锁尝试时,可以计算出在等待上花费了多长时间;
c. 通过检测待定的指令模式来检测安全问题。
6.4.5 磁盘空间和解析时间
即使考虑了跟踪文件的压缩格式,编码后的数据仍然会占用很大的磁盘空间。这使得PT工具并不适用于长时间运行的负载,不过大负载程序也可以用PT运行一小段时间。
用户可以通过多种方式进一步限制采集,限制只跟踪用户或内核空间的代码。此外,还有一个地址过滤的功能,动态 地控制跟踪的开启和关闭以限制内存带宽。这使得我们可以只跟踪一个函数,甚至一个循环。
解析PT跟踪文件很耗时。 Intel PT工具被本书作者认为是性能分析的终极手段,有着较低的运行开销。
6.5 本章小结
1. 只有当上层的性能问题解决之后,才建议使用硬件特性进行底层的调优。调优设计很差的算法对开发者来说就是浪费时间。
2. TMA是一种非常强大的技术,可以识别程序CPU微架构低效利用。TMA方法是一个多步骤的迭代过程,包括表征负载和定位性能发生瓶颈的精确代码位置。建议将TMA作为分析底层性能调优的分析入口点。
3. LBR可以在运行程序的同时并行持续地记录最近跳转分支指令的输出,产生的性能损耗最小,每次采样中收集足够深的调用栈,还能帮助识别热点分支、错误预测率,并提供机器码的精确时间信息。
4. PEBS不使用中断的方式自动对特定的缓冲区采样来降低采样的开销,还能精准定位到某个性能事件的具体指令(精准事件)。
5. Intel PT技术记录程序执行过程并把报文编码到高压缩率二进制文件,该压缩文件可以基于每条指令的时间戳重建程序的执行流。PT技术覆盖度大、开销小。主要用途是对性能故障进行事后分析和根因定位。