第9步---MySQL的索引和存储引擎
1.索引
1.1分类
索引可以快速的找出具有特定值的行。不用从头开始进行寻找了。
类别
-
hash和b+tree

hash
-
根据字段值生生成一个hash的值
-
快速的进行定位到对应的行的值
-
可能会出现相同的值,找到对应的空间会出现对应的值
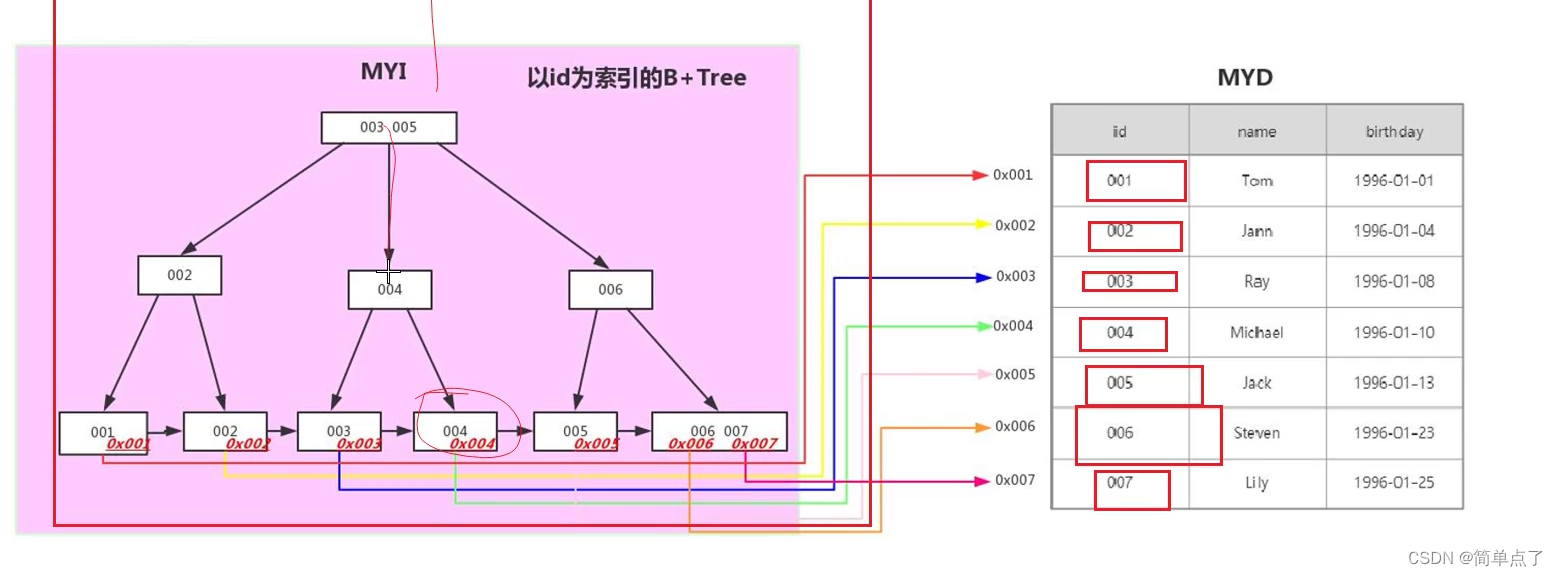
b+tree树
-
基于树的结构
-
左边的数据都是比较大的
-
中间的是相似的大小的数据
-
最右边的是比较大的数据
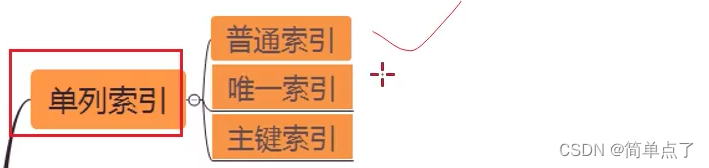
类型
-
单列:普通 唯一和主键
-
组合
-
全文
-
空间
1.2索引操作
基本语法
index 索引名字(要添加索引名称的列) -- 给name列创建索引创建的方法
三种方式
创建表的时候
直接创建
修改表的方式
创建表的时候进行指定
-- ========================索引相关操作=================
-- 方式1-创建表的时候直接指定
DROP TABLE IF EXISTS student;
create table student(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double,
index index_name(name) -- 给name列创建索引
);
刚刚创建的是普通的normal的索引的类型,创建的数据结构是btree。
之后查询指定索引的时候才是会有效的。而且数据量需要达到一定的规模不然也是不行的,速度变化不是很大的。
-- 直接创建的方式
CREATE INDEX index_gender ON student (gender);
-- 修改表结构的方式
ALTER TABLE student add index index_age(age);
1.3查看索引
-- 1、查看数据库所有索引
-- select * from mysql.`innodb_index_stats` a where a.`database_name` = '数据库名’;
select * from mysql.`innodb_index_stats` a where a.`database_name` = 'xx';
-- 2、查看表中所有索引
-- select * from mysql.`innodb_index_stats` a where a.`database_name` = '数据库名' and a.table_name like '%表名%’;
select * from mysql.`innodb_index_stats` a where a.`database_name` = 'xx' and a.table_name like '%student%';
-- 3、查看表中所有索引
-- show index from table_name;
show index from student;
最后一个就可以了。前两个是比较详细的数据的信息了。
1.4删除索引
-- 删除索引
drop INDEX 索引名字 ON 表名;
alter table student drop index index_age;
drop INDEX index_gender ON student;1.5唯一索引
创建表的时候创建唯一索引
直接创建唯一索引
修改表的时候创建唯一索引
-- 方式1-创建表的时候直接指定
create table student2(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double,
unique index_card_id(card_id) -- 给card_id列创建索引
);
-- 方式2-直接创建
-- create unique index 索引名 on 表名(列名)
create table student3(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double
);
create unique index index_card_id on student3(card_id);
-- 方式3-修改表结构(添加索引)
-- alter table 表名 add unique [索引名] (列名)
create table student4(
sid int primary key,
card_id varchar(20),
name varchar(20),
gender varchar(20),
age int,
birth date,
phone_num varchar(20),
score double
);
alter table student4 add unique index_phone_num(phone_num);
删除索引
-- 操作-删除索引
drop index 索引名 on 表名;
alter table 表名 drop index 索引名;
1.6主键索引
在设置完主键进行创建表的时候会自动进行创建不需要单独进行指定索引。

1.7组合索引
针对的是对多个字段进行索引的设置的情况
-- 创建复合索引
-- 跟顺序是有关的
CREATE INDEX index_phone_number_name on (phone_num,name);

删除组合索引
drop index index_phone_number_name on student ;创建一个组合唯一索引
-- 创建唯一索引两列的值不能相同
CREATE UNIQUE INDEX index_phone_number_name on student(phone_num,name);
当出现下面的第4种的情况的时候是不行的是会出现错误的。

什么时候可以用到索引呢?

组合索引是有原则的,最多优先的原则,尽量多的才能进行识别的。而且还遵循一个最左原则。
1.8全文索引
相似度的长度。数据量大的时候是比较好的。比全文检索的是快的。
不同的存储引擎对搜索引擎的支持是不同的。
最小搜索长度和最大搜索长度。
show variables like '%ft%';
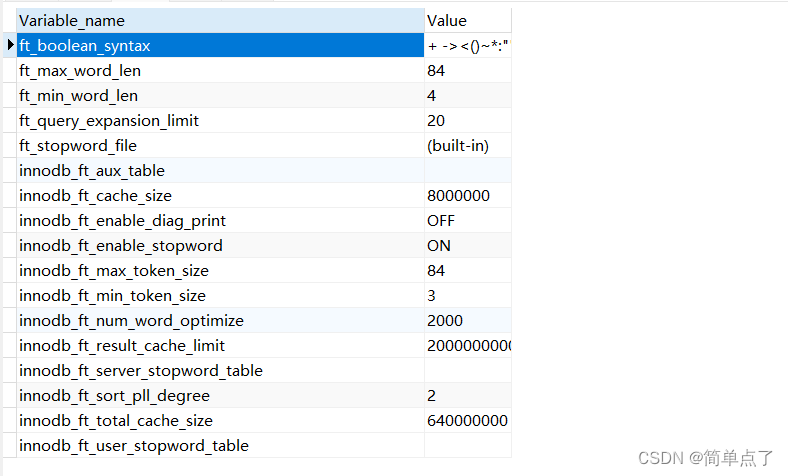
可以在my.ini文件夹下进行设置。
1.9全文检索的操作
create table t_article (
id int primary key auto_increment ,
title varchar(255) ,
content varchar(1000) ,
writing_date date -- ,
-- fulltext (content) -- 创建全文检索
);
insert into t_article values(null,"Yesterday Once More","When I was young I listen to the radio",'2021-10-01');
insert into t_article values(null,"Right Here Waiting","Oceans apart, day after day,and I slowly go insane",'2021-10-02');
insert into t_article values(null,"My Heart Will Go On","every night in my dreams,i see you, i feel you",'2021-10-03');
insert into t_article values(null,"Everything I Do","eLook into my eyes,You will see what you mean to me",'2021-10-04');
insert into t_article values(null,"Called To Say I Love You","say love you no new year's day, to celebrate",'2021-10-05');
insert into t_article values(null,"Nothing's Gonna Change My Love For You","if i had to live my life without you near me",'2021-10-06');
insert into t_article values(null,"Everybody","We're gonna bring the flavor show U how.",'2021-10-07');
创建表的时候时候创建全文索引,不推荐
-- fulltext (content) -- 创建全文检索
-- 修改表结构添加全文索引
alter table t_article add fulltext index_content(content)
-- 添加全文索引 推荐
create fulltext index index_content on t_article(content);

-- 使用全文索引
-- 跟最小的匹配的长度是相关的
SELECT * FROM t_article WHERE MATCH(content) against('you');
SELECT * FROM t_article WHERE content like '%you%';
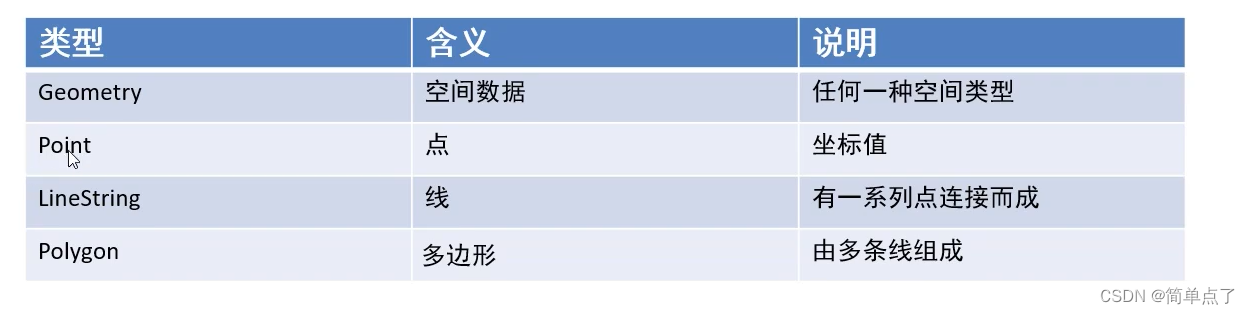
1.10空间索引
不常用
create table shop_info (
id int primary key auto_increment comment 'id',
shop_name varchar(64) not null comment '门店名称',
geom_point geometry not null comment '经纬度',
spatial key geom_index(geom_point)
);
1.11hash算法

1.12二叉树

1.13B-Tree树和B+Tree树
MyISAM引擎采用的就是b+tree树作为索引结构的。

InnerDB和myisam是不一样的。

1.14索引的特点

1.15索引使用的原则
-
经常变动的不建议
-
数据量小的不建议
-
重复数据多的不建议
-
首先对where和order by的加上索引
2.存储引擎
2.1介绍
数据库底层的如那件组织。数据库管理系统使用数据引擎进行创建查询和更新以积极删除数据。
-- 查看引擎
SHOW ENGINES;
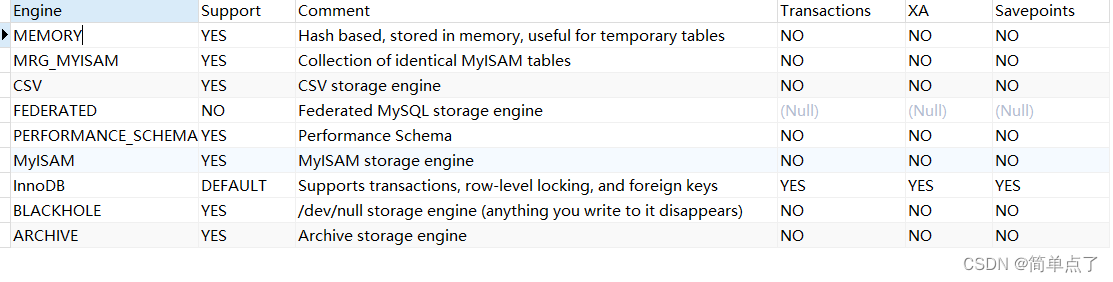
只有innnerdb是支持存储引擎的操作其他的是不支持引擎的操作的。
存储引擎的简单比较
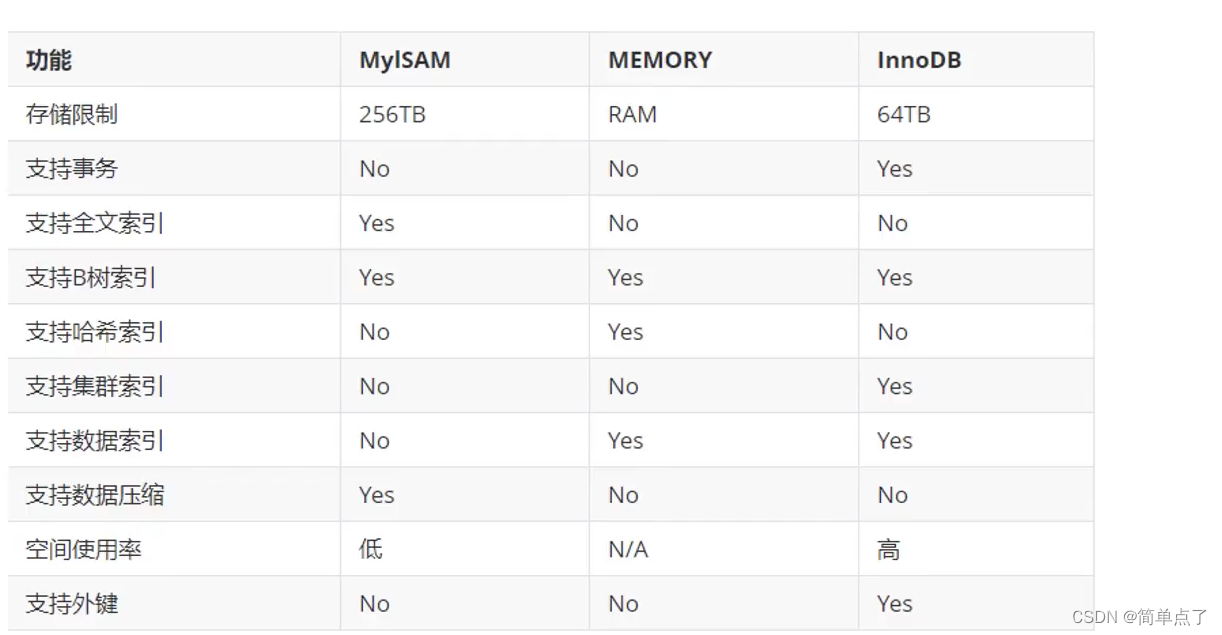
2.2基本操作
-- 查看引擎
SHOW ENGINES;
-- 查看当前默认的存储引擎
SHOW VARIABLES like '%storage_engine%'; 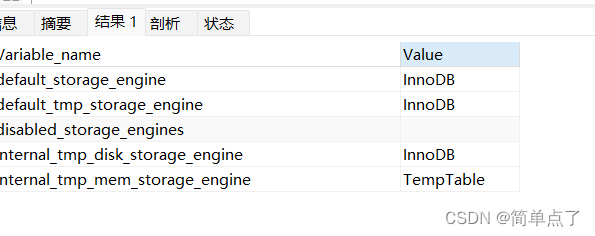
-- 查看表的存储引擎
SHOW create TABLE student;
指定创建表时候的存储的引擎
CREATE TABLE `student7` (
`sid` int(11) NOT NULL,
`card_id` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL,
`name` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL,
`gender` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`birth` date DEFAULT NULL,
`phone_num` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL,
`score` double DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=MyISAM
-- 查看创建表时候的存储引擎
SHOW CREATE TABLE student7;
修改表的存储引擎
-- 修改表的存储引擎
ALTER TABLE student7 engine = InnoDB;
SHOW CREATE TABLE student7;
修改默认的数据库默认的存储引擎
-
关闭服务
-
修改myi.ini文件
-
找到Idefault-storage-engine=INNODB 修改成自己默认的引擎
-
重新启动服务
2.3事务操作
只有innoDB的存储引擎是支持事务的操作的。
转账的时候必须需要支持事务的操作的,需要保证转出的钱是正确的。
-- 创建账户表
create table account(
id int primary key, -- 账户id
name varchar(20), -- 账户名
money double -- 金额
);
-- 插入数据
insert into account values(1,'zhangsan',1000);
insert into account values(2,'lisi',1000);
事务操作就是把几条sql绑定在一起然后采用统一的操作,将失败的进行回滚。
-
开启事务:begin 或者是START TRANSACTION;
-
提交事务:commit
-
回滚事务:rollback
-- 设置的事务的时候需要先设置事务 不能自动提交
-- 需要为一个整体设置事务的操作不能单独的进行设置事务的操作
-- 设置事务操作
-- 设置事务手动提交
SELECT @@autocommit;
-- 设置手动提交事务
set autocommit=0;
-- 设置事务自动提交
set autocommit=1;
-- 转账的操作
BEGIN;
UPDATE account set money=money-200 WHERE name ='zhangsan';
UPDATE account set money=money+200 WHERE name ='lisi';
COMMIT;

-- 先执行下面的这几句sql
BEGIN;
UPDATE account set money=money-200 WHERE name ='zhangsan';
UPDATE account set money=money+200 WHERE name ='lisi';
此时进行下面的操作
-
此时查询的数据是内存中的数据是没有进行持久化的数据
-
但是navicat中得数据是持久化的数据
SELECT * FROM account;
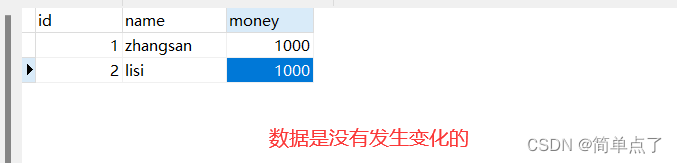
此时内存中的数据是发生变化的。
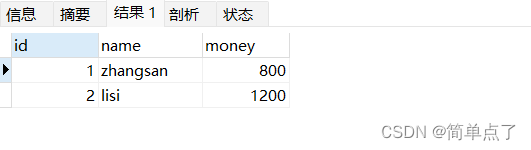
此时数据没有从内存中持久化到数据库中的,此时进行提交的话操作才能进行生效。提交了之后就不能进行事务的回滚的操作了。需要在没有提交的时候进行回滚的操作。
rollback;一般的事务的操作时通过异常才进行事务的回滚的操作。正常的时候是不需要进行事务的操作。
事务的特性
-
原子性:要么全做要么全不做
-
一致性:一个正确的状态转换成另外一个正确的状态
-
隔离性:事务之间是相互之间不能干扰的
-
持久性:事务提交之后。事务的操作时永久的不能进行更改的。
2.4隔离性
isolate:事务和事务之间要 隔离起来,比如多个事务操作同一个表。
-
读未提交:A事务会读取到B事务没有提交的数据
-
读提交:A事务不会读取B事务没有提交的数据,但是不能重复读
-
可重复读:有幻读
-
序列化:互斥的,效率低下,数据库表被锁定了

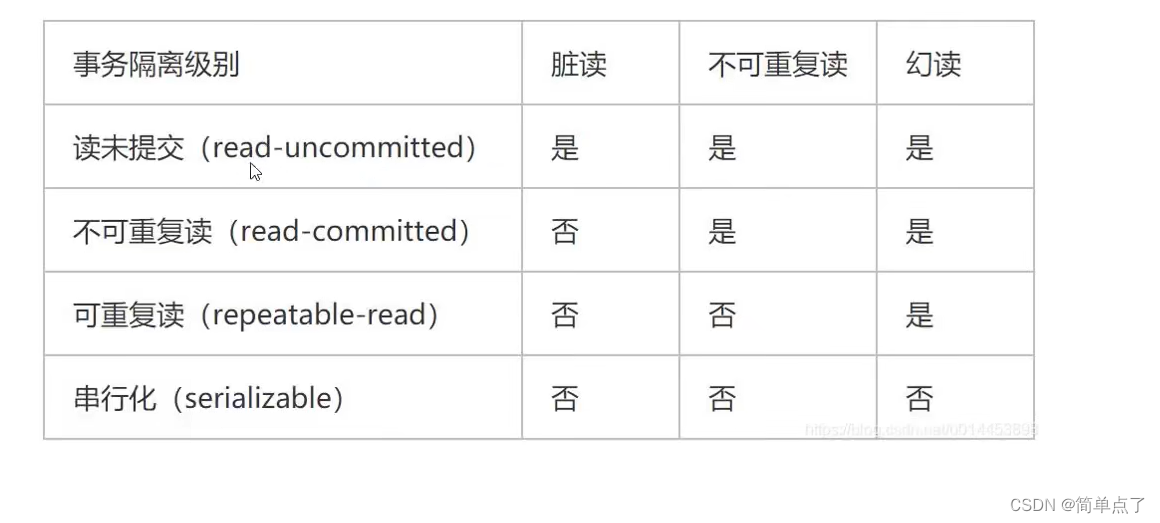
下面是隔离级别的演示
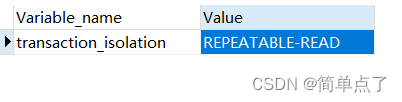
-- 查看隔离级别
show variables like '%isolation%';
此时对下面表中的数据进行相关的操作。

-- 执行下面的操作
set autocommit=0;
-- 设置隔离级别
/*
set session transaction isolation level 级别字符串
级别字符串:read uncommitted、read committed、repeatable read、serializable
*/
-- 设置read uncommitted
set session transaction isolation level read uncommitted;
-- 这种隔离级别会引起脏读,A事务读取到B事务没有提交的数据
-- 设置read committed
set session transaction isolation level read committed;
-- 这种隔离级别会引起不可重复读,A事务在没有提交事务之前,可看到数据不一致
-- 设置repeatable read (MySQ默认的)
set session transaction isolation level repeatable read;
-- 这种隔离级别会引起幻读,A事务在提交之前和提交之后看到的数据不一致
-- 设置serializable
set session transaction isolation level serializable;
-- 这种隔离级别比较安全,但是效率低,A事务操作表时,表会被锁起,B事务不能操作。
设置读未提交
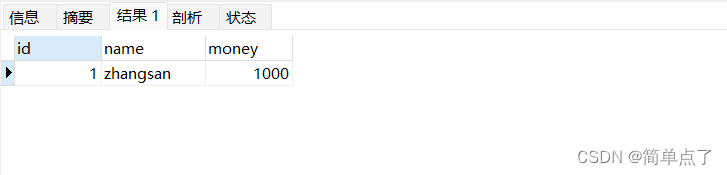
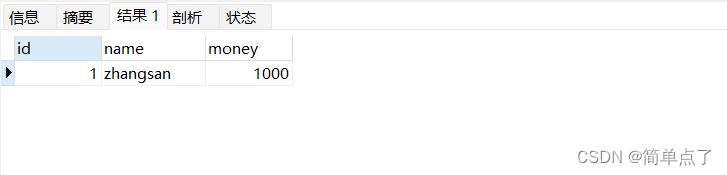
上面两个数据目前是正常的
分别执行
-- 设置隔离级别
set session transaction isolation level read uncommitted;
第一个开启事务
begin;
第二个开始事务
-- 开启事务
begin;
第一个zhangsan转出去500
UPDATE account set money=money-500 WHERE name ='zhangsan';
第二个执行
SELECT * FROM account WHERE name ='zhangsan';

当第一个回滚了事务
rollback;第二个再去执行
SELECT * FROM account WHERE name ='zhangsan';
此时查询到的数据就是1000
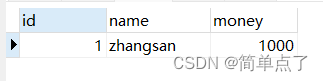
出现了脏读。
设置读已提交
续








![linux学习(文件系统+inode)[14]](https://img-blog.csdnimg.cn/50d40015930f40ca9fe58196c2e901ec.png)
