摘要
时序预测这个领域的工作与很多其他领域类似,我们可以按“深度学习”方法的引入作为分界线。在此之前的方法是传统的时序建模方法,比如移动平均、自回归、以及结合差分的ARIMA模型等,有着悠久的历史以及基于理论基础的可解释性。但是,这类方法一般要求时间序列是平稳的,而且对于多变量协同预测要做很多人工处理,因此主要适用于小规模单变量的时序预测问题。在当前的大数据应用场景下,用深度神经网络粗暴的自动提取特征,虽然丢失了可解释性,但性能远超传统方法。
使用神经网络对于序列信息进行建模的经典方法是循环神经网络(RNN: Recurrent Neural Network)及其各种变种(LSTM: Long Short-Term Memory、GRU: Gated Recurrent Unit)。然而,RNN的训练难以并行化,而且对于长序列建模面临梯度消失和梯度爆炸等问题。2017年基于自注意力机制的Transformer架构横空出世,Google展示了它在机器翻译领域的绝佳性能。自此以后,无数文章前仆后继把Transformer用于各种序列信息建模,把所有之前用到RNN的问题都洗了几遍,把SOTA性能刷的也是死去活来。这一两年来,Transformer也开始对CNN相关问题下手,刷榜还在如火如荼地进行中,这是题外话,咱们就不展开说了。
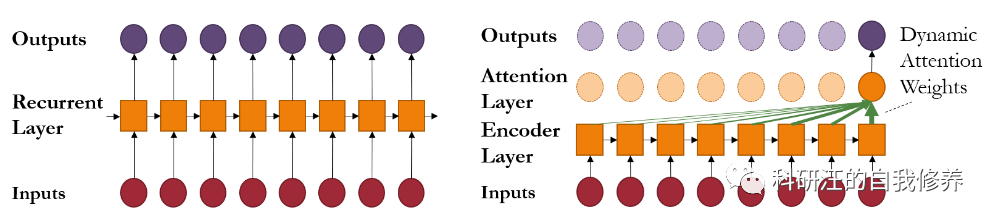
Tranformer确实在序列建模方面性能出色,但也有个重大弱点,那就是复杂度非常高,对计算和存储资源的消耗极大,速度也比较慢。因此近年来有很多工作尝试在对性能影响不大的前



![[附源码]Nodejs计算机毕业设计基于的餐厅管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/89cfee27fe99439588602cd9fb55ae8f.png)



![[附源码]Python计算机毕业设计高校请假管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/fbe1d63c410449f4aa85c6db1f9b8404.png)