文章目录
- 引言
- 正文
- Abstract
- Introduction
- 问题
- 2 Problem And Task Definition
- 3. Official Dataset And Baseline第一部分
- 问题
- 4. Evaluation
- 问题
- 4.1 Step 1:Objective Evaluation
- 问题
- 4.2 Step 2: Subjective Evaluation
- 问题
- 4.3 Execution(非重点)
- 5 Results
- 6 Conclusion
- 总结
引言
- 这是一篇竞赛性质的说明论文,因为需要对FoleySound做一个标准且全面的认知,所以需要好好读一下,同时也是为了方便和老师做汇报。
- 之前在DCASE的官网上看过简短的介绍,但是尚且不足以形成一个完整的文档和介绍,所以需要好好翻译并且读一下这篇文章。
正文
Abstract
- 多媒体后期制作中,一般会进行配音,添加一些伪声,借此来提高视听效果。传统的伪声添加都是通过伪声师(FoleySound Artists),他们一般是使用之前记录的声音或者使用特定的道具进行模拟。然而,声音合成和生成的最新技术能够很好的应用于半自动或者纯自动的伪声合成。
- 为了进一步促进声音合成技术在伪声合成(FoleySound)领域的应用,我们在今年的DCASE中专门组织了这个比赛:任务 7-Foley Sound Synthesis伪声合成。这个挑战的主要目标是为伪声系统提供一个标准的评测框架,这个框架要严密高效,能够检测不同的伪声合成系统。
- 我们总共收集到了17个版本的提交,分别对这17中方法进行主观和客观的评测,根据三个原则对他们进行排名:音频质量、适应类别的程度和多样性。通过这个挑战,我们希望估计研究社区的积极参与,并且推进自动FoleySound的技术发展。
- 在这篇技术报告中,我们将会提供一些这个挑战所涉及的具体系统,包括任务的定义、数据集、baseline模型、测试模式和原则、比赛结果和最终的讨论。
Introduction
- 近几年,生成模型在在各个领域都快速发展,包括图片生成、文本生成、音乐生成和声音生成。这一类模型能够生成高质量并且不同的样例,他们已经广泛用于学术界和工业界。最近几年,越来越多人关注声音生成领域了,随和声音合成和生成模型的快速发展,现在已经能够创建很多逼真并且不同的音频内容了。
- 声音合成对于提高多媒体的音频体验感还是很关键的,比如说电影、音乐以及视频等。自动伪声合成系统或者机器辅助的音频合成系统,已经初具能力来简化创建这些音效的流程了,同时还能释放多媒体创作者的时间和资源。
- 为了进一步促进自动伪声合成(Foley Sound Synthesis)领域的发展和研究,我们提出了这个挑战。想通过这个挑战来提供针对不同检测系统的标准检测框架。
问题
- music generation和sound generation有什么区别
- Music generation音乐生成,关注生成音乐的旋律、和声、节奏和结构,需要符合一定的结构和顺序。
- sound generation声音生成,涉及的更加广泛的声音,在某些情景下,声音生成还涉及到创建特定的声小,比如说在电影或者游戏中使用的FoleySound声效。
2 Problem And Task Definition
-
我们将这个挑战的问题定义为“category-to-sound”(指定类别生成声音),类别如下:狗叫、枪声、键盘声、骑行摩托车的声音、下雨声还有咳嗽的声音。每一段声音都是4秒钟的单声道的片段,采样率是22,050Hz
-
**这是这个比赛举办的第一年,我们选择让整个系统的输入为声音的类别,而不是自然语言的文字输入。**这样做是为了省力,并且降低比赛的门槛。这七种声音作为生成的目标,具体原因如下:1、这七种声音对于媒体创作是有用的; 2、通过手动审查,收集足够过的训练\评估数据是可行的;3、对于评估者而言,这七种声音比较好评判。
-
虽然已经简化过了,这个挑战的主要的目的还是为了构建在现实世界中具有普适性和潜在实用性的方法。所以,你提交过来的系统不应该是简单复制输入的声音,或者是单纯从别的数据库中检索相似声音的系统。
-
我们的目标是激起大家对于FoleySound合成的新方法的研究兴趣。同时,我们都知道,在机器学习领域,大量的数据确实能够快速提高模型的效果,所以我们创建了两个挑战路线:
- 1、可以使用外部的数据源来增强提供的数据集
- 2、不可以使用任何额外的数据集,只能用我们提供的数据
-
为了提高挑战的效率,我们也提供了两个预训练的模型,HiFi-GAN和VQ-VAE,这是专门给任务二提供的。这些模型是使用官方数据集进行训练的。
-
为了能够公平并且正确的对结果进行测评,我们需要参赛者提供Google Colab的笔记本。
3. Official Dataset And Baseline第一部分
-
项目中使用的音频数据集时长加起来总共有6.1个小时,每一个标注有不同的类别,分别是:脚步声、打喷嚏、雨声、狗叫、摩托车移动的声音、枪声和键盘打字声。这七种类别是城市声音分类中常见的类别。七个类分别是“人类”、“自然”和“机械”三个顶层角度选择的。彼此之间没有重叠
-
数据主要来自UrbanSound8K,FSD50K和BBC Sound Effects三个数据集来。我们对每一段音频进行了两个步骤的预处理。首先,搜集所有和七个类别标签相近的所有的音频样本。然后,为了确保数据的一致性,我们将所有的音频处理为单声道、16位、22,050Hz的音频,然后在对其进行填补或者分割为4秒钟的音频。第二步的处理是应用在选音频之前的,因为音频事件仅仅是完整音频的一小部分。
-
为了提高数据集的质量,我们从三个角度选择每一个类别的音频,分别是可靠性、差异性和清晰度。一个人负责一个类别的音频,但是其他人会去验证。总的来说,总共选择了5,550段标记的声音片段,每一个类别的数量分别是681到900个
-
我们将数据集划分为训练集和测试集。训练集每一个类别的数量不一样,但是测试集每一个类别都是100个样本。不会存在一个测试集和训练集会来自同一个片段的相近音频。
-
作为baseline系统,是由三个独立训练的模块构成。PixelSNAIL、VQ-VAE和HiFi-GAN.第一个模块PixelSNAIL是一个自回归模型,将声音类别的输入转换为时频域的表示。第二个模块,是VQ-VAE,将PixelSNAIL的输出转换为Mel频谱图,通过一个紧凑并且潜在向量的解码器。最后一个模块,HiFi-GAN,VQ-VAE的输出Mel频谱图转换为时域音频信号。
-
我们选择上述模型作为baseline的原因如下
- 模型被分为两个任务,分别是重建任务和生成任务,这提高了整个架构的可解释性。
- 参赛者可以重用这些模块,因为每一个模块都是独立训练的,所以参赛者可以通过该别某一个特定模块的结构或者方案,其他的不变,来提高性能。
问题
-
UbranSound8K、FSD50K和BBC Sound Effects三个数据集介绍
- UrbanSound8K:
- 描述: UrbanSound8K 是一个声音数据集,专门包含来自城市环境的声音。
- 内容: 它包含了8,000个10秒钟的声音片段,这些片段被分为10个不同的类别,如汽车喇叭、儿童玩耍、枪声等。
- 用途: 该数据集主要用于声音分类任务,特别是在城市环境噪声的上下文中。
- FSD50K:
- 描述: FSD50K (Freesound Dataset 50K) 是一个开源的声音数据集,由Freesound提供。
- 内容: 它包含了约51,000个声音,涵盖了多种声音类别。
- 用途: 该数据集主要用于声音分类、声音标注和其他声音处理任务。
- BBC Sound Effects:
- 描述: BBC Sound Effects 是由英国广播公司 (BBC) 提供的一个声效库。
- 内容: 它包含了数千个声音效果,涵盖了从自然声音到人造声音的各种类别。
- 用途: 这些声音效果主要用于广播、电影和电视制作。
- UrbanSound8K:
-
单声道、16位、22050Hz的音频数据
- 单声道:
- 音频只有一个通道,并不像立体声,有两个通道,可以提供空间感
- 16位
- 音频的位深度或者量化数,决定了每一个音频样本可以采用的不同值的数量
- 16位是CD印制的标准位深度
- 22050Hz
- 音频的采样率,每秒钟从音频信号中采集的样本数
- 单声道:
4. Evaluation
-
对这个任务提供准确的评判标准和解释还是很难得,所以必须提供多个评价指标,但这样会让比赛的排名变得很复杂。不同于分类任务,生成标签,这个是生成声音,需要对声音质量进行测评。这个问题目前还是在积极研究中,所以我们采用了主观和客观两个角度来评价生成结果。
-
具体来说,我们采用了两个步骤。首先对所有提交的系统使用客观评分标准进行排名。然后在对前四个评分最高的,进行主观评分,主观评分就是我们比赛的组织者直接听,进行评价。
-
我们决定衡量一下两个质量标准
- 音频感知质量:生成声音的清晰度,不受任何伪影,模糊性,退化,失真还有噪声的影响。
- 类别切合度:声音被划分为特定类别的程度。
- 差异度:系统产生同一类别不同声音的能力。
-
上述执行诶质量标准通常牵扯到人类的高层次的感受和认知过程,所以不能仅仅通过简单的计算过程来估计。因为这个原因,我们选择使用主观指标来补充客观指标。虽然必不可少,但是主观估计往往会受到很多约束。不同的人根据听到的上下文不同,可能会给出不同的排名,而且评判过程会很累。由此,我们仅仅对客观指标的前四个进行主观指标计算,不全部都进行主观指标的计算。为了确保不同评分者的上下文是相似的,每一个音频样本应该包含一些参考点,即一些明显的高音或者低音。通过参考点,有助于是的主观指标尽可能公平公正。
问题
- 伪影artifacts,模糊性fuzziness,退化degradation和失真distortion几个影响指标的含义
- artifacts伪影或人为产生的效果:这种噪声通常指的是由于数据压缩、转换或其他处理过程中引入的不期望的效果或声音。例如,某些音频编码方法可能会在压缩过程中,引入听得到的伪影。
- Fussiness模糊性:在音频中可能指的是声音的不清晰或则不明确。一般是由于低质量的录音过度或者过度的压缩或其他因素造成的。
- Degradation降解:音频质量的减少和损失。一般是由于多次复制、低质量的转换或存储在劣质介质上造成的。
- Distortion失真:音频信号被扭曲或者改变,与原始信号不同
- Noise噪声:任何不期望的声音或者干扰。
4.1 Step 1:Objective Evaluation
- 我们采用了Fr ́echet音频距离(FAD) ,一个无参考评估指标。需要对每一个类别尽心FAD计算。主要是通过七个类别的的FAD平均分对系统进行排名和评估,只有评分最高的系统,才会采取第二步。
问题
- 无参考评估指标 reference-free evaluation metric
- 指的是在没有基准或者参考的情况下,对目标进行评估的方法或者指标。
4.2 Step 2: Subjective Evaluation
- 主观检测是通过两个步骤进行实现的。第一个是线上调查,主要是衡量音频对于类别的符合度和音频的感知质量。类别切合度要求听者能够对对声音进行分类,可选项不仅仅是给出的七种声音类别。每一个类别选20个声音片段进行执行。
- 二十个声音的选择过程如下:首先计算所有样本的OpenL3 嵌入,并对他们进行K-means聚类,选择其中距离最近的20个样本。
- 评估这需要同时对感知质量和类别切合度两个指标进行评估。每一个指标都有0-10的11个等级,可以听很多遍,并对两个指标进行评分。
- 在对每一个类别进行评估之前,评估者先听听看标注的声音是什么样,然后在进行打分。
问题
- OpenL3是什么
- openL3是一个音频和图像embedding工具,将数据转化为一个新的表示形式,通常用于机器学习任务
4.3 Execution(非重点)
- 这段文本描述了一个音频评估挑战的主观评分过程。参与者需要对多个音频类别的质量和匹配度进行评分,总时长约3-6小时。评分过程中使用了"锚点"声音作为参考,并对评分进行了一些规范化处理。除了对音频质量和匹配度的评分外,还进行了对音频多样性的评估。为了确保评分的公正性和准确性,组织者采取了多种措施,如试点研究、盲评和权重调整。
5 Results
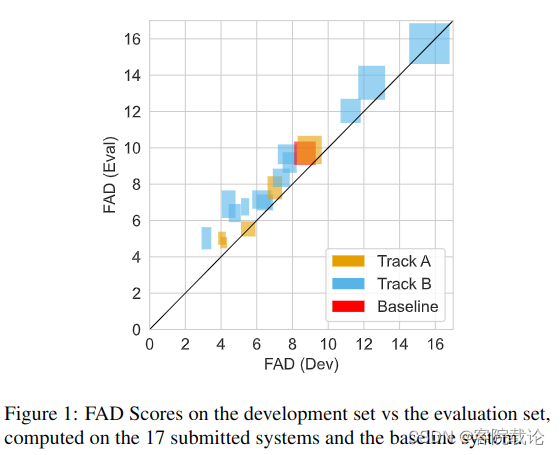
- 总共收到能跑的,没问题的有36个系统,9个A类,27个B类别,然后总共是17个队伍,这里绘制17个系统的FAD评分,横坐标是训练集的FAD平均值,纵坐标是测试集的FAD平均值,矩形的方差表示对应两个数据集上的七个类别的平均方差。
-
看图说话,有如下结论
- 大部分的系统,在训练集上的效果要好于在测试集的效果
- FAD-Dev和FAD-Eval的关系并不大,并不能通过训练集的指标很好的知道测试集的效果
- 将A和B的两个前几的系统进行比较,可以看到B赛道的系统在FAD-Dev上表现的更好,但是在FAD-Eval上效果很差。说明B赛道更难。
-
看第二部分图,是FAD和最终排名作为横纵坐标的散点图,具体如下
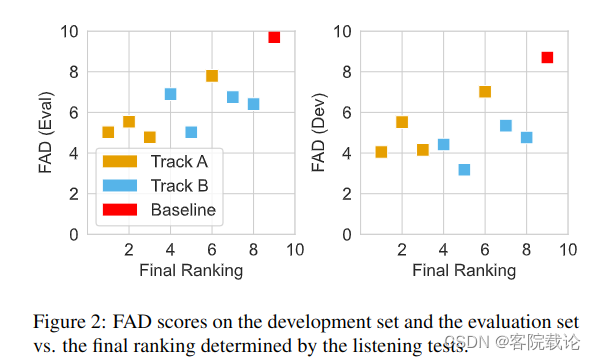
- 看上图,这里计算了FAD-Dev、FAD-Eval分别和最终排名的Spearnman相关系数,来显示二者之间的关系。训练集上的关联程度很低,只有0.238弱相关。测试集上的关联系数很大,有0.524,强相关。
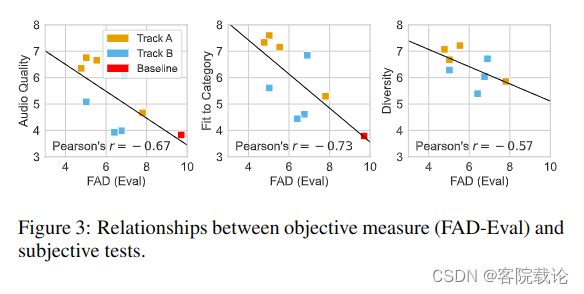
- 客观测量FAD-Eval和主观测试的三个指标的关联程度
- 这个方法虽然有些地方不咋地,但是还能用,总体来说是合理的,不就结,现在先把实验做出来
6 Conclusion
- 在这篇文章中,我们提出的FoleySound合成系统挑战,旨在于促进更多的研究者能够投身到声音的生成式AI的开发中。我们已经给这个挑战提供了一些细节介绍。已经达成了目的,收了很多论文,都做了评估。
- 评估不能仅仅依靠主观评估,还需要客观评估,评估需要很多时间。
- 未来,希望这个挑战提供的标准化评估框架有助于促进不同的FoleySound声音合成系统的比较。目前已经很明显,不久的将来,可以使用文本的输入、视频的输入等进行复杂的FoleySound声音合成。
总结
-
这篇文章看了两天,中间有一个半天被抽调去工厂了。下面对这个论文来进行一个总结,主要是说一下我认为的重点。
-
Baseline Model
- 这个主要由三个部分构成,方便参赛者分模块进行修改,而不需要改动其他的模块,能够降低参赛的门槛。
-
主客观评估体系
- 这是文章的重点,目前对于声音生成的评价体系过于单调,仅仅依靠客观指标并不能有效反应生成模型的效果,所以需要结合主观指标和客观指标。
- 目前对我来说 ,不是重点,因为我还要去实现,只需要在客观指标上有所创新就行了。
-
Foley Sound Synthesis System
- 这个比赛是第一次举办,目前关于这部分的研究比较少。
- 这个系统目的是自动化背景音合成,或者辅助背景音合成
- 这个比赛的内容是简化版,仅仅是要求生成特定类别的声音,以后可能包括文字生成声音,视频生成声音等更加高级的应用。