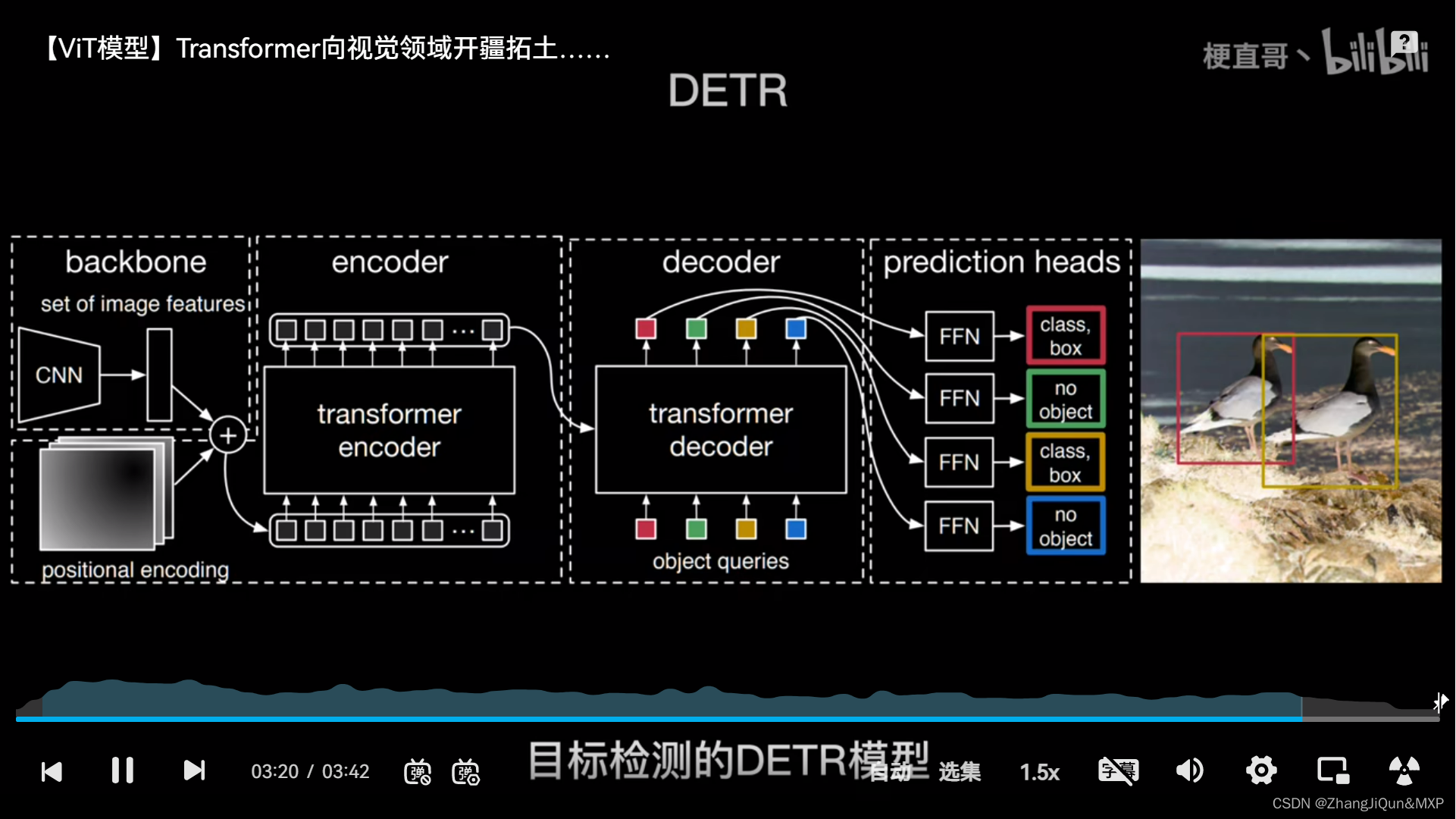
练习1-CRUD
// 进入test数据库
use test;
// 查询文档内容
db.students.find();
// 显示当前数据库中所有集合
show collections;
// 向数据库的user集合中插入一个文档
db.users.insertOne(
{username: "lyh"}
);
// 查看当前数据库中所有的集合 发现users集合被创建
show collections;
// 查看users集合中所有文档
db.users.find();
// 向users集合中插入一个文档
db.users.insertOne(
{username: "sxau"}
);
// 查看users集合中所有文档
db.users.find();
// 统计users集合中文档的数量
db.users.find().count();
// 查询集合users中username为lyh的文档
db.users.find({username: "lyh"});
// 向users集合中username为lyh的文档添加一个address属性,属性值为shanxi
db.users.updateOne(
{username: "lyh"},
{$set:
{address: "shanxi"}
}
);
// 使用 {username:"lj"} 替换 username 为 sxau 的文档
db.users.replaceOne(
{username: "sxau"},
{username: "lj"}
);
// 删除username为lyh的address属性
db.users.updateOne(
{username: "lyh"},
{
$unset: {address: 404}
}
);
// 向username为lyh的文档中添加一个hobby属性:{cities["chengdu","xian"],sport:["basketball","football"]}
// mongdb文档(document)的属性值也可以是一个文档,当一个文档的属性值是一个文档的时候,我们称这个文档叫做内嵌文档
// 比如下面我们的这个文档中又存放了一个名为hobby的文档,它有两个属性:cities和sport
db.users.updateOne(
{username: "lyh"},
{
$set: {
hobby:{
cities:["chengdu","xian"],
sports:["basketball","football"]
}
}
}
);
// 向username为lj的文档中添加一个hobby属性:{sport:["basketball","sing"]}
db.users.updateOne(
{username: "lj"},
{
$set: {
hobby: {
sport:["basketball","sing"]
}
}
}
);
// 查询 喜欢basketball 运动的文档
// MongDB 支持对内嵌文档进行查询 查询的时候属性名必须加引号 单引号和双引号都行
db.users.find(
{"hobby.sport":"basketball"}
);
// 向lj的sport的中添加一个"pingpang"
// 这里用 $push 而不是 $set push是向数组中添加一个新的元素
// push 可以给数组添加重复的元素 但是下面的set不会
db.users.updateOne(
{username: "lj"},
{
$push:{
"hobby.sport": "pingpang"
}
}
);
db.users.find();
// 除了 $push 还可以用 $addToSet 表示添加到集合 和push的区别就是
// addToSet 会把我们的数组当做一个set集合来看待 它不可以添加重复的元素
db.users.updateOne(
{username: "lj"},
{
$addToSet:{
"hobby.sport": "pingpang"
}
}
);
// 删除喜欢 sing 的用户
db.users.deleteOne(
{"hobby.sport": "sing"}
);
练习2-条件查询
- 这里会学习到一个数据类型:数组,这里的语法和JavaScript十分相似。数组使用push来添加数据。
- 这里还会学到比较运算符:小于:lt ,等于:eq,大于: gt,小于等于: lte,大于等于: gte。和我们shell编程的比较运算符很像。
// 向 numbers 插入20000条数据 耗时十几秒
for(var i=1;i<=20000;i++){
db.numbers.insertOne(
{num:i}
);
};
db.numbers.find();
// 删除只需要0.2s
db.numbers.drop();
// 使用数组存储2w条数据 只调用一次insert方法
var arr = [];
for(var i=1;i<=20000;i++){
arr.push({num: i});
};
// 这次只用了 1s
db.numbers.insertMany(arr); //插入数组需要使用insertMany而不是insertOne 后者会插入2w个列族
db.numbers.find();
// 查询numbers中num为500的文档
db.numbers.find(
{num: 500}
);
// 查询numbers中num大于18888的文档
db.numbers.find(
{
num: {$gt: 18888}
}
);
// 查询numbers中num小于等于30的文档
db.numbers.find(
{num:{$lte: 30}}
);
// 查询numbers集合中num等于77的文档
db.numbers.find(
{num:{$eq: 77}}
);
// 查询numbers中num大于50小于70的文档
db.numbers.find(
{num:{$gt:50,$lt: 70}}
);
// 查询numbers中的前10条文档
db.numbers.find().limit(10);
// 实际开发过程中我们不可能使用没有查询条件的查询 加载时间长 我们都是分页加载的 而且即使不考虑服务器的性能 还有网速的影响 而且用户也看不完那么多数据 用户的内存也存不了
db.numbers.find();
// 查询numbers中的第10条到第20条文档
// skip() 用于跳过指定数量的数据
db.numbers.find().skip(10).limit(10);
// 查询numbers中的第21条到第30条文档
db.numbers.find().skip(20).limit(10);
// mongdb 会自动调整我们 limit和skip方法的顺序 下面的语句执行时其实还是 db.numbers.find().skip(20).limit(10);
db.numbers.find().limit(10).skip(20);
文档之间的关系
文档之间有三种:
- 一对一
- 夫妻
- 一对多/多对一
- 文章和评论
- 多对多
- 老师和学生
这些都可以通过内嵌文档来映射。
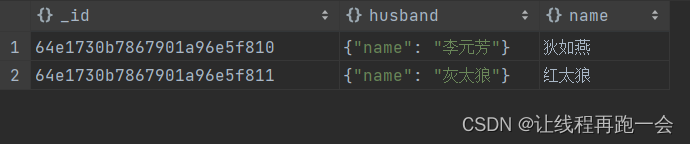
一对一
// 李元芳是狄如燕的丈夫 注意:插入多个文档或者一个数组时需要使用insertMany
db.wifeAndHusband.insertMany(
[
{name: "狄如燕",
husband:{
name: "李元芳"}
},{
name: "红太狼",
husband:{
name: "灰太狼"
}
}
]
);
一对多
//一对多 一篇文章对多个评论
db.article.insertOne(
{
name: "《沉默的大多数》",
comments: [
"很好看",
"给王小波点赞",
"神作"
]
}
);
db.article.find();
// 增加字段 'author' 并赋值为 '王小波' 给所有含有 'name' 属性的文档
db.article.updateMany(
{name: {$exists: true}},
{
$set: {
author: "王小波"
}
}
);
db.article.insertOne(
{
name: "《祈念守护人》",
author: "东野圭吾",
'comments': [
"很治愈",
"好看",
"力推"
]
}
);

如果非要严格的说相同的评论内容可以对应多个作者的话,也可以算是多对多。
多对多
// 多对多
db.teachers.insertMany([
{name: "狄仁杰"},
{name: "曾泰"},
{name: "李元芳"}
]);
db.students.insertMany(
{name: "狄春",age: 22,isDel: 0,gender: "男"},{name: "狄如燕",age: 20,isDel: 0,gender: "女"}
);
//添加字段 teacher_ids 与teachers 产生关联
db.students.updateOne(
{name: "狄春"},
{$set:{
teacher_ids:[
ObjectId("64e17b707867901a96e5f81e"),
ObjectId("64e17b707867901a96e5f820")
]
}
}
);

练习3-条件查询
- 这里我们会学到一个新的关键字:$inc 是自增的意思,需要指定增加的值。
数据源:dept(部门表),emp(员工表)
b.dept.insertMany([
{deptno: 1001,dname: "财务部",loc: "北京"},
{deptno: 1002,dname: "办公室",loc: "上海"},
{deptno: 1003,dname: "销售部",loc: "成都"},
{deptno: 1004,dname: "运营部",loc: "西安"}
]);
db.emp.insertMany([
{empno: 7001,ename: "光头强",job: "伐木工",depno: 1004,sal: 800},
{empno: 7001,ename: "熊大",job: "护林员",depno: 1004,sal: 100},
{empno: 7001,ename: "熊二",job: "护林员",depno: 1004,sal: 500},
{empno: 7001,ename: "吉吉",job: "老板",depno: 1001,sal: 7000},
{empno: 7001,ename: "毛毛",job: "会计",depno: 1002,sal: 2000},
{empno: 7001,ename: "二狗",job: "保安",depno: 1003,sal: 1000},
{empno: 7001,ename: "大马猴",job: "保安",depno: 1003,sal: 1000}
]);
- 工资小于1100
db.emp.find(
{sal: {$lt: 1100}}
);
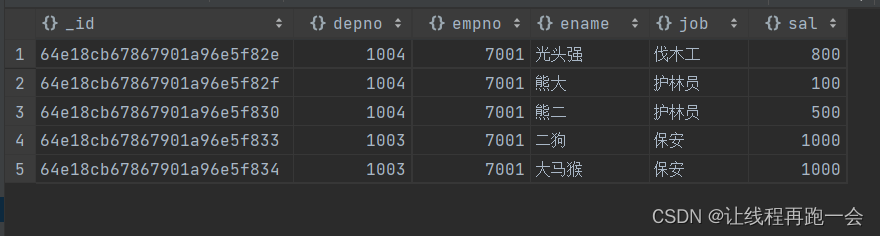
- 工资在500-1000
db.emp.find(
{sal: {$gt: 500,$lt: 1000}}
);

- 工资小于1000或者大于2000
db.emp.find(
{
$or:[
{sal: {$lt: 1000}},
{sal: {$gt: 2000}}
]
}
);

- 查询运营部所有员工
// 查询运营部所有员工
var depno = db.dept.findOne(
{dname: "运营部"}
).deptno;
db.emp.find(
{depno: depno}
);

- 给所有工资低于1000的员工增加500元工资
// 给所有工资低于1000的员工增加500元工资
db.emp.updateMany(
{sal: {$lte: 1000}},
{
$inc:{
sal: 500
}
}
);
这里使用了一个新的关键字:inc 代表 increase:自增的意思,如果我们要做减法的话,可以令增加的值为负数。
sort和投影
- sort 是默认按照 _id 进行排序的,可以根据设置指定的字段来排序,需要以对象的格式来设置参数(中括号{字段名: 1},1代表升序,-1代表降序)。
- 投影的是设置查询结果中显示的字段,需要设置find()中的参数,同样是对象的格式(中括号{自字段名:1},1代表显示,0代表不显示),其中,_id 默认是显示的。
//默认按照 _id 来进行排序
db.emp.find();
// 按照工资来升序排序 sort()需要一个对象来指定排序规则 1: 升序 -1: 降序
db.emp.find().sort({sal:1});
// 先按照工资来排序,如果工资相同则按照empno排序
// limit skip 和 sort 都可以以任意顺序调用
db.emp.find().sort({sal:1,empno:-1});
// 指定查询结果字段 也就是find的第二个参数 是一个对象 1代表显示 0代表不显示 _id默认显示
db.emp.find({},{ename: 1,_id: 0});