文章目录
- 一、models字段类型
- 概述
- 属性命名限制
- 使用方式
- 逻辑删除和物理删除
- 常用字段类型
- 二、常用字段参数
- 常用字段选项(通过字段选项,可以实现对字段的约束)
- 实践
- 创建模型
- 执行迁移命令 并 创建超级用户登录admin后台
- 添加文件和图片字段
- 定义模型字段和约束及在Admin后台管理系统的表单情况
- 三、models基本操作
- 3.1 增
- 实践
- 方式一
- 方式二
- 方式三
- 方式四(不会报错)
- 测试
- 添加多条数据
- 3.2 删
- 删除多条数据
- 3.3 修改数据
- 修改多条数据
- 3.4 查
- get() 获取单条数据
- all() 获取所有数据
- first() 返回第一条数据
- last() 返回最后一条数据
- filter() 过滤
- count(): 返当前查询集中的对象个数
- exists():判断查询集中是否有数据
- values(): 获取指定列的值
- values_list():获取指定列的值
- exclude() 排除,取反
- 聚合
- 排序
- 分页功能
- 手动分页
- Django中的自动分页器
- 四、Django模型进阶
- 4.1 配置MySQL
- 实践
- 报错1:django.db.utils.NotSupportedError: MySQL 8 or later is required (found 5.7.26).
- 报错2:RuntimeWarning: Got an error checking a consistent migration history performed for database connection 'default': (1045, "Access denied for user 'root'@'localhost' (using password: YES)")
- 4.2 多模块关联关系
- 4.3 Model连表结构
- 4.3.1 一对多关联
- 实践
- 增加数据
- 删除数据
- 修改数据
- 查询数据
- 前三种查询
- 第四种查询
- 4.3.2 多对多关联
- 实践
- 添加数据
- 写法一
- 写法二
- 修改数据
- 删除数据
- 删除电影
- 删除用户
- 查询
- 4.3.3 一对一
- 实践
- 增删改
- 查询
一、models字段类型
概述
django根据属性的类型确定以下信息
- 当前选择的数据库支持字段的类型
- 渲染管理表单时使用的默认html控件
- 在管理站点最低限度的验证
django会为表增加自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后,则django不会再生成默认的主键列。
属性命名限制
- 遵循标识符规则
- 由于django的查询方式,不允许使用连续的下划线,写一个下划线是可以的,写两个下划线_不可以
定义属性时,需要字段类型,字段类型被定义在django.db.models.fields目录下,为了方便使用被导入到django.db.models中
使用方式
- 导入from django.db import models
- 通过models.Field 创建字段类型的对象,赋值给属性
逻辑删除和物理删除
对于重要数据都做逻辑删除,不做物理删除,实现方法是定义is_delete属性,类型为BooleanField,默认值为False
is_delete = models.BooleanField(default=False)
常用字段类型
-
AutoField
- 一个根据实际ID自动增长的IntegerField,通常不指定,如果不指定,主键字段id将自动添加到模型中
-
CharField(max_length=字符长度)
- 字符串,默认的表单样式是 Input
-
DecimalField(max_digits=None, decimal_places=None)
- 使用python的Decimal实例表示的十进制浮点数
- 参数说明
- DecimalField.max_digits
- 位数总数
- DecimalField.decimal_places
- 小数点后的数字位数
- DecimalField.max_digits
-
FloatField
- 用Python的float实例来表示的浮点数
-
BooleanField
- True/False 字段,此字段的默认表单控制是CheckboxInput
-
DateField( [auto_now=False, auto_now_add=False] )
- 使用Python的datetime.date实例表示的日期
- 参数说明
- DateField.auto_now
- 每次保存对象时,自动设置该字段为当前时间,用于
"最后一次修改”的时间戳,它总是使用当前日期, 默认为false
- 每次保存对象时,自动设置该字段为当前时间,用于
- DateField.auto_now_add
- 当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用创建时的日期默认为false
注意: auto_now_add,auto_now,and default 这些设置是相互排斥的 , 他们之间的任何组合将会发生错误的结果
- 当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用创建时的日期默认为false
- DateField.auto_now
-
TimeField
- 使用Python的datetime.time实例表示的时间,参数同DateField
-
DateTimeField
- 使用Python的datetime.datetime实例表示的日期和时间,参数同DateField
-
FileField
- 一个上传文件的字段
-
ImageField
- 继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image需要安装Pillow:
"pip install Pillow"
- 继承了FileField的所有属性和方法,但对上传的对象进行校验,确保它是个有效的image需要安装Pillow:
二、常用字段参数
常用字段选项(通过字段选项,可以实现对字段的约束)
- null=True
数据库中字段是否可以为空 - blank=True
django的Admin 中添加数据时是否可允许空值
一般null=True & blank=True 搭配着用,出现null=True就用上blank=True
- primary_key = True
主键,对AutoField设置主键后,就会代替原来的自增 id 列 - auto_now和 auto_now_add
auto_now 自动创建 - - - 无论添加或修改,都是当前操作的时间
auto_now_add 自动创建 - - - 永远是创建时的时间 - choices (后台admin下拉菜单)
USER_TYPE_LIST = (
(1, “超级用户”),
(2, ‘普通用户’),
)
user_type = models.IntegerField( choices=USER_TYPE_LIST, default=1, verbose_name=‘用户类型’) - max_length 最大长度
- default 默认值
- verbose_name Admin(后台显示的名称)中字段的显示名称
- name | db_column 数据库中的字段名称,在我做迁移的时候默认情况表当中的字段名称和写的属性名是一样的,如果想不一样就用name 或者 db_column 来指定
- unique=True 不允许重复
- db_index = True 数据库索引, 例如: 如果你想通过name查询的更快的话,给他设置为索引即可
- editable=True 在Admin里是否可编辑,不可编辑则不显示
- 设置表名
class Meta:
db_table = ‘person’
实践
新建一个项目Day03DjangoPro01
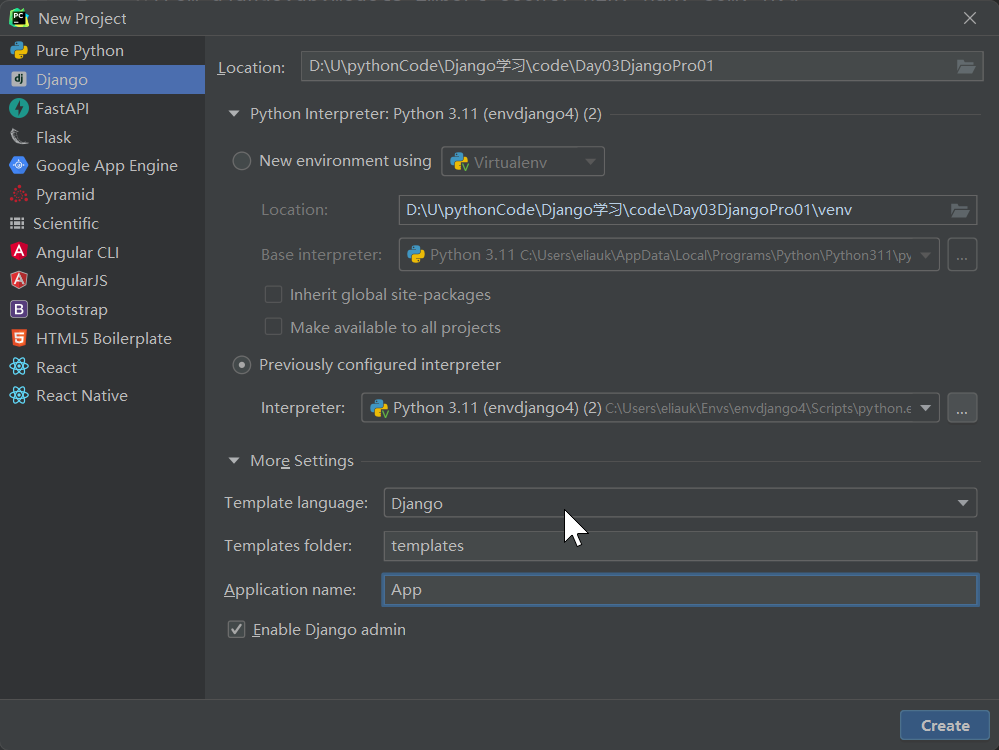
创建模型
App\models.py
from django.db import models
class UserModel(models.Model):
# uid 它会成为主键,原来的id不会创建
uid = models.AutoField(auto_created=True, primary_key=True)
# CharField: 字符串类型 最大长度 unique唯一 db_index索引
name = models.CharField(max_length=30, unique=True, db_index=True)
# IntegerField: 整数类型, default默认值
age = models.IntegerField(default=18)
# BooleanField 类型
sex = models.BooleanField(default=True) # True男
# TextField 大文本 null=True 可以为空 blank=True 在Admin管理页面可以为空
info = models.TextField(null=True, blank=True)
# FloatField 小数
salary = models.FloatField(default=100000.456)
# DecimalField 十进制小数 max_digits=9 总长度9 ,decimal_places=2 小数点后保留2位
money = models.DecimalField(max_digits=9, decimal_places=2, default=0)
# 日期
birthday = models.DateField(default='2000-3-4')
birthday2 = models.DateTimeField(auto_now=True) # auto_now=True 每一次修改后都会自动修改该时间为最新的修改时间
birthday3 = models.DateTimeField(auto_now_add=True) # auto_now_add=True 第一次添加数据的时候的时间,以后不会修改
数据迁移
迁移的概念: 就是将模型映射到数据库的过程
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
如果遇到 Please select a fix:
1) Provide a one-off default now (will be set on all existing rows with a null value for this column)
2) Quit and manually define a default value in models.py.
Select an option:
1)现在提供一次性默认值(将在所有现有行上设置此列的空值)
2)退出并在models.py中手动定义一个默认值。
这里是告诉你: 因为新添加了字段,原有数据因为没有这个新字段,那么1就是设置一次性默认值填入到之前的数据中;2 models.py中手动定义一个默认值default=。
Select an option: 输入1或者2 回车
创建超级用户
python manage.py createsuperuser
用户名 admin
密码 123456
弹出信息,你的密码太简单了太短了,至少八个字符,看你是否要使用,Y就是的使用
执行迁移命令 并 创建超级用户登录admin后台
App\admin.py
from django.contrib import admin
from App.models import *
# 后台管理系统的使用:
# 在这里注册对应的模型
admin.site.register(UserModel)
打开cmd
workon envdjango4
python manage.py makemigrations
python manage.py migrate
python manage.py createsuperuser
访问admin后台: http://127.0.0.1:8000/admin/
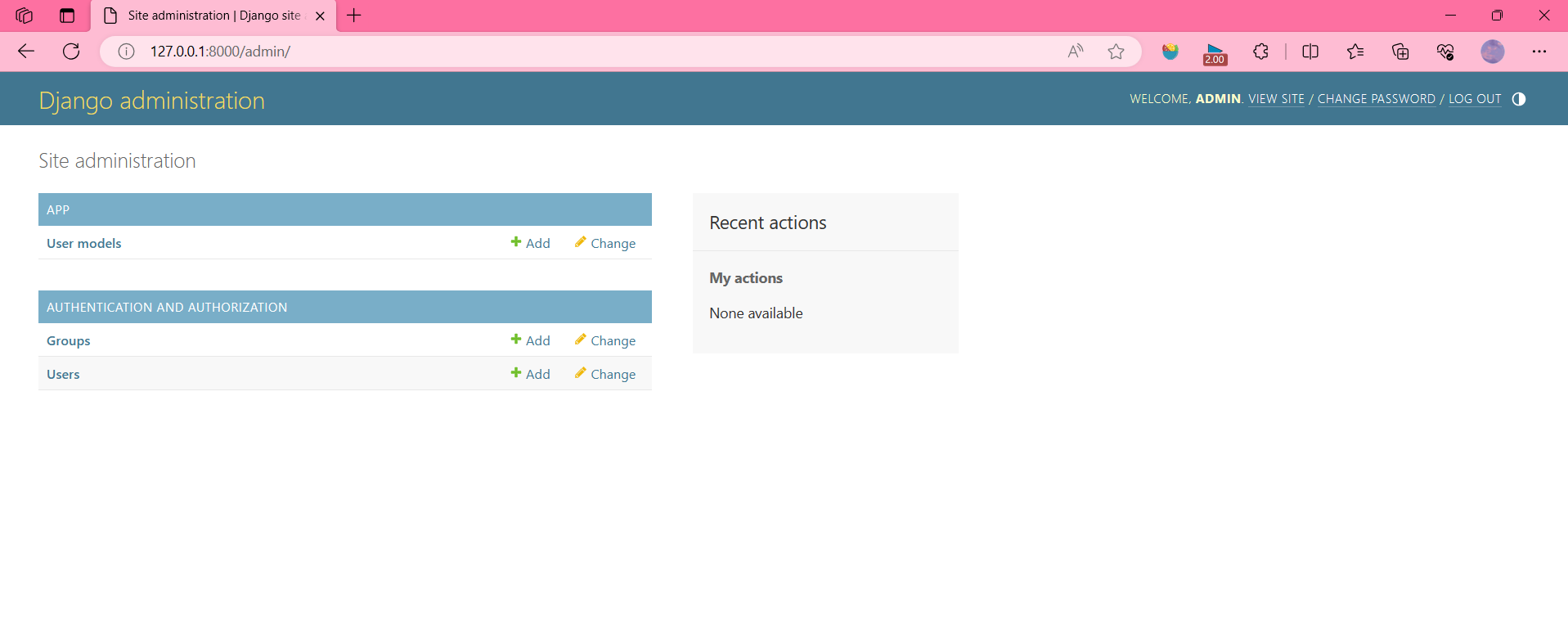
添加一条数据,在数据库观察 birthday2 和 birthday3

修改刚刚添加的数据

可以看到 birthday2 发生了变化,birthday3 没有改变。
auto_now=True 每一次修改后都会自动修改该时间为最新的修改时间
auto_now_add=True 第一次添加数据的时候的时间,以后不会修改
添加文件和图片字段
App\models.py
# 既可以上传文件又可以上传图片
icon = models.FileField(null=True, blank=True, upload_to='static/uploads')
# upload_to 上传的地方
再重新生成迁移文件、执行迁移
python manage.py makemigrations
python manage.py migrate
执行完之后进入admin后台管理页面,点击添加
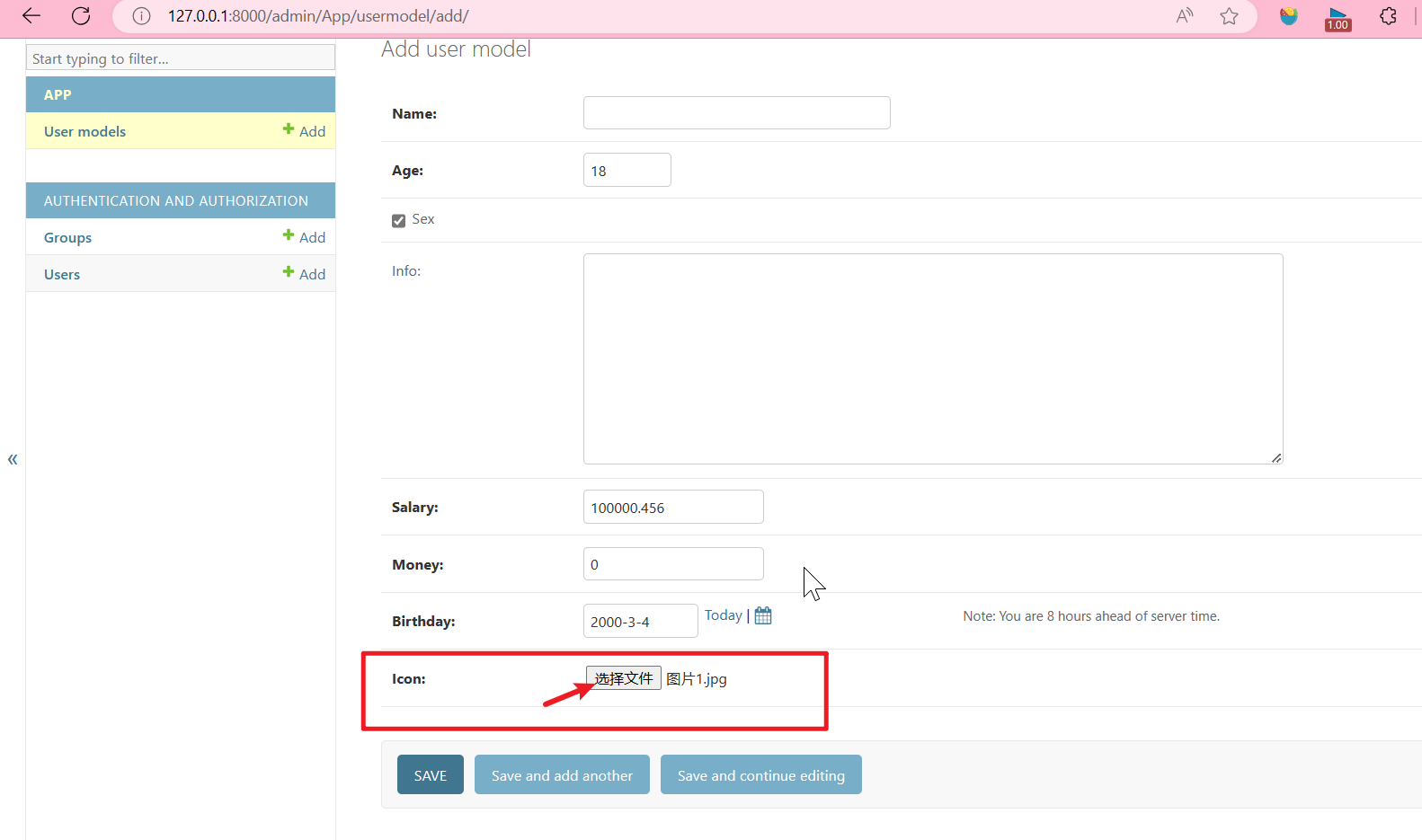

App\models.py
# 限制只能上传图片
icon2 = models.ImageField(null=True, blank=True, upload_to='static/uploads')

安装
# 1
python -m pip install Pillow
# 2
pip install Pillow
# 3 镜像
pip install pillow -i https://pypi.douban.com/simple
再重新生成迁移文件、执行迁移
python manage.py makemigrations
python manage.py migrate
执行完之后进入admin后台管理页面,点击添加
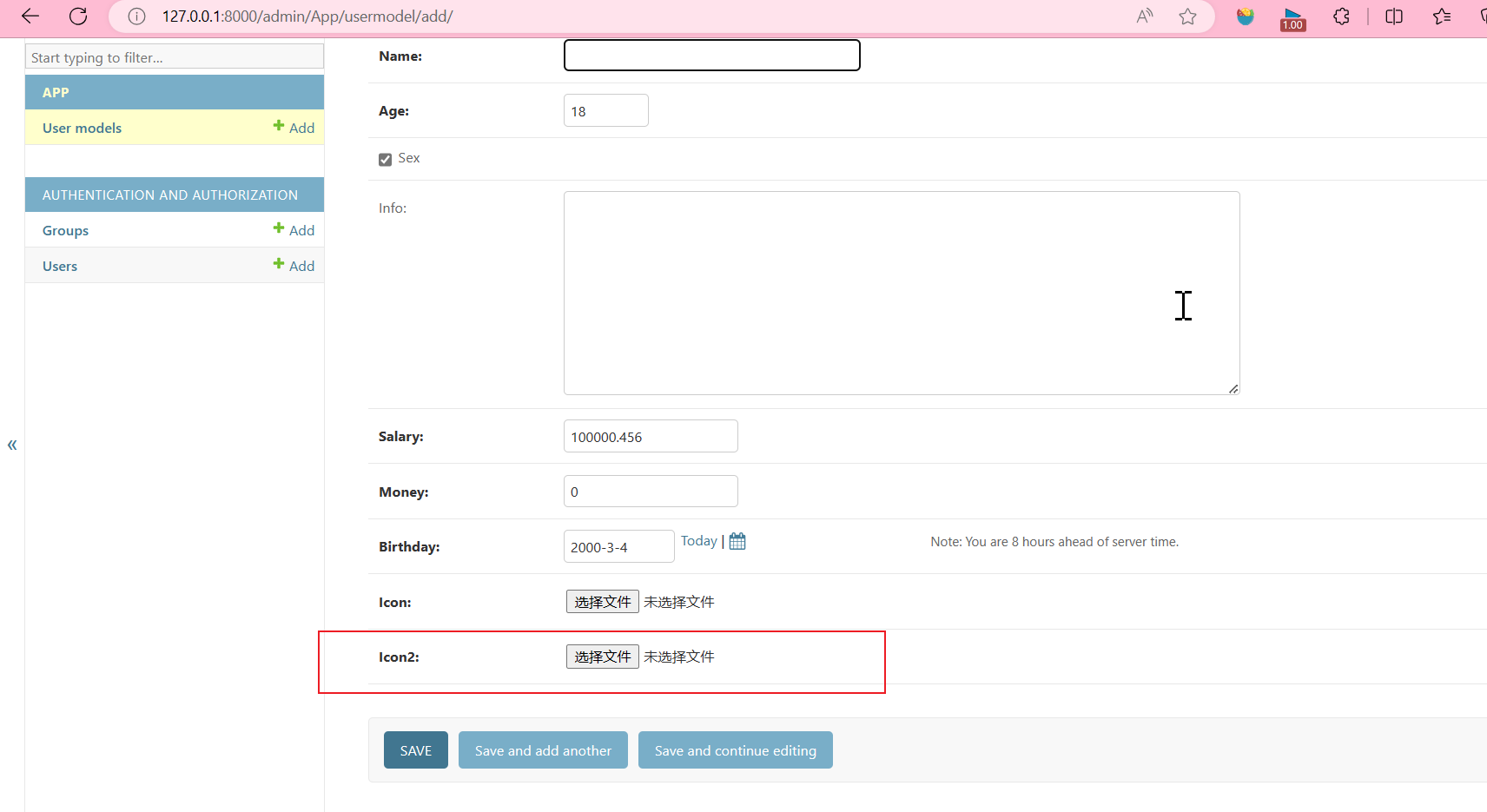
定义模型字段和约束及在Admin后台管理系统的表单情况
App\models.py
# 其他约束
choices = ((1, '青铜'), (2, '白银'), (3, '王者'))
# 保存到数据库当中的是前面的数字123,显示出来的是青铜白银王者,
#青铜白银王者在后台管理系统中会显示出来,实际上数据库存的是数字123
user_type = models.IntegerField(choices=choices, default=1,
name='utype', verbose_name='用户类型')
user_type2 = models.IntegerField(default=1, editable=False,
db_column='utype2', verbose_name='用户类型2')
再重新生成迁移文件、执行迁移
python manage.py makemigrations
python manage.py migrate
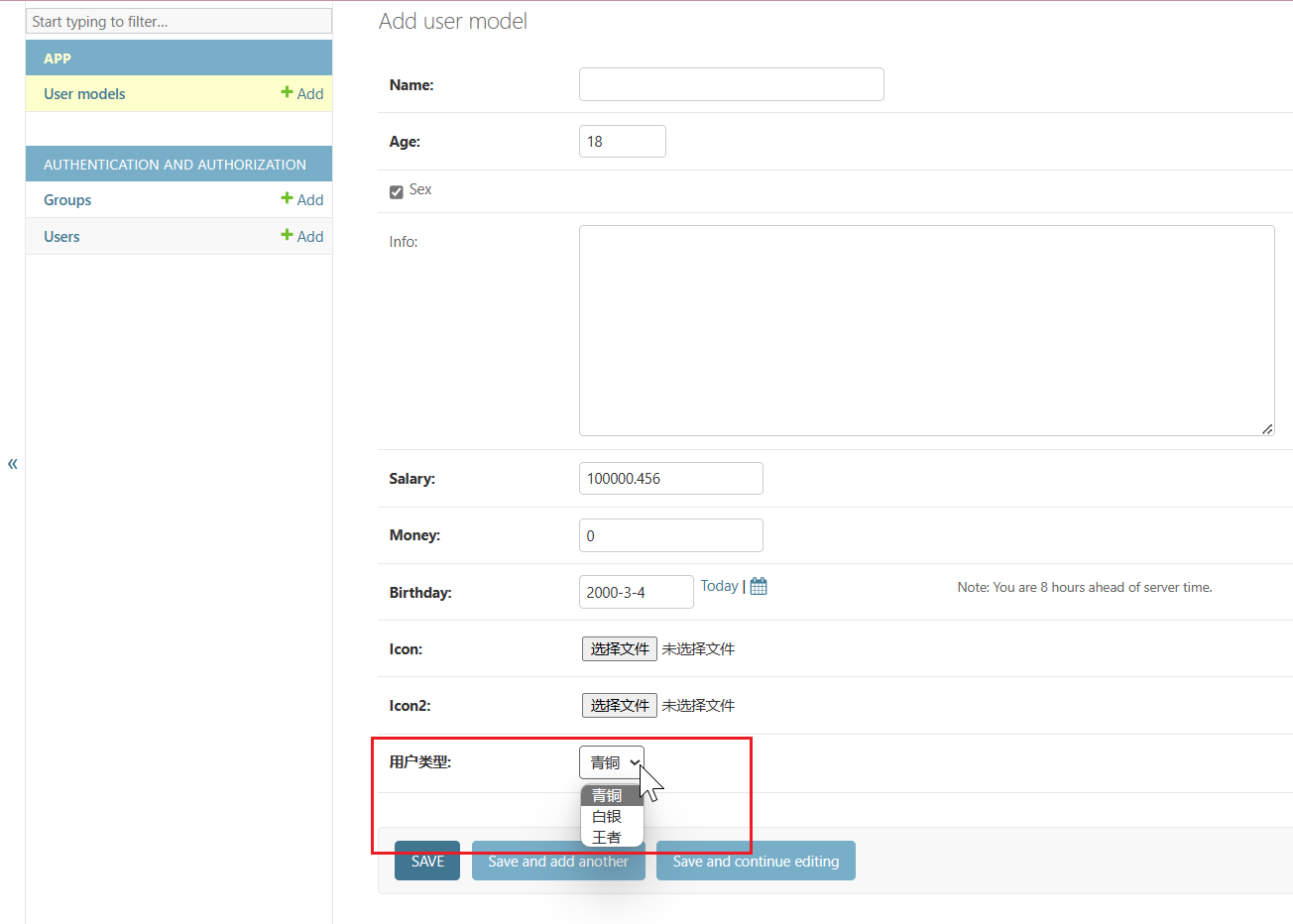
user_type在后台系统显示,user_type2不显示,是因为editable=False
三、models基本操作
一般的数据库操作流程:
- 创建数据库,设计表结构和字段
- 连接
Mysql数据库,并编写数据访问层代码 - 业务逻辑层去调用数据访问层执行数据库操作
Django通过Model操作数据库,不管你数据库的类型是MySql或者Sqlite,Django自动帮你生成相应数据库类型的SQL语句,所以不需要关注SQL语句和类型,对数据的操作Django帮我们自动完成。只要会写Model就可以了。
django使用对象关系映射 (Object Relational Mapping,简称ORM) 框架去操控数据库。
ORM(Object Relational Mapping) 对象关系映射,是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。
3.1 增
# ORM:
模型 <=> 表
类结构 -> 表结构
对象 -> 表的一条数据
类属性 -> 表的字段
# models基本操作
# 增:
1) 创建对象实例,然后调用save方法:
obj = Author()
obj.first_name = 'zhang'
obj.last_name = 'san'
obj.save()
2)创建对象并初始化,再调用save方法:
obj = Author(first_name='zhang',last_name='san')
obj.save()
3)使用create方法
Author.objects.create(first_name='li',last_name='si')
4)使用get_or_create方法,可以防止重复
Author.objects.get_or_create(first_name='zhang', last_name='san')
实践
我们单独再创建一个模型吧
App\models.py
from django.db import models
# 增删改查
class PersonModel(models.Model):
name = models.CharField(max_length=30, unique=True)
age = models.IntegerField(default=18)
# 表名
class Meta:
db_table = 'person'
注意:我们的name设置的是unique唯一的, 后面实践会用到
生成迁移文件、执行迁移
python manage.py makemigrations
python manage.py migrate
就不写子路由了,根路由Day03DjangoPro01\urls.py
from django.contrib import admin
from django.urls import path
from App.views import *
urlpatterns = [
path('add/', add_person), # 添加
path('admin/', admin.site.urls),
]
方式一
App\views.py
from django.shortcuts import render, HttpResponse
from App.models import *
# 增加数据
def add_person(request):
# 方式一
try:
p = PersonModel()
p.name = '清风'
p.age = 30
p.save() # 同步到数据库表中
except Exception as e:
return HttpResponse('add fail! 添加失败')
return HttpResponse('add success! 添加成功')
方式二
App\views.py
def add_person(request):
# 方式二
try:
p = PersonModel(name='微泫', age=26)
p.save() # 同步到数据库表中
except Exception as e:
return HttpResponse('add fail! 添加失败')
return HttpResponse('add success! 添加成功')
方式三
App\views.py
def add_person(request):
# 方式三
try:
PersonModel.objects.create(name='意境', age=26)
except Exception as e:
return HttpResponse('add fail! 添加失败')
return HttpResponse('add success! 添加成功')
方式四(不会报错)
App\views.py
def add_person(request):
# 方式四
ret = PersonModel.objects.get_or_create(name='甘雨', age=26)
print('ret: ', ret)
# (<PersonModel: PersonModel object (3)>, False) 失败
# (<PersonModel: PersonModel object (4)>, True) 成功
print('type: ', type(ret)) # <class 'tuple'>
print('Bool: ', ret[1]) # False 失败;True 成功
if ret[1]:
return HttpResponse('add success! 添加成功')
return HttpResponse('add fail! 添加失败')
测试
http://127.0.0.1:8000/add/
第一次:
第二次:因为name我们设置的是唯一的,所以添加失败
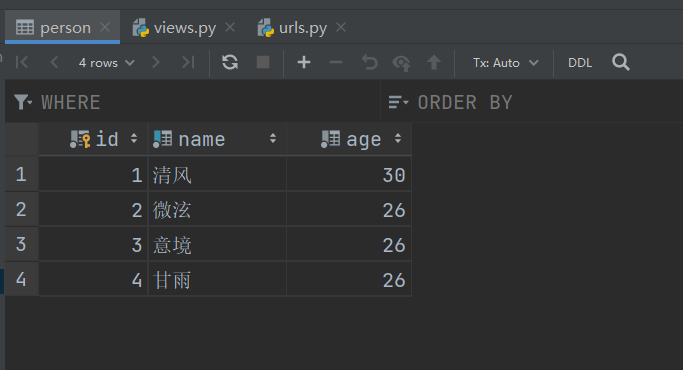
添加多条数据
App\views.py
def add_person(request):
# 添加多条数据
for i in range(1, 10):
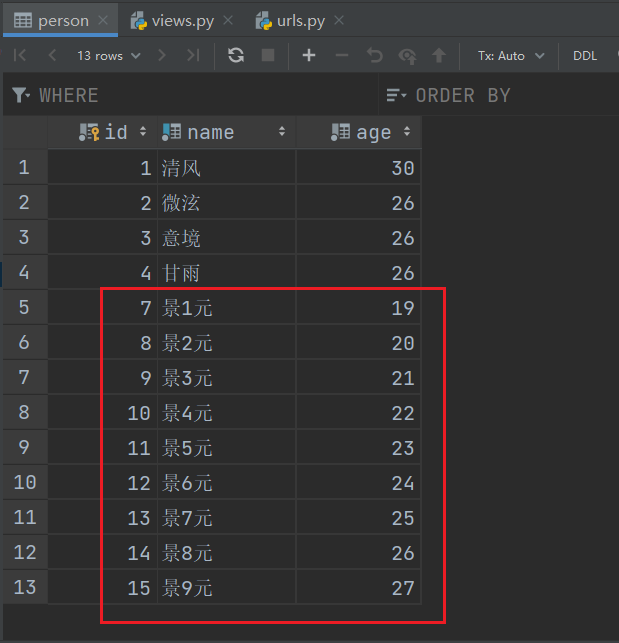
PersonModel.objects.get_or_create(name=f'景{i}元', age=18 + i)
return HttpResponse('add success! 添加成功')
http://127.0.0.1:8000/add/
3.2 删
使用Queryset的delete方法:
# 删除指定条件的数据
Author.objects.filter(first_name='zhang').delete()
# 删除所有数据
Author.objects.all().delete()
注意: objects不能直接调用delete方法。
使用模型对象的delete方法:
obj = Author.objects.get(id=5)
obj.delete()
根路由Day03DjangoPro01\urls.py
path('del/', del_person), # 删除
App\views.py
def del_person(request):
# 删除数据
# 1. 先找到要删除的数据
# 2. 然后删除
# 删除一条数据
try:
p = PersonModel.objects.first() # 第一条数据
p.delete()
except Exception as e:
return HttpResponse("删除失败!")
return HttpResponse("删除成功!")
http://127.0.0.1:8000/del/
删除多条数据
def del_person(request):
# 删除多条数据
try:
PersonModel.objects.filter(age__gt=23).delete() # 条件年龄 age > 23 岁的
except Exception as e:
return HttpResponse("删除失败!")
return HttpResponse("删除成功!")
3.3 修改数据
Author.objects,filter(last_name='dfdf').update(last_name='san')
模型没有定义update方法,直接给字段赋值,并调用save,能实现update的功能,比如:
obj = Author.objects.get(id=3)
obj.first_name ='zhang'
obj.save()
save更新时会更新所有字段。如果只想更新某个字段,减少数据库操作,可以这么做:
obj.first_name ='li'
obj.save(update_fields=['first_name'])
Day03DjangoPro01\urls.py
path('update/', updete_person)
App\views.py
def updete_person(request):
# 修改数据
# 1. 先找到要修改的数据
# 2. 然后修改
try:
# 修改一条数据
p = PersonModel.objects.get(id=7)
p.age = 110
# p.save() # 同步到数据库表中
p.save(update_fields=['age']) # 指定更新的字段,一定程度提高更新效率
except Exception as e:
return HttpResponse("修改失败!")
return HttpResponse("修改成功!")
http://127.0.0.1:8000/update
修改多条数据
def updete_person(request):
# 修改多条数据
try:
PersonModel.objects.all().update(age=66)
except Exception as e:
return HttpResponse("修改失败!")
return HttpResponse("修改成功!")
PersonModel.objects.all() 是一个查询集
3.4 查
get(): 获取单条数据
Author.objects.get(id=123)
如果没有找到符合条件的对象,会引发模型类.DoesNotExist异常
如果找到多个,会引发模型类.MultipleObjectsReturned 异常
first():返回查询集(QuerySet)中的第一个对象
last():返回查询集中的最后一个对象
count():返当前查询集中的对象个数
exists():判断查询集中是否有数据,如果有数据返回True没有反之
a11():获取全部数据:
Author.objects.al1()
values(): 获取指定列的值,可以传多个参数!返回包含字典的列表(保存了字段名和对应的值)
Author.objects.all().values('password')
values_list():获取指定列的值,可以传多个参数!返回包含元组列表 (只保存值)
Author.objects.al1().values_list('password')
进阶操作:
#获取个数
Author.objects.filter(name='seven').count()
Author.objects.filter(id__gt=1)# 获取id大于1的值
# select * from Author where id > 1
Author.objects.filter(id__gte=1)# 获取id大于或等于1的值
# select * from Author where id >= 1
Author.objects.filter(id__lt=10)# 获取id小于10的值
# select * from Author where id < 10
Author.objects.filter(id__lte=10)# 获取id小于或等于10的值
# select * from Author where id <= 10
Author.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
# select * from Author where id < 10 and id > 1
Author.objects.filter(id__in=[11, 22, 33] ) # 获id在11、22、33中的数据
# select * from Author where id in (11,22,33)
Author.objects.exclude(id__in=[11, 22, 33]) # not in
# select * from Author where id not in (11,22,33)
Author.objects,filter(name__contains="ven") # contains (和数据库中like语法相同)
# select * from Author where name like '%ven%'
Author.objects.filter(name__icontains="ven") # icontains大小写不敏感
Author.objects.filter(name__regex="^ven") # 正则匹配
Author.objects.filter(name__iregex="^ven") # 正则匹配,忽略大小写
Author.objects.filter(age__range=[10, 20])# 范围bettwen and 10-20
# xx__startswith , xx__istartswith , xx__endswith, xx__iendswith:
# 以什么开始,以什么结束,和上面一样带i的是大小写不敏感的,其实不带i的也忽略大小写
Author.objects.filter(name='seven').order_by('id')# asc升序
Author.objects.filter(name='seven').order_by('-id')# desc降序
Author.objects.a11()[10:20] # 切片,取所有数据的10条到20条,分页的时候用的到
#下标从0开始,不能为负数,可以实现分页
#手动分页
page 页码
per_page 每页数量 =5
第1页(page=1):0-4 =>[0:5]
第2页(page=2):5-9 =>[5:10]
第3页(page=3):10-14 =>[10:15]
第4页(page=4):15-19 =>[15:20]
...
每一页数据范围:
(page-1)*per_page: page*per_page
#聚合
使用aggregate()函数返回聚合函数的值
Avg:平均值
Count:数量
Max:最大
Min:最小
Sum:求和
from django.db.models import Count, Min, Max, Sum
Author.objects.aggregate(Max('age'))
注意双下划线__
Day03DjangoPro01\urls.py
path('get/', get_person), # 查询
get() 获取单条数据
如果没有找到符合条件的对象,会引发模型类.DoesNotExist异常
如果找到多个,会引发模型类.MultipleObjectsReturned 异常
App\views.py
# 查询数据
def get_person(request):
# get(): 得到一个对象(一条数据)
p = PersonModel.objects.get(id=8)
print('*' * 52)
print(p, type(p))
print(p.name, p.age)
print('*' * 52)
return HttpResponse('查询成功')
http://127.0.0.1:8000/get/

加入我调用get() ‘’id=‘’不写会怎么样?
# p = PersonModel.objects.get(8) # 会报错
pk:primary key
p = PersonModel.objects.get(pk=8) # pk:primary key
查询成功
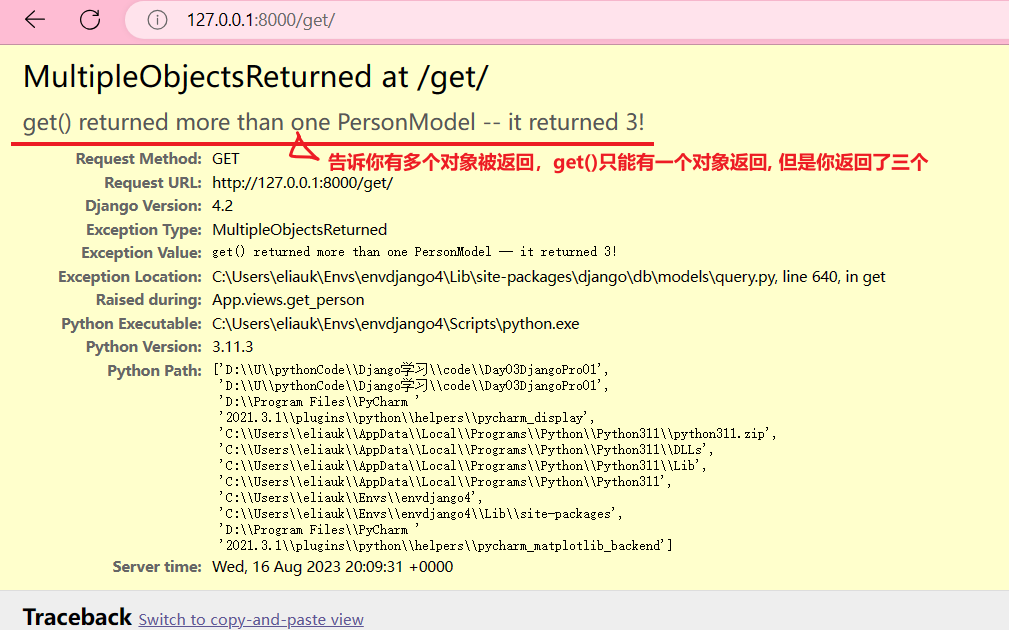
注意1:get()只能返回一个对象, 不然会报错 MultipleObjectsReturned
p = PersonModel.objects.get(age=19) # 数据库只有一个age=19,所以不会报错
p = PersonModel.objects.get(age=66) # 数据库有很多age=66,所以报错 MultipleObjectsReturned
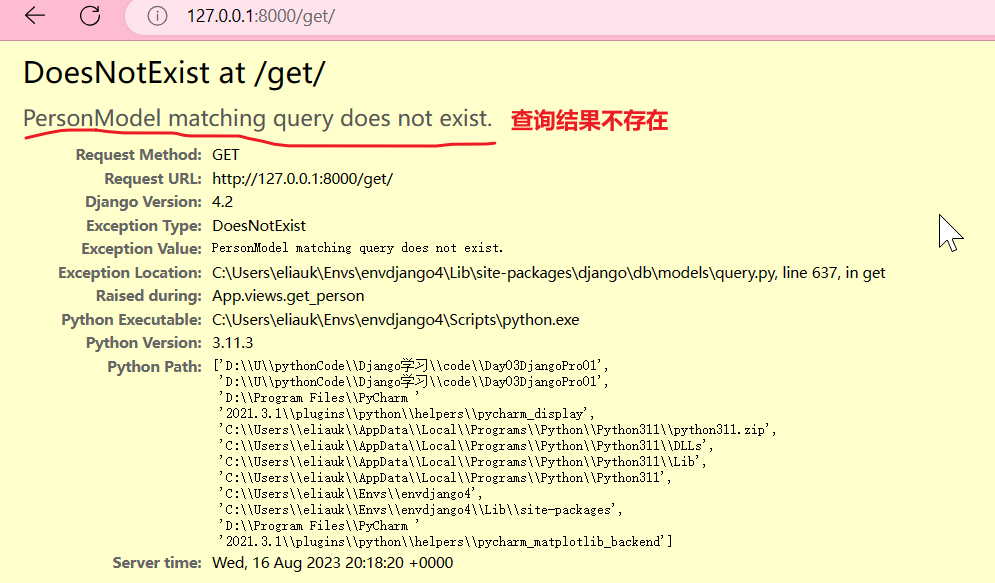
注意2:get() 查询结果不存在 DoesNotExist
p = PersonModel.objects.get(age=1000) # 数据库没有age=1000,所以报错 DoesNotExist
all() 获取所有数据
App\views.py
# 查询数据
def get_person(request):
# 获取所有数据
persons = PersonModel.objects.all()
print(persons, type(persons))
# QuerySet 查询集
# 可以遍历查询集
for p in persons:
print(p.name, p.age)
return HttpResponse('查询成功')
<QuerySet [<PersonModel: PersonModel object (7)>, <PersonModel: PersonModel object (8)>,
<PersonModel: PersonModel object (9)>, <PersonModel: PersonModel object (10)>,
<PersonModel: PersonModel object (11)>, <PersonModel: PersonModel object (16)>]>
<class 'django.db.models.query.QuerySet'>
景1元 110
景2元 110
景3元 66
景4元 66
景5元 66
甘雨 19
类型:QuerySet 查询集
first() 返回第一条数据
返回queryset中匹配到的第一个对象,如果没有匹配到对象则为None,如果queryset没有定义排序,则按主键自动排序。
all[0]:
与 first() 不同,如果没有匹配到,会报IndexError错误。
App\views.py
def get_person(request):
# 获取第一条数据
p = PersonModel.objects.first()
print(p.name, p.age)
return HttpResponse('查询成功')
last() 返回最后一条数据
App\views.py
def get_person(request):
# 获取最后一条数据
p = PersonModel.objects.last()
print(p.name, p.age)
return HttpResponse('查询成功')
filter() 过滤
使用最多。类似数据库中的where语句
App\views.py
def get_person(request):
persons = PersonModel.objects.filter() # 默认没有条件, 得到所有数据
persons = PersonModel.objects.filter(age__gt=100) # age>100
persons = PersonModel.objects.filter(age__gte=100) # age>=100
persons = PersonModel.objects.filter(age__lt=100) # age<100
persons = PersonModel.objects.filter(age__lte=100) # age<=100
persons = PersonModel.objects.filter(age=110) # age=110
print(persons.filter().filter())
for p in persons:
print('+++', p.name, p.age)
return HttpResponse('查询成功')
就算只拿到一个数据,它也是一个查询集 QuerySet 。
查询集 QuerySet 可以继续去查询 filter ,内部会返回self ,所以它可以做链式调用。

count(): 返当前查询集中的对象个数
exists():判断查询集中是否有数据
App\views.py
def get_person(request):
persons = PersonModel.objects.filter(age__gt=100) # age>100
for p in persons:
print('+++', p.name, p.age)
print(persons.exists()) # 查询集是否存在数据,如果存在则为True,否则为False
print(persons.count()) # 查询集中的数据个数
return HttpResponse('查询成功')
values(): 获取指定列的值
可以传多个参数!返回包含字典的列表(保存了字段名和对应的值)
App\models.py
class PersonModel(models.Model):
name = models.CharField(max_length=30, unique=True)
age = models.IntegerField(default=18)
# 表名
class Meta:
db_table = 'person'
def __str__(self):
return f'{self.name}-{self.age}'
def __repr__(self):
return f'{self.name}--{self.age}'
__str__方法大家应该都不陌生,它类似于Java当中的 toString 方法,可以根据我们的需要返回实例转化成字符串之后的结果。
__str__ 和 __repr__ 这两个函数都是将一个实例转成字符串。但是不同的是,两者的使用场景不同,其中__str__更加侧重展示。所以当我们print输出给用户或者使用str函数进行类型转化的时候,Python都会默认优先调用__str__函数。而__repr__更侧重于这个实例的报告,除了实例当中的内容之外,我们往往还会附上它的类相关的信息,因为这些内容是给开发者看的。所以当我们在交互式窗口输出的时候,它会优先调用__repr__。
App\views.py
def get_person(request):
persons = PersonModel.objects.filter() # 默认没有条件, 得到所有数据
print("persons: ", persons)
print("list(persons): ", list(persons)) # 将查询集强制转换成列表
# values() : 列表套字典,包括字段和值
print("persons.values(): ", persons.values()) # 列表套字典
print("persons.values('name'): ", persons.values('name'))
print("persons.values('name', 'age'): ", persons.values('name', 'age'))
# values_list() : 列表套元组,只有值
print("persons.values_list(): ", persons.values_list())
print("persons.values_list('name', 'age'): ", persons.values_list('name', 'age')) # 用法跟values一样
return HttpResponse('查询成功')
结果:
persons: <QuerySet [景1元--110, 景2元--120, 景3元--30, 景4元--66, 景5元--20, 甘雨--19]>
list(persons): [景1元--110, 景2元--120, 景3元--30, 景4元--66, 景5元--20, 甘雨--19]
persons.values(): <QuerySet [{'id': 7, 'name': '景1元', 'age': 110}, {'id': 8, 'name': '景2元', 'age': 120}, {'id': 9, 'name': '景3元', 'age': 30}, {'id': 10, 'name': '景4元', 'age': 66}, {'id': 11, 'name': '景5元', 'age': 20}, {'id': 16, 'name': '甘雨', 'age': 19}]>
persons.values('name'): <QuerySet [{'name': '景1元'}, {'name': '景2元'}, {'name': '景3元'}, {'name': '景4元'}, {'name': '景5元'}, {'name': '甘雨'}]>
persons.values('name', 'age'): <QuerySet [{'name': '景1元', 'age': 110}, {'name': '景2元', 'age': 120}, {'name': '景3元', 'age': 30}, {'name': '景4元', 'age': 66}, {'name': '景5元', 'age': 20}, {'name': '甘雨', 'age': 19}]>
persons.values_list(): <QuerySet [(7, '景1元', 110), (8, '景2元', 120), (9, '景3元', 30), (10, '景4元', 66), (11, '景5元', 20), (16, '甘雨', 19)]>
persons.values_list('name', 'age'): <QuerySet [('景1元', 110), ('景2元', 120), ('景3元', 30), ('景4元', 66), ('景5元', 20), ('甘雨', 19)]>
values_list():获取指定列的值
可以传多个参数!返回包含元组列表 (只保存值)
exclude() 排除,取反
App\views.py
def get_person(request):
person = PersonModel.objects.filter(age__in=[20, 50, 30]) # in
print("person: ", person)
person = PersonModel.objects.exclude(age__in=[20, 50, 30]) # not in
print("person: ", person)
return HttpResponse('查询成功')
聚合
使用aggregate()函数返回聚合函数的值
Avg:平均值
Count:数量
Max:最大
Min:最小
Sum:求和
from django.db.models import Count, Min, Max, Sum
PersonModel.objects.aggregate(Max(‘age’))
aggregate 是聚合的意思
App\views.py
from django.db.models import Count, Min, Max, Sum, Avg
def get_person(request):
# 聚合函数
result = PersonModel.objects.aggregate(Max('age')) # 最大值
print(result) # {'age__max': 120}
print(result['age__max']) # 120
return HttpResponse('查询成功')
def get_person(request):
# 聚合函数
result = PersonModel.objects.aggregate(Max('age')) # 最大值 {'age__max': 120}
result = PersonModel.objects.aggregate(Min('age')) # 最小值 {'age__min': 19}
result = PersonModel.objects.aggregate(Sum('age')) # 求和 {'age__sum': 365}
result = PersonModel.objects.aggregate(Avg('age')) # 求平均 {'age__avg': 60.833333333333336}
result = PersonModel.objects.aggregate(Count('age')) # 统计个数 {'age__count': 6}
print(result)
return HttpResponse('查询成功')
排序
PersonModel.objects.all().order_by()
App\models.py
class PersonModel(models.Model):
name = models.CharField(max_length=30, unique=True)
age = models.IntegerField(default=18)
# 表名
class Meta:
db_table = 'person'
def __str__(self):
return f'{self.id}-{self.name}-{self.age}'
def __repr__(self):
return f'{self.id}--{self.name}--{self.age}'
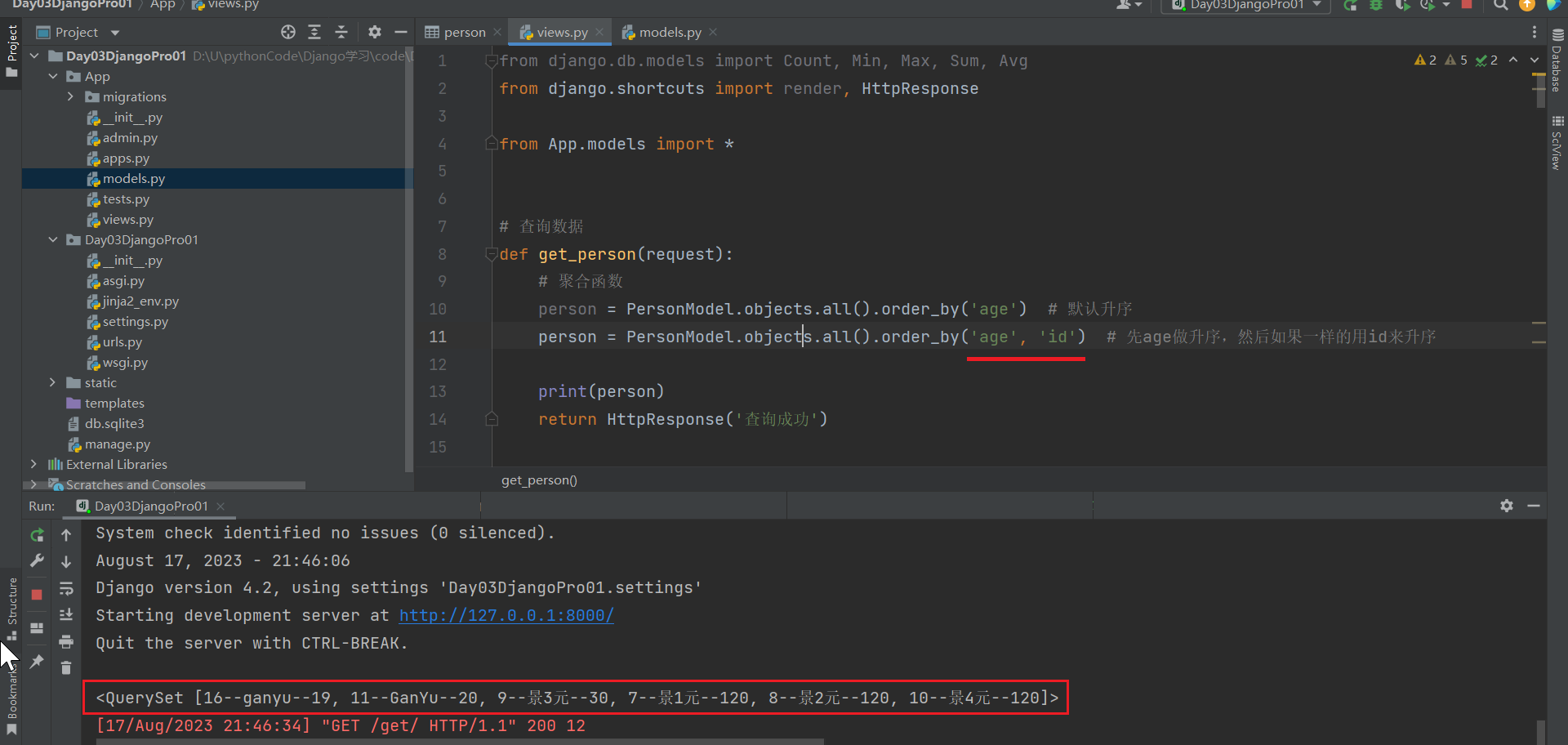
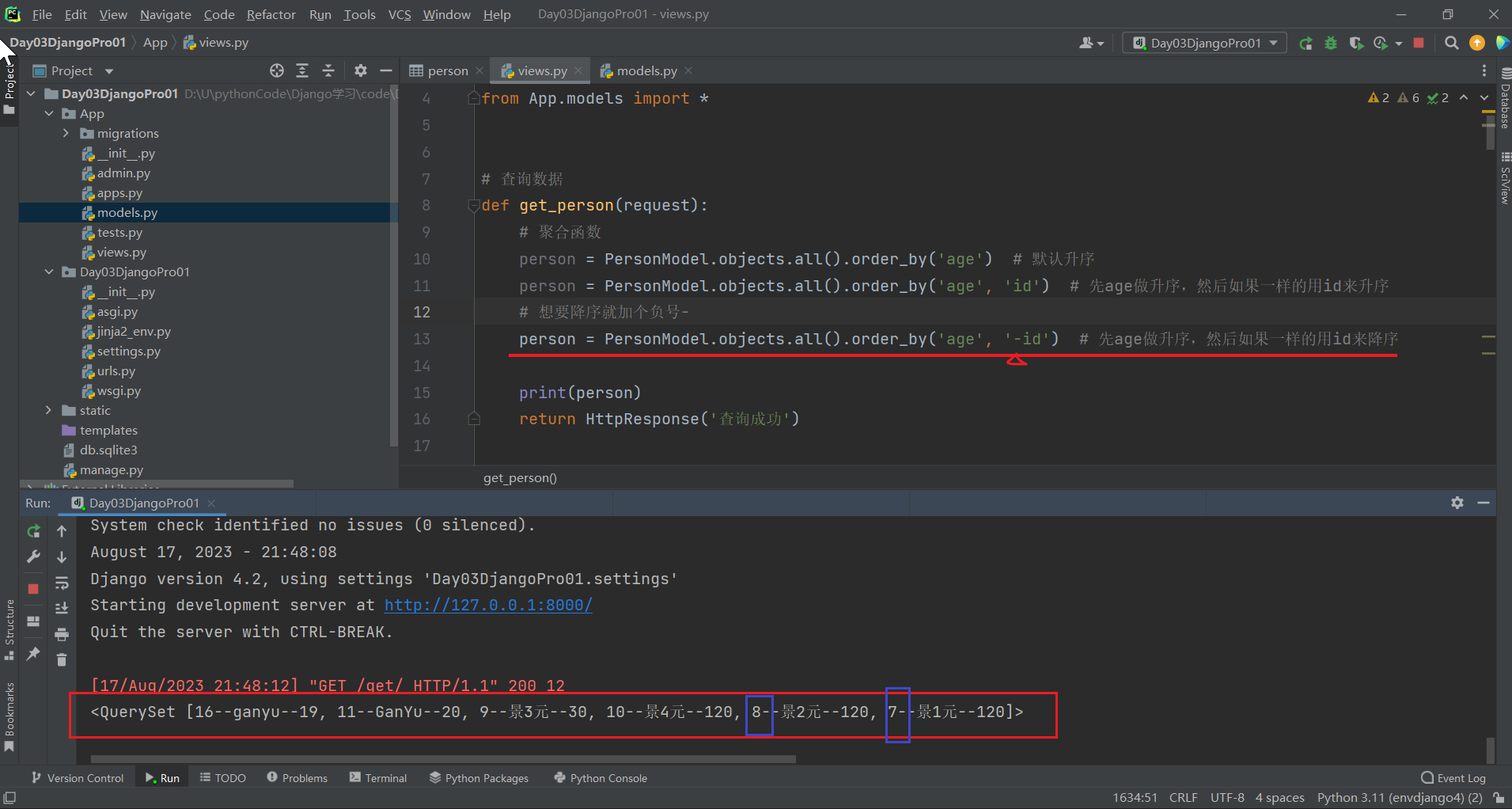
def get_person(request):
# 聚合函数
person = PersonModel.objects.all().order_by('age') # 默认升序
person = PersonModel.objects.all().order_by('age', 'id') # 先age做升序,然后如果一样的用id来升序
# 想要降序就加个负号-
person = PersonModel.objects.all().order_by('age', '-id') # 先age做升序,然后如果一样的用id来降序
print(person)
return HttpResponse('查询成功')
分页功能
手动分页
Day03DjangoPro01\urls.py
path('paginate/<int:page>/<int:per_page>/', paginate, name="paginate"), # 分页功能
App\views.py
import math
# 分页功能
def paginate(request, page=1, per_page=10):
# 页码:page=1
# 每页数据数量:per_page=10
'''
思路:分页功能
数据:[1,2,3,...,47]
第几页 数据范围 下标范围 切片
page=1, 1 ~ 10 0 ~ 9 [0:10]
page=2, 11 ~ 20 10 ~ 19 [10:20]
page=3, 21 ~ 30 20 ~ 29 [20:30]
...
page=n, [(n-1) * 10 : n * 10]
page=page, [(page-1)*per_page : page*per_page]
'''
# 实现分页功能
persons = PersonModel.objects.all()
persons = persons[(page - 1) * per_page:page * per_page]
# 求总页数
total = PersonModel.objects.count() # 总数据条数
total_page = math.ceil(total / per_page) # 总页数,可能是小数47/10,所以需要向上取整
pages = range(1, total_page + 1)
return render(request, "paginate.html", {
"persons": persons,
"pages": pages,
"per_page": per_page
})
templates\paginate.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页功能的实现</title>
<style>
ul{
list-style: none;
padding: 0;
}
.btns{
display: flex ;
align-content: center;
}
.btns li{
margin: 5px;
}
</style>
</head>
<body>
<h2>分页功能</h2>
<hr>
页数:{{ per_page }}
<ul class="btns">
{# <li>#}
{# <a href="{% url 'paginate' 1 10 %}"><button>1</button></a>#}
{# </li>#}
{# <li>#}
{# <a href="{% url 'paginate' 2 10 %}"><button>2</button></a>#}
{# </li>#}
{# <li>#}
{# <a href="{% url 'paginate' 3 10 %}"><button>3</button></a>#}
{# </li>#}
{% for page in pages %}
<li>
<a href="{% url 'paginate' page per_page %}"><button>{{ page }}</button></a>
</li>
{% endfor %}
</ul>
<hr>
<ul>
{% for person in persons %}
<li>{{ person.name }} - {{ person.age }}</li>
{% endfor %}
</ul>
</body>
</html>
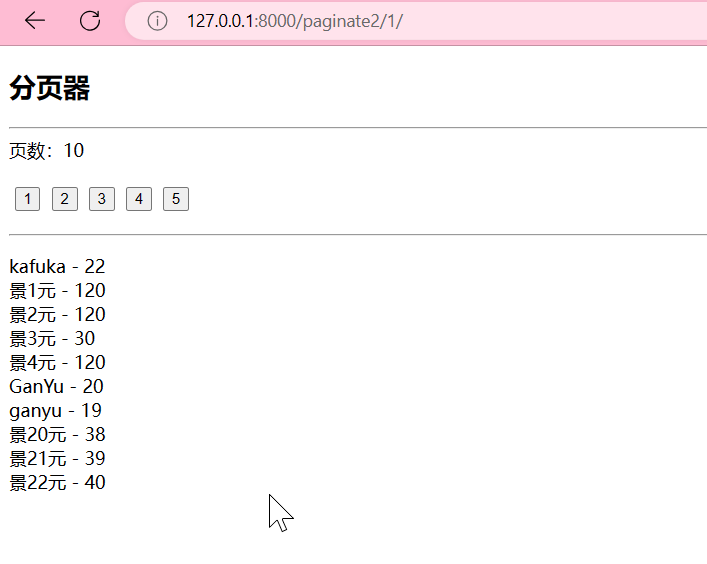
浏览器http://127.0.0.1:8000/paginate/1/10/
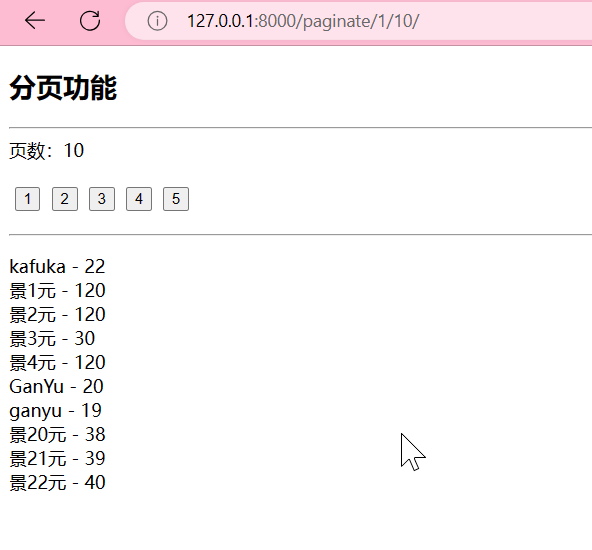
这就是最基本的分页功能啦!!!
Django中的自动分页器
Day03DjangoPro01\urls.py
path('paginate2/<int:page>/', paginate2, name="paginate2"),
App\views.py
# 分页器:自动分页
from django.core.paginator import Paginator
def paginate2(request, page=1):
per_page = 10 # 每页数据数量
all_data = PersonModel.objects.all()
# 使用分页器
paginator = Paginator(all_data, per_page)
persons = paginator.page(page) # 获取第page页的数据
pages = paginator.page_range # 页码的范围,可以遍历
data = {
"persons": persons,
"pages": pages,
"per_page": per_page
}
return render(request, "paginate2.html", data)
新建一个 templates\paginate2.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页器</title>
<style>
ul{
list-style: none;
padding: 0;
}
.btns{
display: flex ;
align-content: center;
}
.btns li{
margin: 5px;
}
</style>
</head>
<body>
<h2>分页器</h2>
<hr>
页数:{{ per_page }}
<ul class="btns">
{% for page in pages %}
<li>
<a href="{% url 'paginate2' page %}"><button>{{ page }}</button></a>
</li>
{% endfor %}
</ul>
<hr>
<ul>
{% for person in persons %}
<li>{{ person.name }} - {{ person.age }}</li>
{% endfor %}
</ul>
</body>
</html>
浏览器 http://127.0.0.1:8000/paginate2/1/
四、Django模型进阶
MYSQL和SQLite只是数据库不一样,配置不一样,其他的是一样的。
注意:我的 Django版本是4.2,MYSQL是8.0,Python 3.11.3
4.1 配置MySQL
1.安装mysql
2.MySQL驱动
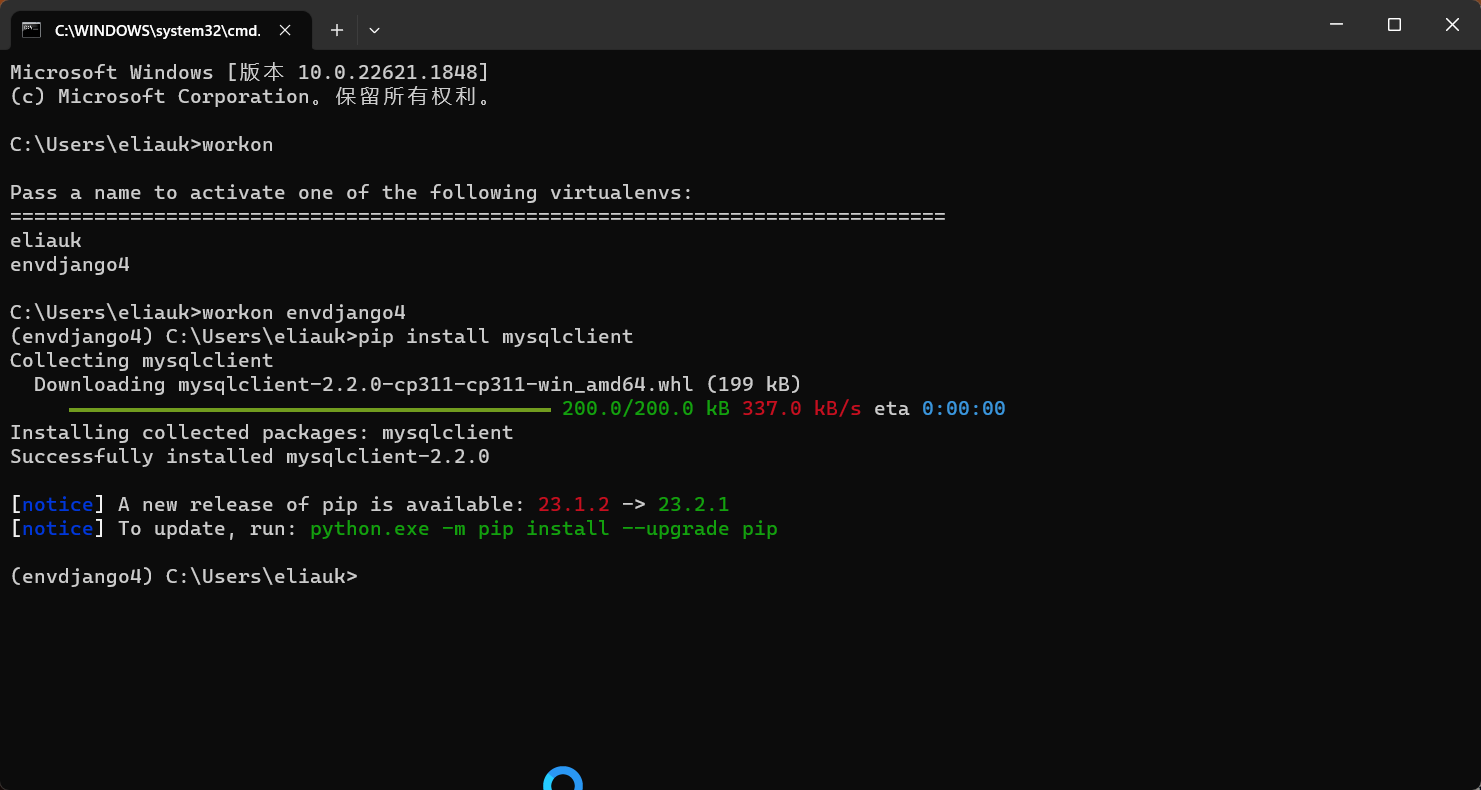
使用mysqlclient
pip install mysqlclient
(如果上面的命令安装失败,则尝试使用国内豆瓣源安装:
pip install -i https://pypi.douban.com/simple mysqlclient
)
(Linux Ubuntu下需要先安装:apt install libmysqld-dev
再安装:apt install libmysqld-dev
)
3.在Django中配置和使用mysq1数据库
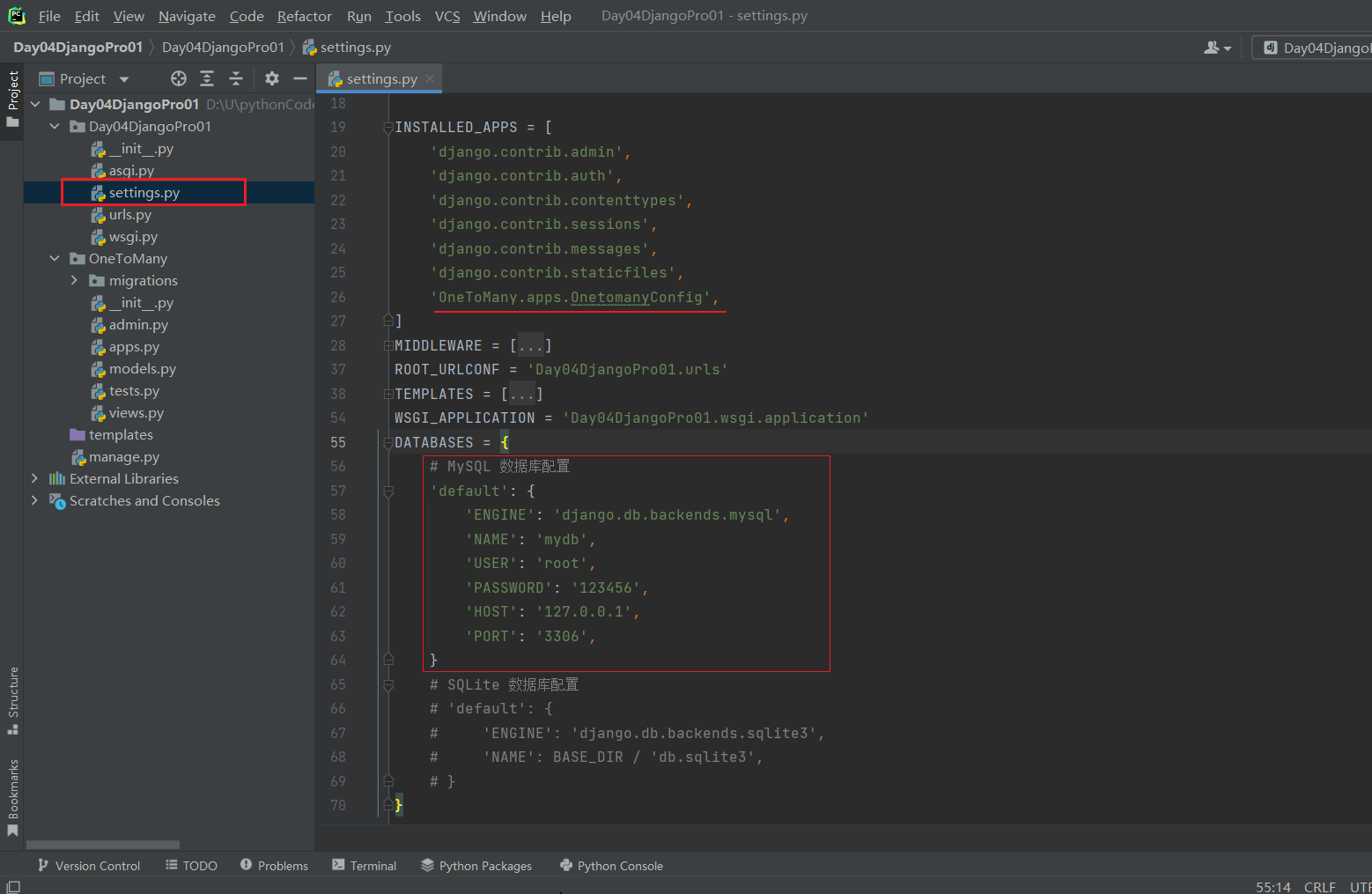
使用mysql数据库,settings中配置如下
DATABASES={
'default':{
'ENGINE':'django.db.backends.mysql',
'NAME':'mydb',
'USER':'root',
'PASSWORD':'123456',
'HOST':'127.0.0.1',
'PORT':'3306',
}
}
实践
workon envdjango4
pip install mysqlclient
新建一个新的项目Day04DjangoPro01
DATABASES = {
# MySQL 数据库配置
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'mydb', # 数据库名字
'USER': 'root', # 数据库的用户名
'PASSWORD': '123456', # 用户名对应的密码
'HOST': '127.0.0.1', # 数据库的主机IP
'PORT': '3306', # 端口
}
# SQLite 数据库配置
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': BASE_DIR / 'db.sqlite3',
# }
}
mysql -u root -p
输密码 我的是 123456
看一下数据库
show databases
创建新的数据库
create datadase 数据库名 charset=utf8;
注意这个数据库要求是一个空的数据库
使用数据库
use 数据库名
show tables;
怎么安装MySQL这里就不写了, 我偷懒就直接用小P(phpstudy)吧。网盘链接:https://pan.baidu.com/s/1Hc_oHRem4pY3VSmqCrbCjw?pwd=6666
提取码:6666
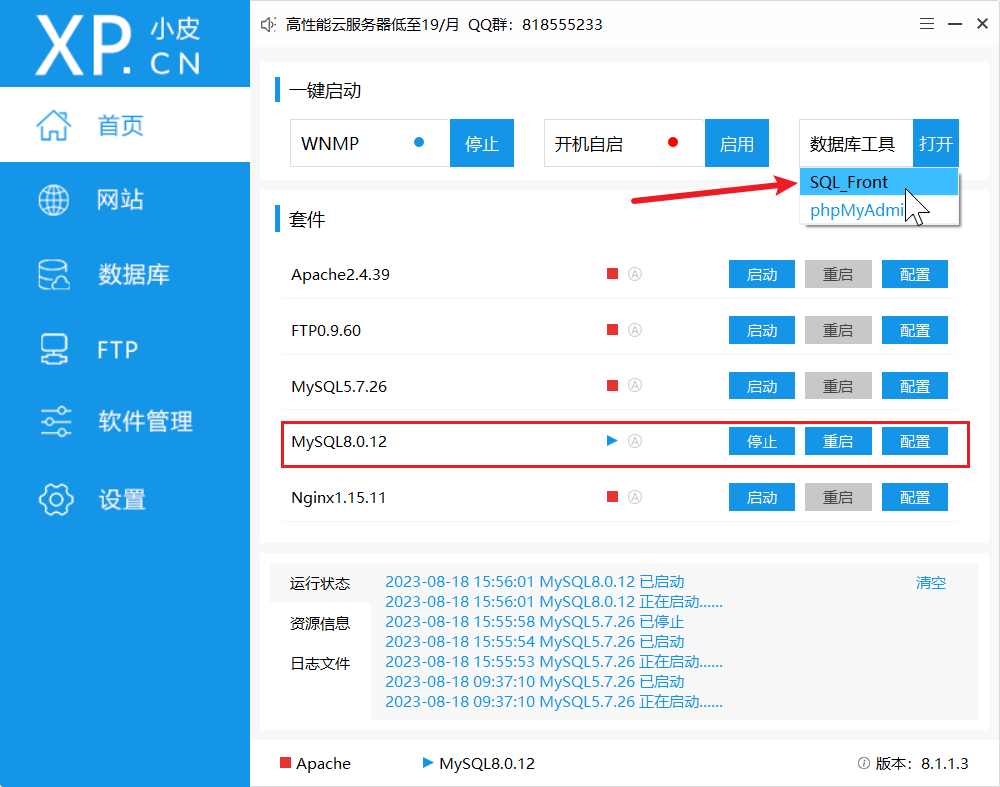
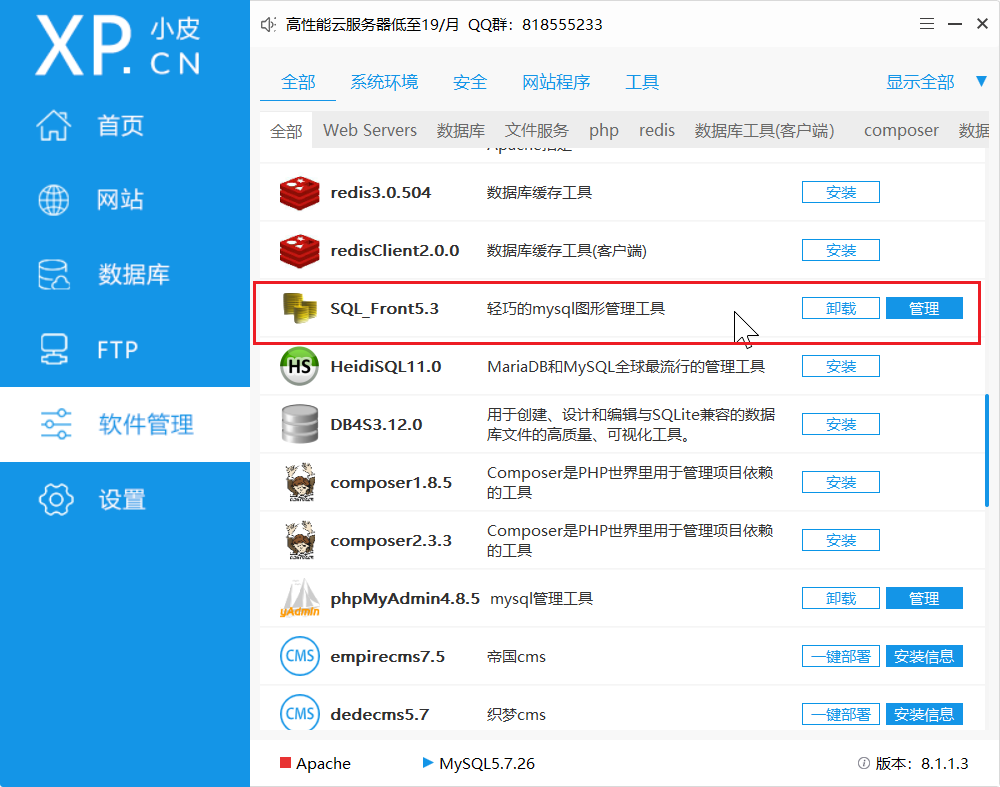
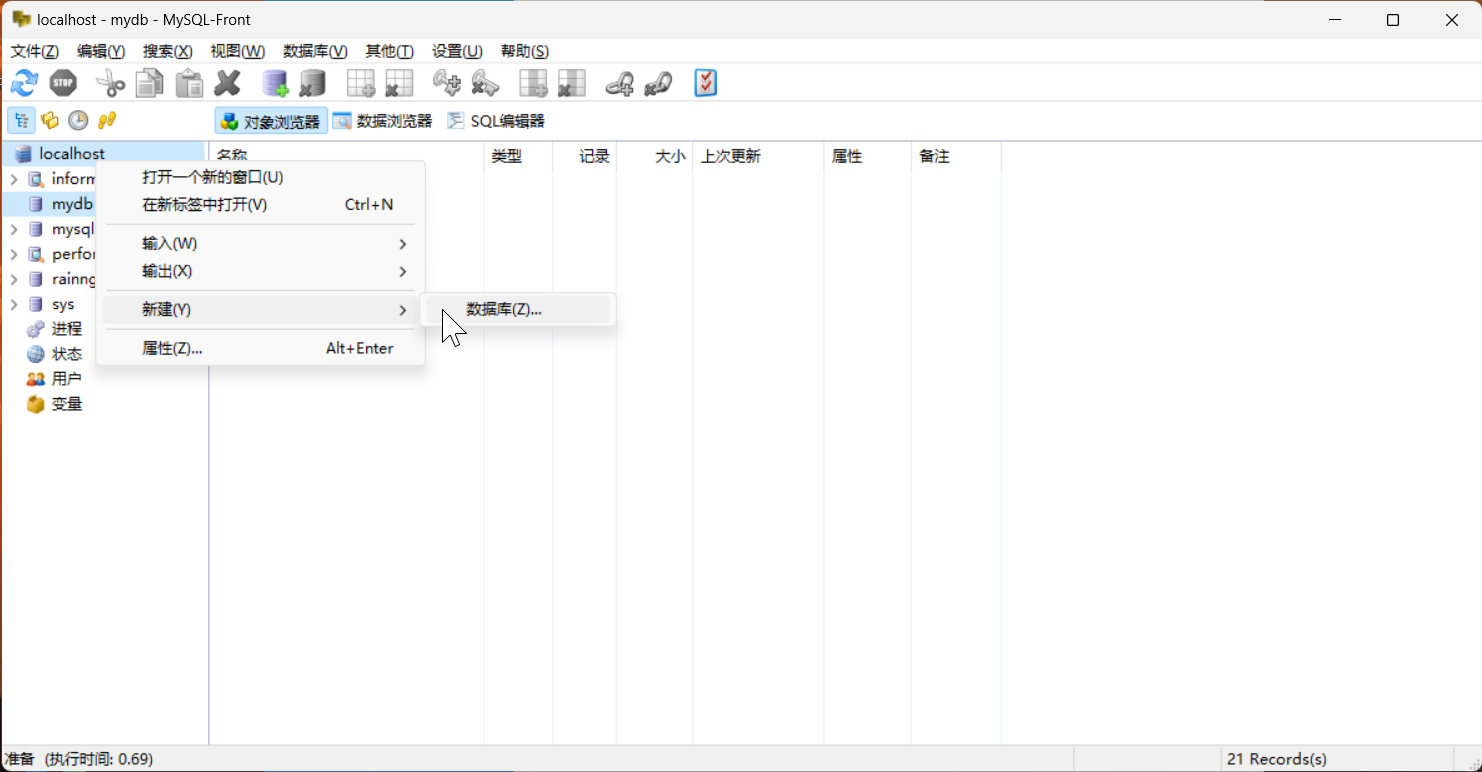
我们知道Django项目里面它自带本身有很多迁移文件,我们是不是可以把内部的迁移文件生成到数据库里面去呀?
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
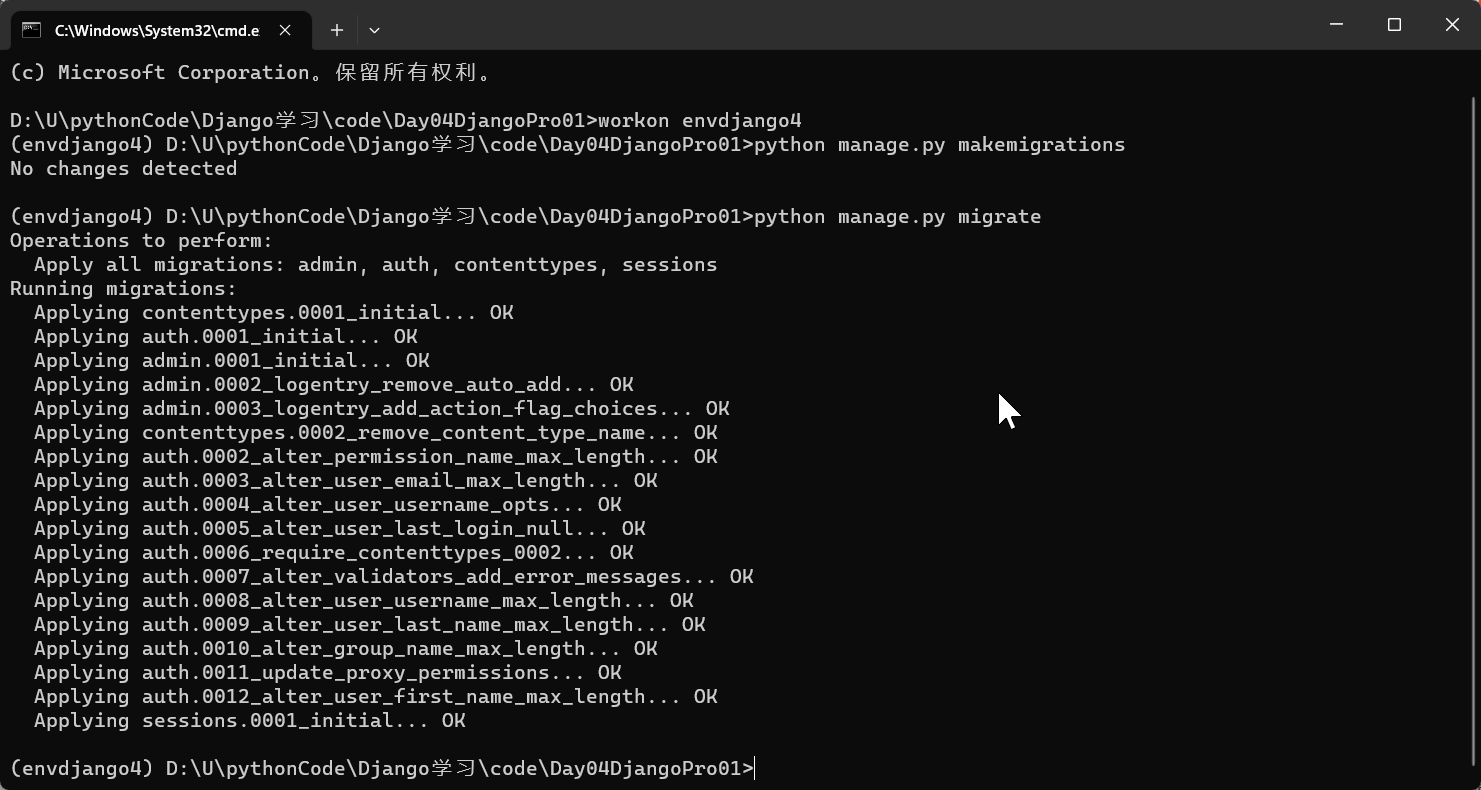
然后就成功啦!!!
报错1:django.db.utils.NotSupportedError: MySQL 8 or later is required (found 5.7.26).
说是MYSQL兼容问题
解决办法:数据库更新到 8.0就好啦
报错2:RuntimeWarning: Got an error checking a consistent migration history performed for database connection ‘default’: (1045, “Access denied for user ‘root’@‘localhost’ (using password: YES)”)
用户密码错了,所以连接不上。
4.2 多模块关联关系
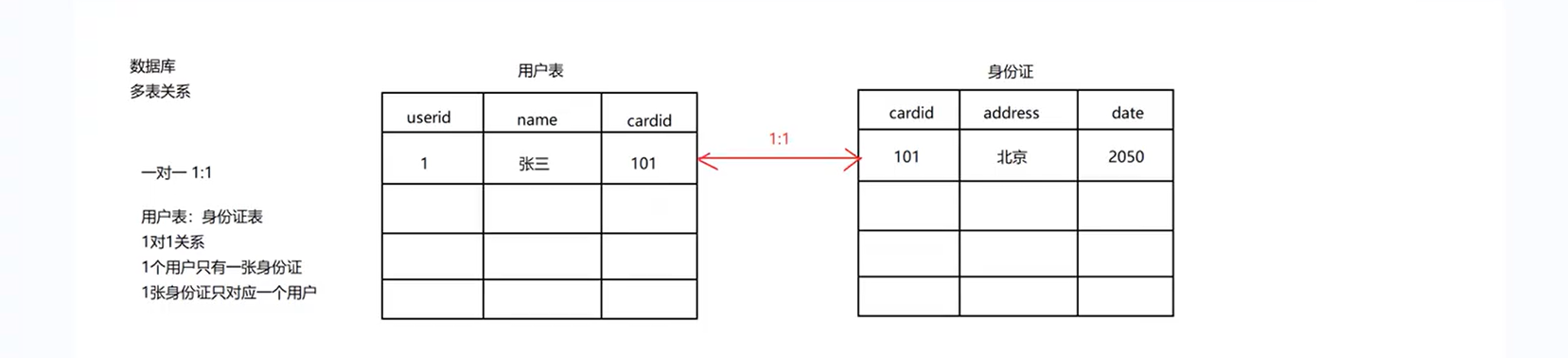
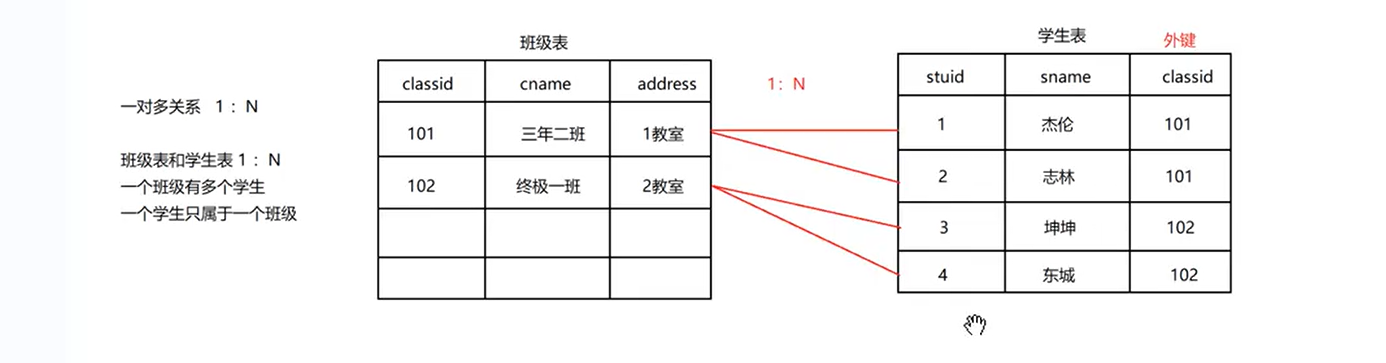
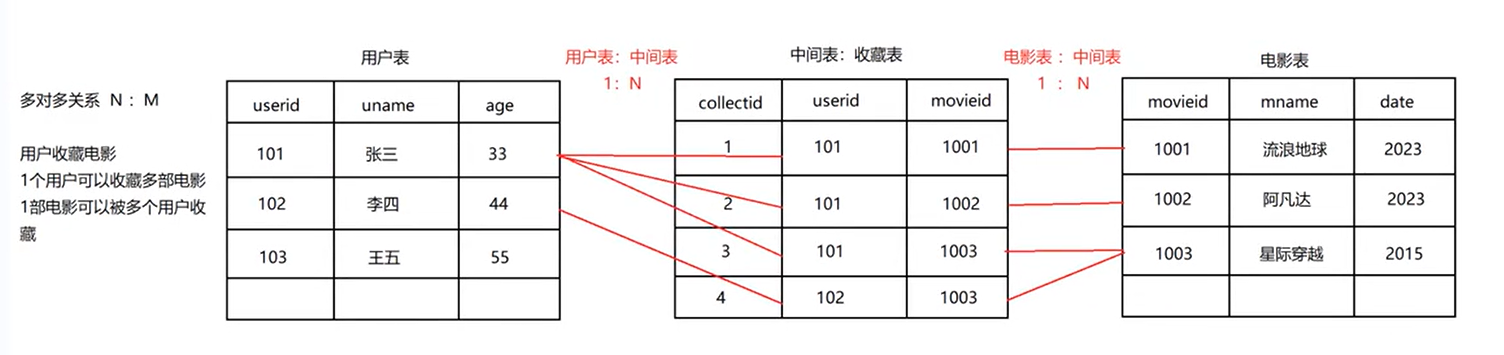
多个模块关联
关联分类
- ForeignKey:一对多,将字段定义在多的端中
- ManyToManyField: 多对多,将字段定义在两端的任意一端中
- OneToOneField:一对一,将字段定义在任意一端中
一对多关系,举例说明 (一对一, 多对多类似) :
一个班级可以有多个学生,一个学生只能属于一个班级
class Grade(models.Model):
name = models.CharField(max_length=20)
class Student(models.Model):
name = models.CharField(max_length=20)
grade = models.ForeignKey(Grade)
对象的使用:
正向 (在Student这边,有grade属性的这一边):
获取学生所在班级(对象):stu.grade
获取学生所在班级的属性:stu.grade.name
反向(在Grade这边):
获取班级的所有学生(获取Manager对象):grade.student_set
获取班级的所有学生(获取QuerySet查询集): grade.student_set.all()
filter(),get()等操作中的使用:
正向(在Student这边,有grade属性的这一边)
Student.objects.filter(属性__name='1')
如: Student.objects.filter(grade__name='1')
反向(在Grade这边)
Grade.objects.filter(类名小写__id=7)
如: Grade.objects.filter(student__id=7)
xx_set 其实是一个管理器 ,类似于 objects ,通过它 .filter() 或者 .all() 就可以拿到所有查询到的结果(叫查询集)。
4.3 Model连表结构
一对多: models.ForeignKey(其他表)
多对多: models.ManyToManyField(其他表)
一对一: models.OneToOneField(其他表)
应用场景:
一对多:当一张表中创建一行数据时,有一个单选的下拉框(可以被重复选择)
例如: 创建用户信息时候,需要选择一个用户类型[普通用户][金牌用户][铂金用户]
多对多:在某表中创建一行数据时,有一个可以多选的下拉框。 (猫眼App,淘票票,格拉瓦电影)
例如:创建用户信息,需要为用户指定多个爱好。
一对一:在某表中创建一行数据时,有一个单选的下拉框(下拉框中的内容被用过一次就消失了)
例如:有个身份证表,有个person表。每个人只能有一张身份证,一张身份证也只能对应一个人,这就是一对一关系。
4.3.1 一对多关联
一对多关系,即外键
为什么要用一对多。先来看一个例子。有一个用户信息表,其中有个用户类型字段,存储用户的用户类型。如下:
class UserInfo(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField()
user_type = models.CharField(max_length=10)
不使用外键时用户类型存储在每一行数据中。如使用外键则只需要存储关联表的id即可,能够节省大量的存储空间。同时使用外键有利于维持数据完整性和一致性.
当然也有缺点,数据库设计变的更复杂了。每次做DELETE 或者UPDATE都必须考虑外键约束。
刚才的例子使用外键的情况: 单独定义一个用户类型表:
class UserType(models.Model):
caption = models.CharField(max_length=32)
class UserInfo(models.Model):
user_type = models.ForeignKey('UserType')
username = models.CharField(max_length=32)
age = models.IntegerField()
我们约定:
正向操作: ForeignKey在UserInfo表里,如果根据UserInfo去操作就是正向操作。
反向操作: ForeignKey不在UserType里,如果根据UserType去操作就是反向操作。
一对多的关系的增删改查:
正向操作:
增
1)创建对象实例,然后调用save方法
obj = UserInfo(name='li',age=44, user_type_id=2)
obj.save()
2)使用create方法
UserInfo.objects.create(name='li',age=44,user_type_id=2)
3)使用get_or_create方法,可以防止重复
UserInfo.objects.get_or_create(name='li',age=55,user_type_id=2)
4)使用字典
dic = {'name':'zhangsan', 'age':18, 'user_type_id':3}
UserInfo.objects.create(**dic)
5)通过对象添加
usertype = UserType.objects.get(id=1)
UserInfo.objects.create(name='li',age=55,user_type=usertype)
删
和普通模式一样删除即可。如:
UserInfo,objects.filter(id=1).delete()
改
和普通模式一样修改即可。如:
UserInfo.objects.filter(id=2).update(user_type_id=4)
查
正向查找所有用户类型为钻石用户的用户,使用双下划线:
users = UserInfo.objects,filter(user_type__caption__contains='钻石')
# __contains是过滤条件 like '%钻石%'
正向获取关联表中的属性可以直接使用点.语法,比如:
获取users查询集中第一个用户的caption:
users[0].user_type.caption
反向操作:
增(一般使用正向增即可)
通过usertype来创建userinfo
1)通过userinfo_set的create方法
#获取usertype实例
ut = UserType.objects.get(id=2)
#创建userinfo
ut.userinfo_set.create(name='smith',age=33)
删
删除操作可以在定义外键关系的时候,通过on_delete参数来配置删除时做的操作。
on_delete参数主要有以下几个可选值:
models.CASCADE 默认值(Django1.11),表示级联删除,即删除UserType时,相关联的UserInfo也会被删除。
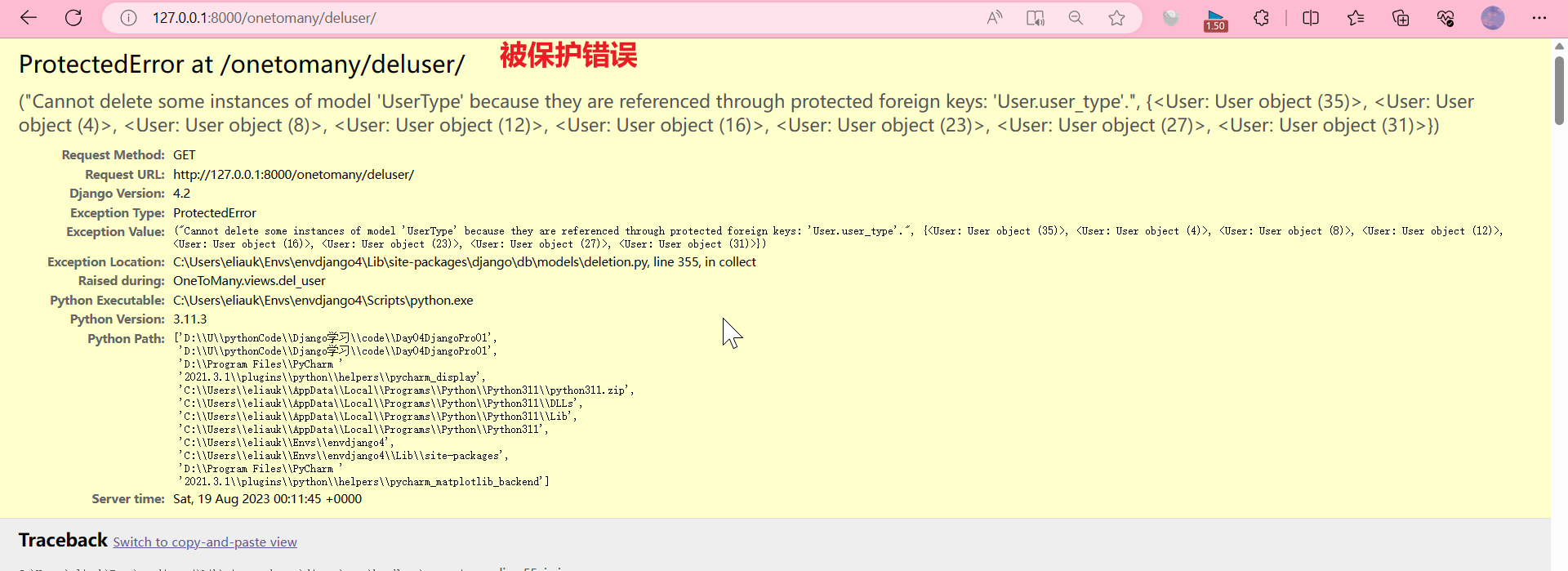
models.PROTECT 保护模式, 阻止级联删除。如果UserType还有关联的User存在,那么他就阻止你不让你删除。删除的时候可能报错。
models.SET_NULL 置空模式,设为null,null=True参数必须具备。删除UserType的时候不会将所关联的用户删掉,而是把关联的User外键的值置空
models.SET_DEFAULT 置默认值 设为默认值,default参数必须具备。如果删除UserType,关联的User外键的值不置空,设置成指定的值
models.SET(函数名) 删除的时候重新动态指向一个实体访问对应元素,可传函数
models.DO_NOTHING 什么也不做。 (Django1.11)。外键不会动,但是这样关联的外键就是错误的。
注意:修改on_delete参数之后需要重新同步数据库,如果使用的话。需要重新迁移!!!
一般建议 PROTECT 或者 SET_NULL 或者 SET_DEFAULT
改
和普通模式一样,不会影响级联表
查
通过usertype对象来查用户类型为1的用户有哪些
obj=UserType.objects.get(id=1)
obj.userinfo_set.all()
可以通过在定义foreignkey时指定related_name来修改默认的userinfo_set,
比如指定related_name为info
user_type = models.ForeignKey('UserType', related_name='info')
指定related_name之后,反向查的时候就变成了
obj.info.all()
获取用户类型为1且用户名为shuaige的用户
obj.info.filter(username='shuaige')
外键关系中,django自动给usertype加了一个叫做userinfo的属性。使用双下划线。
可以通过userinfo提供的信息来查usertype (了解)
user_type_obj = UserType.objects.get(userinfo__username='zs')
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
实践
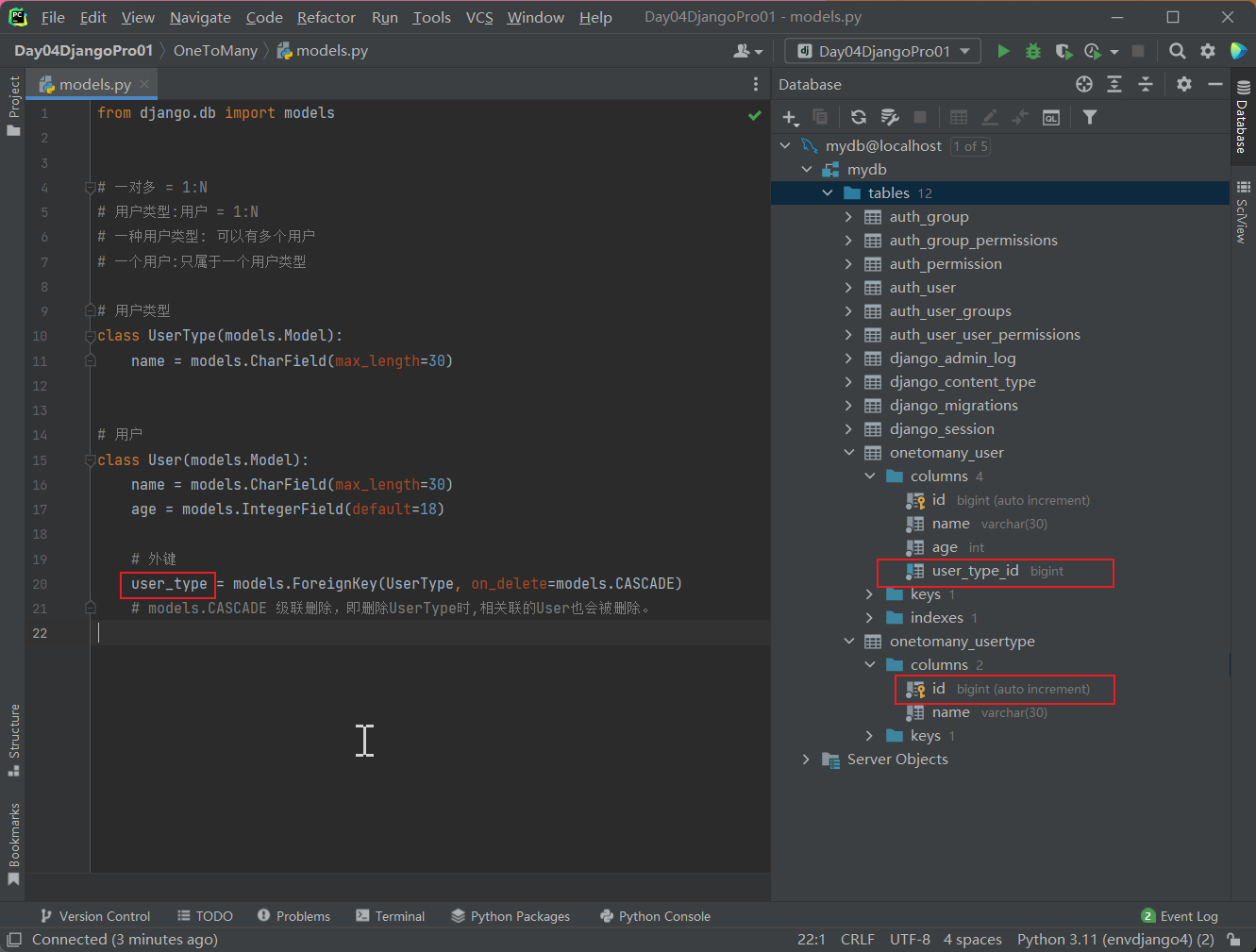
OneToMany\models.py
from django.db import models
# 一对多 = 1:N
# 用户类型:用户 = 1:N
# 一种用户类型: 可以有多个用户
# 一个用户:只属于一个用户类型
# 用户类型
class UserType(models.Model):
name = models.CharField(max_length=30)
# 用户
class User(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField(default=18)
# 外键
user_type = models.ForeignKey(UserType, on_delete=models.CASCADE)
# models.CASCADE 级联删除,即删除UserType时,相关联的User也会被删除。
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
注意:用户表(User)中我们代码写的是user_type,但是数据库写的是user_type_id,这个有区别,它的类型跟 用户类型(UserType) 的主键是一样的。我们在后面使用的时候,可以使用user_type也可以使用user_type_id,但其实得到user_type呢相当于得到上面UserType对象了 ,得到这个对象之后再去 .id .name是可以的。
增加数据
OneToMany\views.py
from django.shortcuts import render, HttpResponse
from OneToMany.models import *
# 一对多关系
# 添加数据
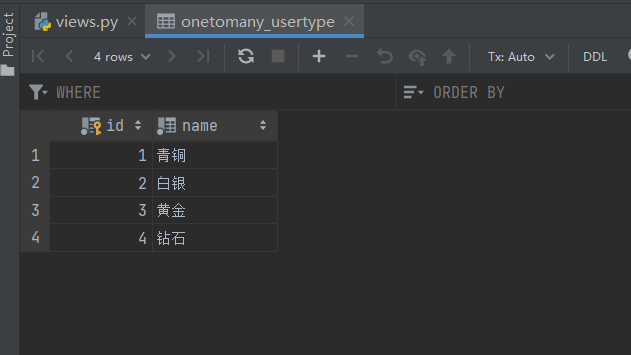
def add_user(request):
# 给UserType添加数据
user_types = ['青铜', '白银', '黄金', '钻石']
for name in user_types:
UserType.objects.create(name=name)
return HttpResponse("添加成功")
根路由Day04DjangoPro01\urls.py
from django.contrib import admin
from django.urls import path
from OneToMany import views as onetomany_view
urlpatterns = [
path('admin/', admin.site.urls),
# onetomany
path('onetomany/adduser/', onetomany_view.add_user ),
]
运行python .\manage.py runserver
http://127.0.0.1:8000/onetomany/adduser/
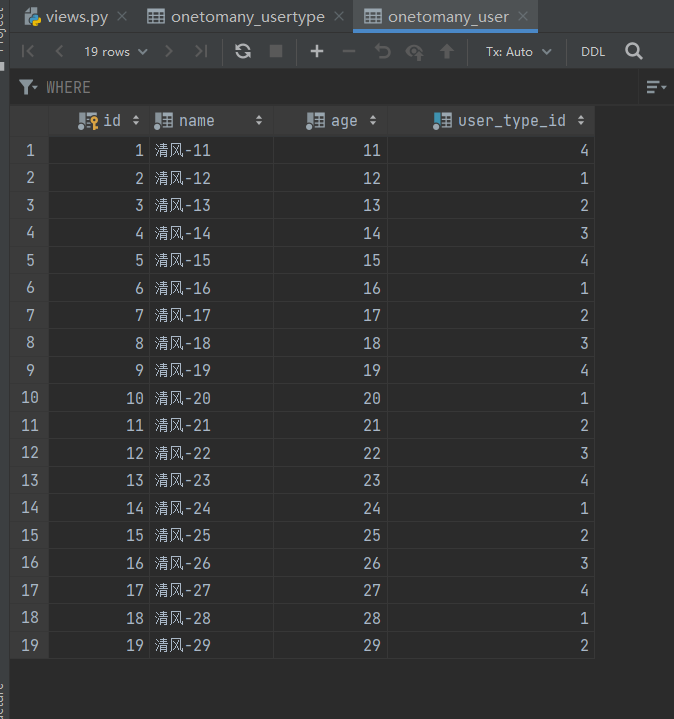
添加完之后,代码注释了,现在写添加User表,OneToMany\views.py
第一种用 user_type_id= id
def add_user(request):
# # 用完就注释
# # 给UserType添加数据
# user_types = ['青铜', '白银', '黄金', '钻石']
# for name in user_types:
# UserType.objects.create(name=name)
# 给User表添加数据
for i in range(11, 30):
User.objects.create(name=f'清风-{i}',age=i,
user_type_id=i % 4 + 1) # i % 4 + 1 = 1~4
return HttpResponse("添加成功")
http://127.0.0.1:8000/onetomany/adduser/
第二种用 user_type= 用户类型的对象
def add_user(request):
# # 用完就注释
# # 给UserType添加数据
# user_types = ['青铜', '白银', '黄金', '钻石']
# for name in user_types:
# UserType.objects.create(name=name)
# 给User表添加数据
for i in range(11, 30):
# User.objects.create(name=f'清风-{i}', age=i,
# user_type_id=i % 4 + 1) # i % 4 + 1 = 1~4
User.objects.create(name=f'微泫-{i}', age=i + 100,
user_type=UserType.objects.get(pk=i % 4 + 1))
return HttpResponse("添加成功")
http://127.0.0.1:8000/onetomany/adduser/
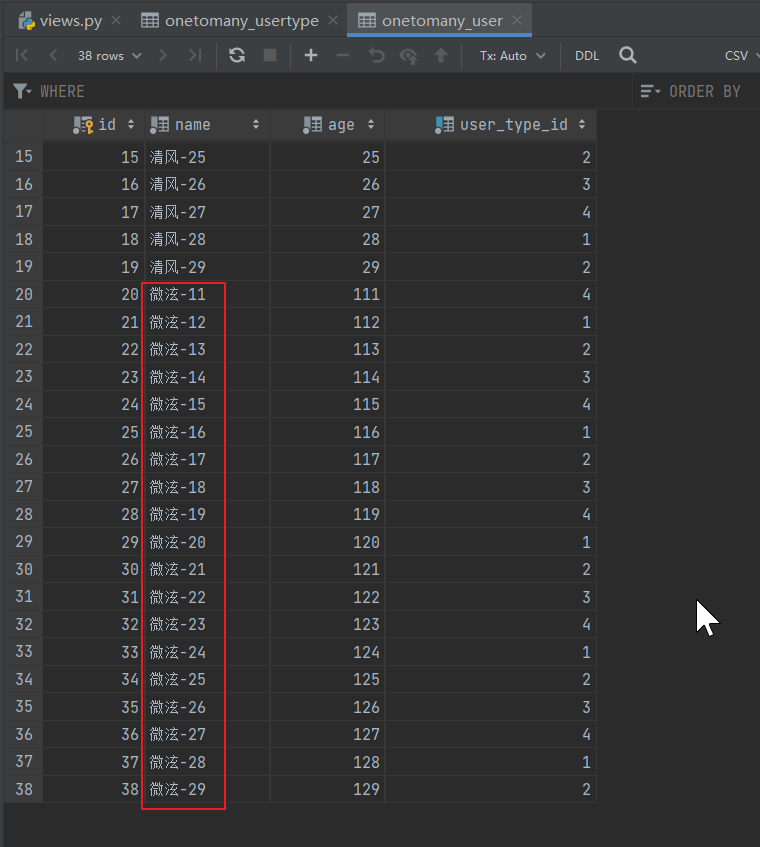
删除数据
根路由Day04DjangoPro01\urls.py
path('onetomany/deluser/', onetomany_view.del_user),
OneToMany\views.py
删除用户数据
# 删除数据
def del_user(request):
# 删除User数据
User.objects.filter(id=6).delete()
return HttpResponse('删除成功')
http://127.0.0.1:8000/onetomany/deluser/
删除UserType数据
def del_user(request):
# 删除User数据
# User.objects.filter(id=6).delete()
# 删除UserType数据
UserType.objects.filter(id=2).delete()
return HttpResponse('删除成功')
http://127.0.0.1:8000/onetomany/deluser/
执行之后,可以观察到UserType表删除了id=2的数据,User表删除了外键user_type_id是2的数据。
因为前面Models设置了 models.CASCADE 表示级联删除,即删除UserType时,相关联的User也会被删除。
试试其他的模式
OneToMany\models.py
user_type = models.ForeignKey(UserType, on_delete=models.PROTECT) # 保护模式
浏览器 http://127.0.0.1:8000/onetomany/deluser/
user_type = models.ForeignKey(UserType, on_delete=models.SET_NULL, null=True) # 置空模式
user_type = models.ForeignKey(UserType, on_delete=models.SET_DEFAULT, default=1) # 置默模式
def fn():
return 4
# 用户
class User(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField(default=18)
# 外键
# user_type = models.ForeignKey(UserType, on_delete=models.CASCADE)
# models.CASCADE 级联删除,即删除UserType时,相关联的User也会被删除。
# user_type = models.ForeignKey(UserType, on_delete=models.PROTECT) # 保护模式
# user_type = models.ForeignKey(UserType, on_delete=models.SET_NULL, null=True) # 置空模式
# user_type = models.ForeignKey(UserType, on_delete=models.SET_DEFAULT, default=1) # 置默模式
user_type = models.ForeignKey(UserType, on_delete=models.SET(fn)) # 删除的时候重新动态指向一个实体访问对应元素,可传函数
其实models.SET(函数名) 跟 models.SET_DEFAULT 差不多
user_type = models.ForeignKey(UserType, on_delete=models.DO_NOTHING) # 什么都不做
测试完我们还是用 user_type = models.ForeignKey(UserType, on_delete=models.PROTECT) # 保护模式 吧
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
修改数据
和普通模式一样,不会影响级联表
根路由Day04DjangoPro01\urls.py
path('onetomany/updateuser/', onetomany_view.update_user),
OneToMany\views.py
# 修改数据
def update_user(request):
# 修改UserType
UserType.objects.filter(id=1).update(name="王者")
return HttpResponse('修改成功')
def update_user(request):
# 修改UserType
# UserType.objects.filter(id=1).update(name="王者")
# 修改User
User.objects.filter(id=2).update(age=1000)
return HttpResponse('修改成功')
http://127.0.0.1:8000/onetomany/updateuser/
查询数据
根路由Day04DjangoPro01\urls.py
path('onetomany/getuser/', onetomany_view.get_user),
正向查询:有属性的地方直接查询,写了外键的地方直接查就是正向查询,通过 用户User 查找他所对应的 用户类型UserType
反向查询:通过 用户类型UserType 查找 用户User
OneToMany\views.py
前三种查询
1、正向查询
2、反向查询
UserType对象.user_set.all()
主表对象.从表名_set.all()
3、在filter中
User.objects.filter(UserType)
相比于第2种_set , 从时间成本来考虑的话还是使用 filter 筛选效率更高一些。
# 查询数据
def get_user(request):
# 1.正向查询:通过用户查找用户类型
user = User.objects.get(id=2)
print("用户:", user.name, user.age, user.user_type, user.user_type_id)
# user.user_type => UserType对象
print("用户所属的类型:", user.user_type.id, user.user_type.name) # User所属UserType的所有数据
print('-' * 60)
# 2.反向查询:通过用户类型查找用户
utype = UserType.objects.get(pk=1)
print('UserType自己的属性', utype.id, utype.name)
# user_set: 是内部自动生成的属性, 可以让你反向查询到所有用户User集合
print(utype.user_set) # OneToMany.User.None 你可以认为它是一个管理对象
print(type(utype.user_set)) # RelatedManager 关联的管理器对象
# <class 'django.db.models.fields.related_descriptors.create_reverse_many_to_one_manager.<locals>.RelatedManager'>
print(utype.user_set.all()) # 所有数据的 查询集 QuerySet
print('+' * 60)
# 3.在filter中还可以这么用
# 比如:查找用户类型名称为'黄金'的所有用户
users = User.objects.filter(user_type=UserType.objects.get(name='黄金')) # 传入UserType对象
users = User.objects.filter(user_type_id=4) # 传入user_type_id
users = User.objects.filter(user_type__name='黄金') # 传入UserType对象的name属性作为条件
# filter(user_type__name='黄金') 加两个下划线__反向引用去查找
print(users)
return HttpResponse("查询成功")
第四种查询
4、related_name: 关联名称
related_name 是我们用于反向查找的内容。通常,为所有外键提供 related_name 是一个好习惯,而不是使用 Django 的默认相关名称。
related_name默认是小写外键的表名_set或者也可以这么理解子表的表名小写_set
主表 UserType表:表中有一个主键被其他表用来当外键的表。
从表(子表)User表:把另外一个表中的主键当做自己的外键的表。
主表对象.从表名_set.all()
主表对象.设置的related_name.all()
OneToMany\models.py
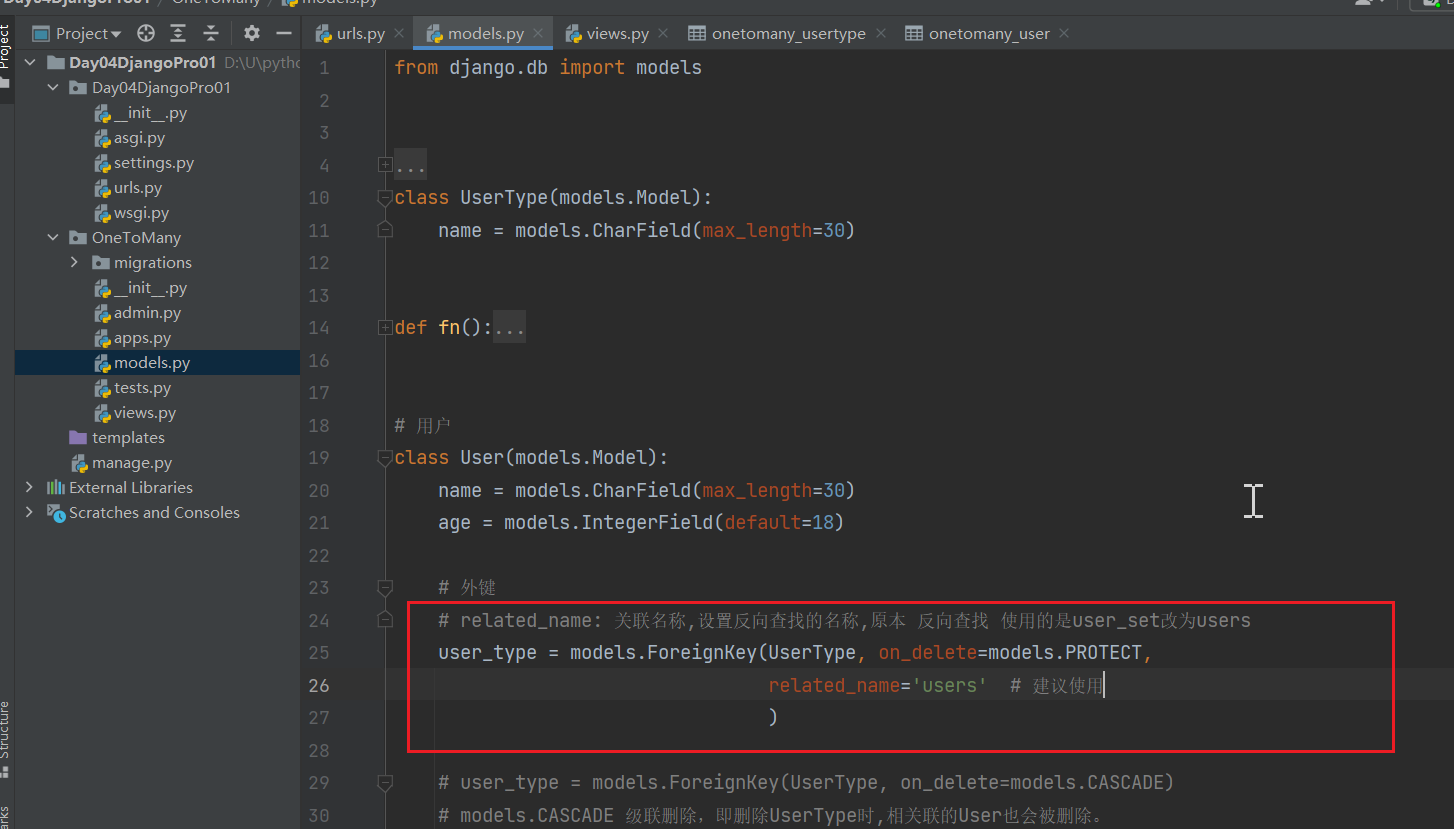
class User(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField(default=18)
# 外键
# related_name: 关联名称,设置反向查找的名称,原本 反向查找 使用的是user_set改为users
user_type = models.ForeignKey(UserType, on_delete=models.PROTECT,
related_name='users' # 建议使用
)
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
OneToMany\views.py
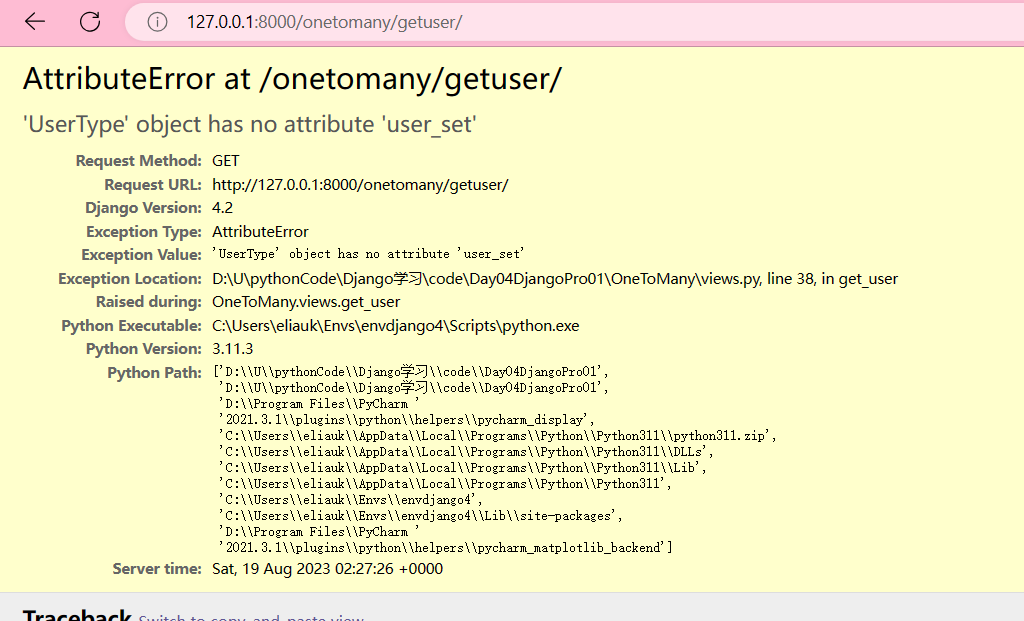
def get_user(request):
print('=' * 60)
# 4.related_name: 关联名称
utype = UserType.objects.get(pk=1)
# print(utype.user_set.all()) # 会报错 AttributeError 'UserType' object has no attribute 'user_set'
# 使用了related_name就不可以在使用带_set的属性
print(utype.users.all()) # <QuerySet [<User: User object (2)>, ...] >
return HttpResponse("查询成功")
执行完迁移之后,现在我们不能再用user_set了,使用就会报错AttributeError ‘UserType’ object has no attribute ‘user_set’。如果我们使用了related_name,原来的属性user_set就不能使用了。
使用了related_name就不可以在使用带_set的属性
4.3.2 多对多关联
多对多其实就是两个一对多,如果不在乎中间表 ,我们可以直接建两边的表,中间的不用管。
多对多关系
针对多对多关系django会自动创建第三张表。也可以通过through参数指定第三张表。
用户和组是典型的多对多关系:
class Group(models.Model):
name = models.CharField(max_length=20)
def __str__(self):
return self.name
class User(models.Model):
name = models.CharField(max_length=64)
password = models.CharField(max_length=64)
groups = models.ManyToManyField(Group)
def __str__(self):
return self.name
操作:
增:
先分别创建user和group,再使用add关联
u = User(name='aa', password='123')
u.save()
g = Group(name='g5')
g.save()
通过Manager对象使用add()方法
u.groups.add(g) 或 g.user_set.add(u)
删:
和一对多类似,删除user或group会级联删除user_groups表中的关联数据
改:
和一对多类似,只修改当前表
查:
正向:
查询id=2的用户所在的所有组group
u = User.objects.get(id=2)
u.groups.al1()
反向:
查询id=1的组中包含的所有用户
g = Group.objects.get(id=1)
g.user_set.all()
实践
新建一个应用 叫 ManyToMany
python manage.py startapp ManyToMany
创建好之后一定要记得注册 Day04DjangoPro01\settings.py
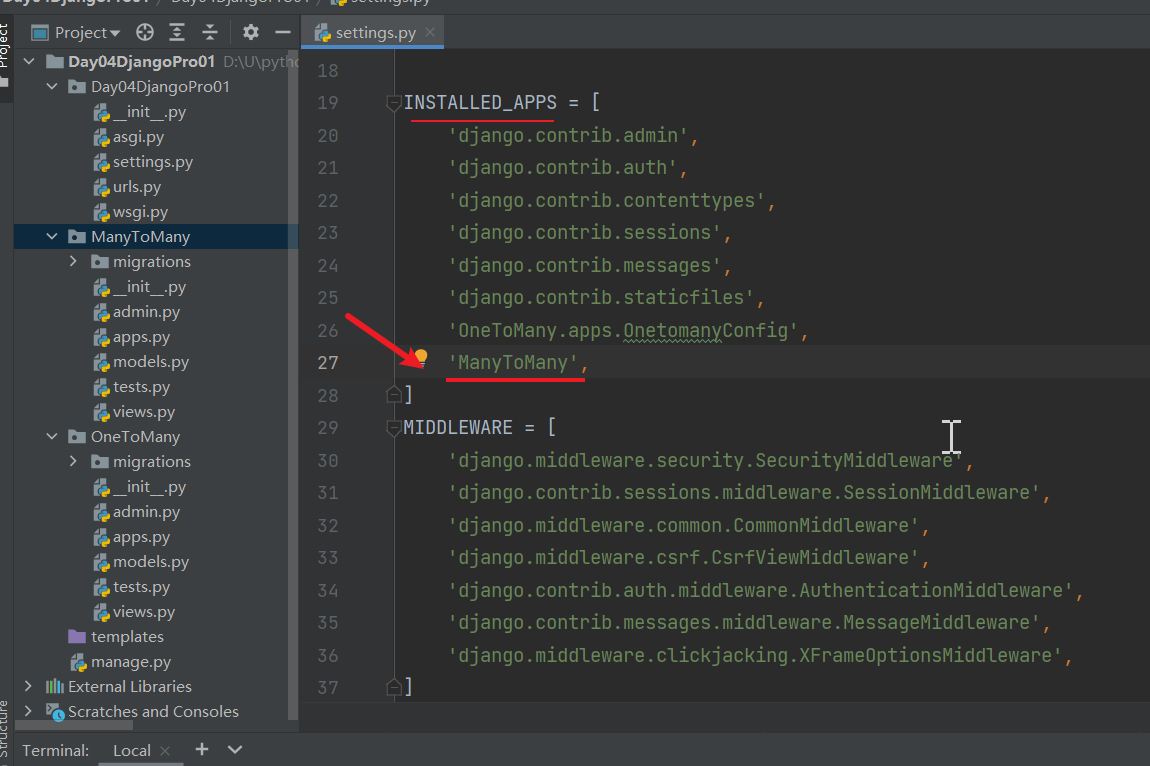
ManyToMany\models.py
from django.db import models
# 多对多
# 用户:电影 = N:M
# 一个用户可以收藏多部电影,一部电影可以被不同用户收藏
# 电影
class Movie(models.Model):
name = models.CharField(max_length=52)
duration = models.IntegerField(default=90) # 电影时长:默认90分钟
# 用户
class User(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField(default=18)
# 多对多关系
movies = models.ManyToManyField(Movie)
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
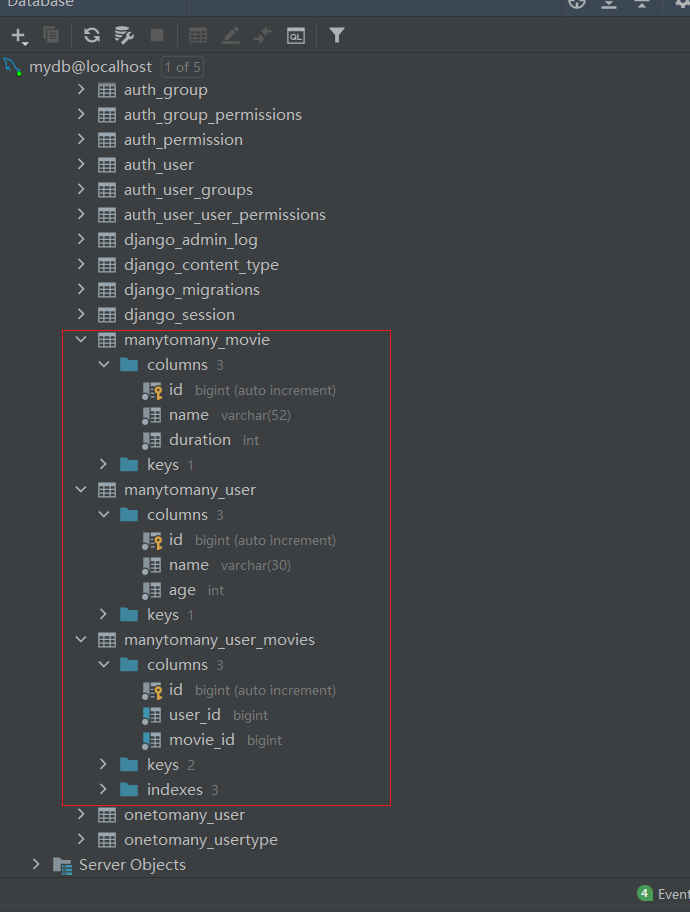
可以看到创建了三个表。
添加数据
子路由不写了,直接写根路由上吧,Day04DjangoPro01\urls.py
写视图函数ManyToMany\views.py
from django.shortcuts import render, HttpResponse
from ManyToMany.models import *
# 多对多
# 增加数据
def add(request):
# 添加User数据
for i in range(1, 10):
User.objects.create(name=f'张三{i}', age=i)
# 添加Movie
for i in range(1, 10):
Movie.objects.create(name=f'消失的她{i}', duration=100+i)
return HttpResponse("添加成功")
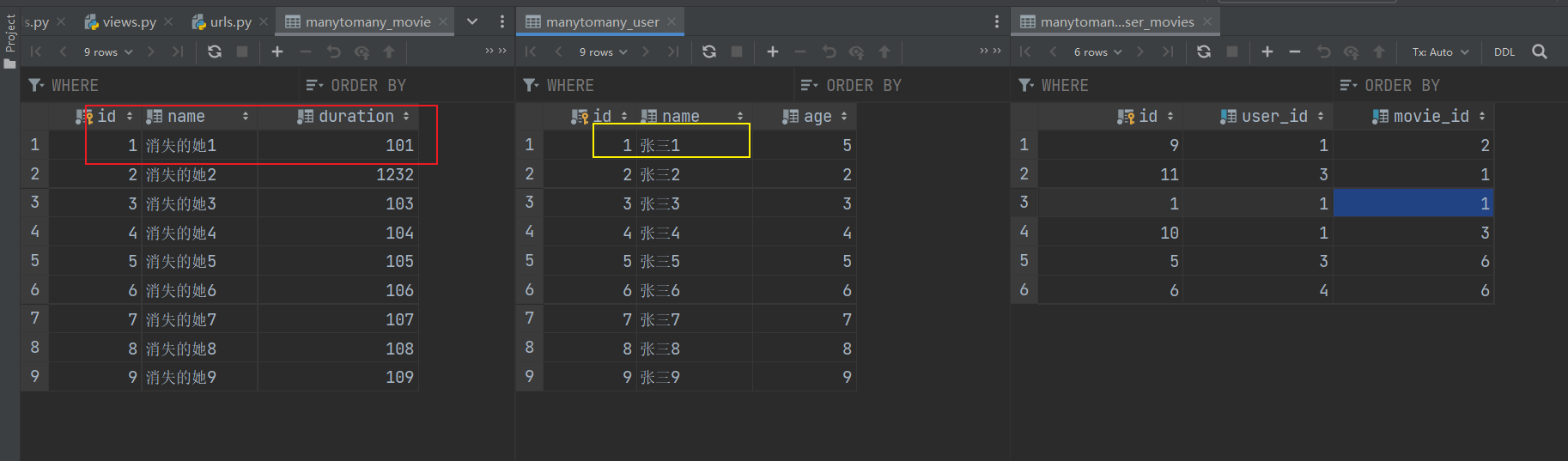
http://127.0.0.1:8000/manytomany/add/
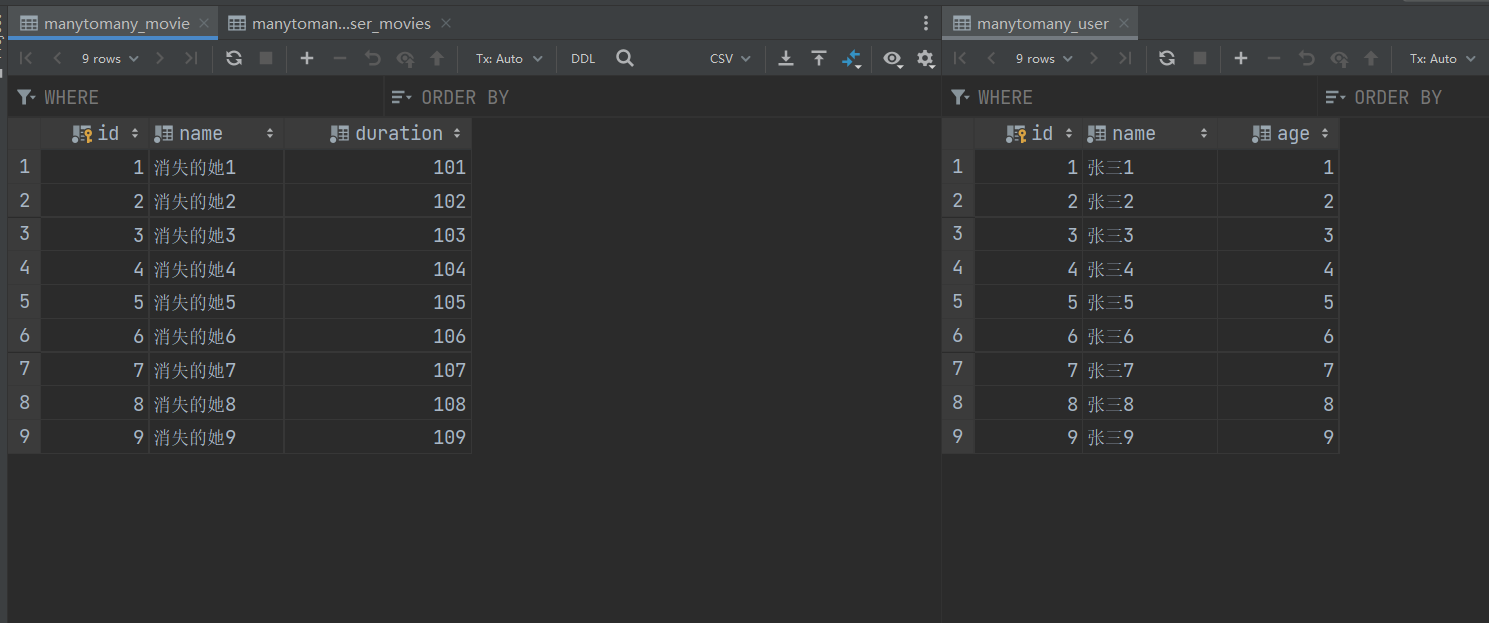
添加完这两个表之后,我们要添加中间表的数据
写法一
ManyToMany\views.py
def add(request):
# 让 张三1 收藏 消失的她1
user = User.objects.get(name='张三1')
movie = Movie.objects.get(name='消失的她1')
# 添加收藏
user.movies.add(movie) # 用户收藏电影
return HttpResponse("添加成功")
浏览器 http://127.0.0.1:8000/manytomany/add/
可以多刷新几次试试,添加是不会重复的
写法二
ManyToMany\views.py
def add(request):
# 让 张三1 收藏 消失的她2
user = User.objects.get(name='张三1')
movie = Movie.objects.get(name='消失的她2')
# 添加收藏
# user.movies.add(movie) # 用户收藏电影
movie.user_set.add(user) # 让用户收藏电影
return HttpResponse("添加成功")
浏览器 http://127.0.0.1:8000/manytomany/add/
手动添加点数据吧
修改数据
一般多对多关系中不涉及到中间表修改,如果要对单表修改那就跟前面的一样了。
删除数据
Day04DjangoPro01\urls.py
path('manytomany/delete/', manytomany_view.delete),
删除电影
ManyToMany\views.py
def delete(request):
# 删除User
# User.objects.get(id=9).delete()
# 删除Movie
# Movie.objects.get(id=9).delete()
# 删除中间表
user = User.objects.get(name='张三1')
user.movies.filter(name='消失的她2').delete() # 删除用户收藏的电影
# user.movies.filter 这里已经到了Movie,所以可以使用name,这个name是Movie的name
return HttpResponse('删除成功')
http://127.0.0.1:8000/manytomany/delete/
效果:电影表中 name=消失的她2 都被删了,中间表有关 电影消失的她2 的数据 也被删了。
注意: 假如 中间表 张三1 没有收藏 消失的她2 的记录,中间表、电影表那么就不会有任何效果。
删除用户
效果其实类似,反过来就好了
ManyToMany\views.py
def delete(request):
movie = Movie.objects.get(name='消失的她1')
movie.user_set.filter(name='张三1').delete()
return HttpResponse('删除成功')
http://127.0.0.1:8000/manytomany/delete/
查询
Day04DjangoPro01\urls.py
path('manytomany/get/', manytomany_view.get_user_movie),
ManyToMany\views.py
# 查询数据
def get_user_movie(request):
# 获取用户收藏的所有电影
user = User.objects.get(name='张三1')
print(user.movies.all())
# 获取电影被哪些用户收藏了
movie = Movie.objects.get(name='消失的她1')
print(movie.user_set.all())
return HttpResponse("查询成功")
http://127.0.0.1:8000/manytomany/get/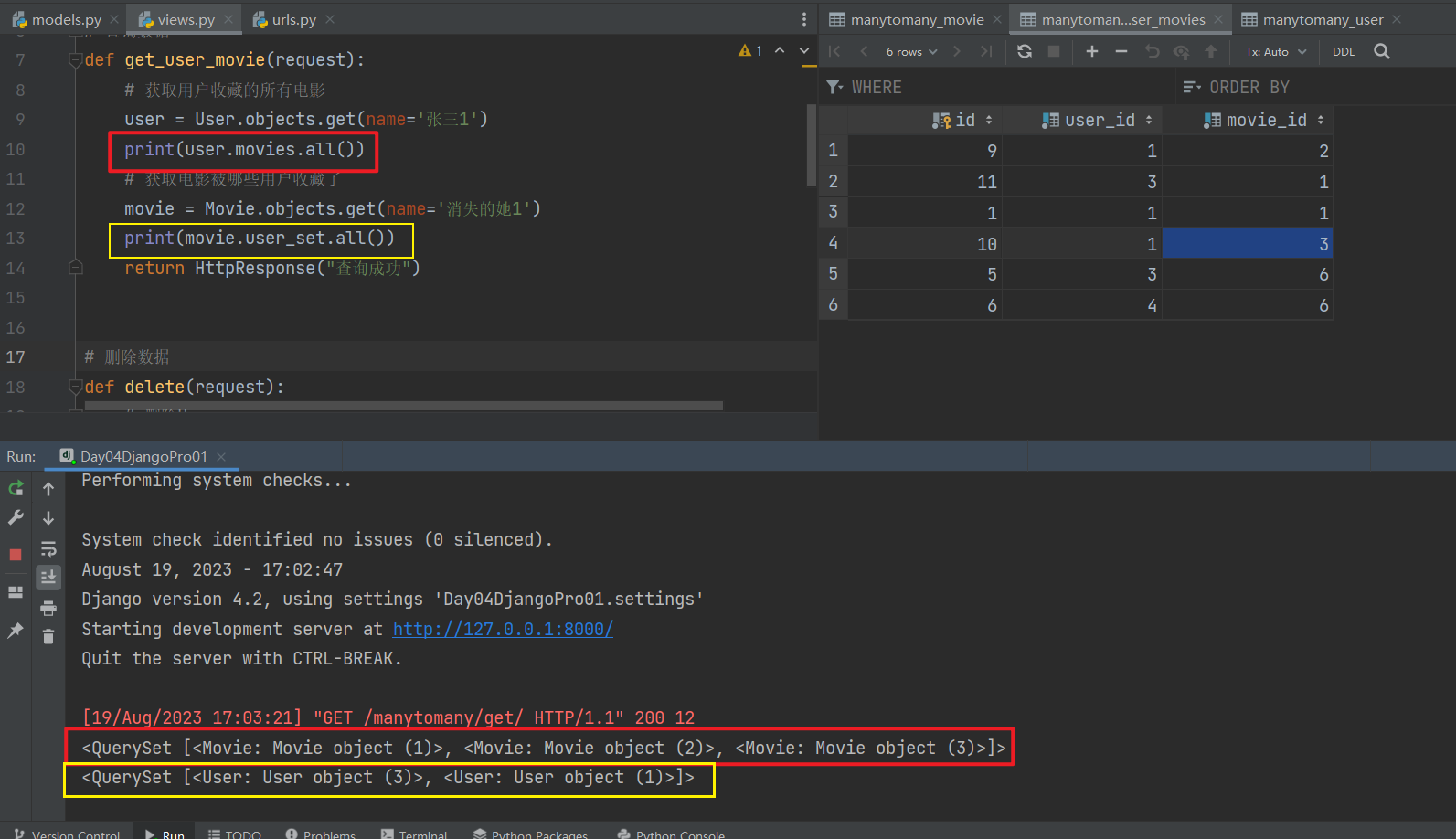
注意:我的数据表里的数据我另外又加回来了
电影:1 消失的她1
用户:1 张三1
4.3.3 一对一
一对一关系
一对一不是数据库的一个连表操作,而是Django独有的一个连表操作。一对一关系相当于是特殊的一对多关系,只是相当于加了unique=True。
一个人只能有一张身份证,一张身份证对应一个人,是一个典型的一对一关系。
class IdCard(models.Model):
idnum = models.IntegerField()
def __str__(self):
return str(self.idnum)
class Person(models.Model):
idcard = models.OneToOneField(IdCard) # 外键
name = models.CharField(max_length=20)
def __str__(self):
return self.name
一对一关系比较简单。两种表互相都有对方。比如:
>>> lisi = Person.objects.get(id=3)
>>> lisi.idcard
<IdCard: 123456>
>>> ids = IdCard.objects.get(id=3)
>>> ids.person
<Person: lisi>
实践
这里演示查询就可以了,其他的跟一对多差不多。
新建一个应用 叫 OneToOne
python manage.py startapp OneToOne
创建好之后一定要记得注册 Day04DjangoPro01\settings.py
OneToOne\models.py
from django.db import models
# 身份证
class IDCard(models.Model):
idcard_num = models.CharField(max_length=18, unique=True)
address = models.CharField(max_length=200)
# 用户表
class Person(models.Model):
name = models.CharField(max_length=20)
age = models.IntegerField(default=18)
sex = models.BooleanField(default=True) # True是男
# 一对一关系
idcard = models.OneToOneField(IDCard, on_delete=models.PROTECT) # 外键
生成迁移文件: python manage.py makemigrations
执行迁移: python manage.py migrate
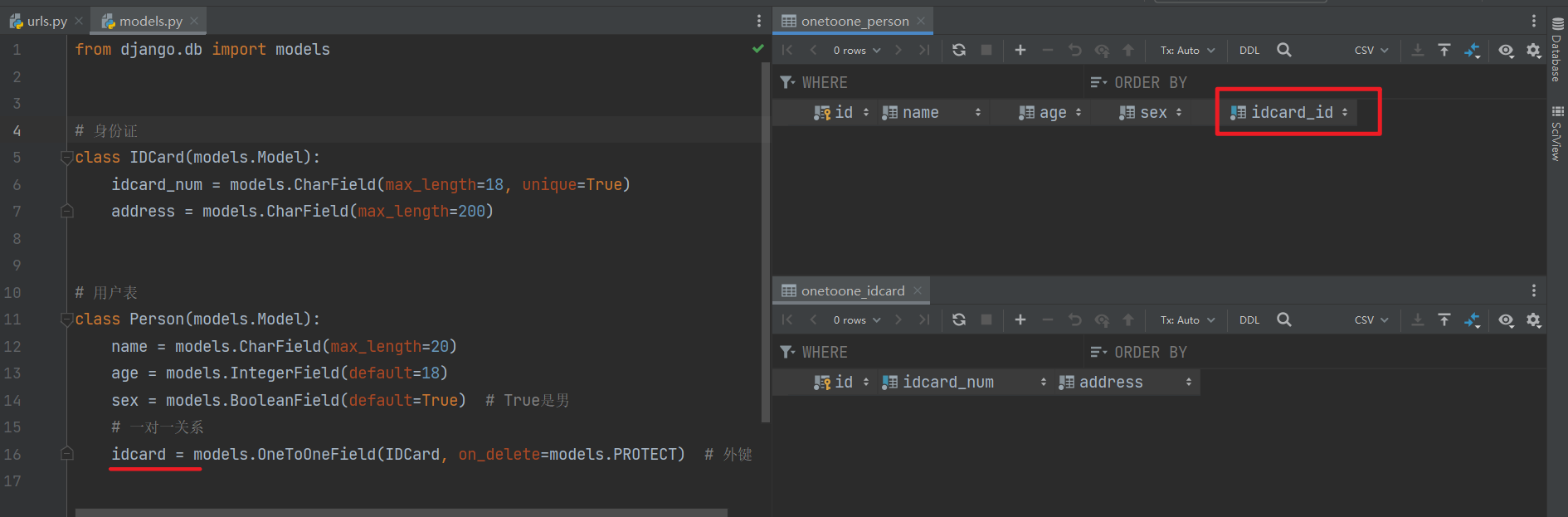
一对一 和 一对多 一样 ,只有两个表,不会产生中间表。
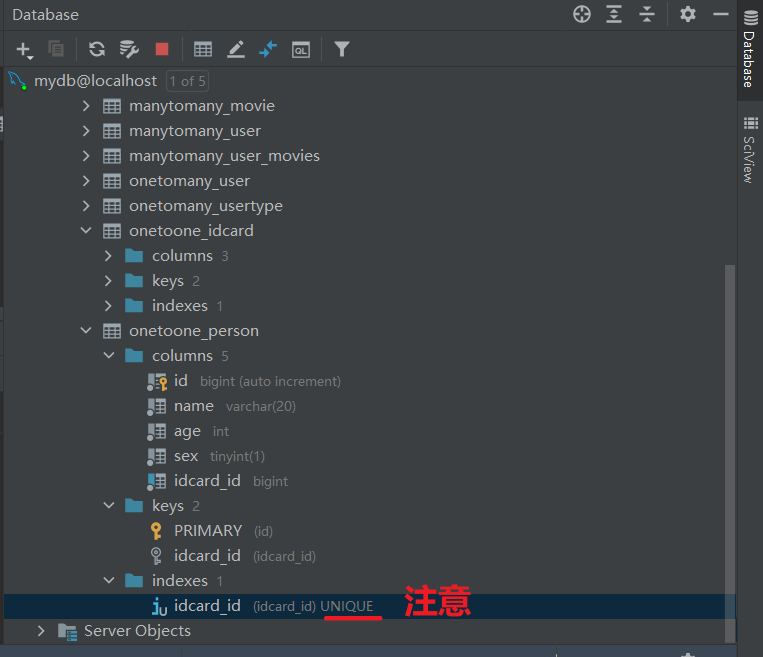
注意: Unique,唯一约束
数据库插入点数据
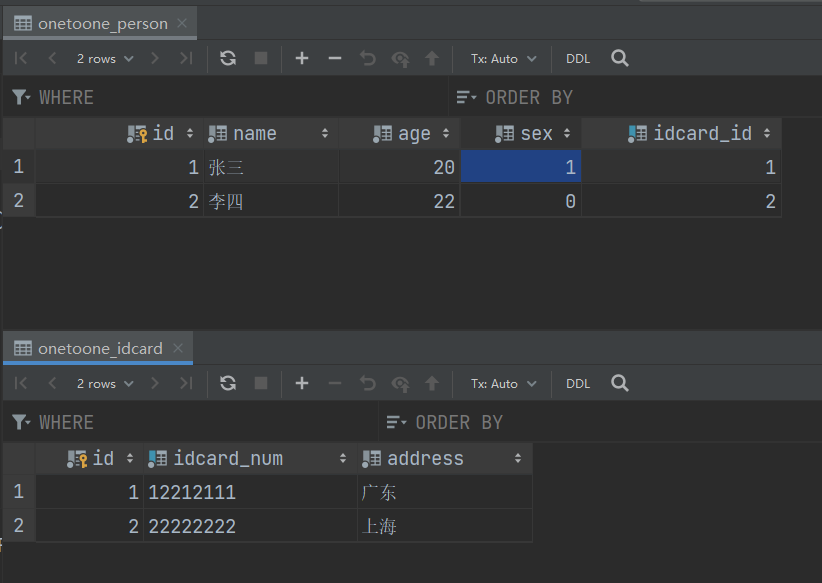
增删改
和一对多是类似的。
查询
和一对多是类似的,不同的是一对一得到的是 对方的对象 而不是 一个查询集。
Day04DjangoPro01\urls.py
OneToOne\views.py
from django.shortcuts import render, HttpResponse
from OneToOne.models import *
# 一对一
# 查询
def get(request):
# 查找某个用户对应的身份证信息
person = Person.objects.get(pk=1)
print(person.idcard) # 对象 IDCard object (1)
print(person.idcard.idcard_num, person.idcard.address)
# 查找身份证对应的用户
idcard = IDCard.objects.get(pk=2)
print(idcard.person) # 对象 Person object (2)
# 注意不是idcard.person_set
print(idcard.person.name, idcard.person.age, idcard.person.sex)
return HttpResponse("查询成功")
注意:不是idcard.person_set ,是 idcard.person
http://127.0.0.1:8000/onetoone/get/