目录
一、实现消息持久化
1.1、消息的存储设定
1.1.1、存储方式
1.1.2、存储格式约定
1.1.3、queue_data.txt 文件内容
1.1.4、queue_stat.txt 文件内容
1.2、实现 MessageFileManager 类
1.2.1、设计目录结构和文件格式
1.2.2、实现消息的写入
1.2.3、实现消息的删除(随机访问文件)
1.2.4、获取队列文件中所有有效消息
1.2.5、GC 机制
1.2.6、GC 拓展
二、统一硬盘操作
一、实现消息持久化
1.1、消息的存储设定
1.1.1、存储方式
传输的 Message 消息因该如何在硬盘上存储?我们应当考虑一下几点:
- 消息操作并不涉及到复杂的增删改查.
- 消息数量可能会非常多,数据库访问的效率不是很高.
因此这里不使用数据库进行存储,而是把消息存储在文件中~
1.1.2、存储格式约定
消息是依附于队列的,因此存储的时候,就把消息按照 队列 维度展开.
根据上一章我们讲到数据库的存储,因此我们已经有了 data 目录(meta.db 就在这个目录中),这里我们约定 —— 一个队列就是一个文件目录,每个对列的文件目录下有两个文件,来存储消息,例如下图:
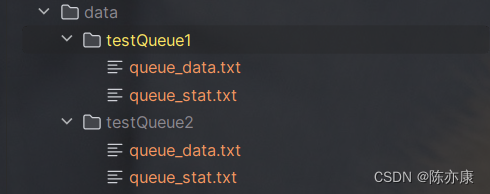
- 第一个文件 queue_data.txt:用来保存消息的内容;
- 第二个文件 queue_stat.txt:用来保存消息的统计信息;
1.1.3、queue_data.txt 文件内容
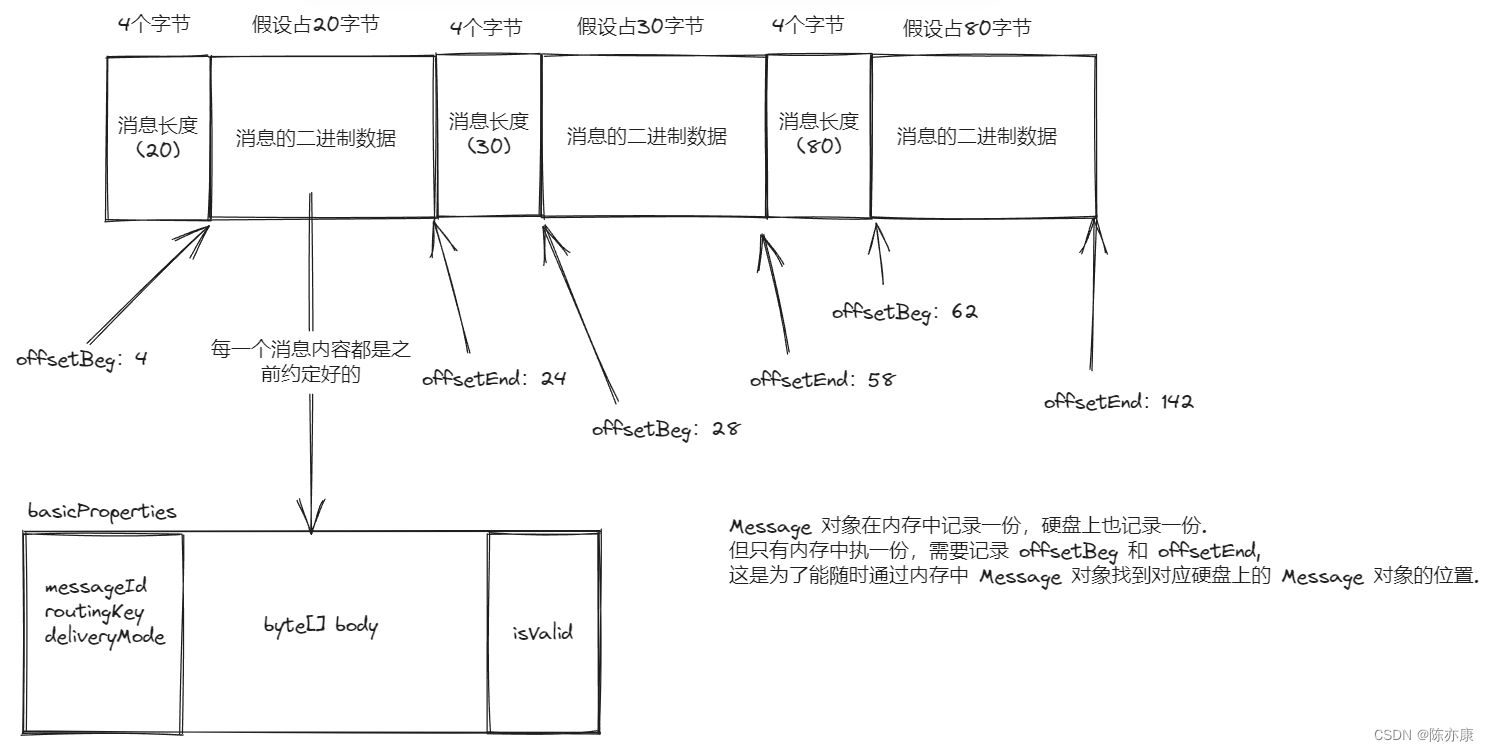
这里约定,queue_data.txt 文件中包含若干个消息,每个消息都以二进制的方式存储,每个消息由两个部分构成,
- 第一个部分约定占用 4 个字节,用来保存消息的长度(防止粘包问题).
- 第二个部分为具体的二进制消息数据(Message 对象序列化后的数据).
如下图:
1.1.4、queue_stat.txt 文件内容
使用这个文件,来保存消息的统计信息。
这里只存一行文本格式的数据,并且只有两列:
- 第一列是 queue_data.txt 中总的消息数目.
- 第二列是 queue_data.txt 中的有效消息数目.
这两者使用 \t 分割,形如:2000\t1500
1.2、实现 MessageFileManager 类
1.2.1、设计目录结构和文件格式
定义一个内部类,表示队列的统计信息(优先考虑 static,和外类解耦合).
static public class Stat {
//对于这样的简单类定义成 public 就不用 get set 方法了,类似于 C 的结构体
public int totalCount;
public int validCount;
}
通过以下方法获取队列对应消息文件的路径,以及队列 数据/统计 文件的路径.
/**
* 用来获取指定队列对应的消息文件所在路径
* @param queueName
* @return
*/
private String getQueueDir(String queueName) {
return "./data/" + queueName;
}
/**
* 用来获取该队列的消息数据文件路径
* 此处使用 txt 文件,存储二进制数据,实际上不太合适,但也先这样吧~
* 跟适合使用 .bin / .dat
* @param queueName
* @return
*/
private String getQueueDataPath(String queueName) {
return getQueueDir(queueName) + "/queue_data.txt";
}
/**
* 用来获取该队列的消息统计文件路径
* @param queueName
* @return
*/
private String getQueueStatPath(String queueName) {
return getQueueDir(queueName) + "/queue_stat.txt";
}
通过以下方法实现队列 统计 文件的读写(便于后续创建文件时对 统计文件 的初始化).
/**
* 从文件中读取队列消息统计信息
* @param queueName
* @return
*/
private Stat readStat(String queueName) {
Stat stat = new Stat();
try(InputStream inputStream = new FileInputStream(getQueueStatPath(queueName))) {
Scanner scanner = new Scanner(inputStream);
stat.totalCount = scanner.nextInt();
stat.validCount = scanner.nextInt();
return stat;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 将队列消息统计信息写入文件
* @param queueName
* @param stat
*/
private void writeStat(String queueName, Stat stat) {
try(OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName))) {
PrintWriter printWriter = new PrintWriter(outputStream);
printWriter.write(stat.totalCount + "\t" + stat.validCount);
printWriter.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
通过以下方法来创建和销毁文件和目录
/**
* 创建队列对应的文件和目录
* @param queueName
*/
public void createQueueFiles(String queueName) throws IOException {
//1.创建队列对应的消息目录
File baseDir = new File(getQueueDir(queueName));
if(!baseDir.exists()) {
//不存在,就创建这个目录
boolean ok = baseDir.mkdirs();
if (!ok) {
throw new IOException("创建目录失败!baseDir=" + baseDir.getAbsolutePath());
}
}
//2.创建队列数据文件
File queueDataFile = new File(getQueueDataPath(queueName));
if(!queueDataFile.exists()) {
boolean ok = queueDataFile.createNewFile();
if(!ok) {
throw new IOException("创建文件失败! queueDataFile=" + queueDataFile.getAbsolutePath());
}
}
//3.创建消息统计文件
File queueStatFile = new File(getQueueStatPath(queueName));
if(!queueStatFile.exists()) {
boolean ok = queueStatFile.createNewFile();
if(!ok) {
throw new IOException("创建文件失败! queueStatFile=" + queueStatFile.getAbsolutePath());
}
}
//4.给消息统计文件,设定初始值. 0\t0
Stat stat = new Stat();
stat.totalCount = 0;
stat.validCount = 0;
writeStat(queueName, stat);
}
/**
* 删除队列的目录和文件
* 此方法的用处:队列也是可以被删除的,队列删除之后,就需要调用此方法,删除对应的消息文件之类的
* @param queueName
* @throws IOException
*/
public void destroyQueueFiles(String queueName) throws IOException {
//先删除里面的文件,再删除目录
File queueDataFile = new File(getQueueDataPath(queueName));
boolean ok1 = queueDataFile.delete();
File queueStatFile = new File(getQueueStatPath(queueName));
boolean ok2 = queueStatFile.delete();
File baseDir = new File(getQueueDir(queueName));
boolean ok3 = baseDir.delete();
if(!ok1 || !ok2 || !ok3) {
//任意一个失败,都算整体删除失败
throw new IOException("删除队列目录和文件失败! baseDir=" + baseDir.getAbsolutePath());
}
}
1.2.2、实现消息的写入
消息写入主要分为以下四步:
- 先检查当前文件是否存在
- 把 Message 对象进行序列化,转化成 二进制 字节数组
- 根据当前队列文件长度,计算出 Message 对象的 offsetBeg 和 offsetEnd
- 将 message 数据追加到文件末尾
- 更新消息统计文件内容
/**
* 检查队列的目录和文件是否存在
* 如果后续有生产者 broker server 生产消息了,这个消息就需要被记录到文件上(持久化的前提是文件必须要存在)
* @param queueName
* @return
*/
public boolean checkFilesExits(String queueName) {
//数据文件和统计文件都判断存在
File queueDataFile = new File(getQueueDataPath(queueName));
if(!queueDataFile.exists()) {
return false;
}
File queueStatFile = new File(getQueueStatPath(queueName));
if(!queueStatFile.exists()) {
return false;
}
return true;
}
/**
* 将一个新的消息(message)放到队列文件中(queue)
* @param queue
* @param message
*/
public void sendMessage(MSGQueue queue, Message message) throws MqException, IOException {
//1.先检查当前文件是否存在
if(!checkFilesExits(queue.getName())) {
throw new MqException("[MessageFileManager] 队列对应的文件不存在! queueName=" + queue.getName());
}
//2.把 Message 对象进行序列化,转化成 二进制 字节数组
byte[] messageBinary = BinaryTool.toBytes(message);
//3.根据当前队列文件长度,计算出 Message 对象的 offsetBeg 和 offsetEnd
//将新的 Message 数据,写入到文件的末尾,那么此时 offsetBeg = 4 + 当前文件总长度 (4 个字节是我们约定好用来表示信息长度的)
// offsetEnd = 当前文件总长度 + 4 + message 长度
//这里为了避免写操作引发线程安全问题
synchronized(queue) {
File queueDataFile = new File(getQueueDataPath(queue.getName()));
message.setOffsetBeg(queueDataFile.length() + 4);
message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length);
//4.将 message 数据追加到文件末尾
try(OutputStream outputStream = new FileOutputStream(queueDataFile, true)) { //这里 true 表示追加到文件末尾
try(DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {
//这里用 writeInt 来写 message 长度是为了保证占 4 个字节(直接用 write 只会写一个字节)
dataOutputStream.writeInt(messageBinary.length);
//写入消息体
dataOutputStream.write(messageBinary);
dataOutputStream.flush();
}
}
//5.更新消息统计文件内容
Stat stat = readStat(queue.getName());
stat.validCount += 1;
stat.totalCount += 1;
writeStat(queue.getName(), stat);
}
}
1.2.3、实现消息的删除(随机访问文件)
这里的删除逻辑实际上就是把硬盘中存储的这个数据里面的 isValid 属性,设置成 0,然后再写入硬盘.
- 先把文件中这段数据读出来,还原回 Message 对象
- 把 isValid 改成 0
- 把上述数据重新写回到文件中
- 更新统计文件
为什么这里采用这样的删除方式?
新增消息可以直接把消息追加到文件末尾,而删除消息不好弄~ 因为文件可以视为是一个 “顺序表” 的结构,因此如果直接删除中间的元素,就需要设计到 “顺序表搬运” 这样的操作,效率是非常低的.
因此这里使用逻辑删除的方式比较合适~~
- 当 isValid 为 1,表示有效消息.
- 当 isValid 为 0 ,表示无效消息
随着时间的推移文件可能会越来越大,并且可能存在大量的无效消息,针对这种情况,就需要对当前消息数据文件进行垃圾回收机制(后续会讲到).
public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException {
//读写文件注意线程安全问题
synchronized(queue) {
try (RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()), "rw")) {
//1.先从文件中读出对应的 Message 数据
byte[] bufferSrc = new byte[(int) (message.getOffsetEnd() - message.getOffsetBeg())];
randomAccessFile.seek(message.getOffsetBeg());
randomAccessFile.read(bufferSrc); //类似于食堂打饭
//2.把当前读出来的二进制数据,反序列化成 Message 对象
Message diskMessage = (Message) BinaryTool.fromBytes(bufferSrc);
//3.把 isValid 设置成无效
diskMessage.setIsValid((byte) 0x0);
//此处不用把形参中的 message 的 isValid 设为 0,因为这个参数代表内存中管理的 Message 对象
//这个对象马上就会被从内存中删除
//4.重新写入文件
byte[] bufferDest = BinaryTool.toBytes(diskMessage);
//这里还需要将光标移动到最初这个消息的位置,因为 read 操作也会挪动光标
randomAccessFile.seek(message.getOffsetBeg());
randomAccessFile.write(bufferDest);
// 通过上述折腾,对于文件来说,只有一个字节发生改变了而已
}
//更新统计文件,消息无效了,消息个数就需要 -1
Stat stat = readStat(queue.getName());
if(stat.validCount > 0) {
stat.validCount -= 1;
}
writeStat(queue.getName(), stat);
}
}
Ps:此处这个参数中的 message 对象,必须得包含有效的 offsetBeg 和 offsetEnd
1.2.4、获取队列文件中所有有效消息
读取文件中有效的(isValid = 1)消息内容加载到内存中(此方法准备在程序启动的时候进行调用,因此也不需要加锁)
Ps:
queueName 这里只用这一个参数就够了,不需要 MSGQueue 对象
使用 LinkedList 主要是为了后续进行头删的操作
public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws IOException, MqException, ClassNotFoundException {
LinkedList<Message> messages = new LinkedList<>();
try (InputStream inputStream = new FileInputStream(getQueueDataPath(queueName))) {
try (DataInputStream dataInputStream = new DataInputStream(inputStream)) {
//记录当前光标位置
long currentOffset = 0;
while(true) {
//1.读取当前消息的长度
int messageSize = dataInputStream.readInt();
//2.按照长度获取消息内容
byte[] buffer = new byte[messageSize];
int actualSize = inputStream.read(buffer);
//比较理论和实际消息长度
if(messageSize != actualSize) {
//如果不匹配说明文件出问题了
throw new MqException("[MessageFileManager] 文件格式错误! queueName=" + queueName);
}
//3.把读到的二进制数据反序列化成 Message 对象
Message message = (Message) BinaryTool.fromBytes(buffer);
//4.判断这个消息是否是无效对象
if(message.getIsValid() != 0x1) {
//无效消息直接跳过
//虽然是无效数据,但是 offset 不要忘记更新
currentOffset += (4 + messageSize);
continue;
}
//5.有效数据就加入到链表中,加入前计算一下 offsetBeg 和 offsetEnd
//这个位置需要知道当前文件光标的位置,由于当下使用的 DataInputStream 不方便直接获取文件光标位置, 因此需要使用 currentOffset 手动记录一下
message.setOffsetBeg(currentOffset + 4);
message.setOffsetEnd(currentOffset + 4 + messageSize);
currentOffset += (4 + messageSize);
//6.最后加入到链表当中
messages.add(message);
}
} catch (EOFException e) {
//这个 catch 并非真的用来处理 ”异常“ ,而是 ”正常“ 业务逻辑,这是为了当消息读完了能得到一个反馈(有点顺水推舟的感觉)
//因为,当消息读取到文件末尾,readInt 就会引发异常(EOF异常)
System.out.println("[MessageFileManager] 恢复 Message 数据完成");
}
}
return messages;
}
1.2.5、GC 机制
这里我们使用 复制算法 对消息数据文件中的垃圾进行回收.
具体的,我们直接遍历原有的消息数据文件,把所有的有效数据拷贝到一个新的文件中,再把之前整个旧的文件都删除,然后将新文件的名字改为旧文件的名字.
什么时候触发一次 GC ?
复制算法比较合适的前提是,当前空间里,有效的数据不多,大部分是无效的数据(减少搬运数据的开销)
因此这里我们约定:当总的消息数目超过 2000 ,并且有效消息的数目低于总消息数目的 50%,就触发一次 GC (避免 GC 太频繁,比如一共 4 个消息,其中 2 个消息无效了,就触发 GC).
Ps:这里的两个数字都是自定义的,关注一定是 策略、思想、方法 ,而不是具体的数字.
/**
* 检查是否要针对队列的消息数据文件进行 GC
* @param queueName
* @return
*/
public boolean checkGC(String queueName) {
Stat stat = readStat(queueName);
if(stat.totalCount > 2000 && (double)stat.validCount / (double)stat.totalCount < 0.5) {
return true;
}
return false;
}
/**
* 获取新文件
* @param queueName
* @return
*/
public String getQueueDataNewPath(String queueName) {
return getQueueDir(queueName) + "/queue_data_new.txt";
}
/**
* 执行真正的 gc 操作
* 使用复制算法完成
* 创建一个新的文件,名字叫做 queue_data_new.txt
* 把之前消息数据文件中的有效消息都读出来,写道新的文件中
* 删除旧的文件,再把新的文件改名回 queue_data.txt
* 同时要记得更新消息统计文件
* @param queue
*/
public void gc(MSGQueue queue) throws MqException, IOException, ClassNotFoundException {
//gc 意味着 "大洗牌" ,这个过程中其他线程不得干预
synchronized(queue) {
//由于 gc 操作可能回比较耗时,此处统计一下执行耗时的时间
long gcBeg = System.currentTimeMillis();
//1.创建一个新文件
File queueDataNewFile = new File(getQueueDataNewPath(queue.getName()));
if(queueDataNewFile.exists()) {
//正常情况下,这个文件是不存在的,如果存在就是以外,说明上次 gc 了一半,中途发生了以外
throw new MqException("[MessageFileManager] gc 时发现该队列的 queue_data_new 已经存在! " +
"queueName=" + queue.getName());
}
boolean ok = queueDataNewFile.createNewFile();
if(!ok) {
throw new MqException("[MessageFileManager] 创建文件失败! queueDataNewFile=" +
queueDataNewFile.getName());
}
//2.从旧文件中读出所有的有效消息
LinkedList<Message> messages = loadAllMessageFromQueue(queue.getName());
//3.把有效消息写入新的文件
try(OutputStream outputStream = new FileOutputStream(queueDataNewFile)) {
try(DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {
for(Message message : messages) {
byte[] buffer = BinaryTool.toBytes(message);
//先写消息长度
dataOutputStream.writeInt(buffer.length);
//再写消息内容
dataOutputStream.write(buffer);
}
}
}
//4.删除旧文件
File queueDataOldFile = new File(getQueueDataPath(queue.getName()));
ok = queueDataOldFile.delete();
if(!ok) {
throw new MqException("[MessageFileManager] 删除旧的文件失败! queueDataOldFile=" + queueDataOldFile.getName());
}
//把 queue_data_new.txt 重命名成 queue_data.txt
ok = queueDataNewFile.renameTo(queueDataOldFile);
if(!ok) {
throw new MqException("[MessageFileManager] 文件重命名失败! queueDataNewFile=" + queueDataNewFile.getAbsolutePath() +
", queueDataOldFile=" + queueDataOldFile.getAbsolutePath());
}
//5.跟新统计文件
Stat stat = readStat(queue.getName());
stat.totalCount = messages.size();
stat.validCount = messages.size();
writeStat(queue.getName(), stat);
long gcEnd = System.currentTimeMillis();
System.out.println("[MessageFileManager] gc 执行完毕!queueName=" +
queue.getName() + "time=" + (gcEnd + gcBeg) + "ms");
}
}
1.2.6、GC 拓展
当某个队列中,消息特别多,并且很多都是有效的消息,就会导致后续对这个文件操作的成本上升很多,例如文件大小是 10G,此时如果触发一次 GC ,整体的耗时就会非常高了.
对于 RabbitMQ 来说,解决方案就是把一个大的文件拆分成若干个小文件.
- 文件拆分:当单个文件长度到达一定阈值以后,就会拆分成两个文件.(拆着拆着,就成了很多文件).
- 文件合并:每个单独的文件都会进行 GC ,如果 GC 之后发现文件变小了很多,就可能会和其他相邻的文件合并.
具体实现思路:
- 需要专门的数据结构,来存储当前队列中有多少个数据文件,每个文件大小是多少,消息数目是多少,无效消息是多少.
- 设计策略,什么时候触发消息拆分,什么时候触发文件合并.
Ps:这里可以先不给出具体实现,需要的可以私信我(前提是备注微信号).
二、统一硬盘操作
使用这个类来管理所有硬盘上的数据
- 数据库:交换机、绑定、队列
- 数据文件:消息
上层逻辑需要操作硬盘,统一通过这个类来操作(上层代码不关心当前数据是存储再数据库还是文件中的),提高了代码的内聚,可维护性.
public class DiskDataCenter {
//这个实例用来管理数据库中的数据
private DataBaseManager dataBaseManager = new DataBaseManager();
//这个实例用来管理数据文件中的数据
private MessageFileManager messageFileManager = new MessageFileManager();
/**
* 针对上面两个实例进行初始化
*/
public void init() {
dataBaseManager.init();
// messageFileManager 中 init 是一个空方法,只是先列在这里,一旦后续需要扩展,就在这里进行初始化即可
messageFileManager.init();
}
//封装交换机操作
public void insertExchange(Exchange exchange) {
dataBaseManager.insertExchange(exchange);
}
public void deleteExchange(String exchangeName) {
dataBaseManager.deleteExchange(exchangeName);
}
public List<Exchange> selectAllExchanges() {
return dataBaseManager.selectAllExchanges();
}
//封装队列操作
public void insertQueue(MSGQueue queue) throws IOException {
dataBaseManager.insertQueue(queue);
//创建队列的同时,不仅需要把队列写入到数据库中,还需要创建出对应的目录和文件
messageFileManager.createQueueFiles(queue.getName());
}
public void deleteQueue(String queueName) throws IOException {
dataBaseManager.deleteQueue(queueName);
//删除队列的同时,不仅需要把队列从数据库中删除,还需要把对应的文件和目录删除
messageFileManager.destroyQueueFiles(queueName);
}
public List<MSGQueue> selectAllQueue() {
return dataBaseManager.selectAllQueues();
}
//封装绑定操作
public void insertBinding(Binding binding) {
dataBaseManager.insertBinding(binding);
}
public void deleteBinding(Binding binding) {
dataBaseManager.deleteBinding(binding);
}
public List<Binding> selectAllBindings() {
return dataBaseManager.selectAllBindings();
}
//封装消息操作
public void sendMessage(MSGQueue queue, Message message) throws IOException, MqException {
messageFileManager.sendMessage(queue, message);
}
public void deleteMessage(MSGQueue queue, Message message) throws IOException, ClassNotFoundException, MqException {
messageFileManager.deleteMessage(queue, message);
//这里删除消息以后还需要看以下文件中是否有太多的无效文件需要进行清除
if(messageFileManager.checkGC(queue.getName())) {
messageFileManager.gc(queue);
}
}
public List<Message> selectAllMessagesFromQueue(String queueName) throws IOException, MqException, ClassNotFoundException {
return messageFileManager.loadAllMessageFromQueue(queueName);
}
}
Ps:这里对队列和消息的封装都是具有一定的逻辑的!
队列:
- 创建队列的同时,不仅需要把队列写入到数据库中,还需要创建出对应的目录和文件
- 删除队列的同时,不仅需要把队列从数据库中删除,还需要把对应的文件和目录删除
消息:
- 删除消息以后还需要看以下文件中是否有太多的无效文件需要进行清除(GC)