目录
java类和接口总览
队列(Queue)
1. 概念
2. 队列的使用
以下是一些常用的队列操作:
1.入队操作
2.出队操作
3.判断队列是否为空
4.获取队列大小
5.其它
优先级队列(堆)
1. 优先级队列概念
Java中的PriorityQueue具有以下特点
2.常用的PriorityQueue操作
1.PriorityQueue的创建
2.插入元素
3.删除具有最高优先级的元素
4.查找具有最高优先级的元素
5.其它
3. 优先级队列的模拟实现
堆
1.堆的概念
2.堆的性质
3.堆的存储方式
4.堆的创建
1.如何把给定的一棵二叉树,变成最小堆或者最大堆
以变成最大堆为例
2.时间复杂度分析
建堆的时间复杂度
5.堆的删除
6.用堆模拟实现优先级队列
7.常用接口介绍
1.关于PriorityQueue的使用注意事项
1. 优先级队列的构造
2. 插入/删除/获取优先级最高的元素
完结撒花✿✿ヽ(°▽°)ノ✿
java类和接口总览

队列(Queue)
1. 概念
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First
In First Out) 入队列:进行插入操作的一端称为队尾(Tail/Rear) 出队列:进行删除操作的一端称为队头(Head/Front)

2. 队列的使用
在Java中,Queue是个接口,底层是通过链表实现的

Java中提供了多种队列(Queue)的实现,如LinkedList、ArrayDeque、PriorityQueue等,可以根据不同的需求选择适合的实现类。
以下是一些常用的队列操作:
1.入队操作
入队操作:使用add()或offer()方法将元素添加到队列的末尾。add()方法如果添加失败会抛出异常,而offer()方法则会返回一个boolean值表示添加是否成功。
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
queue.offer(2);2.出队操作
出队操作:使用poll()或remove()方法从队列的头部获取并移除元素。poll()方法如果队列为空则会返回null,而remove()方法则会抛出异常。
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
queue.add(2);
int item = queue.poll(); // item的值为1
int item2 = queue.remove(); // item2的值为23.判断队列是否为空
判断队列是否为空:使用isEmpty()方法判断队列是否为空。
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
boolean isEmpty = queue.isEmpty(); // isEmpty的值为false4.获取队列大小
获取队列大小:使用size()方法获取队列的大小。
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
queue.add(2);
int size = queue.size(); // size的值为25.其它
除了以上常用的操作外,Java的Queue接口还提供了其他一些方法,如element()方法用于获取队列的头元素但不移除,peek()方法用于获取队列头元素但不移除且判断队列是否为空等。可以根据具体需求选择适合的方法使用。

优先级队列(堆)
1. 优先级队列概念
前面介绍过队列,队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,比如:在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话;初中那会班主任排座位时可能会让成绩好的同学先挑座位。
在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。堆实现了Queue这个接口,可以把它当做优先级队列
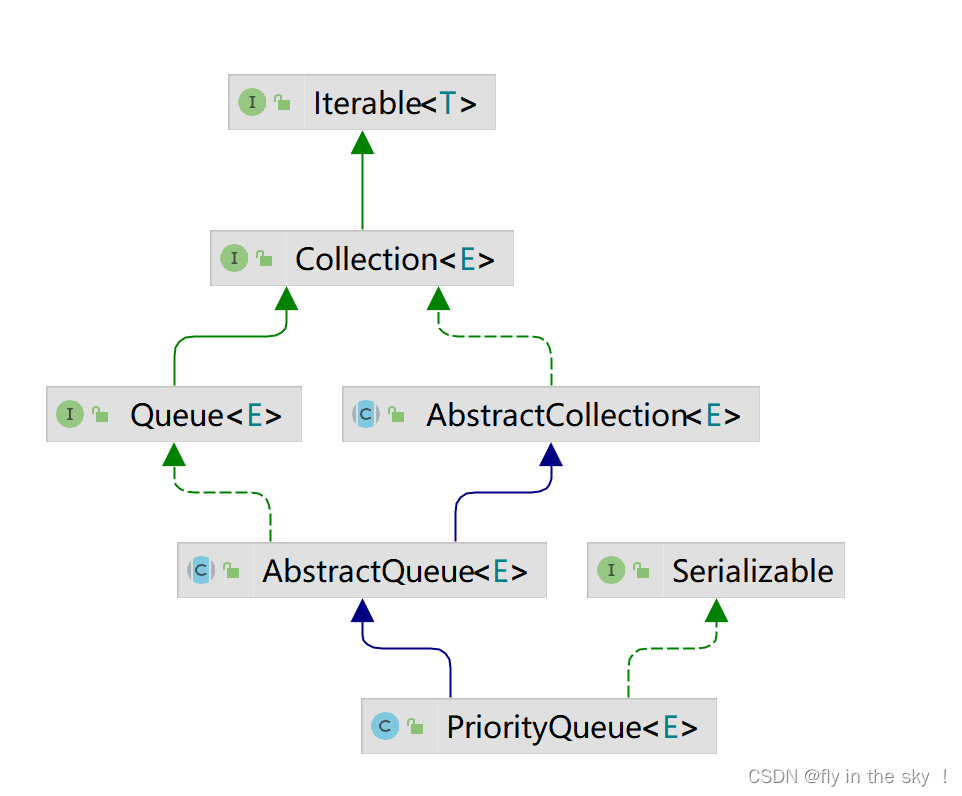

Java中的优先级队列(PriorityQueue)是一种特殊的队列,它使用二叉堆实现。在优先级队列中,每个元素都有一个优先级,优先级越高的元素在队列中的位置越靠前。
Java中的PriorityQueue具有以下特点
插入操作:向PriorityQueue中插入元素时,会根据元素的优先级确定其位置。如果新插入的元素的优先级高于当前队列中的最高优先级元素,则新元素将成为队列中的最高优先级元素。
删除操作:从PriorityQueue中删除元素时,会删除具有最高优先级的元素。如果队列中有多个具有相同最高优先级的元素,则会按照它们在队列中的顺序删除。
可查找操作:PriorityQueue支持查找操作,可以查找具有最高优先级的元素,或者查找具有指定优先级的元素。
2.常用的PriorityQueue操作
以下是一些常用的PriorityQueue操作
1.PriorityQueue的创建
在Java中,PriorityQueue可以使用以下代码创建:
PriorityQueue<Integer> pq = new PriorityQueue<>();2.插入元素
可以使用add()方法向PriorityQueue中插入元素,例如:
pq.add(3);
pq.add(1);
pq.add(2);3.删除具有最高优先级的元素
可以使用poll()方法从PriorityQueue中删除具有最高优先级的元素,例如:
int max = pq.poll(); // max = 34.查找具有最高优先级的元素
可以使用peek()方法查找具有最高优先级的元素,例如:
java
int max = pq.peek(); // max = 35.其它
除了默认的PriorityQueue外,Java还提供了一些其他类型的PriorityQueue,例如ArrayDeque、LinkedBlockingDeque等。这些PriorityQueue的实现方式略有不同,可以根据实际需求选择适合的类型。

3. 优先级队列的模拟实现
JDK1.8中的PriorityQueue底层使用了堆这种数据结构,而堆实际就是在完全二叉树的基础上进行了一些调整,本质上堆是一棵顺序存储的二叉树
Java中的优先级队列(PriorityQueue)是使用二叉堆实现的一种数据结构。二叉堆是一种特殊的树形数据结构,其中每个节点都满足堆的性质:根节点的值小于或等于其子节点的值(最大堆)或根节点的值大于或等于其子节点的值(最小堆)。
虽然Java中的PriorityQueue是使用二叉堆实现的,但我们可以使用其他数据结构来模拟实现优先级队列。
下面是一种使用数组实现优先级队列的示例代码:
public class PriorityQueue<T extends Comparable<T>> {
private int[] heap;
private int size;
public PriorityQueue(int capacity) {
heap = new int[capacity + 1];
}
public void enqueue(T value) {
if (size == heap.length - 1) {
resize();
}
int index = size;
heap[index] = value.compareTo(((T) heap[index - 1])) > 0 ? value : heap[index - 1];
upHeap(index);
size++;
}
public T dequeue() {
if (size == 0) {
throw new IllegalStateException("Priority queue is empty");
}
T max = (T) heap[0];
heap[0] = heap[size - 1];
size--;
downHeap(0);
return max;
}
private void resize() {
int[] newHeap = new int[heap.length * 2];
System.arraycopy(heap, 0, newHeap, 0, heap.length);
heap = newHeap;
}
private void upHeap(int index) {
while (index > 0) {
int parentIndex = (index - 1) / 2;
if (heap[parentIndex].compareTo((T) heap[index]) <= 0) {
break;
}
swap(parentIndex, index);
index = parentIndex;
}
}
private void downHeap(int index) {
int size = heap.length - 1;
while (true) {
int leftChildIndex = 2 * index + 1;
int rightChildIndex = 2 * index + 2;
int largestIndex = index;
if (leftChildIndex < size && heap[leftChildIndex].compareTo((T) heap[largestIndex]) > 0) {
largestIndex = leftChildIndex;
}
if (rightChildIndex < size && heap[rightChildIndex].compareTo((T) heap[largestIndex]) > 0) {
largestIndex = rightChildIndex;
}
if (largestIndex == index) {
break;
}
swap(index, largestIndex);
index = largestIndex;
}
}
private void swap(int i, int j) {
Object temp = heap[i];
heap[i] = heap[j];
heap[j] = temp;
}
}注:该代码定义了一个泛型的PriorityQueue类,支持向队列中插入元素(enqueue)和从队列中删除元素(dequeue)的操作。PriorityQueue使用一个数组来模拟二叉堆,通过调整数组元素的位置来维护堆的性质。在插入元素时,使用upHeap方法调整数组元素的位置,以维护最大堆的性质;在删除元素时,使用downHeap方法调整数组元素的位置,以维护最大堆的性质。在需要获取队列中的最大元素时,始终返回数组的第一个元素即可。
堆
1.堆的概念
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一
个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为 小堆(或大
堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
2.堆的性质
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
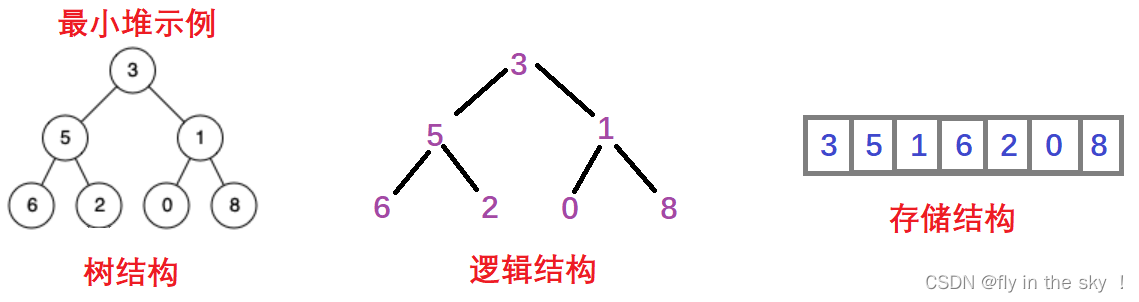

3.堆的存储方式
从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储,

注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
将元素存储到数组中后,可以对树进行还原。
- 假设i为节点在数组中的下标,则有:
- 如果i为0,则i表示的节点为根节点,否则i节点的双亲节点为 (i - 1)/2
- 如果2 * i + 1 小于节点个数,则节点i的左孩子下标为2 * i + 1,否则没有左孩子
- 如果2 * i + 2 小于节点个数,则节点i的右孩子下标为2 * i + 2,否则没有右孩子
4.堆的创建
问题:对于集合{ 0,1,2,3,5,68 }中的数据,如果将其创建成最大堆呢?
1.如何把给定的一棵二叉树,变成最小堆或者最大堆
以变成最大堆为例
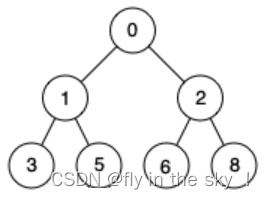
从这棵树的最后一棵子树开始调整,从右往左,从上往下
仔细观察上图后发现:根节点的左右子树已经完全满足堆的性质,因此只需将根节点向下调整好即可。
向下过程(以最大堆为例):
1. 让parent标记需要调整的节点,child标记parent的左孩子(注意:parent如果有孩子一定先是有左孩子)
2. 如果parent的左孩子存在,即:child > size, 进行以下操作,直到parent的左孩子不存在
parent右孩子是否存在,存在找到左右孩子中较大的孩子,让child进行标计,
将parent与较大的孩子child比较,如果:parent大于较大的孩子child,调整结束
否则:交换parent与较大的孩子child,交换完成之后,parent中大的元素向下移动,可能导致子树不满足最大堆的性质,因此需要继续向下调整,即parent = child;child = parent*2+1; 然后继续。

public class MaxHeapify {
private int[] heap; // 存储二叉树节点的数组
private int size; // 二叉树的大小
public MaxHeapify(int n) {
heap = new int[n + 1]; // 创建一个大小为 n+1 的数组,因为数组下标从0开始
size = 0; // 二叉树的大小初始为0
}
public void add(int val) {
heap[++size] = val; // 将新节点插入到数组的末尾
int i = size; // 当前节点下标
while (i > 1 && heap[i / 2] < heap[i]) { // 如果当前节点不是根节点且当前节点的值大于根节点的值
swap(i, i / 2); // 则交换当前节点和根节点
i /= 2; // 重新获取当前节点下标
}
}
public int get(int i) {
return heap[i]; // 返回指定下标的节点的值
}
public void maxHeapify(int i) { // i表示当前节点的下标
int left = 2 * i + 1; // 左子节点的下标
int right = 2 * i + 2; // 右子节点的下标
int largest = i; // 记录最大的节点下标
if (left < size && heap[left] > heap[largest]) { // 如果左子节点存在且值大于当前最大值
largest = left; // 更新最大值下标为左子节点下标
}
if (right < size && heap[right] > heap[largest]) { // 如果右子节点存在且值大于当前最大值
largest = right; // 更新最大值下标为右子节点下标
}
if (largest != i) { // 如果当前节点不是最大值节点
swap(i, largest); // 则交换当前节点和最大值节点
maxHeapify(largest); // 对新的当前节点进行最大堆调整
}
}
private void swap(int i, int j) { // i和j分别表示两个节点的下标
int temp = heap[i]; // 保存第一个节点的值
heap[i] = heap[j]; // 将第二个节点的值赋给第一个节点
heap[j] = temp; // 将第一个节点的值赋给第二个节点
}
}
/*注释:
private int[] heap; 和 private int size; 分别表示存储二叉树节点的数组和二叉树的大小。
public MaxHeapify(int n) 是构造函数,创建一个大小为 n+1 的数组,因为数组下标从0开始。
public void add(int val) 方法将新节点插入到数组的末尾,然后通过交换节点和其父节点来调整二叉树,使其满足最大堆的性质。
public int get(int i) 方法返回指定下标的节点的值。
public void maxHeapify(int i) 方法用于调整以 i 为根节点的子树为最大堆。首先找到左右子节点中最大的节点,然后与当前节点进行交换,并对新的当前节点进行最大堆调整。这个方法使用了递归的方式,直到每个子树都是最大堆为止。
private void swap(int i, int j) 方法用于交换两个节点的值。*/ public void shiftDown(int[] array, int parent) {
// child先标记parent的左孩子,因为parent可能右左没有右
int child = 2 * parent + 1;
int size = array.length;
while (child < size) {
// 如果右孩子存在,找到左右孩子中较小的孩子,用child进行标记
if (child + 1 < size && array[child + 1] < array[child]) {
{
child += 1;
}
}
// 如果双亲比其最小的孩子还小,说明该结构已经满足堆的特性了
if (array[parent] <= array[child]) {
break;
} else {
// 将双亲与较小的孩子交换
int t = array[parent];
array[parent] = array[child];
array[child] = t;
// parent中大的元素往下移动,可能会造成子树不满足堆的性质,因此需要继续向下调整
parent = child;
child = parent * 2 + 1;
}
}
}注意:在调整以parent为根的二叉树时,必须要满足parent的左子树和右子树已经是堆了才可以向下调整。
2.时间复杂度分析
时间复杂度分析:最坏的情况即图示的情况,从根一路比较到叶子,比较的次数为完全二叉树的高度,即时间复杂度为O(log2n)
建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是
近似值,多几个节点不影响最终结果):

因此:建堆的时间复杂度为O(N)。
堆的插入与删除
2.4.1 堆的插入
堆的插入总共需要两个步骤:
1. 先将元素放入到底层空间中(注意:空间不够时需要扩容)
2. 将最后新插入的节点向上调整,直到满足堆的性质
public void shiftUp(int child) {
// 找到child的双亲
int parent = (child - 1) / 2;
while (child > 0) {
// 如果双亲比孩子大,parent满足堆的性质,调整结束
if (array[parent] > array[child]) {
break;
} else {
// 将双亲与孩子节点进行交换
int t = array[parent];
array[parent] = array[child];
array[child] = t;
// 小的元素向下移动,可能到值子树不满足对的性质,因此需要继续向上调增
child = parent;
parent = (child - 1) / 1;
}
}
}5.堆的删除
注意:堆的删除一定删除的是堆顶元素。具体如下:
1. 将堆顶元素对堆中最后一个元素交换
2. 将堆中有效数据个数减少一个
3. 对堆顶元素进行向下调整

6.用堆模拟实现优先级队列
public class MyPriorityQueue {
// 演示作用,不再考虑扩容部分的代码
private int[] array = new int[100];
private int size = 0;
public void offer(int e) {
array[size++] = e;
shiftUp(size - 1);
}
public int poll() {
int oldValue = array[0];
array[0] = array[--size];
shiftDown(0);
return oldValue;
}
public int peek() {
return array[0];
}
}7.常用接口介绍
PriorityQueue的特性:Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,主要介绍的是PriorityQueue。
1.关于PriorityQueue的使用注意事项
关于PriorityQueue的使用要注意:
1. 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
2. PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出
ClassCastException异常
3. 不能插入null对象,否则会抛出NullPointerException
4. 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
5. 插入和删除元素的时间复杂度为
6. PriorityQueue底层使用了堆数据结构
7. PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
3.2 PriorityQueue常用接口介绍
1. 优先级队列的构造
PriorityQueue中常见的几种构造方式

public static void TestPriorityQueue() {
// 创建一个空的优先级队列,底层默认容量是11
PriorityQueue<Integer> q1 = new PriorityQueue<>();
// 创建一个空的优先级队列,底层的容量为initialCapacity
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
// 用ArrayList对象来构造一个优先级队列的对象
// q3中已经包含了三个元素
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
System.out.println(q3.size());
System.out.println(q3.peek());
}注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());
p.offer(4);
p.offer(3);
p.offer(2);
p.offer(1);
p.offer(5);
System.out.println(p.peek());
}
}此时创建出来的就是一个大堆。
2. 插入/删除/获取优先级最高的元素
| 函数名 | 功能介绍 |
| boolean offer(E e) | 插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时间复杂度O(log2N),注意:空间不够时候会进行扩容 |
| E peek() | 获取优先级最高的元素,如果优先级队列为空,返回null |
| E poll() | 移除优先级最高的元素并返回,如果优先级队列为空,返回null |
| int size() | 获取有效元素的个 |
| void clear() | 清空 |
| boolean isEmpty() | 检测优先级队列是否为空,空返回true |
public static void TestPriorityQueue2() {
int[] arr = {4, 1, 9, 2, 8, 0, 7, 3, 6, 5};
// 一般在创建优先级队列对象时,如果知道元素个数,建议就直接将底层容量给好
// 否则在插入时需要不多的扩容
// 扩容机制:开辟更大的空间,拷贝元素,这样效率会比较低
PriorityQueue<Integer> q = new PriorityQueue<>(arr.length);
for (int e : arr) {
q.offer(e);
}
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
// 从优先级队列中删除两个元素之和,再次获取优先级最高的元素
q.poll();
q.poll();
System.out.println(q.size()); // 打印优先级队列中有效元素个数
System.out.println(q.peek()); // 获取优先级最高的元素
q.offer(0);
System.out.println(q.peek()); // 获取优先级最高的元素
// 将优先级队列中的有效元素删除掉,检测其是否为空
q.clear();
if (q.isEmpty()) {
System.out.println("优先级队列已经为空!!!");
} else {
System.out.println("优先级队列不为空");
}
}注意:以下是JDK 1.8中,PriorityQueue的扩容方式:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}优先级队列的扩容说明:
如果容量小于64时,是按照oldCapacity的2倍方式扩容的
如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
完结撒花✿✿ヽ(°▽°)ノ✿