目录
一、执行计划的生成
二、执行计划的分发
三、执行计划的执行
一、执行计划的生成
在Doris的FE端,与大多数数据库系统一样,要从SQL或某种http请求,生成执行计划,从SQL生成,一开始是“抽象语法树”(Abstract Syntax Tree),这个抽象语法树不一定是规则的二叉树,而只是一些语法对象,通过类的成员变量联系起来,例如:
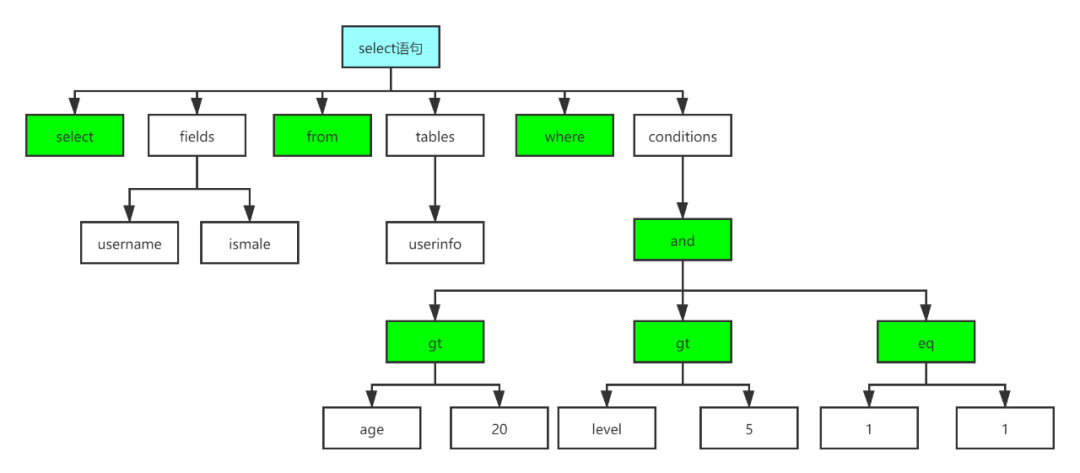
然后经过分析,重写步骤(有些数据库称为bind,语义分析等等),将AST改造成逻辑语法树,这个逻辑语法树,就是以关系运算符为主干的二叉树了,或者近似于这样一个二叉树了。

这个称为逻辑计划,生成逻辑计划以后,就可以进行各种优化了。在java代码中,逻辑计划的节点都是PlanNode的子类的对象,AST的节点都有个analyze(),analyze()被层层调用,生成逻辑计划树。
数据是分布式的分散到BE的,执行计划也是在BE节点上执行,而不是在FE节点上执行,FE只负责生成执行计划,并决定把执行计划发给谁。
接下来就是生成物理执行计划,并且把执行计划分布式化。

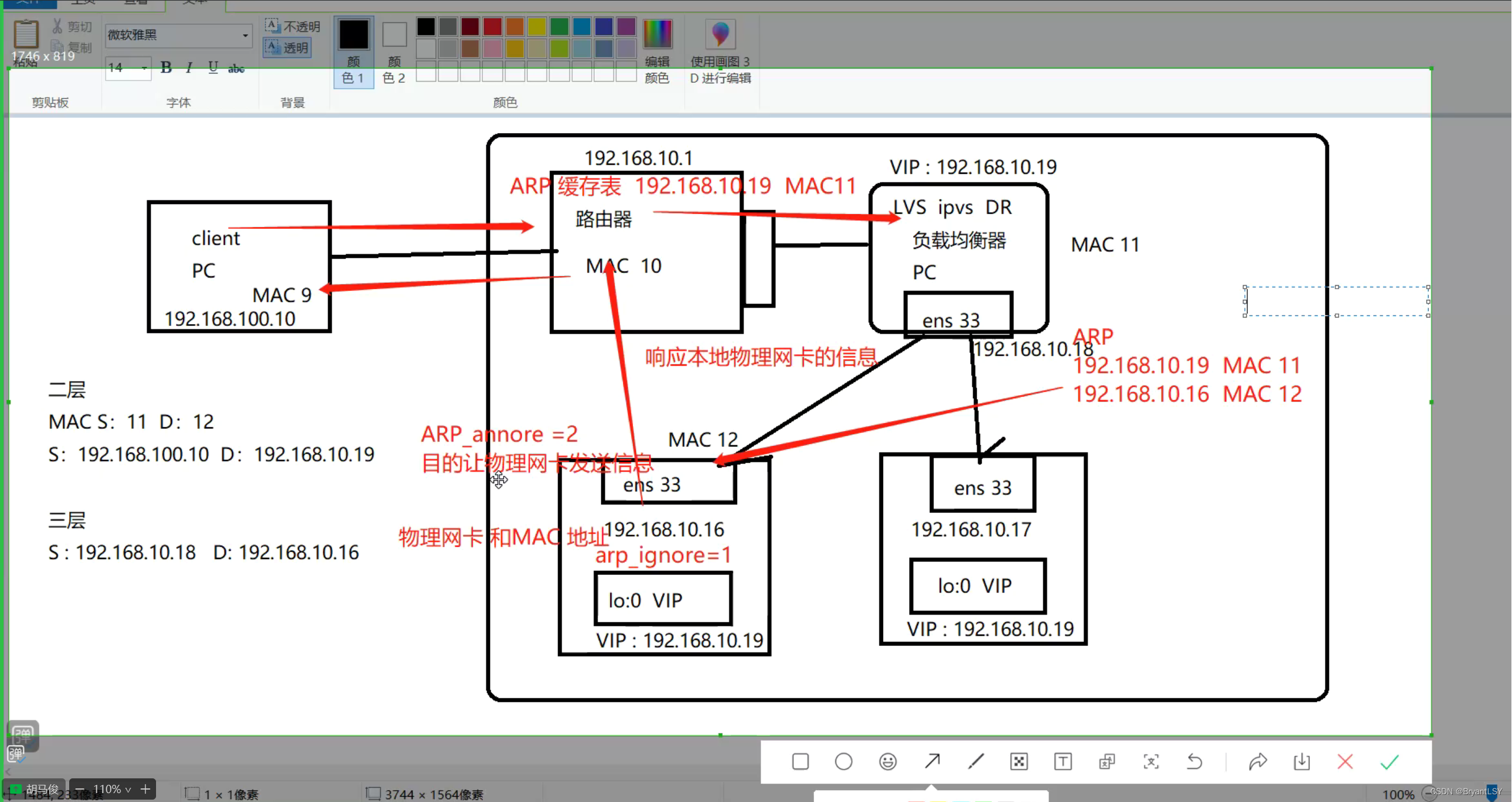
就是把PlanNode组成的执行计划树,分割成不同部分,这些不同部分称为fragment,代码中用PlanFragment类的对象表示,这些不同部分可以在不同的BE节点上执行,并且在BE节点上执行的同样一个PlanFragment,可以有多个并行执行的示例,虽然每个实例是一样的操作逻辑,但是读取的是同一个表的不同部分,这些部分称为ScanRange,例如一个PlanFragment的两个实例,它们在同一个BE节点上,读取同一个表dup1,它们的Scan操作符读取的也是同一个表,但是不同的实例的Scan操作符,读取的是不同的tablet,每个Scan操作符有自己的独一无二的ScanRange,ScanRange是一个tablet列表。
参考FE代码:Coordinator::computeScanRangeAssignment()
调试时,可以调用这个函数 tablets_id_to_string(_scan_ranges) 返回ScanRange里的tablet_id。
//every doris_scan_range is related with one tablet so that one olap scan node contains multiple tablet
Fragment之间通过网络通讯,新增了两个算子专门联系两个Fragment之间的运算符,就是DataSink和ExchangeNode,例如上图,之前直接联系的Hash Join Node和OlapScanNode,在分到不同的Fragment后通过DataSink和ExchangeNode沟通数据。
FE会决定执行计划划分为几个Fragment,并且决定这些Fragment分发到哪个BE上执行,也决定分发到BE上的Fragment,要创建几个实例,这些实例的scan操作符的ScanRange是什么,总之BE只负责无脑执行,所有执行细节都有FE在创建最终执行计划时设置好了。
二、执行计划的分发
执行计划在FE上生成完毕,由FE直接下发给需要执行的它的BE,而不会是先下发给一个所谓的coordinator BE,然后又它再分给其它BE,注意这一点,容易引起误会,select这样的计划,最终数据会汇总到一个BE上,再由这个BE传给FE,这个BE称为Root BE,它负责执行时数据的最终汇总,但是不负责执行计划的分发!
FE下发执行计划的入口函数是:
Coordinator::exec()
|__> Coordinator::sendPipelineCtx()
底层调BackendServiceClient::execPlanFragmentPrepareAsync(),通过grpc把fragments信息发给BE。

在FE的代码里,PlanFragment里的planRoot成员变量,指向自己所包含的执行计划片段的最上层的一个节点,每个执行计划算子(PlanNode)都有一个fragment成员变量,指向自己所在的PlanFragment对象。
PlanFragment的children成员变量,将父子fragment联系起来。
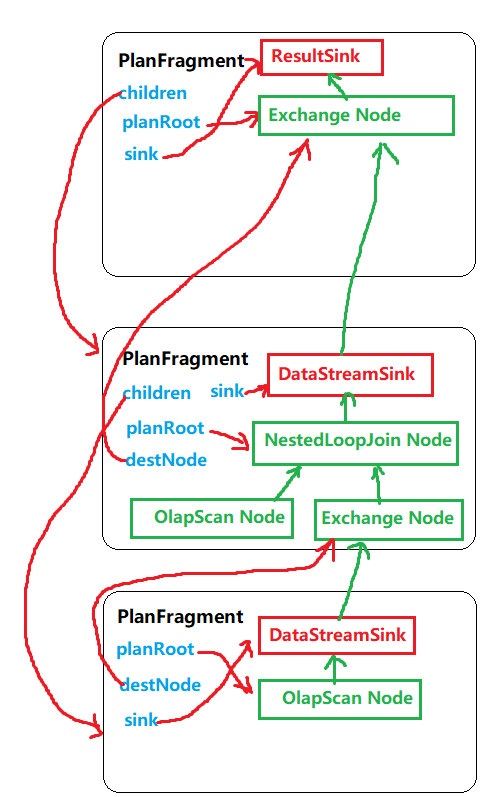
在Coordinator::sendPipelineCtx() 中,beToPipelineExecCtxs存的是发给所有BE的fragment信息,其中每个PipelineExecCtxs是发给同一个BE的所有fragment信息(可能向一个BE发送多个不同的fragment,并且同一个fragment会有多个实例),一个PipelineExecCtxs包含多个PipelineExecContexts,一个fragment对应一个PipelineExecContexts,一个PipelineExecContexts对象里又可能包含多个fragment instance。
FE中Coordinator这个类很重要,里面有个fragment list,就是要发给BE的要执行的fragment。
FE与BE之间的RPC调用,是有超时的,在FE端fe.conf通过下面两个参数可以设置超时时间:
backend_rpc_timeout_ms
remote_fragment_exec_timeout_ms
FE向BE分发fragment,并不是每个BE都分发相同的fragment,而其中发给Root BE的fragment与其它BE稍有不同,多了顶部的fragment,其它BE的数据汇总到这个Root BE,然后从这个Root BE统一发给FE,注意,不是每个BE分别向FE发数据。
BE之间的数据传输,底层也是用grpc。最底层调用
doris::PBackendService_Stub::transmit_block()
关于执行计划(fragments)的分发,是从FE直接向需要执行执行计划的BE发fragments,而不是发给coordinator BE由它转发给其它BE。
笼统的说,FE向BE分发执行计划并执行,大体分两种情况:
1、如果执行计划只有一个fragment,那么FE只向BE发一个RPC(BackendServiceClient::execPlanFragmentAsync()),把执行计划发给BE,BE端根据信息重建ExecNode组成的执行计划树,并且执行。注意,不管哪种情况,fragment信息通过rpc到达BE后,其中plan都有一个reconstruct的过程!
2、如果执行计划中有多个fragment,会分两步,第一步是FE调用BackendServiceClient::execPlanFragmentPrepareAsync()下发fragment,在BE端响应了这个RPC后,会根据fragment信息,重建ExecNode组成的执行计划树,但是不执行,当把所有fragment的执行计划树都重建好了,即prepare完毕。然后FE端再调用BackendServiceClient::execPlanFragmentStartAsync(),让BE上刚才准备好的执行计划开始执行。
上述逻辑FE端的代码在 Coordinator::sendPipelineCtx()。
BackendServiceClient::execPlanFragmentPrepareAsync
BackendServiceClient::execPlanFragmentStartAsync
FE这两个函数已经比较底层了,里面就调用最底层的stub。
BE、FE交互的许多类型,定义在doris/gensrc/build/gen_cpp/下生成的文件里。
三、执行计划的执行
FE调用BackendServiceClient::execPlanFragmentPrepareAsync
导致BE调用PInternalServiceImpl::exec_plan_fragment_prepare
在这里面request参数包括所有fragment的信息。
(在我的单机FE+BE各一个环境,是FE一次远程调用,向BE下发所有fragment,
放在PExecPlanFragmentRequest->request里,这是个字符串,需要进行反序列化)
一步一步往下调用,在PInternalServiceImpl::_exec_plan_fragment里,
从FE传来的所有fragment信息,被反序列化到TPipelineFragmentParamsList,
里面每个param是一个fragment信息,每个fragment调用一次fragment_mgr()->exec_plan_fragment(),
进而调用PipelineFragmentContext::prepare(),以ExecNode的子类为节点构造执行计划树
PipelineFragmentContext::prepare->ExecNode::create_tree()。FE调用BackendServiceClient::execPlanFragmentStartAsync
导致BE调用PInternalServiceImpl::exec_plan_fragment_start
进一步调用FragmentMgr::start_query_execution()(这个函数,整个query只调一次,不是每个fragment调一次)
设置query_id所指的执行计划为可执行状态
在BE的PInternalServiceImpl::_exec_plan_fragment()中,通过RPC 传来的参数TPipelineFragmentParams,代表一个fragment,其中的local_params,每个元素代表这个fragment的instance,每个元素的类型时TPipelineInstanceParams。它们的定义在 gensrc/thrift/PaloInternalService.thrift。
在BE端,谁分配到了最顶层的fragment,谁就是这次查询的Root Fragment。不同BE间,sink和exchange的通讯,是基于brpc(应该是百度内部优化过的rpc),BE代码中相关函数:transmit_block/transmit_data。
sink的底层是channel,channel底层是RPC调用,使用gRPC(百度版本的RPC?),接口定义在gen_cpp/internal_service.pb.cc/h里定义的PBackendService,在internal_service.proto里定义:
Channel::init()
Channel/PipChannel::add_rows() -- 积累行记录
Channel/PipChannel::send_(local_)block() -- 向另一个fragment发送行记录
在BE上fragment prepare(包括重建,准备好各种数据收发对象)完成后,就开始执行了,新的执行引擎模型称为pipeline,它与火山模型不同的是,不是通过遍历执行计划树来执行的,而是再把每个算子或fragment分成若干个operator,operator之间可以并行执行。PipelineTask是被pipeline系统调用的对象,可以理解为线程。整个pipeline引擎类似于一个线程池,一个BE只有一个pipeline引擎(TaskScheduler对象),和线程池不同的是,pipeline的线程在遇到阻塞时,会放弃任务,然后去执行其它不会阻塞的任务。pipeline引擎的阻塞任务队列有一个,就绪任务队列有好几个,有一个专门线程不断检查阻塞任务队列,将其中不再阻塞的任务(PipelineTask对象),加到其中一个就绪队列中,有好几个线程会从就绪队列里取PipelineTask执行。
在整个BE中,有一个(也只有一个)ExecEnv对象,通过ExecEnv::GetInstance()获得,里面包含了TaskScheduler对象(全局只有一个),这就是流水线的执行对象,TaskScheduler对象里包含了BlockedTaskScheduler对象。BE中还有一些其它模块的线程池,BE中有可能每个模块都有自己的线程池。
相关代码在:
ExecEnv::init_pipeline_task_scheduler()和TaskScheduler::start()
BE中Fragment、Pipeline、PipelineTask、Operator对象的关系:一个PipelineTask对应一个Pipeline对象,一个PipelineTask处理多个operator,operator chain在PipelineTask::_operators成员中。PipelineTask的operator chain是从Pipeline创建来的--Pipeline::build_operators()。
operator可以对应一个ExecNode,也可能一个ExecNode对应多个Operator。Operator的执行最终还是要调用相应ExecNode里的算法函数执行,一个Fragment可能被分成多个Pipeline,一个Pipeline里有多个operator由一个PipelineTask执行。使用operator后,ExecNode的get_next不用了,用push和pull。这些还有待研究代码证实。
VMysqlResultWriter从BE将结果写给FE,FE通过BackendServiceClient::fetchDataAsync 接收BE的 VResultSink::send发来的数据。
举个例子?
参考:
Doris全面解析】Doris SQL 原理解析 (qq.com)
Doris原理分享(2) - 知乎 (zhihu.com)
Pipeline 执行引擎 - Apache Doris
Apache Doris 源码阅读与解析系列直播——第四讲 一条SQL的执行过程_哔哩哔哩_bilibili