目录
一、Python爬虫的详细工作流程
确定起始网页
发送 HTTP 请求
解析 HTML
处理数据
跟踪链接
递归抓取
存储数据
二、Python爬虫的组成部分
请求模块
解析模块
数据处理模块
存储模块
调度模块
反爬虫处理模块
一、Python爬虫的详细工作流程
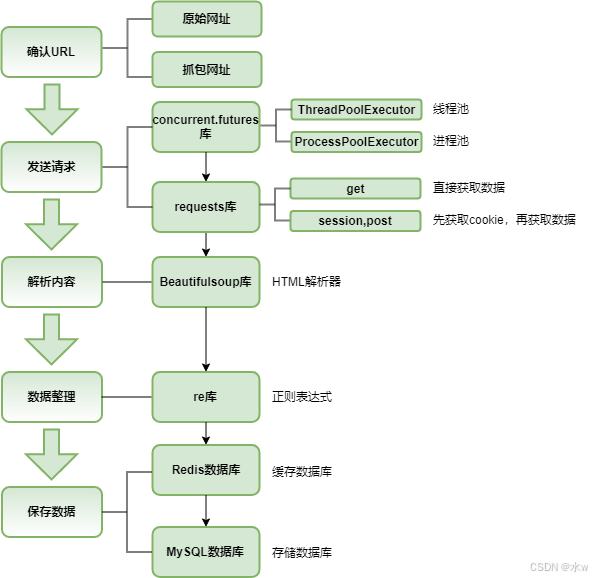
在进行网络爬虫工作时,以下是其核心的工作流程及相应的详细操作步骤:
确定起始网页
首先,需要精心挑选一个或多个合适的起始网页,它们将作为整个爬虫程序开始抓取数据的关键入口点。这些起始网页的选择往往基于爬虫的目标和需求,例如,若要采集某类新闻资讯,可选取该领域知名新闻网站的首页或者特定频道的首页作为起始网页;若聚焦于电商商品信息,则可将大型电商平台的分类商品列表页作为起始点。
发送 HTTP 请求
选好起始网页后,爬虫便会模拟浏览器的行为,向这些起始网页所在服务器发送 HTTP 请求。这个过程如同我们在浏览器地址栏输入网址并回车获取网页内容一样,只不过爬虫是通过代码来实现这一操作。借助相应的网络请求库(如requests),爬虫能够获取到网页的原始 HTML 代码,这是后续解析和提取数据的基础素材。
解析 HTML
获取到 HTML 代码后,爬虫会运用专业的 HTML 解析工具来深入剖析这些代码内容。
常见且实用的解析器有Beautiful Soup,它提供了便捷且功能强大的方法,能按照 HTML 标签、属性、类名等元素精准定位到所需数据所在位置;另外,正则表达式也可用于对 HTML 代码进行解析,尤其适用于一些具有特定格式规律的数据提取场景。
通过这些解析手段,爬虫可以从繁杂的 HTML 代码中挖掘出各类有用的数据,像页面中的文本信息、展示的图片链接以及指向其他页面的超链接等。
处理数据
从 HTML 代码中提取出的数据往往还处于较为原始、杂乱的状态,需要进一步对其进行处理、清洗和整理。例如,提取的文本可能包含多余的空格、换行符或者一些特殊字符,此时就需要通过编写代码去除这些不必要的内容,使其格式规范统一;对于图片链接,可能需要检查其有效性,并根据后续存储和分析的需求进行相应的格式转换等操作。经过这样的处理过程,数据才能更便于后续的存储以及各类分析工作开展。
跟踪链接
在解析当前网页的 HTML 代码时,爬虫会从中提取出众多指向其他页面的链接,这些链接蕴含着拓展数据采集范围的潜力。爬虫会把这些链接有序地添加到待抓取列表中,然后依据预先设定好的抓取策略,例如按照链接的重要性排序、深度优先或者广度优先等策略,从中选择下一个要抓取的链接,从而为进一步深入挖掘更多网页数据做好准备。
递归抓取
依托上述的操作流程,爬虫会以递归的方式持续工作。即不断重复发送 HTTP 请求、解析 HTML、处理数据以及跟踪链接这些步骤,持续抓取新的网页,并从中提取出有价值的数据。这一过程会循环往复地进行,直至满足特定的停止条件。
停止条件可能是达到了预先设定的抓取深度,比如规定只抓取三层页面链接内的数据;或者是抓取的网页数量达到了既定目标;亦或是遇到了如特定页面提示 “无更多内容” 之类的指定终止条件,以此确保爬虫工作在合理的范围内有序完成。
存储数据
在整个抓取过程中,爬虫会将获取到的各类数据妥善保存起来,以便后续进行深入的使用和分析。
存储的介质可以是多样化的,例如将数据存储到关系型数据库(如 MySQL、Oracle 等)中,方便进行复杂的查询和数据关联操作;也可以保存到非关系型数据库(如 MongoDB 等),以应对数据结构较为灵活、复杂的情况;还能将数据写入到本地文件(如 CSV 文件便于数据分析、JSON 文件利于数据交换等)中,根据具体的使用场景和需求选择最为合适的存储方式。
通过这样一套严谨且有序的流程,网络爬虫能够高效、准确地从互联网上抓取到大量有价值的数据,为后续的各类应用和分析提供有力的数据支撑。
二、Python爬虫的组成部分
Python 爬虫主要由以下几个核心部分组成:
请求模块
该模块的主要功能是,负责向目标网站发送 HTTP 请求,以获取网页的原始内容。HTTP 请求有多种类型,如 GET、POST 等,爬虫可根据不同的需求选择合适的请求类型。
import requests
# 发送GET请求
response = requests.get('https://www.example.com')
if response.status_code == 200:
print(response.text)解析模块
该模块的主要功能是,对请求模块获取到的网页内容(通常是 HTML、XML 或 JSON 格式)进行解析,从中提取出所需的数据。
常用库:
-
BeautifulSoup:是一个强大的 HTML/XML 解析库,能将复杂的 HTML 或 XML 文档转换为树形结构,方便用户通过标签名、类名、ID 等属性查找和提取数据。
-
request:这是一个简洁且功能强大的 HTTP 库,它使得发送 HTTP 请求变得异常简单,支持多种请求方法(如 GET、POST 等),还能处理请求头、请求参数、Cookie 等。
-
lxml:是一个高性能的 XML 和 HTML 解析器,解析速度快,功能强大。
from bs4 import BeautifulSoup
import requests
response = requests.get('https://www.example.com')
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a') # 查找所有的<a>标签
for link in links:
print(link.get('href'))数据处理模块
该模块的主要功能是,对解析模块提取的数据进行清洗、转换和整理,使其符合后续存储或分析的要求。例如,去除数据中的多余空格、特殊字符,将数据转换为统一的格式等。
# 去除字符串中的多余空格 cleaned_data = " hello, world! ".strip()存储模块
该模块的主要功能是,将处理好的数据保存到合适的存储介质中,以便后续使用。常见的存储介质包括文件(如 CSV、JSON、TXT 等)、数据库(如 MySQL、MongoDB、Redis 等)。
import csv
data = [['Name', 'Age'],['Alice', 25],['Bob', 30]]with open('data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)import pymysql
# 连接数据库
conn = pymysql.connect(host='localhost', user='root', password='password', database='test')
cursor = conn.cursor()# 创建表
create_table_sql = "CREATE TABLE IF NOT EXISTS users (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), age INT)"
cursor.execute(create_table_sql)# 插入数据
insert_sql = "INSERT INTO users (name, age) VALUES (%s, %s)"
data = [('Alice', 25), ('Bob', 30)]
cursor.executemany(insert_sql, data)# 提交事务
conn.commit()# 关闭连接
cursor.close()
conn.close()调度模块
该模块的主要功能是,负责管理爬虫的任务调度,包括确定抓取的起始页面、控制抓取的顺序和频率、处理待抓取的 URL 队列等。对于大规模的爬虫项目,调度模块还需要考虑分布式爬取和并发控制,以提高爬取效率。
-
Scrapy是一个功能强大的 Python 爬虫框架,它内置了调度模块,提供了高效的任务调度和并发控制机制。
以下是一个简单的 Scrapy 爬虫示例:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['https://www.example.com']
def parse(self, response):# 提取数据
links = response.css('a::attr(href)').getall()
for link in links:
yield {'link': link}反爬虫处理模块
该模块的主要功能是,在爬虫过程中,目标网站可能会采取各种反爬虫措施,如 IP 封禁、验证码、请求频率限制等。反爬虫处理模块的作用是识别和应对这些反爬虫机制,确保爬虫能够正常运行。
常用方法:
-
使用代理 IP:通过代理服务器隐藏真实 IP 地址,避免被目标网站封禁。可以使用第三方代理服务或自己搭建代理池。
-
设置请求头:模拟浏览器的请求头信息,使爬虫的请求看起来更像正常的浏览器请求。
-
控制请求频率:合理设置请求间隔时间,避免过于频繁的请求触发目标网站的反爬虫机制。
综上所述,一个完整的 Python 爬虫系统需要各个组成部分协同工作,以实现高效、稳定地从互联网上抓取所需的数据。






![[LeetCode 1696] 跳跃游戏 6(Ⅵ)](https://i-blog.csdnimg.cn/direct/6b2ae3863b7a4c688a4e15e365e9786f.png)