Graph Embedding理论介绍及5种算法演示
- 1.图数据结构
- 2.图表示学习
- 3.Graph Embedding
- 3.1 DeepWalk算法
- DeepWalk算法理论
- DeepWalk 核心代码
- 参考资料
1.图数据结构
在现实世界中,网络只是互连节点的集合。为了表示这种类型的网络,我们需要一个与之相似的数据结构。幸运的是,我们有一个数据结构,即图(Graph)。图包含由边连接的顶点(代表网络中的节点)(可以代表互连b/q节点)。
2.图表示学习
在数据结构中,图是一种基础且常用的结构。现实世界中许多场景可以抽象为一种图结构,如社交网络,交通网络,电商网站中用户与物品的关系等。
目前提到图算法一般指:
- 经典数据结构与算法层面的:最小生成树(Prim,Kruskal,…),最短路(Dijkstra,Floyed,…),拓扑排序,关键路径等
- 概率图模型,涉及图的表示,推断和学习,详细可以参考Koller的书或者公开课
- 图神经网络,主要包括Graph Embedding(基于随机游走)和Graph CNN(基于邻居汇聚)两部分。
这里主要介绍Graph Embedding的相关内容。
3.Graph Embedding
Graph Embedding技术将图中的节点以低维稠密向量的形式进行表达,要求在原始图中相似(不同的方法对相似的定义不同)的节点其在低维表达空间也接近。得到的表达向量可以用来进行下游任务,如节点分类,链接预测,可视化或重构原始图等。
本文主要介绍以下5种经典的Graph Embedding算法
DeepWalk: 采用随机游走,形成序列,采用skip-gram方式生成节点embedding。node2vec:不同的随机游走策略,形成序列,类似skip-gram方式生成节点embedding。LINE:捕获节点的一阶和二阶相似度,分别求解,再将一阶二阶拼接在一起,作为节点的embedding。struc2vec:对图的结构信息进行捕获,在其结构重要性大于邻居重要性时,有较好的效果。SDNE:采用了多个非线性层的方式捕获一阶二阶的相似性
3.1 DeepWalk算法
DeepWalk算法思想与 word2vec 类似,**从一个初始节点沿着图中的边随机游走一定的步数,将经过的节点序列视为句子。**那么,从不同的起点开始的不同游走路线就构成了不同的句子。当获取到足够数量的句子(节点访问序列)后,可以使用 skip-gram 模型对每个节点学习其向量表示。这个过程如下图所示:
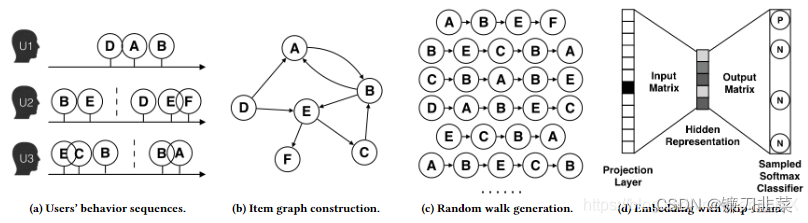
**DeepWalk 利用类似深度优先遍历的方式将复杂的图结构转换为序列,进而实现节点的Embedding。**这个遍历的过程相当于对图中的节点进行采样,捕获局部上下文信息。上图中B与D都是A与E共有的邻居,那么在经过节点B、D的随机游走序列中,节点A或者节点E出现的频率也比较高,说明节点A和E具有相似的上下文语境,那么A和E的Embedding表示也应该相似。
DeepWalk算法理论

【KDD 2014】DeepWalk: Online Learning of Social Representations
论文摘要:我们提出了 DeepWalk,一种学习网络中节点潜在表示的新方法。这些潜在的表征将社会关系编码在一个连续的向量空间中,这很容易被统计模型利用。DeepWalk 总结了语言建模和从单词序列到图形的无监督特征学习(或深度学习)方面的最新进展。DeepWalk 使用从截断的随机游走中获得的局部信息,通过将游走视为句子的等价物来学习潜在表征。我们展示了 DeepWalk 在几个社交网络的多标签网络分类任务上的潜在表现,如 BlogCatalog、 Flickr 和 YouTube。我们的研究结果表明,DeepWalk 的表现优于具有挑战性的基线,后者允许从全局角度观察该网络,尤其是在存在缺失信息的情况下。当标记数据稀少时,DeepWalk 的表示方法可以提供比竞争方法高出10% 的 F1分数。在一些实验中,DeepWalk 的表示能够超越所有的基线方法,同时使用的训练数据减少了60% 。DeepWalk 也是可扩展的。它是一种在线学习算法,可以构建有用的增量结果,并且具有平行性。这些特性使它适合于广泛的现实世界应用,如网络分类和异常检测。
DeepWalk uses local information obtained from truncated random walks to learn latent representations by treating walks as the equivalent of sentences.
在NLP任务中,word2vec是一种常用的word embedding方法,word2vec通过语料库中的句子序列来描述词与词的共现关系,进而学习到词语的向量表示。
DeepWalk的思想类似word2vec,使用图中节点与节点的共现关系来学习节点的向量表示。那么关键的问题就是如何来描述节点与节点的共现关系,DeepWalk给出的方法是使用随机游走(Random Walk)的方式在图中进行节点采样。
Random Walk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
定义(随机游走, Random Walk)设
G
=
{
V
,
E
}
G=\{V, E\}
G={V,E}表示一个连通图。考虑从图
G
G
G上的节点
v
(
0
)
∈
V
v^{(0)}\in V
v(0)∈V开始的随机游走。假设在随机游走的第
t
t
t步访问的是节点
v
(
t
)
v^{(t)}
v(t),那么随机游走的下一个节点按照如下概率从
v
(
t
)
v^{(t)}
v(t)的邻居节点中选出:
p
(
v
(
t
+
1
)
∣
v
(
t
)
)
=
{
1
d
(
v
(
t
)
)
v
(
t
+
1
)
∈
N
(
v
(
t
)
)
,
0
others
p(v^{(t+1)}|v^{(t)})=\begin{cases}\frac{1}{d(v^{(t)})} & v^{(t+1)}\in N(v^{(t)}), \\0 & \text{ others } \end{cases}
p(v(t+1)∣v(t))={d(v(t))10v(t+1)∈N(v(t)), others
式中,
d
(
v
(
t
)
)
d(v^{(t)})
d(v(t))表示节点
v
(
t
)
v^{(t)}
v(t)的度,
N
(
v
(
t
)
)
N(v^{(t)})
N(v(t))表示
v
(
t
)
v^{(t)}
v(t)的邻居节点集合。换句话说,将被访问的下一个节点是按照均匀分布从当前节点的邻居中随机选择的。

DeepWalk算法主要包括两个步骤:
- 第一步为随机游走采样节点序列
- 第二步为使用skip-gram model word2vec学习表达向量,即更新过程。
算法中的外层循环指定了我们应该在每个顶点开始随机游走的次数
γ
\gamma
γ。 我们将每次迭代视为对数据进行“传递”,并在此传递期间对每个节点进行一次遍历。在每次遍历的开始,我们生成一个随机顺序来遍历顶点。 这不是严格要求的,但众所周知可以加速随机梯度下降的收敛。
在算法的内部循环中,我们遍历图的所有顶点。对每个顶点
v
i
v_i
vi,我们生成一个随机游走
∣
W
v
i
∣
=
t
|W_{v_i}|=t
∣Wvi∣=t,并且然后使用它更新我们的表示(第7行)。我们使用SkipGram算法根据目标函数更新表示。
也就是说,获取足够数量的节点访问序列后,使用SkipGram model 进行向量学习。
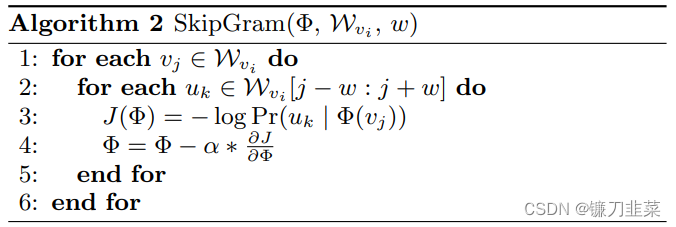
SkipGram 是一种语言模型,它最大化句子中窗口
w
w
w内出现的单词之间的共现概率。算法2 迭代出现在窗口
w
w
w内的随机游走中的所有可能组合(第1-2行)。对于每一种组合,将每个节点
v
j
v_j
vj映射到它的当前表示向量
Φ
(
v
j
)
∈
R
d
\Phi(v_j)\in \mathbb{R}^d
Φ(vj)∈Rd。给定
v
j
v_j
vj的表示向量,目标是最大化它的邻居在walk中的概率(第3行)。我们可以使用多种分类器选择来学习这种后验分布。例如,使用逻辑回归对前面的问题进行建模会产生大量等于
∣
V
∣
|V|
∣V∣的标签。 可能是数百万或数十亿。这样的模型需要大量的计算资源,可能跨越整个计算机集群。为了加快训练时间,可以使用Hierarchical Softmax来近似概率分布。
Hierarchical Softmax
假定
u
k
∈
V
u_k\in V
uk∈V,在第三行中计算
P
r
(
u
k
∣
Φ
(
v
j
)
)
Pr(u_k|\Phi(v_j))
Pr(uk∣Φ(vj))是不可行的。计算分配函数(归一化因子)非常昂贵。 如果我们将顶点分配给二叉树的叶子,预测问题就变成了最大化树中特定路径的概率。
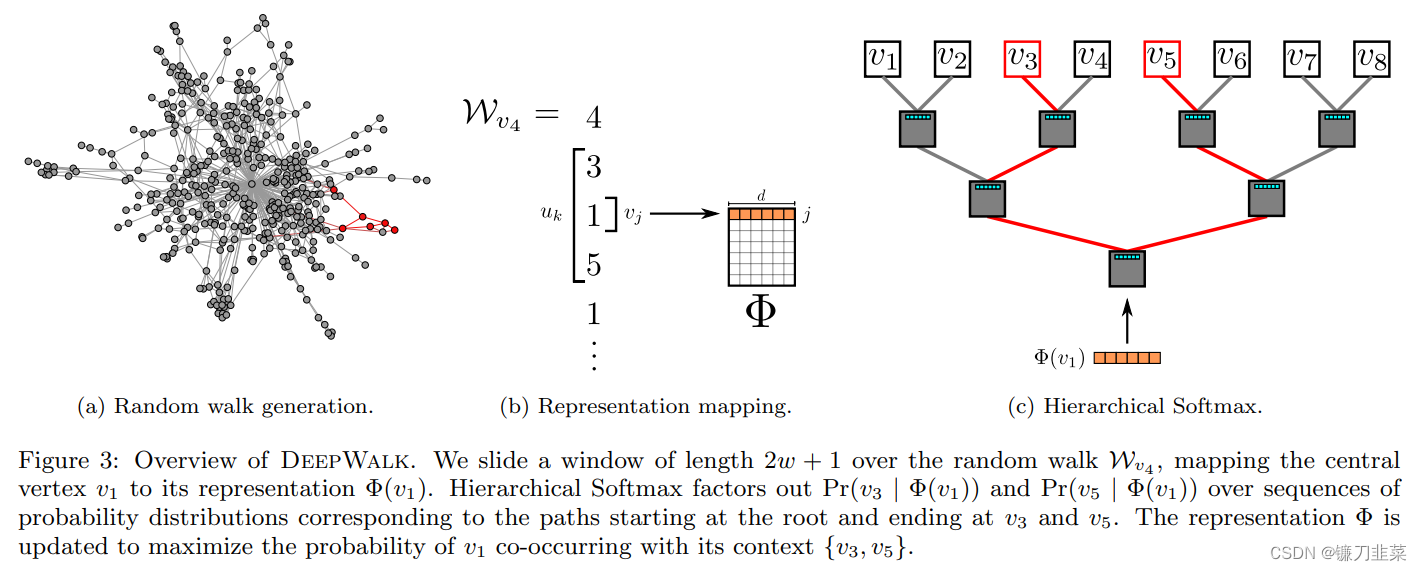
如果到节点
u
k
u_k
uk的路径由一组有序的树节点
(
b
0
,
b
1
,
.
.
.
,
b
⌈
log
∣
V
∣
⌉
)
(b_0,b_1,...,b_{\left \lceil \log |V| \right \rceil })
(b0,b1,...,b⌈log∣V∣⌉),
(
b
0
=
root
)
,
b
⌈
log
∣
V
∣
⌉
=
u
k
(b_0=\text{root}), b_{\left \lceil \log |V| \right \rceil }=u_k
(b0=root),b⌈log∣V∣⌉=uk,然后:
P
r
(
u
k
∣
Φ
(
v
j
)
)
=
∏
l
=
1
⌈
log
∣
V
∣
⌉
P
r
(
b
l
∣
Φ
(
v
j
)
)
Pr(u_k|\Phi(v_j))=\prod _{l=1}^{\left \lceil \log |V| \right \rceil}Pr(b_l|\Phi(v_j))
Pr(uk∣Φ(vj))=l=1∏⌈log∣V∣⌉Pr(bl∣Φ(vj))
现在,
P
r
(
b
l
∣
Φ
(
v
j
)
)
Pr(b_l|\Phi(v_j))
Pr(bl∣Φ(vj))可以通过一个二元分类器来建模,该分类器是被分配给节点
b
l
b_l
bl的父辈(parent)。这样就将
P
r
(
u
k
∣
Φ
(
v
j
)
)
Pr(u_k|\Phi(v_j))
Pr(uk∣Φ(vj))的复杂度从
O
(
∣
V
∣
)
O(|V|)
O(∣V∣)降低为
O
(
log
∣
V
∣
)
O(\log |V|)
O(log∣V∣)。
我们可以通过为随机游走中的频繁顶点分配更短的路径来进一步加快训练过程。 霍夫曼编码用于减少树中频繁元素的访问时间。
DeepWalk 核心代码
DeepWalk算法主要包括两个步骤,第一步为随机游走采样节点序列,第二步为使用skip-gram model word2vec学习表达向量。
①构建同构网络,从网络中的每个节点开始分别进行Random Walk 采样,得到局部相关联的训练数据;
②对采样数据进行SkipGram训练,将离散的网络节点表示成向量化,最大化节点共现,使用Hierarchical Softmax来做超大规模分类的分类器
优化策略:我们可以通过并行的方式加速路径采样,在采用多进程进行加速时,相比于开一个进程池让每次外层循环启动一个进程,我们采用固定为每个进程分配指定数量的num_walks的方式,这样可以最大限度减少进程频繁创建与销毁的时间开销。
核心代码:deepwalk_walk方法对应上一节算法1中第6行,_simulate_walks对应算法1中第3行开始的外层循环。最后的Parallel为多进程并行时的任务分配操作。
代码实现
- 构造图
主要是使用networkx这个库来从文件中读取边的信息来构造图,文件的每一行的形式如下:
node1 node2 <edge_weight>
node1 node3 <edge_weight>
......
其中,边的权重 edge_weight 不是必须有的。具体读取数据并构造图的代码如下:
import networkx as nx
# create_using=nx.DiGraph() 表示构造的是有向图
G = nx.read_edgelist('data/wiki/Wiki_edgelist.txt', create_using=nx.DiGraph())
- 随机游走
import random
# 从 start_node 开始随机游走
def deepwalk_walk(walk_length, start_node):
walk = [start_node]
while len(walk) < walk_length:
cur = walk[-1]
cur_nbrs = list(G.neighbors(cur))
if len(cur_nbrs) > 0:
walk.append(random.choice(cur_nbrs))
else:
break
return walk
# 产生随机游走序列
def _simulate_walks(nodes, num_walks, walk_length):
walks = []
for _ in range(num_walks):
random.shuffle(nodes)
for v in nodes:
walks.append(deepwalk_walk(walk_length=walk_length, start_node=v))
return walks
# 得到所有节点
nodes = list(G.nodes())
# 得到序列
walks = _simulate_walks(nodes, num_walks=80, walk_length=10)
- embedding
为了方便起见,这里就使用gensim中的Word2Vec 来实现节点的 Embedding 了:
from gensim.models import Word2Vec
# 默认embedding为100维
w2v_model = Word2Vec(walks, sg=1, hs=1)
# 打印其中一个节点的embedding向量
print(w2v_model.wv['1300'])
输出:
[-1.39947191e-01 -5.33481300e-01 -1.09855458e-01 1.20146805e-03
4.00672972e-01 -2.46553212e-01 7.22396374e-01 -4.26189333e-01
-6.57133341e-01 4.69600588e-01 8.28870296e-01 -3.03234637e-01
1.88222304e-01 1.24777816e-01 -4.44700539e-01 -4.37811464e-01
-7.45837808e-01 -2.50921756e-01 -8.02963614e-01 -2.61410743e-01
-8.72843862e-01 1.92571595e-01 -3.41048539e-01 -6.70526385e-01
1.99061573e-01 -5.20646274e-01 -5.71959019e-01 -7.80863523e-01
-4.22291279e-01 -1.36520281e-01 3.66761714e-01 2.14738473e-01
5.09930909e-01 7.76802227e-02 -1.40453383e-01 6.05036378e-01
9.81948152e-02 -6.10185206e-01 -5.65821946e-01 -4.70802654e-03
-7.46539950e-01 -1.27204442e+00 6.58222020e-01 -6.65924609e-01
5.60211726e-02 -3.12636346e-01 -1.23164944e-01 8.69078815e-01
3.40234697e-01 -3.22459549e-01 -4.56874669e-01 7.09066838e-02
...
使用随机游走有两个好处:
- 并行化,随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
- 适应性,可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
参考资料
[1] A Gentle Introduction to Skip-gram (word2vec) Model — AllenNLP ver.
[2] DeepWalk:算法原理,实现和应用
[3] 《图深度学习》 马耀 汤继良 著
[4] DeepWalk: Online Learning of Social Representations
[5] DeepWalk原理与代码实战