前言
MySQL从5.7的版本开始支持Json后,我时常在设计表格时习惯性地添加一个Json类型字段,用做列的冗余。毕竟Json的非结构性,存储数据更灵活,比如接口请求记录用于存储请求参数,因为每个接口入参不一致,也有不传和空传的等等。
然而在一些特定场景下,需要用Json字段里的某个键用来In查询,并且需要保证不会造成慢查询的前提下,用该键对整个查询结果分组。因为这张表属于是高频储存的表,数据相对庞大,下面先看看SQL查询和放到业务里的查询时间。
场景介绍
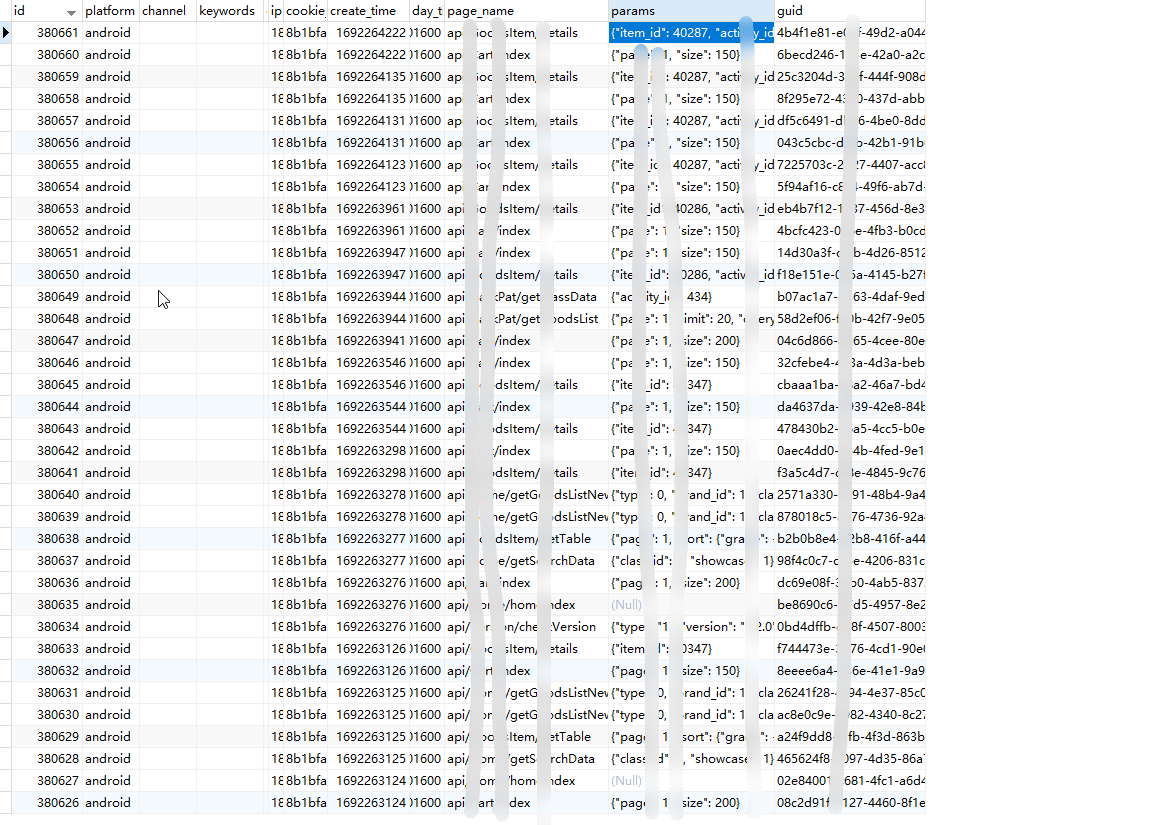
数据表主要存储来自客户端的请求信息,如客户端标识,接口名,渠道,来源,IP,入参等等。而场景是需要对某个页面下某个物品的请求总数和请求用户数,也就是要将访问数和访问用户数作为字段字段方式拼接到物品上。到这里可能很多人会说,在指定页埋点计数式更新物品两个字段就可以了,干嘛这么麻烦去明细表里统计。
如此的做法,就真的是因为懒,毕竟有时功能不是很重要就没必要为此多创建一张与库里有重叠性质的表,下次去掉这部分时,多一张给后来者新增一份负担,看着没用的表又不敢删。好了扯远了,下面就开始用SQL和业务代码测试查询效果和后面优化方法吧。
SQL查询
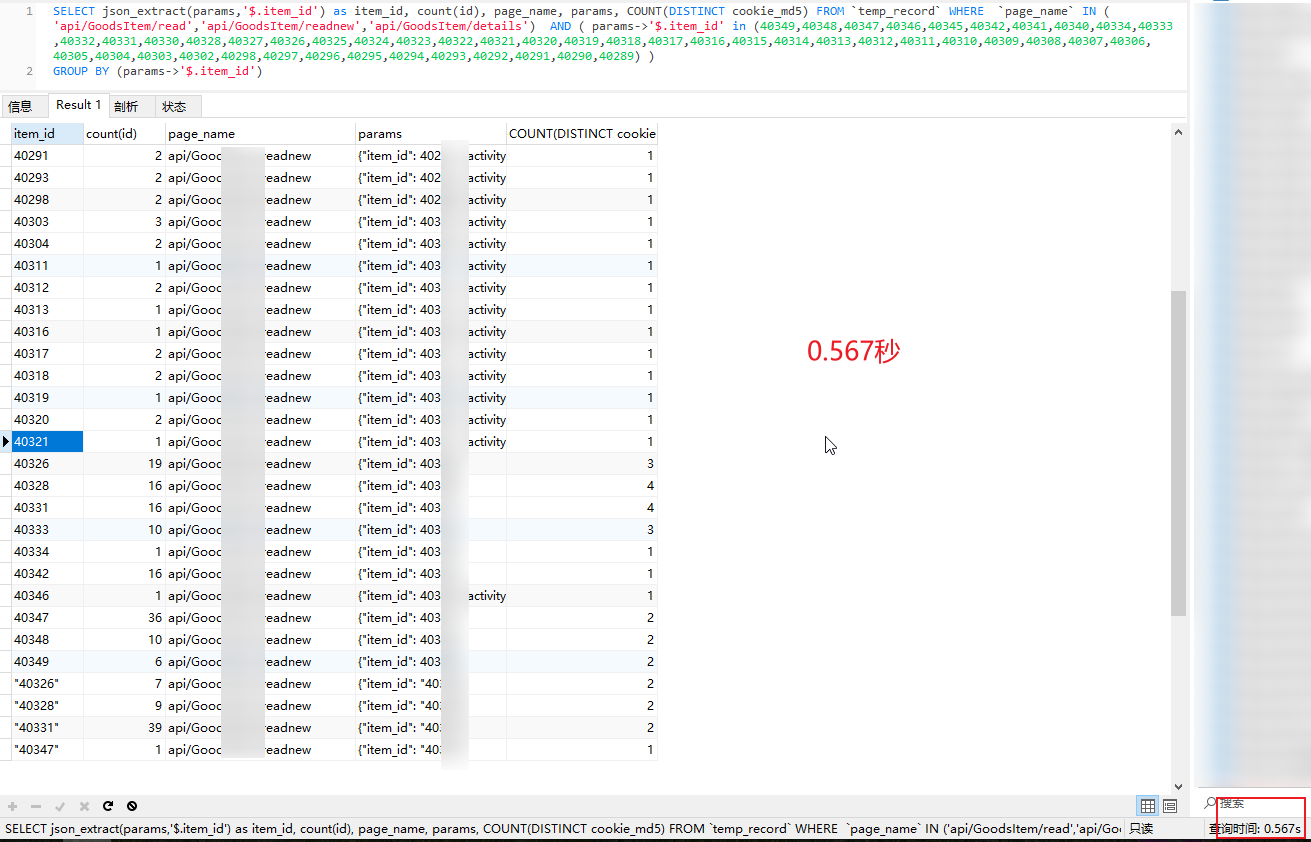
SELECT json_extract(params,'$.item_id') as item_id, count(id), page_name, params, COUNT(DISTINCT cookie_md5) FROM `temp_record` WHERE `page_name` IN ('api/GoodsItem/read','api/GoodsItem/readnew','api/GoodsItem/details') AND ( params->'$.item_id' in (40349,40348,40347,40346,40345,40342,40341,40340,40334,40333,40332,40331,40330,40328,40327,40326,40325,40324,40323,40322,40321,40320,40319,40318,40317,40316,40315,40314,40313,40312,40311,40310,40309,40308,40307,40306,40305,40304,40303,40302,40298,40297,40296,40295,40294,40293,40292,40291,40290,40289) )
GROUP BY (params->'$.item_id')当前数据量不多的情况下,查询时间0.56秒,针对条件我先对其中一个字段添加了NORMAL类型索引后,查询时间在0.07和0.19间跳动。虽然速度提升了一点,但是这里还有一个关键的查询,就是Json里的item_id的键,既作为条件又作为分组参。
但是索引只能使用字段,Json字段里的键是不可能加进去的。虽然但是有一种曲线设置的方式,就是提取Json里的item_id为一个虚拟字段,然后将该虚拟字段设置为索引,于是就开始操作了。
优化方法
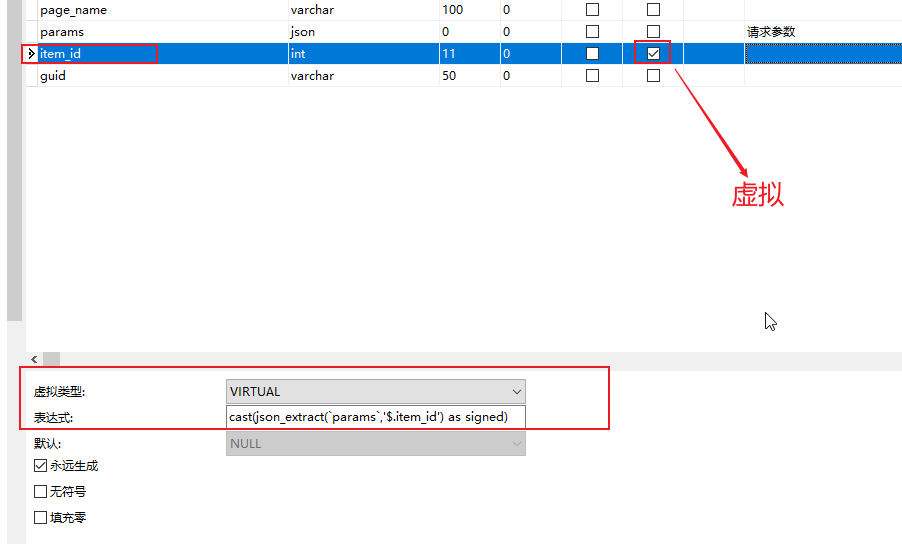
1. 图形创建虚拟字段
以下用Navicat for MySQL为例,新建字段,勾选 “虚拟”, 虚拟类型 “VIRTUAL”, 表达式 cast(json_extract(`params`,'$.item_id') as signed),也就是从Json提取“item_id”。
2. 命令创建虚拟字段
ALTER TABLE `temp_record`
ADD COLUMN `item_id` int(11) GENERATED ALWAYS AS (cast(json_extract(`params`,'$.item_id') as signed));3. 设置索引
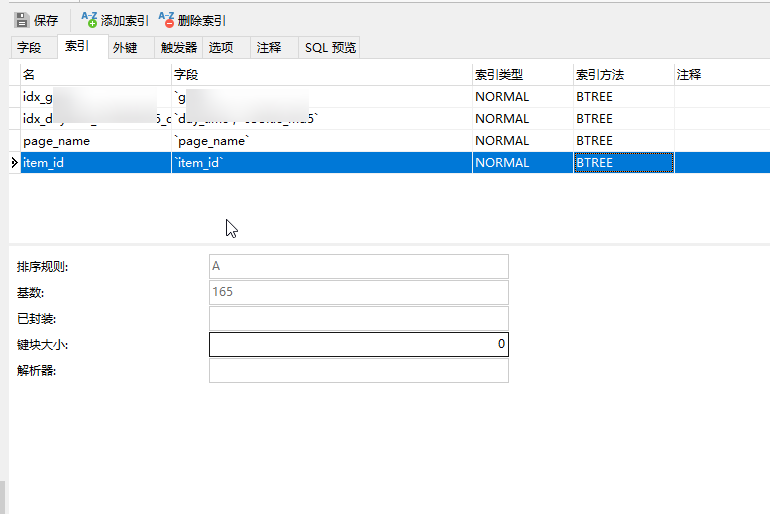
进入设置,像添加普通字段的方式将item_id设置为普通索引。
4. 优化查询结果
SELECT item_id, count(id), page_name, params, COUNT(DISTINCT cookie_md5) FROM `temp_record` WHERE `page_name` IN ('api/GoodsItem/read','api/GoodsItem/readnew','api/GoodsItem/details') AND ( item_id in (40349,40348,40347,40346,40345,40342,40341,40340,40334,40333,40332,40331,40330,40328,40327,40326,40325,40324,40323,40322,40321,40320,40319,40318,40317,40316,40315,40314,40313,40312,40311,40310,40309,40308,40307,40306,40305,40304,40303,40302,40298,40297,40296,40295,40294,40293,40292,40291,40290,40289) )
GROUP BY (params->'$.item_id')修改后,查询时间稳定在0.05秒上下一点,可以说相较之前是快了10倍,分组中其实也是可以改成item,但是数据里有字符串的item_id索引为了兼容这种类型,分组还是用的JSON取值方式,速度影响不大。
PHP代码
1. 统计(仅作参考)
public static function clickCount($goodsItemIds = [])
{
$pageName = [
'api/GoodsItem/read',
'api/GoodsItem/readnew',
'api/GoodsItem/details'
];
$goodsItemIds = implode(",", $goodsItemIds);
$where[] = ['page_name', 'in', $pageName];
//$where[] = ['params->item_id', 'in', $goodsItemIds];
$data = Db::name('temp_record')->field("item_id,count(id) as pv, count(DISTINCT cookie_md5) as uv")
->where($where)->whereRaw("params->'$.item_id' in ($goodsItemIds)")->group("params->item_id")
->select();
$data && $data = array_column($data, null, 'item_id');
return $data;
}2. 明细(仅作参考)
public static function clickRecord($itemId = 0, $page = 1, $size = 20)
{
$result['count'] = 0;
$result['list'] = [];
$pageName = [
'api/GoodsItem/read',
'api/GoodsItem/readnew',
'api/GoodsItem/details'
];
$where[] = ['page_name', 'in', $pageName];
$field = ["from_unixtime(day_time, '%Y-%m-%d') as day_time, count(id) as clicks,
count(DISTINCT cookie_md5) as user_clicks"];
$result['list'] = Db::name('temp_record')
->field($field)
->where($where)->whereRaw("params->'$.item_id' = $itemId")
->group("day_time")
->page($page, $size)
->order('day_time desc')
->select();
$result['count'] = Db::name('temp_record')->field($field)->where($where)
->whereRaw("params->'$.item_id' = $itemId")->group("day_time")->count();
return $result;
}